wrap-up-report
Sentence Textual Similarity
STS는 입력 문장간의 유사도를 예측하는 task이다. 단순히 겹치는(overlap) 수준에서의 유사함이 아닌 의미적인 유사도를 얻기 위한 task이며 cosine 유사도, jaccard 유사도 등 유사도를 측정할 다양한 방법이 있지만 본 실험에서는 딥러닝 모델을 사용한 유사도를 구하려고 한다.
- STS의 활용
어떤 Task를 하더라도 어디서 활용할 수 있는지 모르고 사용한다면 의미가 없다고 생각한다. 그렇다면 STS는 어느 분야에 활용될 수 있는지 알아보자. 의미적으로 반복되는 말이나 글을 인지하여 보고서나 논문 등 전달 목적의 글의 중요한 맥락을 파악하여 가독성을 높여줄 수 있다. 또한 질문에 대한 챗봇의 대답에 대해서도 사용할 수 있으며 표절 탐지나 데이터 증강 분야에도 활용이 가능하다.
이런 비슷한 Task중 Textual Entailment(TE)가 있는데 가장 큰 차이점은 방향성이다. TE는 전제와 가설과 같이 특정한 방향성이 존재하지만 STS는 문장간의 방향성이 동등하다.
목표
이번 프로젝트는 직접 코드를 짜며 딥러닝을 사용한 첫 프로젝트이다.
지금까지 진행해봤던 몇몇 프로젝트는 단순히 프레임워크나 라이브러리를 가져다가 쓰는 것에 그쳤었다.
내 목표는 명확했다. 성능을 떠나 내가 무엇을 하려는지 파악하고 모델의 원리까지 알고 사용하는 것이다.
나는 이번 프로젝트에서 ELECTRA와 RoBERTa 모델로 진행했다.
왜 이모델을 선택했나?
의미적인 유사도를 얻기 위해 우선 encoder의 성능이 중요하다고 생각했다. 가장 먼저 BERT가 떠올랐다. 내 생각은 여기서부터 시작했고 성능이 개선된 RoBERTa를 선택했다. RoBERTa는 기본적으로 더 큰 데이터와 큰 배치사이즈를 사용하여 성능을 크게 개선했다. 또한 BERT의 MLM의 문제점(매번 같은 MASK데이터 사용)을 지적하며 Dynamic Masking을 도입했다. 실제로는 각각 다른 마스킹을 한 데이터를 여러개 만들어 놓고 그 데이터를 에폭별로 사용하게 된다. 따라서 만들어 둔 데이터 이상으로 에폭이 진행되면 똑같은 데이터를 보는 한계는 여전히 존재한다.
RoBERTa는 NSP를 제거했다. 실제로 여전히 NSP의 필요성에 대한 토론이 진행되고 있다고 한다.
두 번째로 ELECTRA에 대해 알아봤다. 기존 BERT의 학습 효율성의 단점을 보완하기 위해 RTD(Replaced Token Detection)을 도입한 모델이다. 전체 Token중 약 15%만 학습을 하던 BERT와는 달리 Discriminator구조를 사용함으로 모든 Token에 대해 학습하는 효과를 얻을 수 있으며 보다 높은 성능을 보이는 모델이다.
따라서 우리가 가지고 있는 컴퓨터 리소스 대비 좋은 효율을 낼 수 있다고 생각했으며 모든 Token에 대해서 사전학습하는 기법 때문에 BERT보다 더 높은 성능과 RoBERTa기반 모델의 다양한 실험과와 앙상블의 효과를 기대하기 위해 ELECTRA를 선택했다.
모델 개선
Feature embedding
사용한 Feature들 중 문장의 출처가 기록되어 있는 source를 모델에 사용하기 위한 embedding을 실험했다. 이 아이디어는 BERT의 positional embedding에서 얻을 수 있었다.
source데이터는 크게 rtt는 0으로 sampled는 1로 변환하여 embedding layer를 통해 ELECTRA모델의 차원과 동일하도록 하였으며 해당 벡터를 CLS토큰 벡터에 더해주는 방식으로 실험했다.
결과
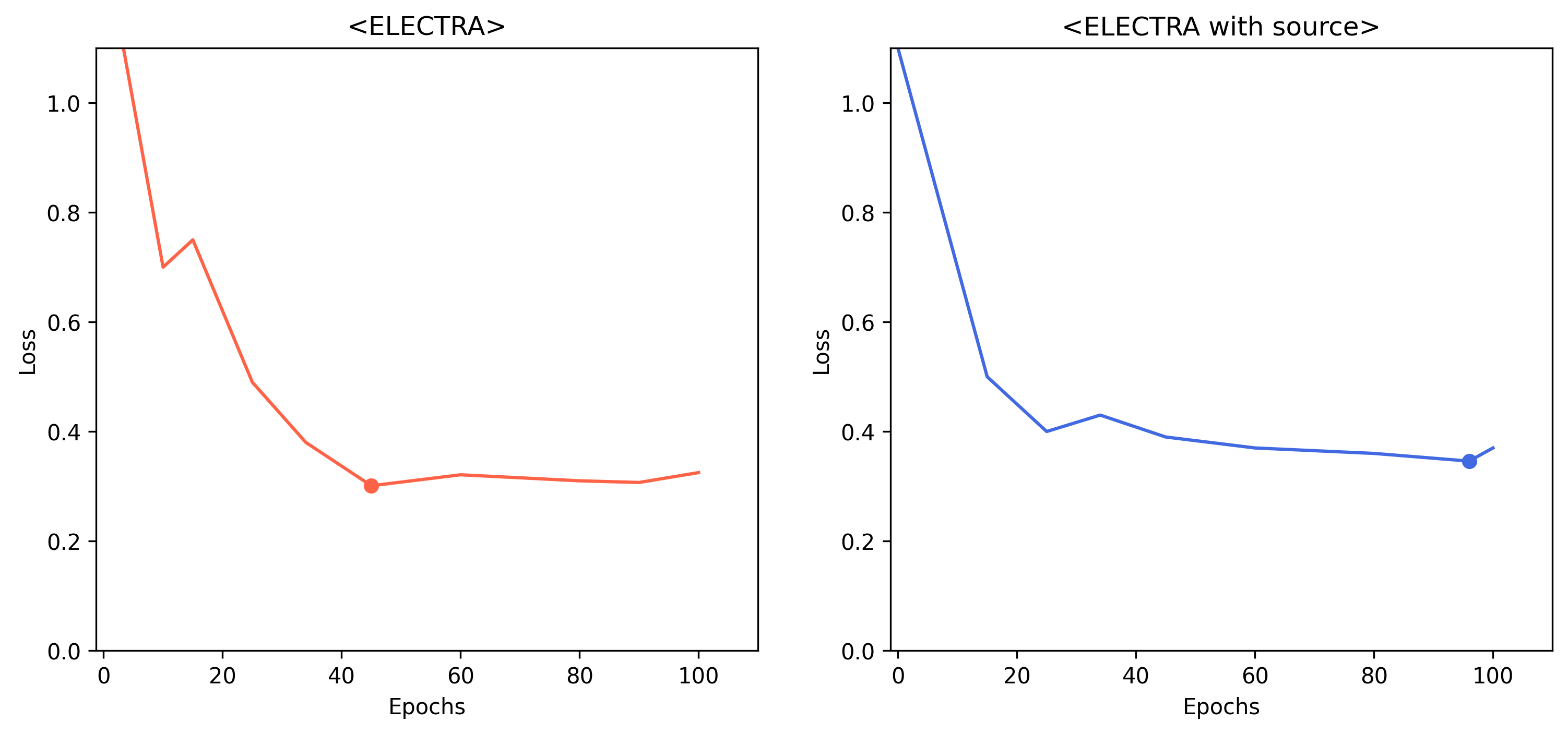
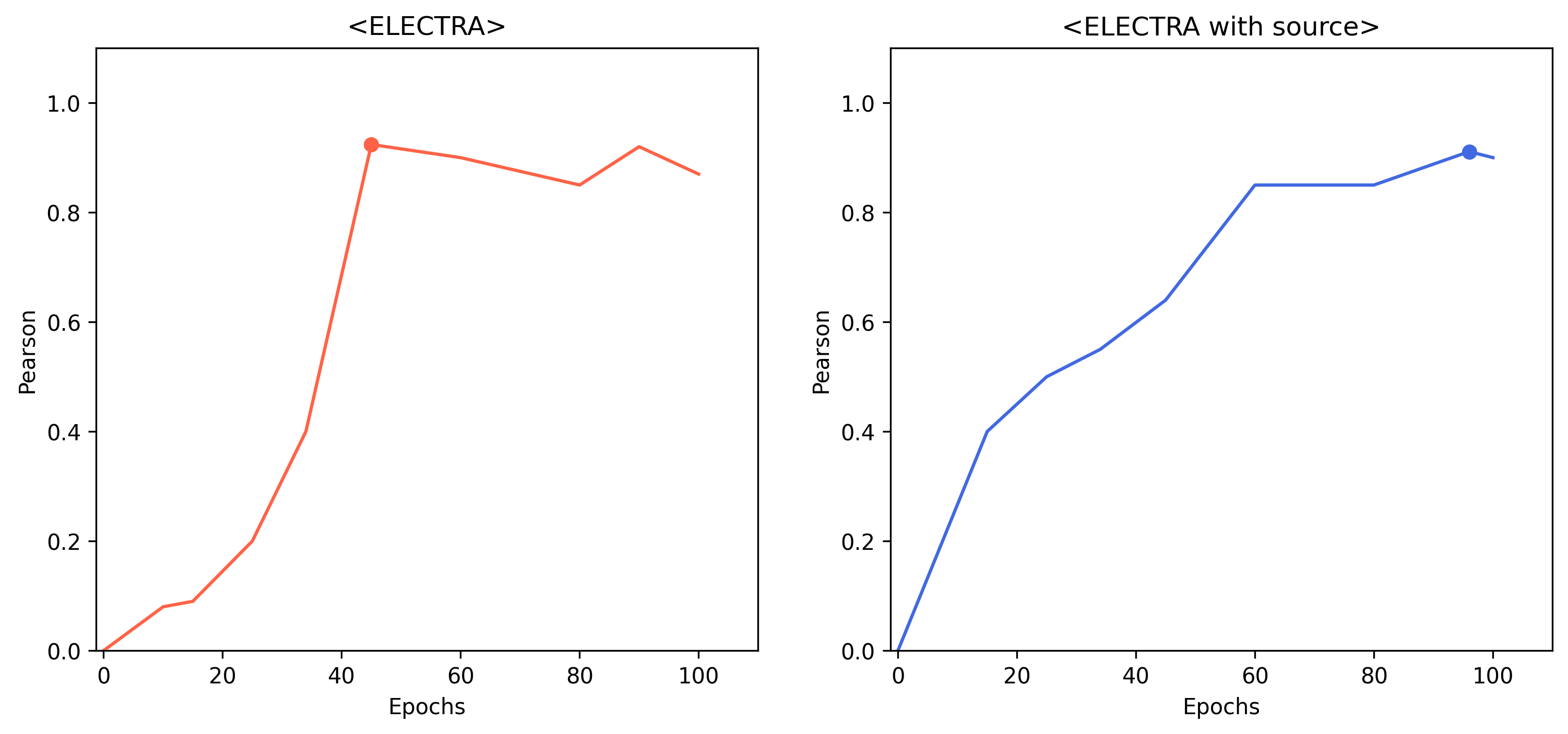
아쉬웠던 점
내가 사용했던 모델들은 NSP가 제거되었거나 segment 정보가 없이 사전학습된 모델을 사용했다.
문장간의 유사도를 구해야하는 특성상 이 정보가 굉장히 중요한 효과를 낼거라고 생각했는데 프로젝트 진행 시간이 부족해 다른 모델들을 적용해보지 못했다.
최종 private 데이터에 대한 성능으로 source피처를 사용한 모델의 성능이 꽤나 높아졌다. public 데이터에 대해서는 성능에서는 다소 성능이 떨어져보였지만 실제로 일반화 능력이 높은것으로 판단된다. 순위에만 집착하지 않았다면 이 모델을 조금 더 정교하게 만들 수 있었을거 같았는데 많이 아쉬운 시간이었다.
다양한 시도 및 생각해볼 점
-
Loss function (L1, Smooth L1, MSE, Huber)
-
다양한 models (T5 ...)
-
multi task 방식으로 접근하여 여러가지 loss를 사용해보기
-
다른 모델에 비해 이만큼 성능이 나온 구체적 이유는 무엇일까?
정량적인 분석도 중요하지만 정성적인 분석도 매우 중요함
