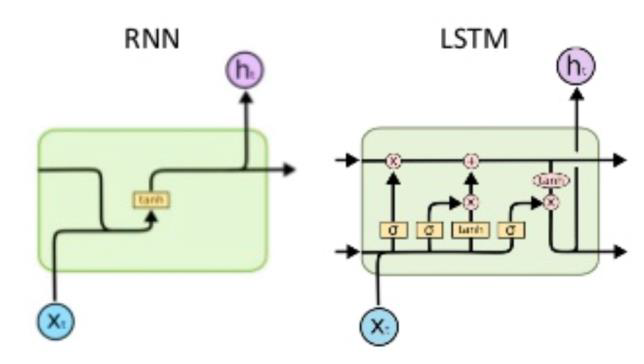
Long Short-Term Memory
-
단기기억을 담당하는 hidden state를 조금 더 길게 유지하기 위해 cell state를 도입하여 long time step에도 효과적으로 전달하려는 목적
-
-
2가지 state 중 cell state vector가 더 정확한 벡터이고 cell state를 한번 더 가공하여 hidden state vector가 된다.
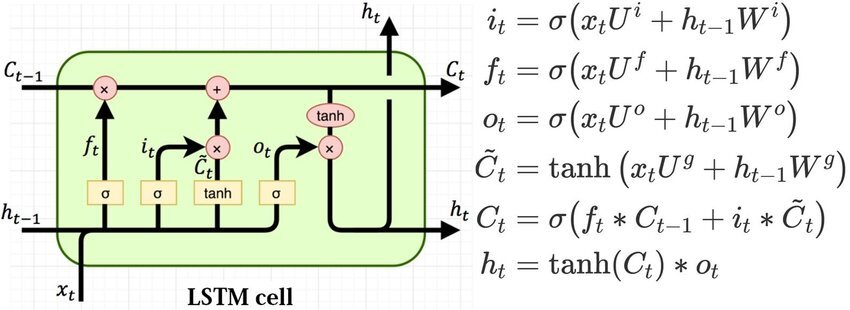
-
: Forget gate, Whether to erase cell
-
: Input gate, Whether to write to cell
-
: Gate gate, How much to write to cell
-
: Output gate, How much to reveal cell
각 Gate들은 이전 time step의 를 적절하게 조율하여 계산하게 된다.
와 , 는 를 만들기 위한 작업이라면 은 를 만들기 위한 작업이다.
-
: 기억해야할 모든 정보를 담고 있다.
-
: 현재 step에서 output 정보로 사용하기 때문에 지금 당장 필요한 정보만을 필터링한다고 이해할 수 있다.
Gated Recurrent Unit
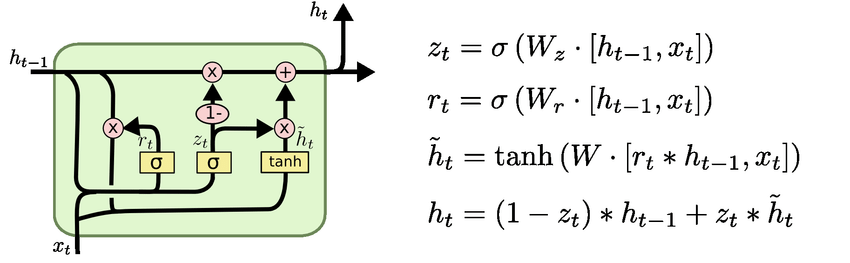
GRU는 LSTM을 경량화하여 더 적은 메모리를 사용하여 빠르게 계산할수 있도록 만든 모델이다.
큰 차이점은 cell state와 hidden state를 일원화하여 만을 사용한다.
LSTM에서 cell state update는 아래와 같다.
GRU에서는 forget gate를 사용하지 않고 input gate만 사용한다.
input gate인 를 사용하고 이 값은 0에서 1사이의 값을 가지고 있기 때문에 가 forget gate를 대체하여 사용한다.
Backpropagation in LSTM/GRU
정보를 담는 주체인 cell state vector가 업데이트되는 과정이 RNN에서 처럼 와 같은 가중치를 계속 곱해주는 형태가 아니라 forget gate를 행렬곱이 아닌 아다마르 곱을 하고 필요한 정보를 곱셈이 아닌 덧셈을 통해 만들기 때문에 vanishing/exploding의 문제가 감소하는 것을 기대할 수 있다.
Tip
RNN, LSTM, GRU를 실제로 사용할때는 layer의 개수와 단방향, 양방향을 설정할 수 있는데 이 설정에 따라 hidden state의 shape가 (num layer * direction, batch, hidden dim)이 되는 것에 주의한다. 여기서 direction은 단방향이면 1, 양방향이면 2의 값을 갖는다.
