Precision and recall
Reference : Half of my heart is in Havana ooh na na
Predicted : Half as my heart is in Obama ooh na
F measure는 2가지의 기준으로 구한 결과들의 조화평균을 구한 값을 의미한다.
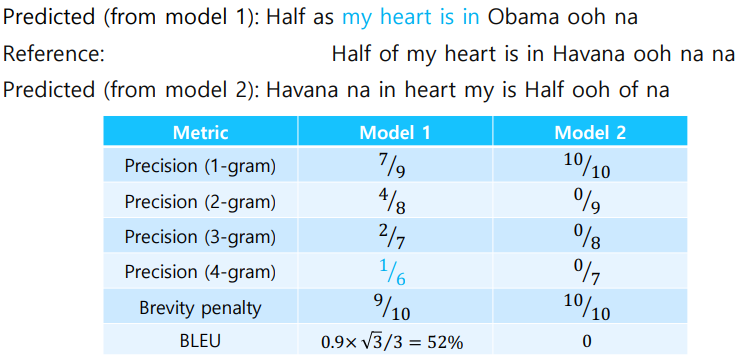
위의 지표들의 가장 큰 문제점은 correct words들은 순서를 고려하지 않는점이다. 가령 reference와 같은 단어들이 뒤죽박죽 섞여있어도 지표점수가 높아진다는 말이다. 이런 문제점을 보완한 지표가 바로 BLEU score이다.
BLEU score
- BiLingual Evaluation Understudy(BLEU)
BLEU score는 개별단어의 overlap보다 더 나아가 N-gram overlap 방식을 사용한다.
이 방식은 연속된 2개 혹은 n개의 연속된 phrase로 봤을때 얼마나 겹치는지를 계산하게 된다.
BLEU score는 precision만을 고려하게 된다. 그 이유는 2개의 지표의 특징차이 때문에 그렇다.
-
recall : groud truth의 요소들을 전부 담고 있는지.
-
precision : 예측값이 groud truth와 얼마나 유사한지.
example
reference : I love this movie very much.
prediction : 나는 이 영화를 많이 사랑한다.
이런 결과에서 very에 상응하는 매우 결과가 없다. 하지만 높은 수준의 결과로 판단할 수 있는데 recall입장에서는 reference의 요소가 얼마나 포함되어 있는지이고 precision은 prediction의 요소들 중 얼마나 reference가 포함되어 있는지의 차이가 있기 때문에 BLEU는 precision만을 이용한다.
BLEU score는 N을 1부터 4까지로 변경하며 precision을 전부 구하고 기하평균을 내는 지표이다. 수식의 term은 brevity penalty를 의미하는데 reference길이보다 조금 더 짧은 문장을 예측한 경우에는 그 비율을 선택하고, 더 길게 예측한 경우 1을 선택하여 곱해주게 된다.
brevity penalty는 길이에 따라 precision값을 조정하는 파라미터이다. 이 항은 recall을 조금 더 simple한 형태로 변형시킨것으로 봐도 무방하다.