Definition of Bias
Bias의 종류
Bias in Learning
-
학습할 때 과적합을 막거나 사전 지식을 주입하기 위해 특정 형태의 함수를 선호하는 것 (Inductive bias)
-
우리가 모델을 만들 때, 이 모델은 우리가 원하는 output을 내놓도록 유도하는 것 자체가 bias가 될 수 있다. 이 bias가 나쁘다는 것이 아니라 우리가 이런 bias가 있다는 것을 인지하고 있어야 한다.
A biased World
-
현실 세계가 편향되어 있기 때문에 모델에 원치 않는 속성이 학습되는 것 (historical bias)
-
성별과 직업 간 관계 등 표면적인 상관관계 때문에 원치않는 속성이 학습되는 것(co-occurrence bias)
Bias in Data Generation
-
입력과 출력을 정의한 방식 때문에 생기는 편향(specification bias)
-
데이터를 샘플링한 방식 때문에 생기는 편향(sampling bias)
-
어노테이션의 특성 때문에 생기는 편향(annotator bias)
Gender Bias
-
대표적인 bias 예시
-
특정 성별과 행동을 연관시켜서 예측 오류가 발생하는 경우
- 요리를 하고 있는 사진에서 사람을 여자로만 구분
- 구글 번역기에서 어떤 사람은 의사이다. 라는 성별을 지칭하지 않는 문장을 번역하면 He is doctor로 번역이 됨
Sampling Bias
-
리터러시 다이제스트 여론조사(1936년)에서 240만 명을 대상으로 당시 대통령 당선 여론조사 실행
-
예측으로 루즈벨트 43%, 알프레드 랜던 57%로 예측
-
실제로 루즈벨트 62%, 알프레드 랜던 38% 였는데 이렇게 큰 차이를 내는 이유는 설문 대상이 중산층 이상으로만 표본을 구성했기 때문에 sampling에 문제가 있었다.
-
2년 후 리터러시 다이제스트는 파산하게 된다.
Bias in Open-domain Question Answering
Retriever-Reader Pipeline
Information Retrieval(Retriever) + Reading Comprehension(Reader)으로 이루어져 있으며 우리는 reader쪽의 bias를 살펴본다.
Training bias in reader model
만약 reader 모델이 한정된 데이터셋에서만 학습이 된다면 reader는 항상 정답이 문서 내에 포함된 데이터쌍(Positive)을 보게 된다.
이렇게 학습된 모델에 데이터 내에서 찾아볼 수 없었던 새로운 문서를 준다면 문서에 대한 독해력은 매우 떨어지며 정답을 내지 못할 수 있다.
그렇다면 이런 문제는 어떻게 해결을 해야되는지 알아보자.
- Train negative examples
훈련할 때 잘못된 예시를 보여줘야 retriever이 negative한 내용들은 먼 곳에 배치할 수 있다. negitive sampling도 positive와 비슷한 negative도 고려할 필요가 있다.
높은 BM25/TF-IDF 스코어를 가지지만 답을 포함하지 않거나 같은 문서에서 나온 다른 Passage/Question을 선택하는 방법이 있다.
- Add no answer bias
입력 시퀀스의 길이가 N일시, 시퀀스의 길이 외 1개의 토큰이 더 있다고 생각한다. 훈련 모델의 마지막 레이어 weight에 훈련 가능한 bias를 하나 더 추가하여 학습하며 softmax로 start end 확률이 해당 bias 위치에 있는 경우가 가장 높은 확률이 되면 "No Answer"로 취급한다.
Annotation Bias from Datasets
what is annotation bias?
데이터셋을 제작할 때 발생하는 bias로 이해할 수 있다.
ODQA를 학습할 때 MRC 데이터셋을 활용하게 되는데 실제로 ODQA Task에 적합하지 않는 bias가 발생할 수 있다.
실제 ODQA 시나리오는 유저가 질문에 대한 답을 모르는 경우에 질문을 하는 상황인데 실제 데이터셋은 그렇지 않기 때문에 원치 않는 편향이 발생한다.
예를들어 SQuAD의 경우 질문을 하는 사람이 답을 알고 있기 때문에 질문에 포함된 단어와 evidence문단 사이의 많은 단어들이 겹치는 bias가 발생한다.
결국 지문에 매우 의존적인 질문만 처리할 수 있는 모델이 될 수 있다.
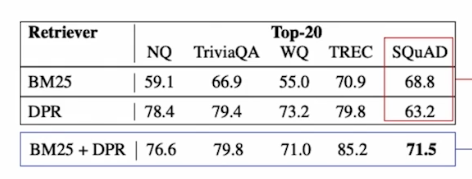
실제로 BM25와 DPR의 경우 DPR이 성능이 더 잘나오는 모델이지만 SQuAD 데이터셋에서는 BM25가 더 높은 성능을 나타낸다.
따라서 이런 bias를 없애는 것이 좋은 MRC 데이터셋을 만드는 것이라고 할 수 있고 이를 인지하여 데이터를 수집해야 한다.
