
지난 시간에는 데이터베이스 설계 단계에서 2단계인 개념적 설계(E-R diagram)에 대해서 알아보았습니다. 이번 시간에는 E-R 다이어그램을 기반으로 논리적 스키마를 설계하는 논리적 설계단계에 대해 알아보겠습니다.
1. 관계 데이터 모델의 개념
1.1. 관계 데이터 모델의 기본 용어

개념적 구조를 논리적 구조로 표현하는 데이터 모델을 관계 데이터 모델이라고 합니다. 일반적으로 하나의 개체에 대한 데이터를 하나의 릴레이션에 저장합니다.
릴레이션(relation)은 데이터들을 2차원 테이블 구조로 표현한 것을 의미합니다.
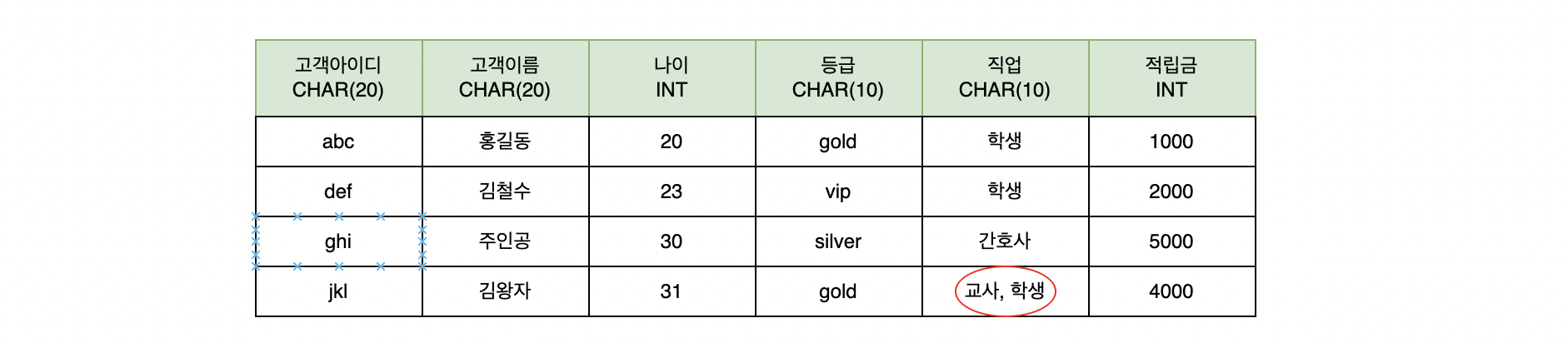
속성(attribute)은 릴레이션의 열을 나타내고 있습니다. 위의 그림은 고객 릴레이션을 나타내고 있습니다. 해당 릴레이션의 열은 고객아이디, 고객이름, 나이 등와 같은 속성에 대한 정보를 표현합니다.
도메인(domain)은 하나의 속성이 가질 수 있는 모든 값의 집합을 의미합니다. 속성 값을 입력하거나 수정할 때 적합성의 판단 기준이 됩니다.
널(null)은 속성 값을 아직 모르거나 해당되는 값이 없음을 표현합니다.
차수(degree)는 하나의 릴레이션에서 속성 전체의 개수를 의미합니다.
튜플(tuple)은 릴레이션의 행을 의미합니다. 즉, 인스턴스를 의미합니다.
카디널리티(cardinality)는 하나의 릴레이션에서 튜플 전체의 개수를 의미합니다.
Q1. 위의 그림의 릴레이션의 차수는 ? : 6
Q2. 위의 그림의 카디널리티는 ? : 4
1.2. 릴레이션의 구성
- 릴레이션 스키마 (relation schema)
릴레이션의 논리적 구조로 릴레이션의 이름과 릴레이션에 포함된 모든 속성 이름으로 정의됩니다. 위의 그림은 고객 릴레이션과 고객 아이디, 이름, 나이, 등급, 직업, 적립금의 속성의 릴레이션 스키마로 이루어져 있다고 할 수 있습니다. 릴레이션 스키마는 변하지 않기 때문에 정적인 특징이 있습니다.
- 릴레이션 인스턴스 (relation instance)
어느 한 시점에 릴레이션에 존재하는 튜플들의 집합을 의미합니다. 과거에 고객 릴레이션에는 100개의 튜플로 구성되어 있었지만 현재는 10만명으로 늘어날 수 있습니다. 따라서 인스턴스는 동적인 특징을 가지고 있습니다.
Q1. 위의 그림에서 릴레이션 스키마는 ? : 첫번째 행
Q2. 위의 그림에서 릴레이션 인스턴스는 ? : 두 번째 행부터 끝 행
1.3. 데이터베이스의 구성
- 데이터베이스 스키마 (database schema)
데이터베이스 스키마는 릴레이션 스키마의 모음으로 정의됩니다.
- 데이터베이스 인스턴스 (database instance)
데이터베이스 인스턴스는 릴레이션 인스턴스의 모음으로 정의됩니다.
Q1. 데이터베이스 스키마는 ? : 고객 릴레이션의 릴레이션 스키마 + 상품 릴레이션의 릴레이션 스키마
Q2. 데이터베이스 인스턴스는 ? : 고객 릴레이션의 릴레이션 인스턴스 + 상품 릴레이션의 릴레이션 인스턴스
1.4. 릴레이션의 특성
-
튜플의 유일성 : 하나의 릴레이션에는 동일한 튜플이 존재할 수 없다.
-
튜플의 무순서 : 하나의 릴레이션에서 튜플 사이의 순서는 무의미하다.
-
속성의 무순서 : 하나의 릴레이션에서 속성 사이의 순서는 무의미하다.
-
속성의 원자성 : 속성 값으로 원자 값만 사용할 수 있다. E-R 다이어그램에서 처럼 다중값 속성을 사용할 수 없다.
1.5. 키(key)

릴레이션에서 튜플들을 구별할 수 있는 유일한 속성 또는 속성들의 집합을 의미합니다.
키의 특성
유일성(uniqueness) : 하나의 릴레이션에서 모든 튜플은 서로 다른 키 값을 가져야 한다.
최소성(minimality) : 꼭 필요한 최소한의 속성들로만 키를 구성해야 한다.
키의 종류
슈퍼키 (super key)
슈퍼키는 유일성을 만족하는 속성 또는 속성들의 집합입니다. 예를 들어, 고객 릴레이션에서 고객아이디, (고객아이디, 고객이름), (고객이름, 주소) 등 최소성은 만족하지 않더라도 유일성은 만족하는 속성 및 속성 집합을 의미합니다.
후보키 (candidate key)
후보키는 유일성과 최소성을 만족하는 속성 또는 속성들의 집합입니다. 고객 릴레이션에서는 고객아이디만으로도 유일성과 최소성을 만족하기 때문에 후보키는 고객아이디가 됩니다.
기본키 (primary key)
후보키 중에서 기본적으로 사용하기 위해 선택한 키를 의미합니다. 기본키는 널값이 포함되거나 값이 자주 변경되는 속성이 포함된 후보키는 부적합하며 최대한 단순한 후보키를 선택하게 됩니다.
예를 들어, 후보키는 고객아이디, (고객이름, 주소)와 같은 속성들이 존재했습니다. 두 가지 중 (고객이름, 주소)의 경우 주소는 자주 변경될 수 있는 속성이기 때문에 기본키로 적합하지 않습니다. 또한 최대한 단순한 후보키를 선택하므로 고객아이디만으로 기본키를 선택하는 것이 적합합니다.
대체키 (alternate key)
기본키로 선택되지 못한 키를 의미하며 위의 예시에서 (고객이름, 주소) 후보키가 됩니다.
외래키 (foreign key)

릴레이션과 릴레이션은 서로 간의 연결(관계)을 맺게 됩니다. 이때 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합을 의미합니다.
참조하는 릴레이션(주문 릴레이션)은 외래키를 가진 릴레이션이며 참조되는 릴레이션(고객 릴레이션)은 외래키가 참조하는 기본키를 가진 릴레이션입니다. 주의할 점은 외래키 속성과 그것이 참조하는 기본키 속성의 이름은 달라도 되지만 도메인은 같아야 합니다.
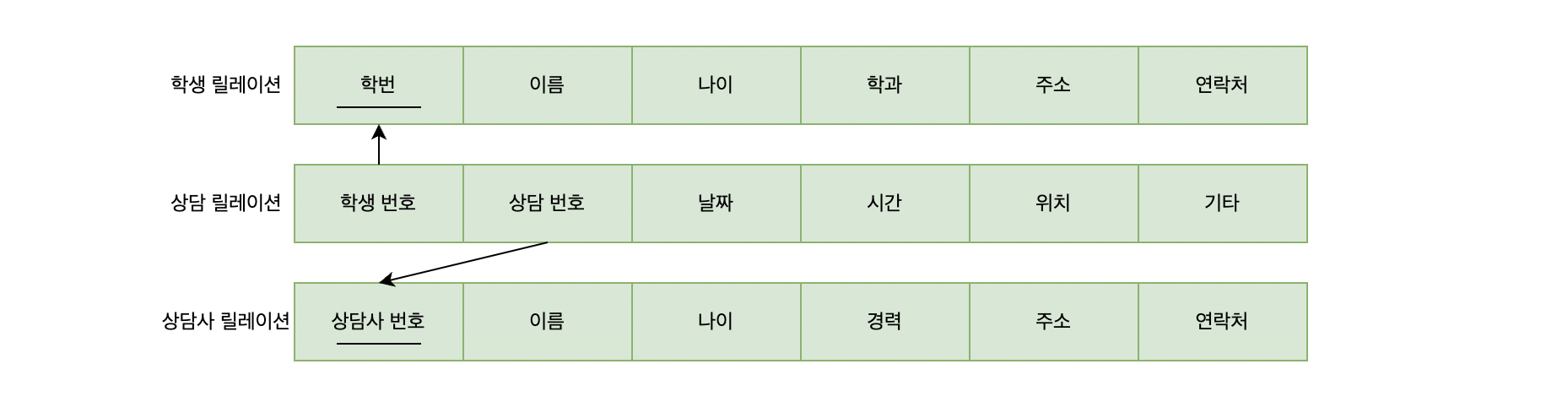
하나의 릴레이션은 여러 개의 릴레이션과 연결될 수 있으므로 하나의 릴레이션은 외래키가 여러 개 존재할 수도 있습니다. 또한 외래키 또는 외래키 집합을 기본키로 사용할 수도 있습니다.

같은 릴레이션의 기본키를 참조하는 외래키를 정의할 수도 있습니다. 만약 추천고객이라는 속성은 추천해준 고객 아이디의 값을 가지게 된다면 현재 기본키의 고객아이디를 참조할 수 있습니다. 또한 추천 받지 않은 경우 널 값을 가지게 되며 이는 외래키의 특징입니다.
2. 관계 데이터 모델의 제약
2.1. 무결성 제약조건 (integrity constraint)
무결성 제약조건은 데이터의 무결성을 보장하고 일관된 상태로 유지하기 위한 규칙입니다. 여기서 무결성이란 데이터를 결함이 없는 상태(정확하고 유효함)로 유지하는 특성 의미합니다.
-
개체 무결성 제약조건 : 기본키를 구성하는 모든 속성은 널 값을 가질 수 없다. 예를 들어, 고객 아이디는 널 값을 가질 수 없다.
-
참조 무결성 제약조건 : 외래키는 참조할 수 없는 값을 가질 수 없다. 예를 들어, 주문고객의 외래키에 고객아이디에 없는 값을 가질 수 없다. 단, 외래키가 널 값을 가진다고 해서 참조 무결성 제약조건을 위반한 것은 아니다.
