
지난 시간까지 컴퓨터 간의 네트워크의 논리적인 흐름에 대해서 공부했다면 이번에는 Network 계층에서는 데이터를 어떻게 이동이 되는지 알아보겠습니다.
1. 라우터

라우터들은 Network 계층 장치로, Network 계층까지만 가지고 있기 때문에 IP packet의 형태만 이해할 수 있습니다.
1.1. 포워딩(forwarding)
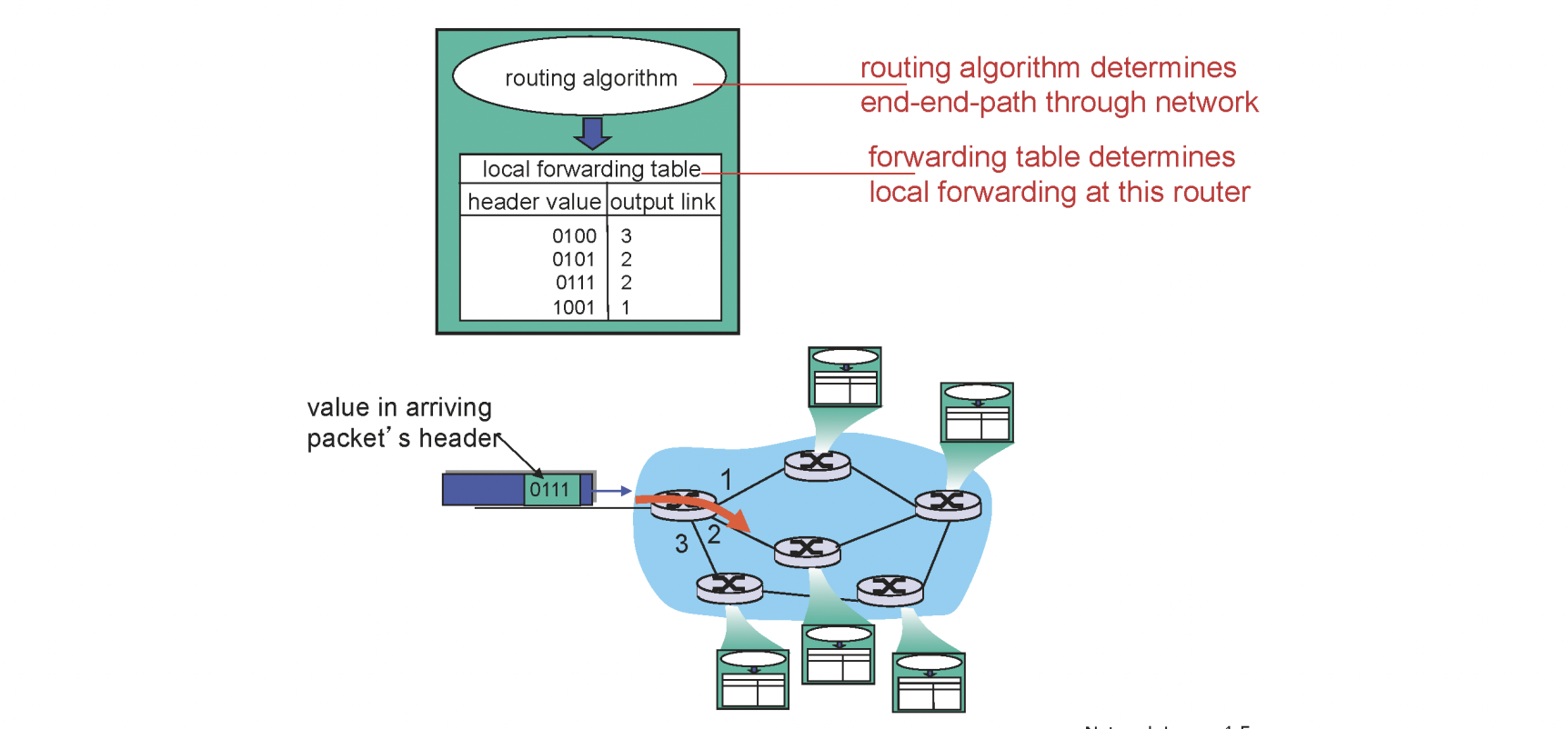
라우터의 포워딩은 단순합니다. 라우터로 들어온 패킷을 적절한 라우터로 보내는 과정입니다.
들어온 패킷에는 목적지의 주소를 가지고 있는데 라우터가 가지고 있는 포워딩 테이블을 매핑하여 이동시키는 방식을 사용합니다.
1.2. 라우팅(routing)
라우팅은 포워딩을 할때 필요한 포워딩 테이블을 만드는 역할을 하게 됩니다.

실제 포워딩 테이블을 만들때는 *표시를 사용하여 범위를 기준으로 만들게 됩니다.
위의 첫번째 주소가 들어오게 된다면 1번 엔트리에 매핑이 됩니다. 반면에 두번째 주소는 2번, 3번에 전부 매치가 되므로 가장 길게 매치되는(longest prefix) 알고리즘을 사용하여 2번 엔트리로 매핑됩니다.
1.3. 구조

라우터의 목적은 input ports(라우터에 연결되어 있는 링크들)에서 알맞은 output ports로 이동시켜 주면 되며, 라우팅 프로세서에 의해 포워딩 테이블을 만들게 됩니다.

input 포트를 자세히 살펴보면 라우팅 프로세서가 만들어준 포워딩 테이블은 각각의 포트에 독립적으로 저장되고 있기 때문에 병렬적으로 처리할 수 있습니다. 소요 시간을 빠르게 하기 위해 병렬처리를 했어도 들어오는 패킷의 양이 더 많을 수 있기 때문에 queue가 존재합니다.
2. IP (Internet Protocol)
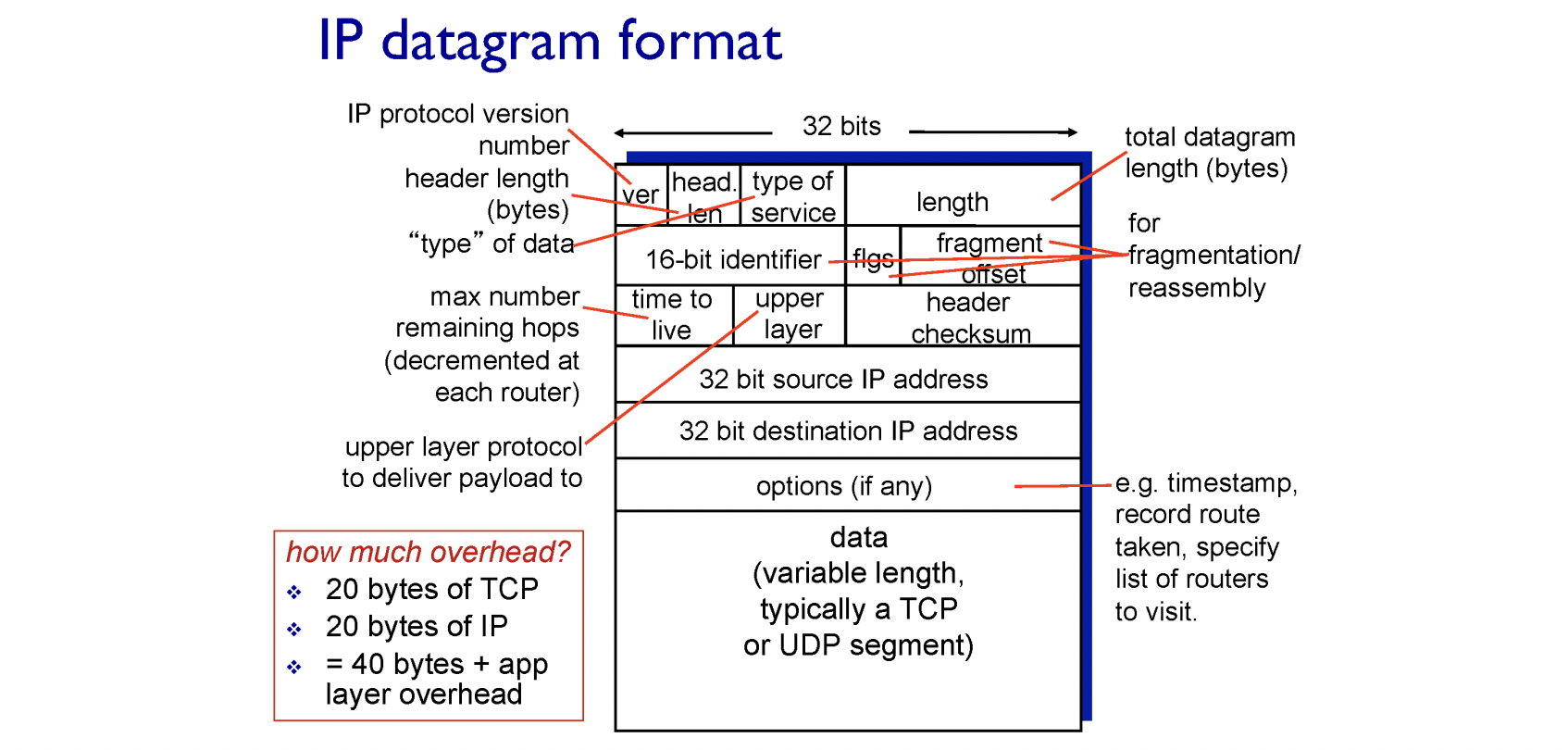
일반적으로 IP 헤더의 크기는 최소 20 bytes입니다. TCP segment의 헤더의 크기도 최소 20 bytes였기 때문에 적어도 40bytes의 오버헤드가 발생합니다.
데이터가 없이 패킷의 크기가 40bytes인 경우는 피드백을 위한 용도의 패킷으로 사용됩니다.
2.1. IP Address (IPv4)

IP를 설명할 때 보통 특정 Host를 가르키는 주소라고 설명합니다. 일반적인 상황에서는 이 설명으로 맞지만 정확한 설명은 특정 인터페이스를 지칭하는 주소가 더 정확한 설명입니다. 예를 들어, 라우터 디바이스의 경우 들어오는 인터페이스가 여러개고 나가는 인터페이스가 여러개인 장치이기 때문에 여러개의 IP 주소를 가질 수 있습니다.
scalability challenge
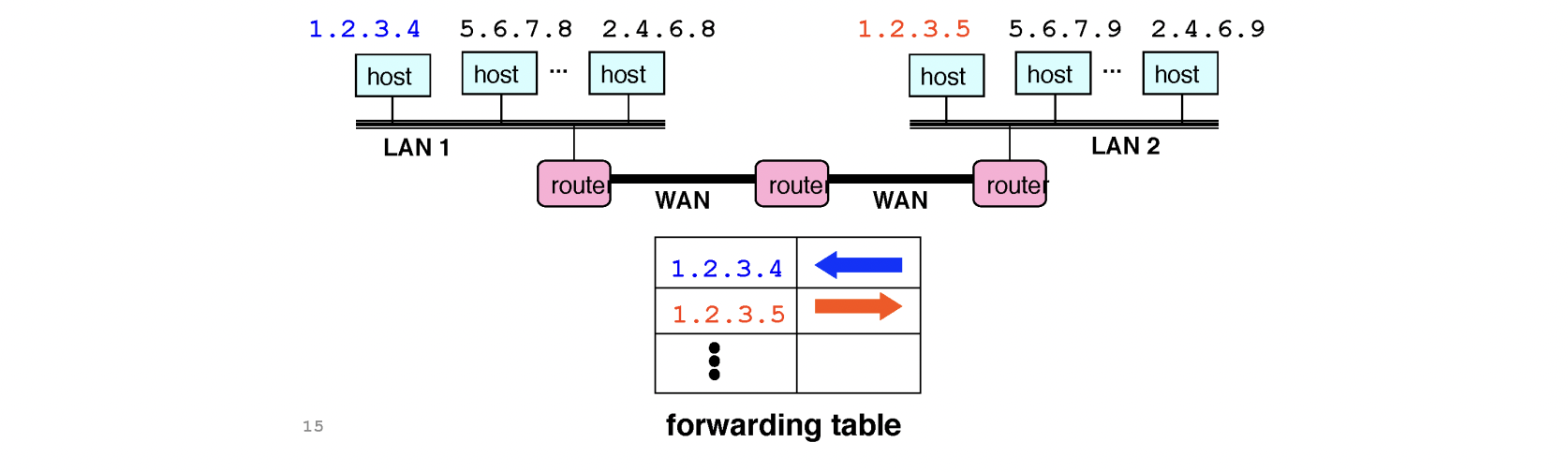
다양한 디바이스들은 결국 IP주소를 가져야 인터넷을 사용할 수 있습니다. 인터넷을 사용하기 위해 IP를 할당할 때, 개의 주소를 랜덤으로 배정하게 되면 포워딩 테이블은 각각의 매핑해야 하기 때문에 그만큼 늘어나게 됩니다.
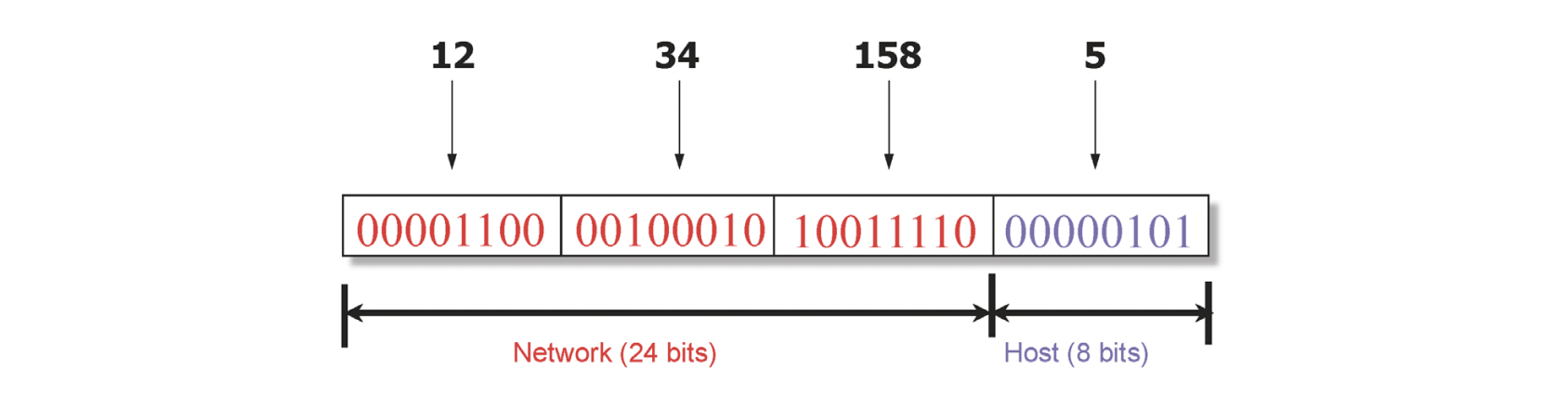

이런 문제를 해결하기 위해 앞의 24bit를 network(prefix)비트로 사용하게끔 계층화 시키게 되고 같은 네트워크(LAN)에 속한 범위를 기준으로 포워딩 테이블을 구성할 수 있습니다.
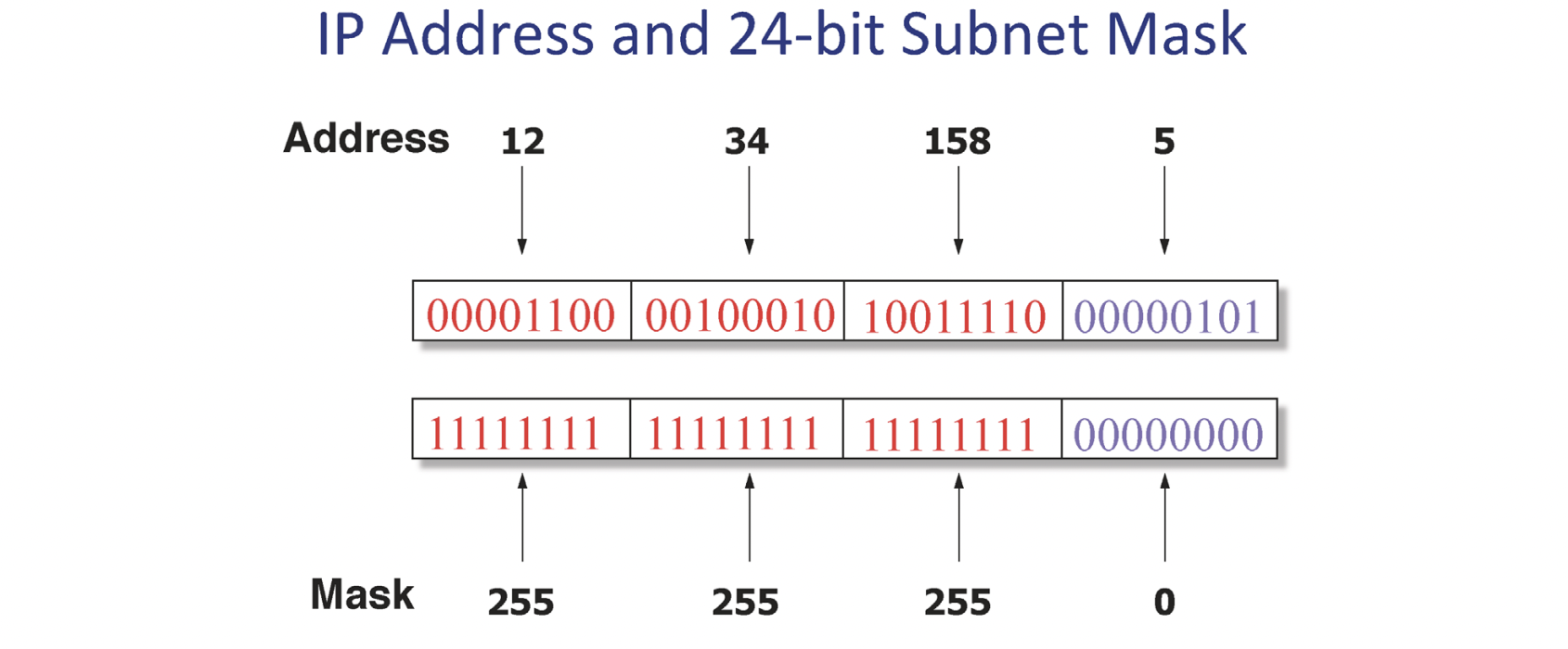
0/24는 앞의 24bit를 네트워크 bit로 사용하고 있다는 표시입니다. 컴퓨터에게 이 의미를 전달하기 위해 subnet mask를 사용하여 and 연산을 통해 네트워크 bit를 구할 수 있습니다.
classful addressing

네트워크를 구분하기 위해 24bit를 이용한다면 IP를 할당할 수 있는 host 개수는 밖에 되지 않습니다. 만약 컴퓨터가 많은 조직에서는 IP주소가 부족한 상황이 발생할 수 있습니다. 반대로 컴퓨터를 1대 밖에 사용하지 사용가능한 IP주소가 남아도는 상황이 발생합니다. 그렇다고 네트워크 비트를 8bit로 고정하게 되면 전세계의 256개의 네트워크만 존재할 수 있는 상황이 발생합니다.
과거에는 이 문제를 해결하기 위해 각 기관별로 그룹을 나눠 고정된 네트워크 bit를 할당했습니다. /8은 네트워크 bit가 8bit라는 의미입니다. 하지만 현대에 인터넷 사용량이 급증하면서 IP부족을 해결하기 위해 CIDR(classless inter-domain routing) 방식을 사용합니다.
CIDR(classless inter-domain routing)
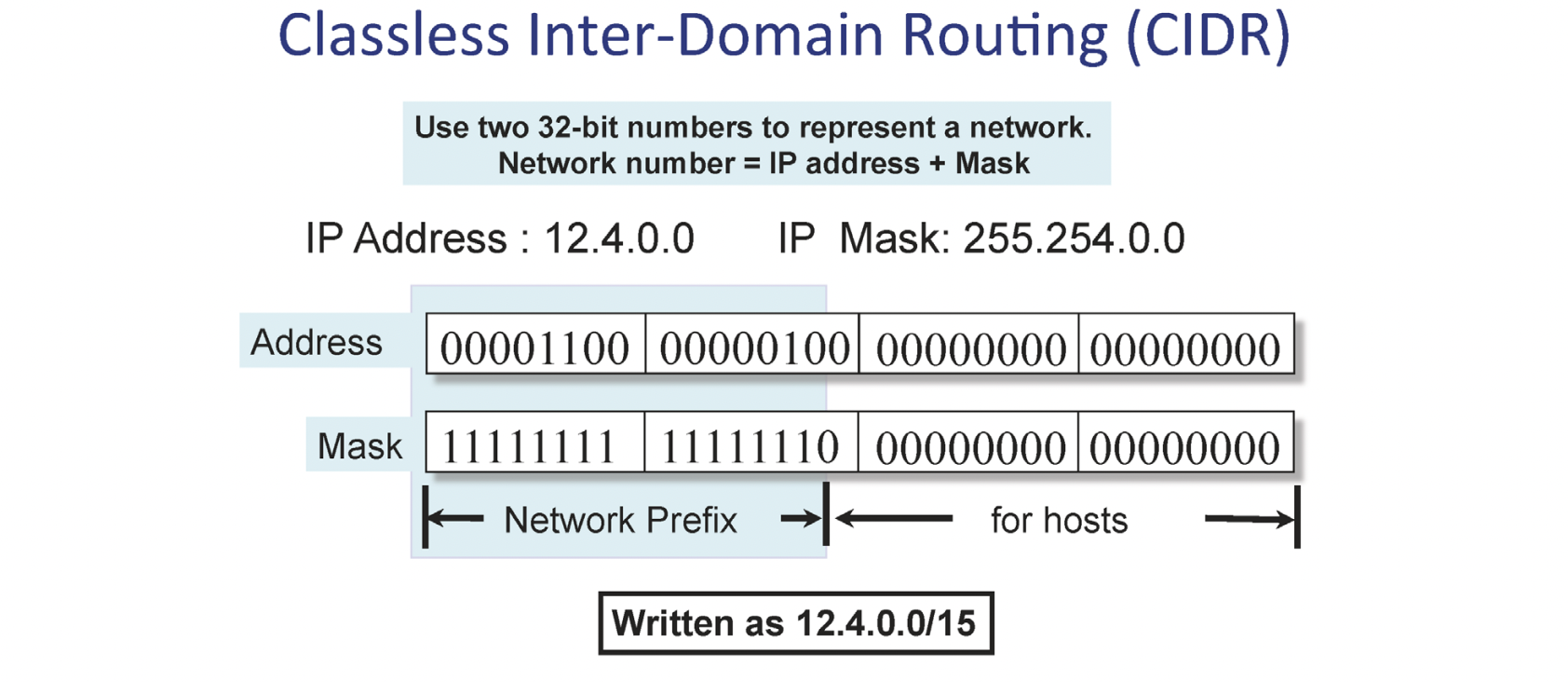
CIDR은 클래스의 구분 없이 가변적인 방식을 사용합니다. 여기서 가변적이라는 고정된(8/16/24) 크기가 아니라 기관에 알맞은 크기로 유연하게 배정하게 됩니다.
2.2. Subnets
IP는 결국 Network ID(prefix, subnet)과 host ID로 나누어 집니다. 결국 subnets이라고 하는 것은 같은 네트워크를 의미하게 됩니다. 또 다른 정의로는 라우터를 거치지 않고 접근할 수 있는 집합이라고 할 수 있습니다. 라우터 같은 경우는 여러개의 서브넷에 속해있는 디바이스라고 할 수 있습니다.
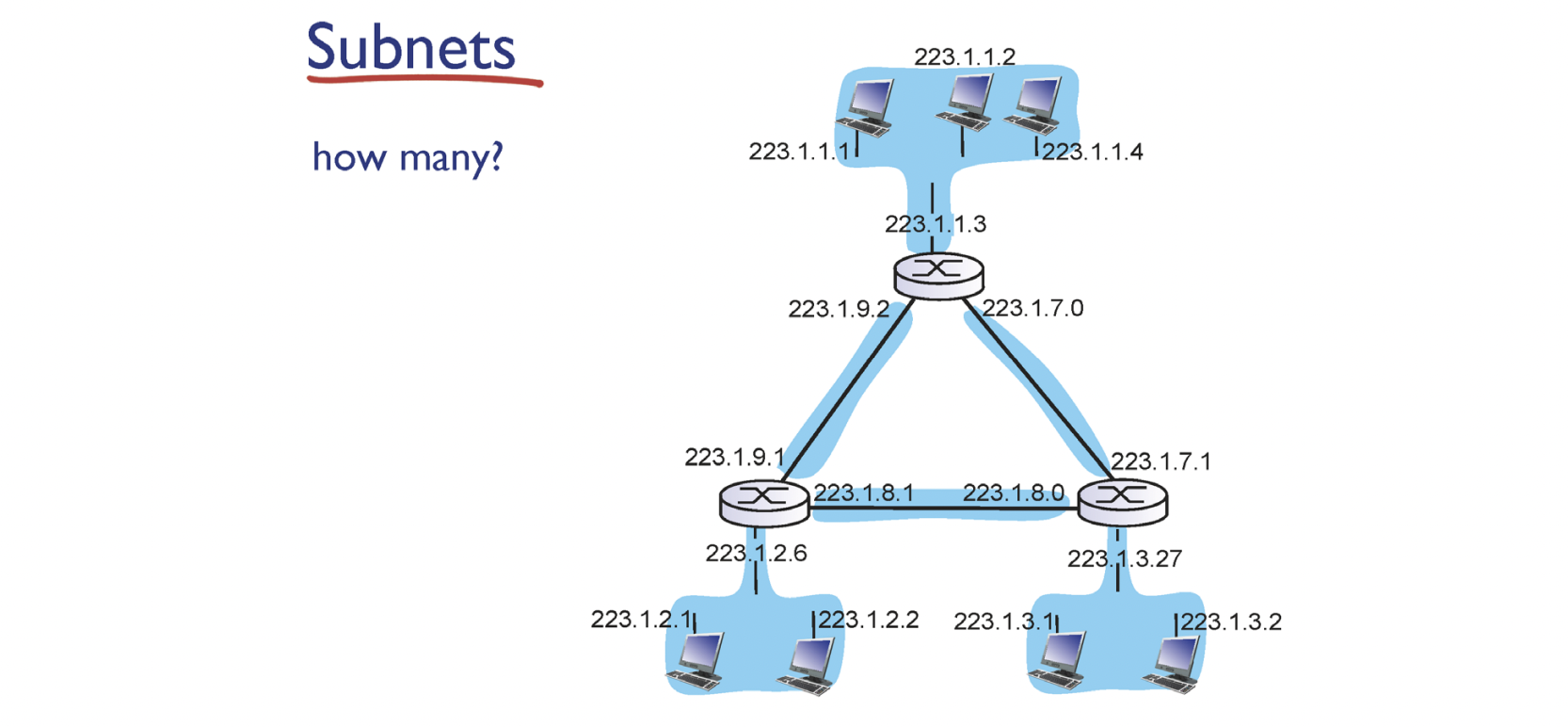
정답 : 6개
2.3. IP Address (IPv6)
IPv4는 32bit로 이루어져 있습니다. 따라서 패킷의 ip address도 32bit로 이루어져 있습니다. 하지만 시간이 지나면서 32bit(약 40억)로는 부족하여 탄생한 것이 IPv6입니다. IPv6의 패킷의 ip address는 128bit입니다. 즉 개의 호스트를 지원할 수 있습니다.
하지만 IPv6을 표준 IP로 사용하기 위해서는 모든 라우터 장비를 교체하는 문제도 있고 IPv4를 사용해도 현재 잘 동작하고 있기 때문에 IPv4를 사용하고 있습니다.
상식적으로 생각해봐도 인구수와 한명 당 가지고 있는 디바이스만 해도 IPv4가 감당할 수 있는 범위를 넘어섰지만 동작이 가능하게 해주는 것이 NAT(Network Address Translation)입니다.
2.4. NAT (Network Address Translation)
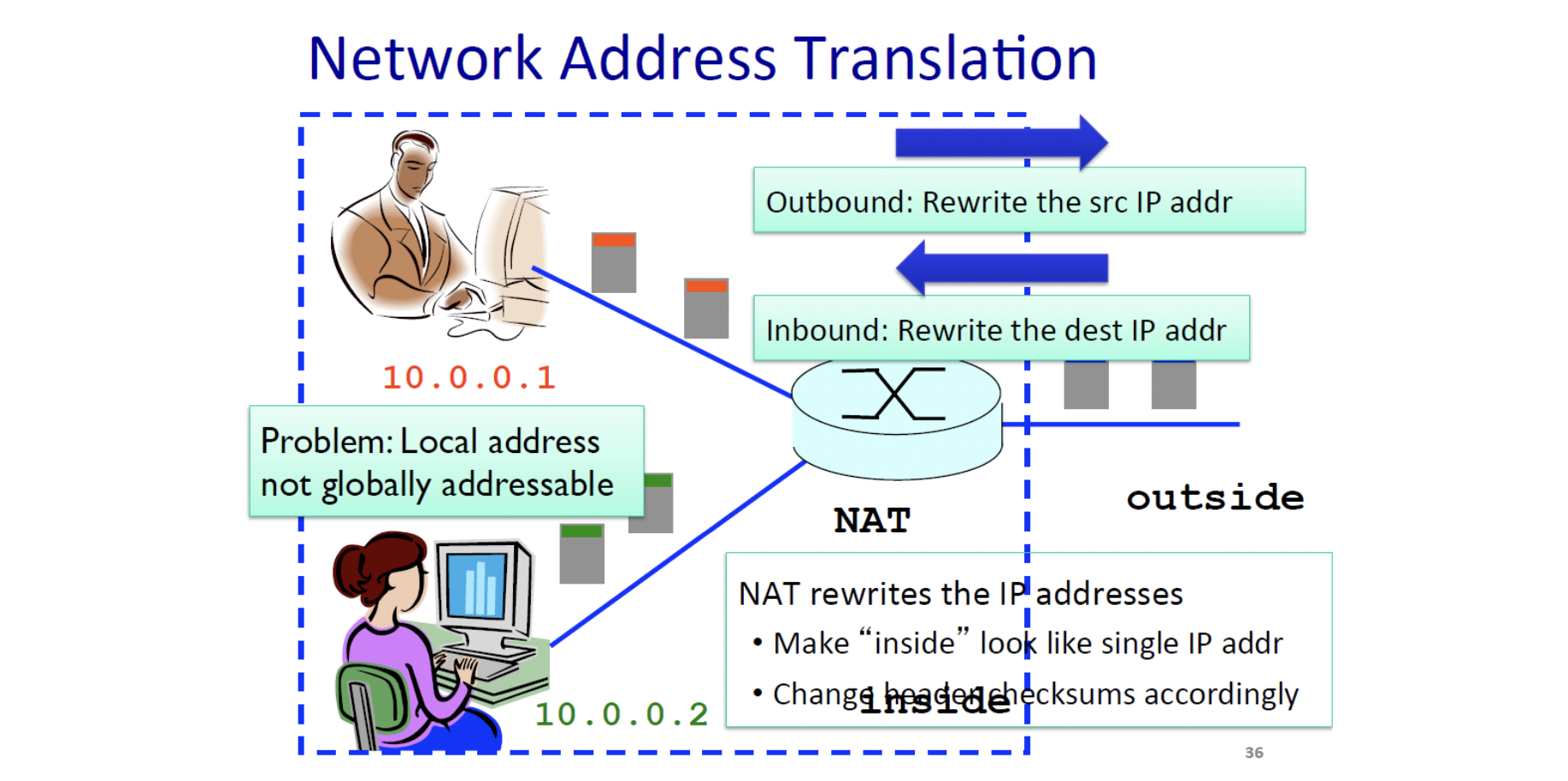
IP는 global unique한 특징을 가져야 하는데 이렇게 되면 개만 할당할 수 있습니다. NAT은 이 문제를 해결하기 위해 하나의 네트워크 안에서 쓰는 ip 주소를 외부와 통신할때는 global unique한 ip주소로 번역합니다. 이때 네트워크 안에서 사용하는 ip주소는 다른 네트워크 안에서 사용하는 ip주소와 동일할 수 있지만 외부로 나가는 ip주소는 unique합니다.

-
TCP 3-handshake의 SYN : 나갈때 gateway에서 ip 주소를 변환하고 NAT table에 저장
- port까지 변환한 이유 : 내부 ip주소는 각각 다르지만 같은 port를 사용할 수 있음
-
목적지 도착
-
gateway까지 도착하여 NAT table에 적힌 정보를 기준으로 ip 변환
-
목적지 도착
부작용
NAT를 사용하는 상황에서 만약 서버를 운영하게 된다면 부작용이 발생합니다. 만약 한국에서 살고 있는 내가 웹서버를 작동하고 미국에 사는 부모님에게 접속을 해보라고 10.0.0.1:7777을 알려준다면 접속할 수 없습니다. 여기서 만약 ip주소를 138.76.29.7로 알려주었다고 해도 접속할 수 없습니다. 그 이유는 NAT table에 번역 정보가 담기는 시점은 내부 주소가 외부로 나갈때이기 때문입니다.
또한 NAT를 사용하게 되면 패킷 헤더에 적혀있는 ip주소를 바꾸고 패킷 데이터(TCP 헤더)의 port를 수정하는 작업을 하게 됩니다. 패킷을 확인하는 것은 end-to-end에서만 확인해야하지만 중간에 NAT라는 개체가 확인하는 셈입니다. 더 나아가 디바이스를 구분해주는 역할을 ip가 아닌 port가 하고 있기 때문에 외부에서 접근하기 힘든 상황이 발생합니다.
현재 인터넷을 이용하는 대부분의 사용자들은 클라이언트 입장에서 사용하기 때문에 큰 불편함을 느끼지는 못해 IPv4를 사용하지만 근본적인 해결책은 IPv6를 사용하는 방법입니다.
3. DHCP(Dynamic Host Configuration Protocol)
나는 단순히 컴퓨터를 켰을뿐인데 어떻게 내 컴퓨터에 IP주소 얻는지 알아보겠습니다.
DHCP는 Host를 네트워크를 사용할 수 있도록 해주는 프로토콜입니다. DHCP는 사실 Application 계층의 프로토콜이지만 IP를 할당하는 역할을 하기 때문에 Network 계층에서 다루겠습니다.
직관적으로 IP를 적절히 할당해주기 위해서 현재 속한 네트워크가 보유하고 있는 IP를 한 사람에게 고정시켜 부여하는 고정 IP 방식이 있습니다. 고정 IP방식은 관리해야하는 IP주소가 클라이언트만큼 증가하게 되고, 모든 클라이언트가 계속 네트워크에 존재하는 것이 아니기 때문에 비효율적인 방식입니다.
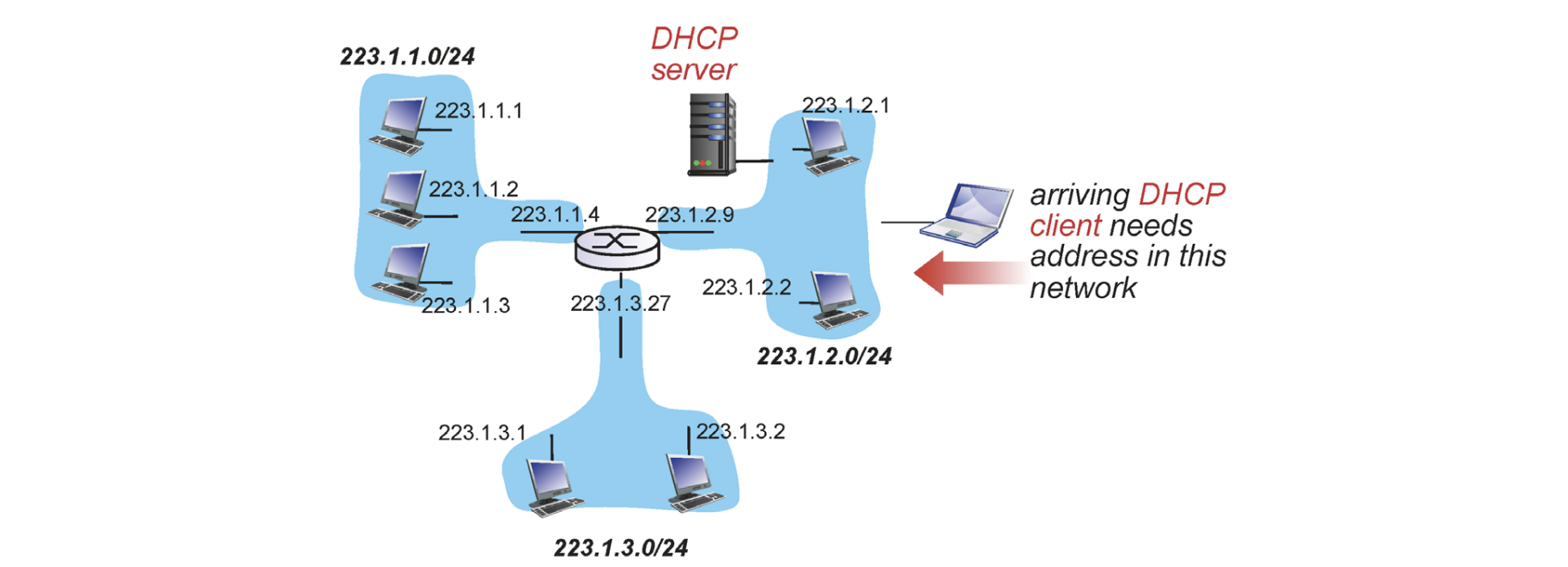
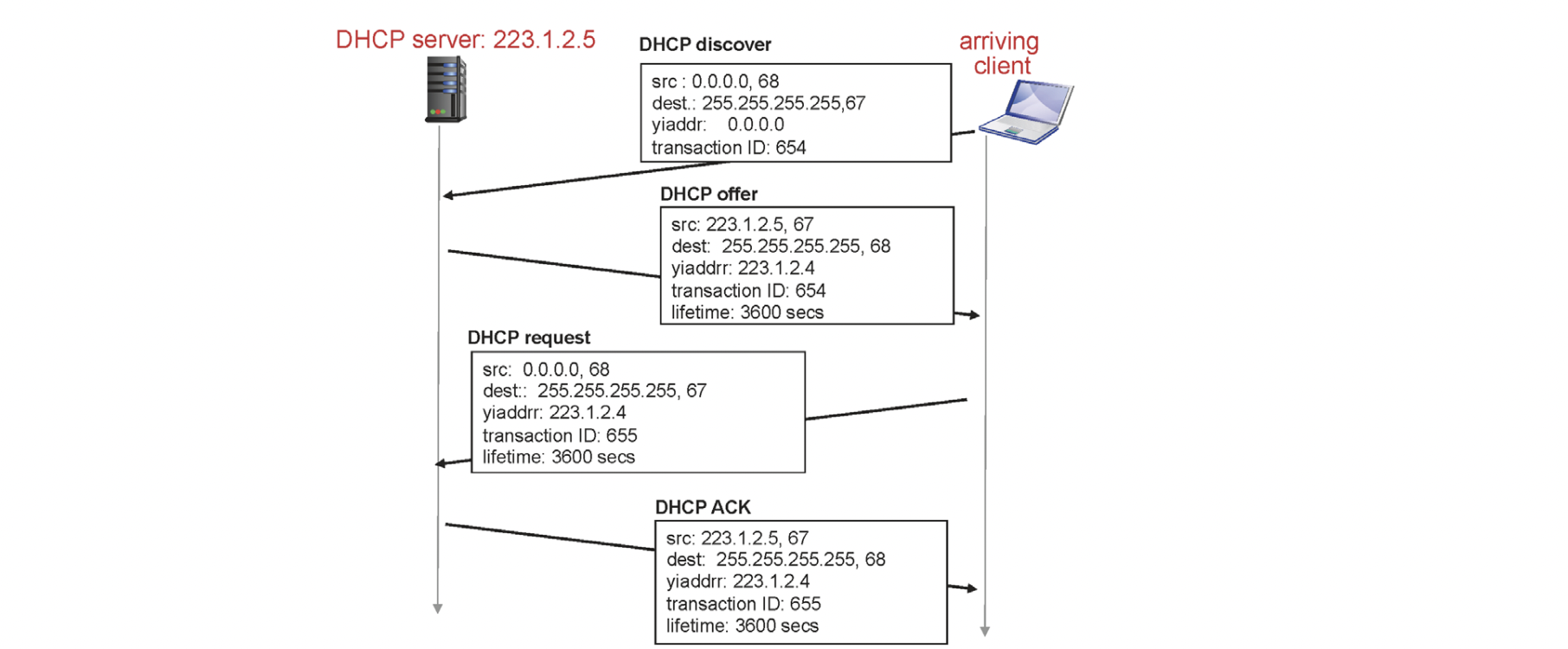
어떤 네트워크에 가더라도 DHCP 서버가 존재합니다. 보통 DHCP 서버는 68포트 클라이언트는 67포트를 사용합니다.
- discover
클라이언트는 IP주소를 할당받기 위해 255.255.255.255:67로 메세지를 송신합니다. 여기서 255.255.255.255는 브로드캐스트의 의미를 가지고 있습니다. 해당 IP로 메세지를 보내면 네트워크에 속한 모든 디바이스에게 전달되지만 67번 포트가 열려있는 곳은 DHCP뿐이기 때문에 서버만 응답을 할 수 있습니다. 소스 IP가 0.0.0.0인 이유는 현재 자신의 IP주소를 모르기 때문입니다.
- offer
서버는 요청을 보낸 클라이언트 IP가 누구인지 모르기 때문에 255.255.255.255:68로 사용 가능한 IP주소를 담아 응답을 보냅니다. 이때 포트번호로도 구분할 수 없기 때문에 transaction ID로 판단할 수 있습니다.
- request
응답을 받은 클라이언트는 서버의 메세지에 응답을 다시 보내는데 현재 주어진 IP를 사용하겠다는 의미입니다. request를 할때도 브로드캐스트로 보내는 이유는 DHCP 서버가 여러개 존재할 수 있기 때문에 요청할 offer를 제외한 나머지 DHCP 서버의 요청은 release하기 위해서 입니다.
- ACK
서버는 클라이언트의 사용요청에 응답을 해주게 됩니다.
이때 메세지는 단순히 src, dest의 IP 뿐만 아니라 서브넷 마스크, gateway router의 ip주소, DNS 서버 ip주소 정보를 같이 담아서 보내게 됩니다. 예를 들어, 집에서 컴퓨터를 사용할 때는 무선 공유기 안에 DHCP 서버가 존재해 IP주소를 할당하고 서브넷 마스크, gateway router, dns 정보를 사용자에게 전달해줍니다.
4. IP fragmentation, reassembly

IP 패킷이 생성이 되서 라우터를 통해 목적지까지 전달이 되는데 라우터들 사이의 링크들마다 지원할 수 있는 패킷의 크기가 다릅니다. 링크에서 지원해줄 수 있는 최대 사이즈를 MTU(maximum transmission unit)이라고 합니다.
만약에 패킷 사이즈보다 MTU가 더 작게 된다면 링크를 지나갈 수 없기 때문에 패킷이 쪼개집니다. 이렇게 쪼개진 패킷을 fragmentation이라고 하며 독립적으로 이동하게 됩니다.

-
4000 bytes의 IP 패킷, MTU는 1500 bytes
-
패킷 헤더가 40 bytes이기 때문에 실제 데이터는 3980 bytes
-
fragflag는 뒤에 분해된 패킷이 있는지 정보를 나타낸다. -
1500 MTU이므로 각각 세개로 fragmentation이 이루어집니다.
-
헤더 20 bytes + 1480 bytes
-
헤더 20 bytes + 1480 bytes
-
헤더 20 bytes + 1020 bytes
-
-
재조립
-
공통된
ID확인 -
fragflag로 뒤에 fragmentation이 있는지 확인 -
offset은 전체 데이터에서 어디에 위치하고 있는지 확인 (1480을 적어주지 않고 8로 나눈값 사용, 패킷 헤더의 필드크기를 줄이기 위해)
-
5. Routing Algorithm
라우터가 패킷을 최단 거리로 목적지에 보내는 방법을 알아보겠습니다.
5.1. Link state

각각의 라우터는 모든 라우터에게 라우터 정보를 브로드캐스트해서 네트워크 전체의 상태를 파악합니다. 이후 각 라우터 별로 모든 라우터까지 최단 거리를 계산하게 되는데 다익스트라 알고리즘을 사용하게 됩니다.
5.2. Distance vector

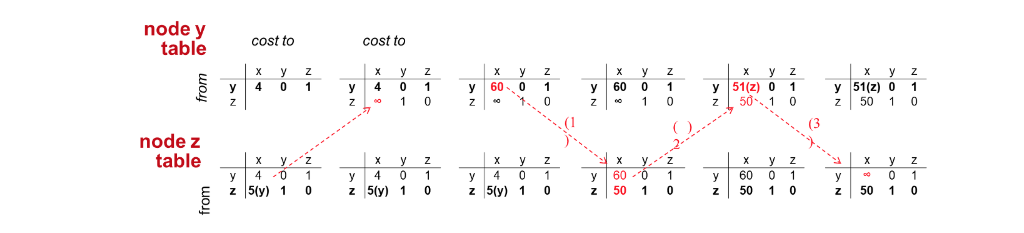
: x에서 y까지의 최단 거리
distance vector는 전체 네트워크의 그림을 모르고 현재 라우터에 인접한 상황만 할 수 있습니다. 이때 bellman-ford equation을 사용하여 distance vector를 구하게 됩니다.
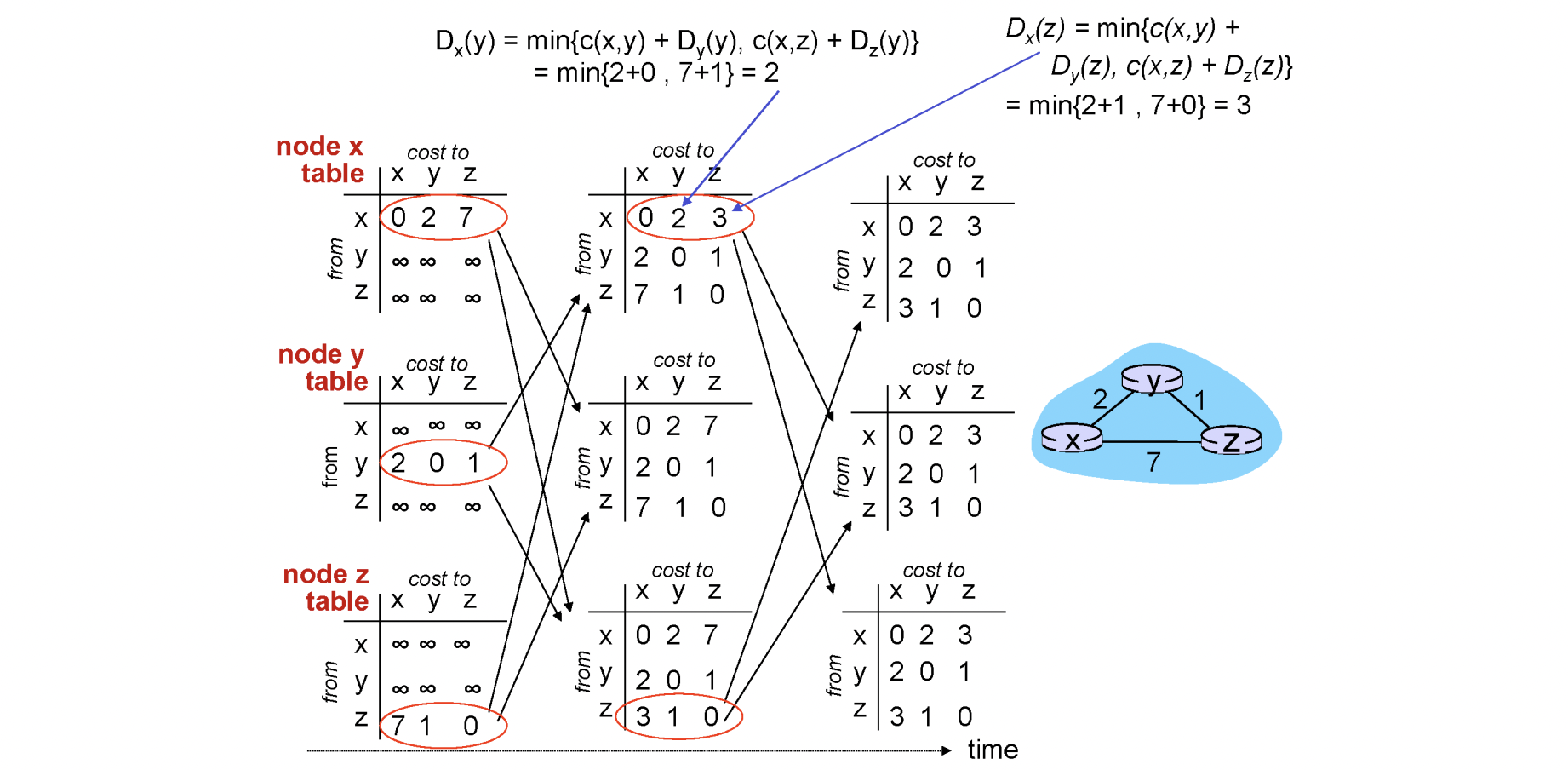
위의 그림처럼 라우터별로 인접한 라우터의 distance vector를 구하고 distance vector를 서로 교환하게 됩니다. 이때 distance vector의 변화가 없을때까지 반복하게 됩니다.
코스트의 변화

만약 위의 예시처럼 더 좋은 방향으로 링크의 비용이 변화하게 된다면 최단 비용이 구하는데 오래걸리지 않습니다.

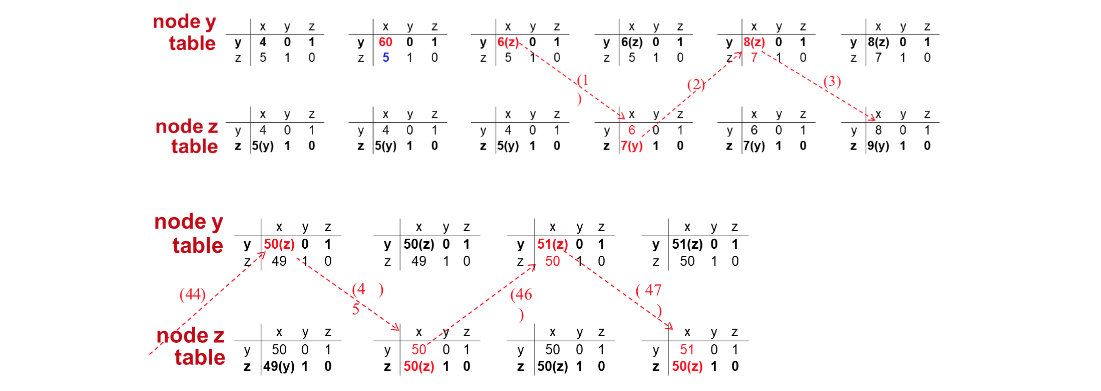
반면에, 위의 상황 처럼 링크 비용이 안좋은 방향 으로 증가하게 된다면 y에서 x가는 경로가 51이 될 때까지 distance vector가 계속 변하기 때문에 반복적으로 계산하게 됩니다.
그 이유를 살펴보면 y -> x로 가는 최단 거리를 계산할 때 y -> x vs y -> z -> y -> x를 비교하여 distance vector를 생성하게 되는데 이 상황에서 안좋은 방향으로 증가한다면 y는 y->z->y->x 잘못된 경로를 선택하는 문제가 발생합니다. 따라서 적절한 값을 계산 하기 위해 더 많은 참조를 하게되고 이를 count-infinity problem이라고 합니다.
이 문제를 방지하기 위해 최소 경로를 계산할때 결정적인 역할을 했던 이웃 라이터에게 무한대의 비용을 전달하여 마치 오염을 시켜 역류를 방지(y->z->y)한다고 하여 poisioned reverse라고 부릅니다.
5.3. Hierarchical routing
위에서 소개한 2가지 알고리즘은 현실 세계에 적용하기 힘듭니다. link state는 전체 네트워크를 파악하기 위해 많은 비용이 소모되고 distance vector는 평생 안정화가 안될 수 있습니다. 문제를 해결하기 위해 계층을 도입한 라우팅 방식을 사용합니다.
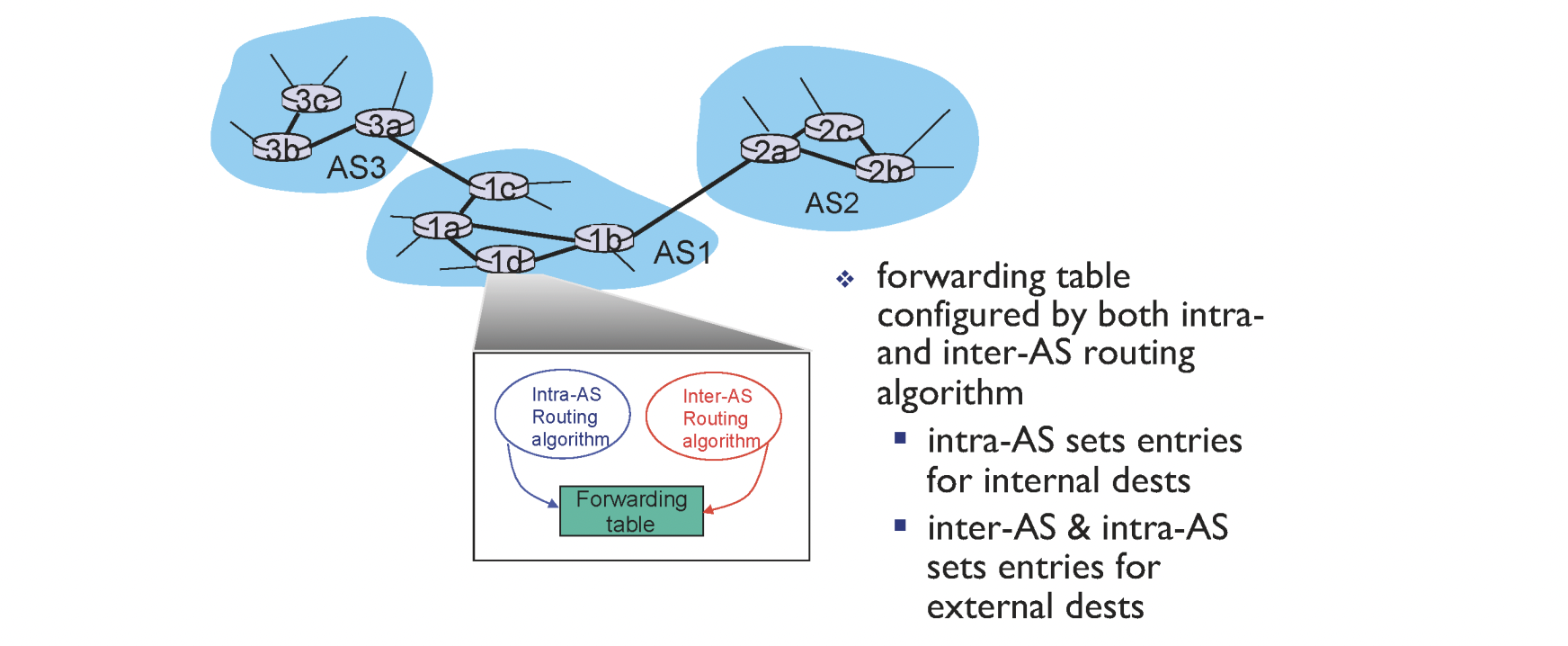
위 그림에서 AS(autonomous system)는 하나의 네트워크를 나타냅니다. AS 내부의 라우터들 사이에서는 Intra-AS 알고리즘(Link, Distance)을 사용해서 포워딩 테이블이 채워집니다. 외부로 나가는 경우 Inter-AS 알고리즘(BGP)을 적용하여 계층화를 시켜 문제를 해결할 수 있습니다.
AS(Autonomous System)
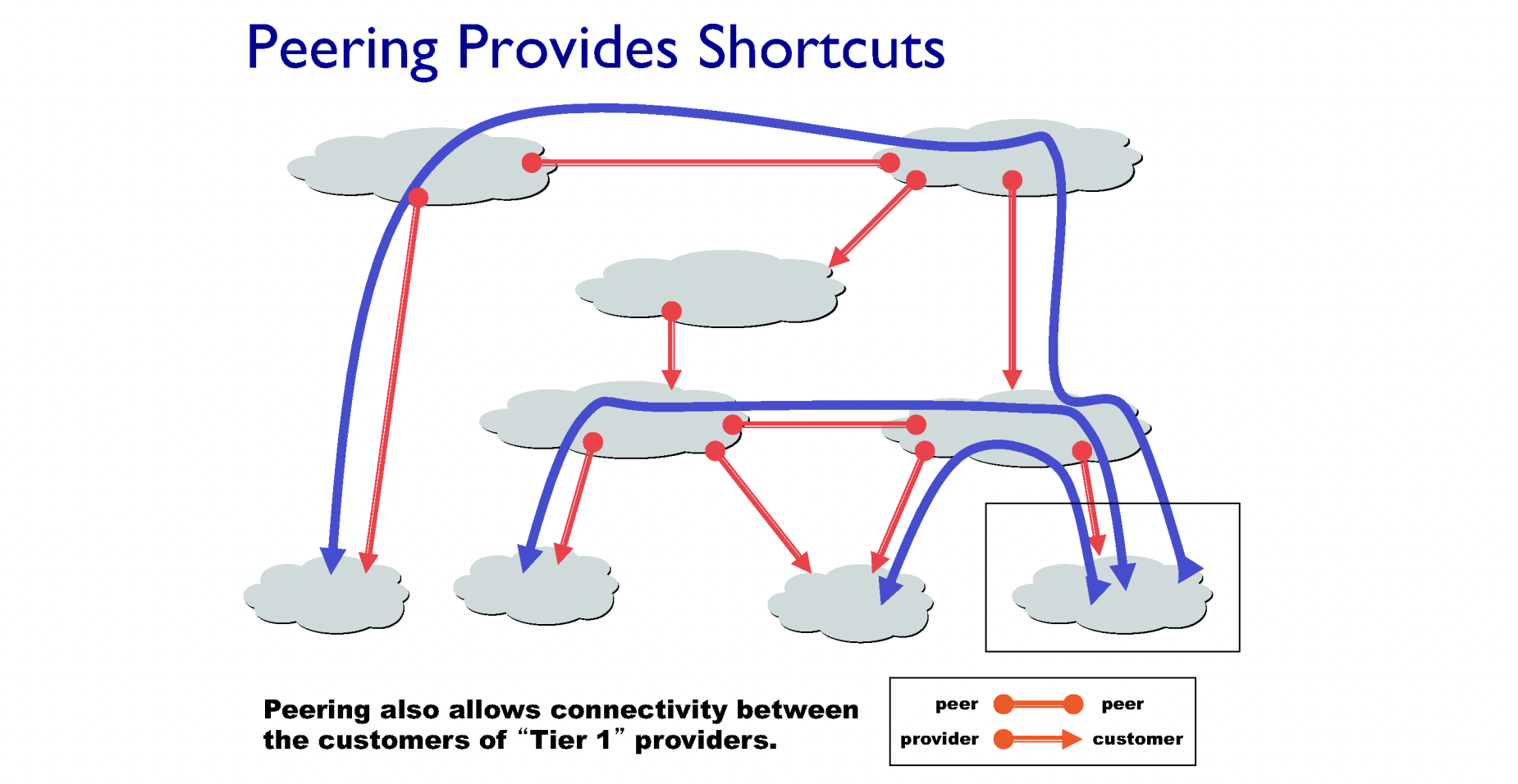
AS는 내의 많은 네트워크와 라우터들은 동일한 라우팅 프로토콜을 사용하고 하나의 조직에 의해서 관리됩니다.
이러한 AS들 사이에서도 계층이 존재하는데 서비스를 제공해주는 쪽을 Provider, 받는쪽을 customer라고 합니다. 인터넷 서비스를 사용하기 위해서 customer는 provider에서 돈을 지불하고 서비스를 이용할 수 있습니다. KT와 SK의 관계에는 서로 provider와 customer의 관계로 볼 수 없기 때문에 돈을 지불하지 않고 서로의 서비스를 이용할 수 있는 peer 관계에 놓이게 됩니다.
BGP (Border Gateway Protocol)
BGP는 Inter-AS 프로토콜이므로 AS 끼리의 포워딩을 담당하게 됩니다. BGP의 내용은 매우 복잡하고 깊은 공부가 필요하기 때문에 간단하게만 알아보겠습니다.
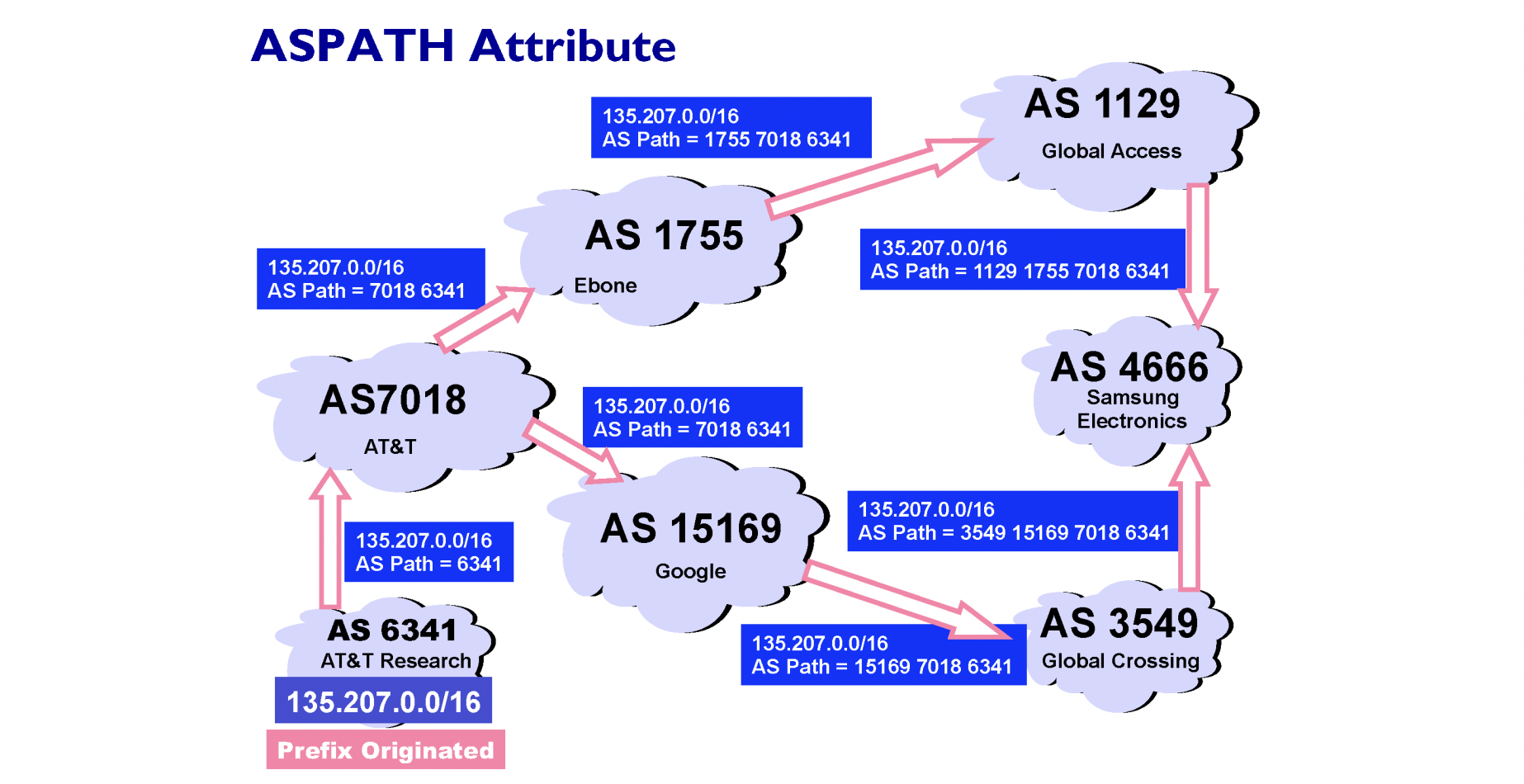
전 지구상 네트워크에 나의 존재를 알려야 하기 때문에 메세지를 전달하는데 이때 자신의 AS number를 추가하며 이동합니다. 따라서 삼성에서 AT&T로 메세지를 보내려면 2가지 방식으로 전달할 수 있는데 내부 정책이나 여러가지 상황에 따라서 경로를 선택할 수 있습니다. 기본적으로 우선순위가 되는 것은 돈을 벌기 위해 customer 관계에 있는 AS에게 보내고 그 후 경로가 짧은 곳이거나 지나가면 안되는 곳을 피해 이동하게 됩니다.
