
KOCW - 양희재 교수님 강의를 기반으로 운영체제 정리
운영체제의 주요 역할 중 Process management(CPU scheduling, synchronized)와 Main memory management(메모리 낭비 방지(동적 적재, 연결, 스와핑), 메모리 할당(연속 메모리 할당, paging, segmentation), 가상 메모리(demanding paging))에 대해서 학습했습니다.
운영체제과 관리해야할 자원 중 CPU, Memory 다음으로 중요한 자원은 보조기억장치(하드디스크)입니다. 하드디스크는 프로그램을 파일의 형태로 관리하고 File system이라고 합니다. 이번 시간에는 File system의 일부인 File allocation에 대해서 학습하겠습니다.
보조기억장치 (하드디스크)
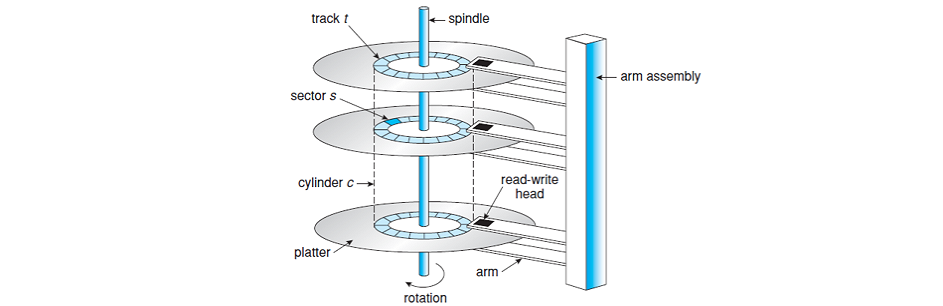
컴퓨터 구조에서 배운것 처럼 하드디스크는 자기물질로 이루어진 플래터라는 원판에 데이터를 저장합니다. 헤더는 코일로 감싸져있는데 여기에 전기를 흘려서 데이터를 기록하고 데이터를 읽을때는 플래터가 회전하면서 데이터를 읽을 수 있습니다.
데이터는 동심원을 이루는 트랙이라는 곳에 저장되고 트랙의 일부분을 섹터라고 표현합니다. 위 그림에서는 나오지 않았지만 여러 개의 플래터에서 같은 거리에 있는 트랙을 모아 실린더라고 표현합니다.
보통 섹터의 크기는 512 bytes인데 데이터를 저장하기에는 매우 작습니다. 따라서 여러 개의 섹터를 모아서 데이터를 저장하는데 이를 블럭(block)이라고 합니다. 결국 하드디스크는 블록 단위로 읽고 쓰기 때문에 block device라고도 합니다.
현재 컴퓨터의 블럭 단위를 알아보기 위해 메모장에 a라는 글자 하나만을 써서 저장해 볼 수 있습니다. a라는 글자는 1byte의 크기를 가지지만 실제로 저장된 파일의 정보를 보면 디스크에 4KB로 저장되어 있는 것을 확인할 수 있습니다. 결국 현재 컴퓨터는 4KB 단위로 블럭 크기를 사용하고 있습니다.
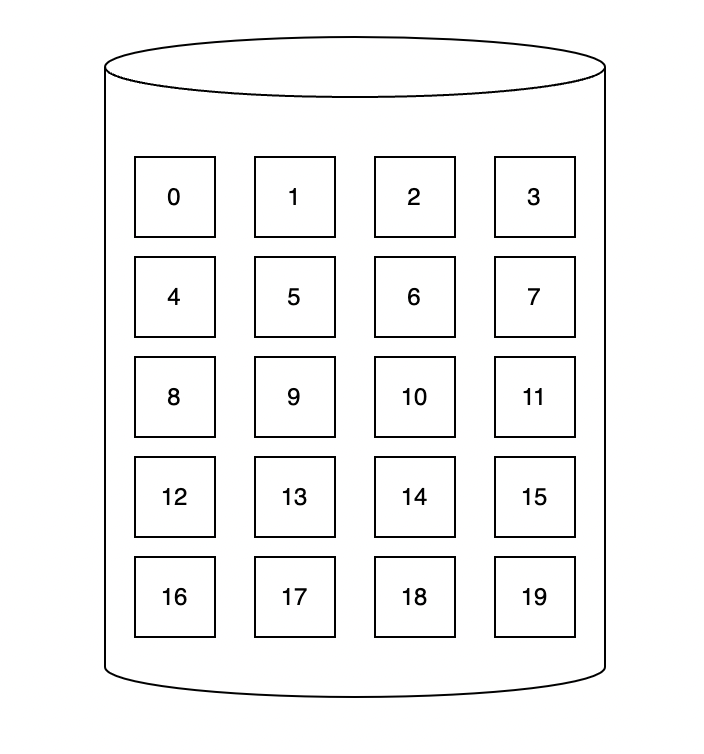
하드디스크의 구조를 논리적 구조로 그려보면 위의 그림 처럼 여러개의 블럭 단위로 이루어져 있습니다. 이처럼 하드디스크는 비어있는 블럭들의 모음(pool of free blocks)라고 볼 수 있습니다. 그렇다면 각각의 파일에 대해 free block을 어떤 방식으로 할당해줄지 알아보겠습니다.
파일 할당
연속 할당 (Contiguous Allocation)
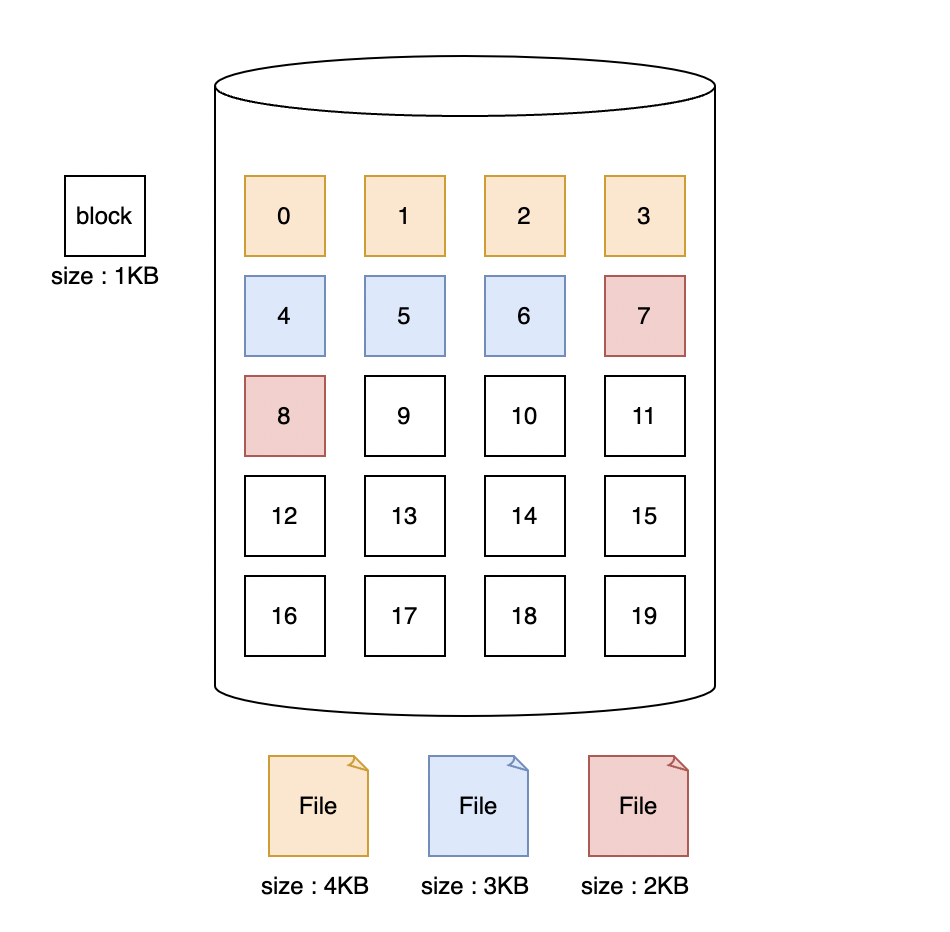
연속 할당 방식은 파일은 연속된 블락에 저장하는 방식입니다. 물리적으로는 헤더가 하나의 트랙을 연속적으로 읽거나 트랙의 용량을 벗어나더라도 약간의 이동으로 읽을 수 있습니다. 따라서 연속 할당 방식은 디스 크 헤더의 이동을 최소화할 수 있기 때문에 빠른 I/O를 보장할 수 있습니다.
연속 할당의 특징은 두 가지가 있습니다.
-
순차 접근(Sequential Access) : 파일을 순서대로 읽을 수 있다.
-
직접 접근(Direct Access) : 운영체제는 파일의 시작 블럭의 번호를 알고 있기 때문에 원하는 파일의 위치를 바로 읽을 수 있다.
디렉토리
파일시스템에서 파일에 대한 정보를 모아두는 곳을 디렉토리라고 합니다. 디렉토리에는 파일의 이름, 크기, 날짜 등의 정보가 있습니다. 컴퓨터를 사용하는 입장에서는 보이지 않지만 운영체제는 파일의 시작 블럭 번호와 같은 저장하고 관리하고 있습니다.
현재 연속 할당은 거의 사용되지 않습니다. 그 이유는 파일을 삭제할 경우에 문제가 발생하기 때문입니다. 만약 파란색 파일을 지우게 되면 해당 디스크의 블럭은 비어있게 됩니다(hole). 연속 할당은 연속된 블럭이 있어야 하기 때문에 메모리 연속 할당과 마찬가지로 외부 단편화가 일어날 수 있습니다.
또 다른 문제점으로 파일을 저장할 때 실제 크기를 알 수 없습니다. 만약 특정 파일을 수정해서 그 크기가 더 커진다면 연속적으로 할당할 수 없는 문제가 발생합니다.
연결 할당 (Linked Allocation)

연결 할당은 파일을 linked list처럼 각 블럭에 pointer(보통 4byte)를 두어 다음 블럭이 어디있는지 가르키게 할당합니다. 이 방법은 파일이 동적으로 늘어나거나 작아져도 포인터를 통해 조절할 수 있고 외부 단편화가 없다는 장점이 있습니다. 따라서 연결 할당을 linked list of data blocks라고 말합니다.
연결 할당의 단점은 직접 접근이 불가능하다는 점입니다. 연속 할당의 경우 시작 블럭 정보를 통해 몇 번째 블럭에 접근할지 결정할 수 있지만 연결 할당은 포인터를 이용하기 때문에 파일의 몇 번째 블럭이 어디에 위치하는지 알 수 없습니다.
또한 포인터 정보를 저장하기 위해 약 4 byte의 손해가 발생하게 됩니다. 만약 하나의 블럭에 문제가 생긴다면 그 이후의 모든 블럭에 접근하지 못하는 문제가 발생하고 이 상황을 신뢰성이 낮다고 합니다. 마지막으로 파일의 블럭이 흩어져 있기 때문에 헤더의 움직임이 증가하여 속도가 느려집니다.
FAT (File Allocation Table)
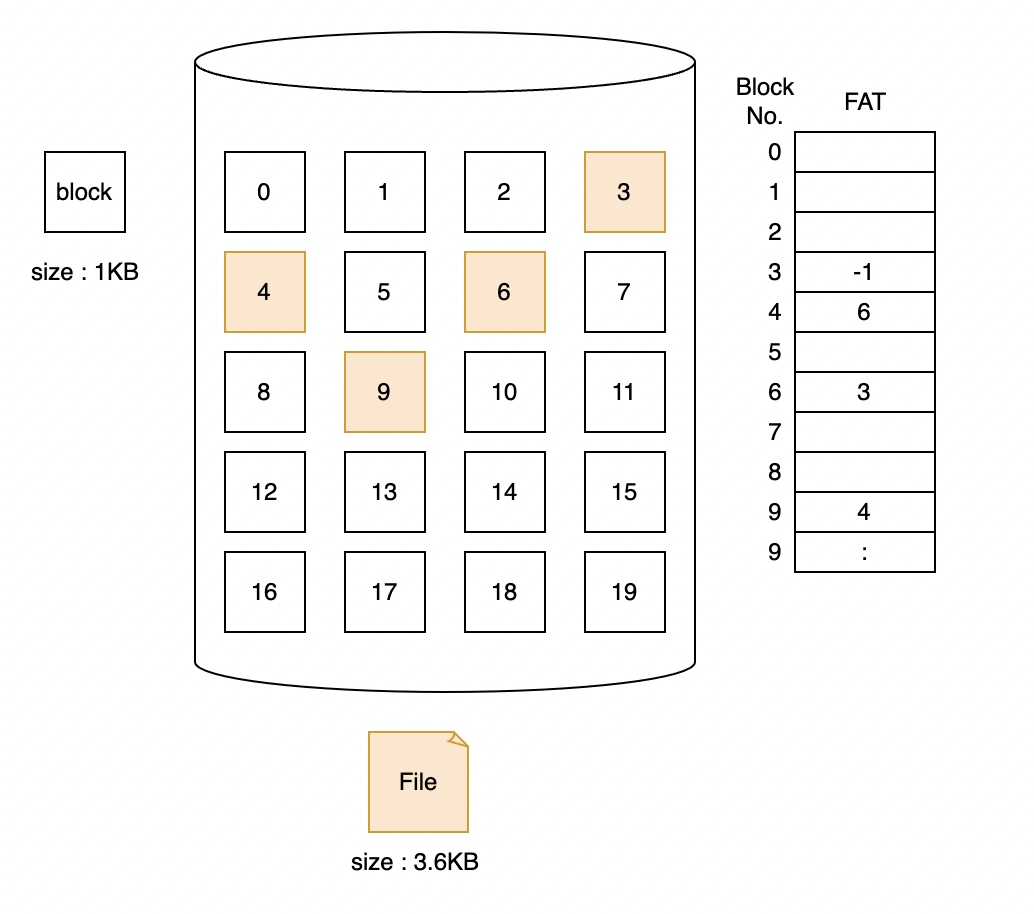
FAT는 연결 할당의 문제점을 개선하기 위해 나온 방법입니다. 연결 할당에서 사용하던 포인터들을 File Allocation Table이라고 하는 다른 저장장치에 저장하여 사용하는 방식입니다.
이 방식을 사용하게 되면 블럭의 포인터를 저장하지 않기 때문에 효율적입니다. 또한 Table의 정보를 이용하여 직접 접근이 가능합니다.
블럭에 문제가 생겨도 FAT만 이상이 없다면 다음 블럭을 읽을 수 있습니다. 이 말은 FAT에 문제가 생기면 치명적일 수 있기 때문에 FAT를 복제하여 백업용 데이터를 들고 있습니다.
해결하지 못한 문제는 속도인데 연결 할당의 가장 큰 목표는 외부 단편화를 없애기 위함이므로 여전히 속도가 느린 문제점은 존재합니다.
FAT의 크기는 하드디스크의 전체 블럭의 개수를 저장할 수 있어야 하기 때문에 보통 32bit를 사용하며 FAT32라고 합니다.
색인 할당 (Indexed Allocation)
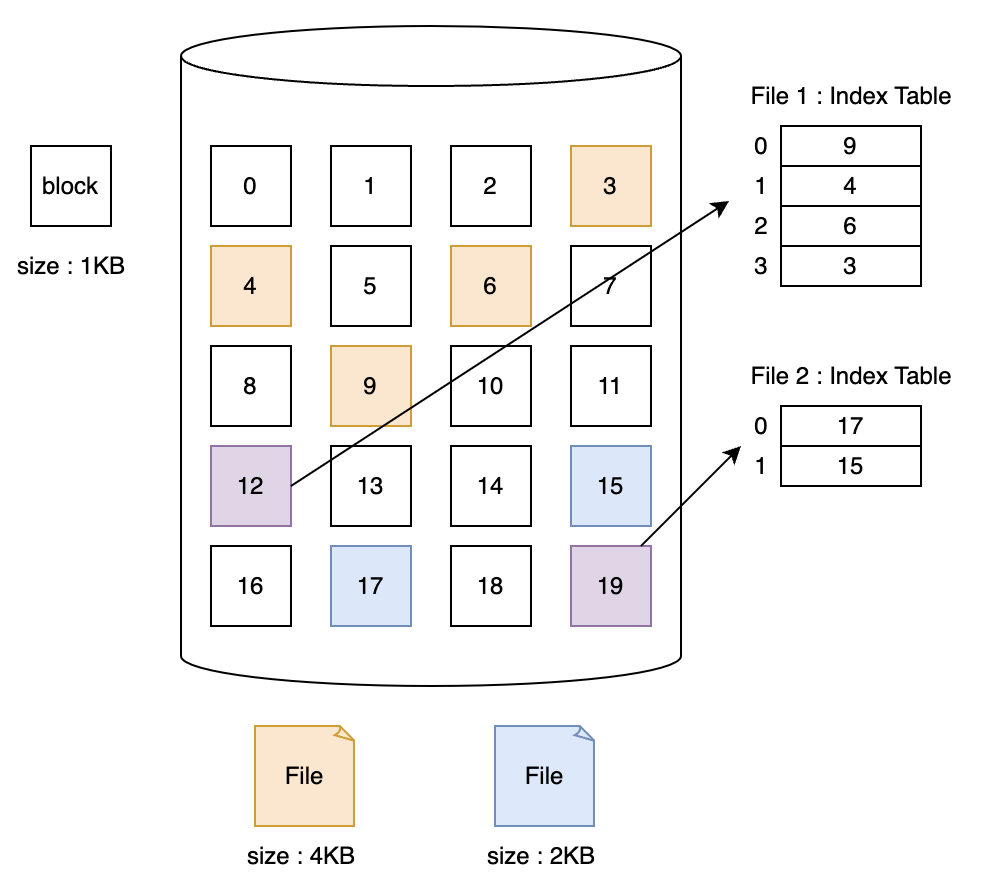
색인 할당 방법도 외부 단편화를 없애기 위해 파일을 흩어져 저장합니다. 연결 할당에서는 파일당 할당된 블럭의 번호를 나타내는 정보를 또 다른 블럭에 저장합니다. 이처럼 색인 할당에서는 데이터를 저장한 블럭을 Data block, 인덱스를 저장한 블럭을 Index block이라고 합니다.
색인 할당을 사용할 경우 운영체제는 파일의 시작 블럭이 아니라 파일의 인덱스 블럭 번호를 사용합니다. 인덱스 블럭은 파일 당 한 개씩 사용하며 이 안에는 데이터 블럭의 순서(인덱스 테이블의 인덱스)대로 하드 디스크의 어느 블럭(인덱스 테이블의 값)에 저장되어 있는지 알 수 있습니다.
색인 할당은 인덱스 테이블을 통해 직접 접근이 가능하고 외부 단편화가 없습니다.
하지만 색인 할당은 작은 크기의 파일인 경우에도 하나의 인덱스 블럭을 사용하기 때문에 저장 공간의 손해가 일어날 수 있습니다. 또한 파일 당 하나의 인덱스 블럭으로 표현할 수 없는 큰 파일을 저장할 수 없습니다.
만약 하나의 블럭 크기가 512 byte라면 블럭 인덱스의 개수는 512 / 4(포인터 크기) = 128개이다. 결국 하나로 표현할 수 있는 파일의 크기는 64KB로 매우 작은 크기입니다. 블럭의 크기가 1KB라고 하더라도 총 256KB로 입니다.
이 문제를 해결하기 위한 방법으로 Linked, Multilevel index, Combined 등의 방법이 있습니다.
Linked
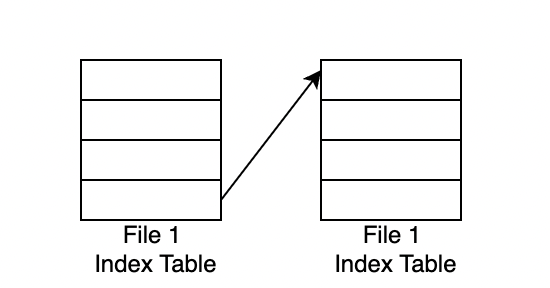
Linked 방식은 Index table을 여러개 두어 마지막 인덱스가 다음 Index table을 가르키도록 연결하는 방법입니다.
Multilevel index
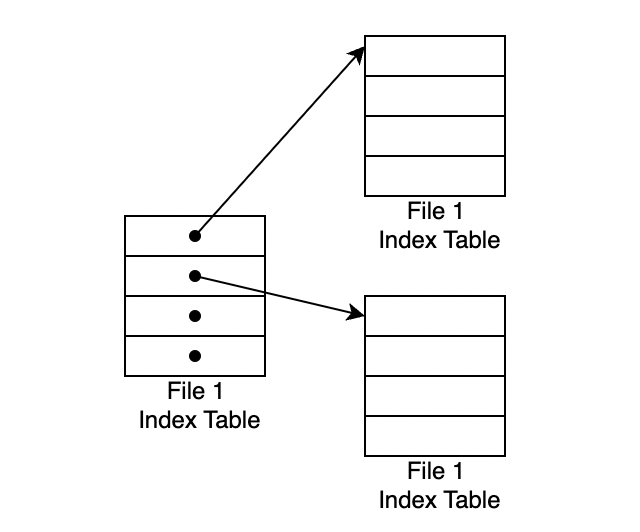
하나의 인덱스 블럭의 모든 값이 또 다른 인덱스 블럭을 가르키는 형태의 방법입니다. 만약 하나의 계층으로 부족하다면 추가로 늘려나갈 수 있습니다.
Combined
Linked와 Multilevel 방식을 합친 방식으로 Index table의 일부분은 데이터 블럭을 가르키고 나머지는 인덱스 블럭을 가르키는 방법입니다.
