
데이터베이스는 파일(File)의 형태로 저장하고 파일 내/외적으로 검색될 가능성이 높은 레코드들을 디스크 상에서 물리적으로 가까운 곳에 모아둡니다(클러스터링).
인덱스 이전에는 힙 파일이나 순차 파일과 같은 조직으로 데이터를 관리하였지만 탐색 시간이 너무 오래걸리기 때문에 현재는 인덱스방식을 사용하여 데이터를 저장합니다.
1. 단일 단계 인덱스
앞선 연구들을 통해 데이터를 어떤 구조로 저장하느냐는 한계가 있다는 것을 알았습니다. 별도로 인덱스 파일을 만들어 올바른 데이터를 찾아가게끔 구조화 했습니다. 여기서 인덱스 파일을 하나만 거치는 것이 단일 단계 인덱스입니다.
인덱스에 저장되는 값(엔트리)은 탐색 키, 레코드에 대한 포인터(주소)입니다. 일반적으로 엔트리들은 탐색 키를 기준으로 오름차순 정렬되어 있습니다. 이렇게 만들어진 인덱스 파일의 크기는 데이터 파일의 크기에 비해 훨씬 작으며 하나의 데이터 파일에 여러 개의 인덱스(속성별로)들을 정의할 수 있습니다.
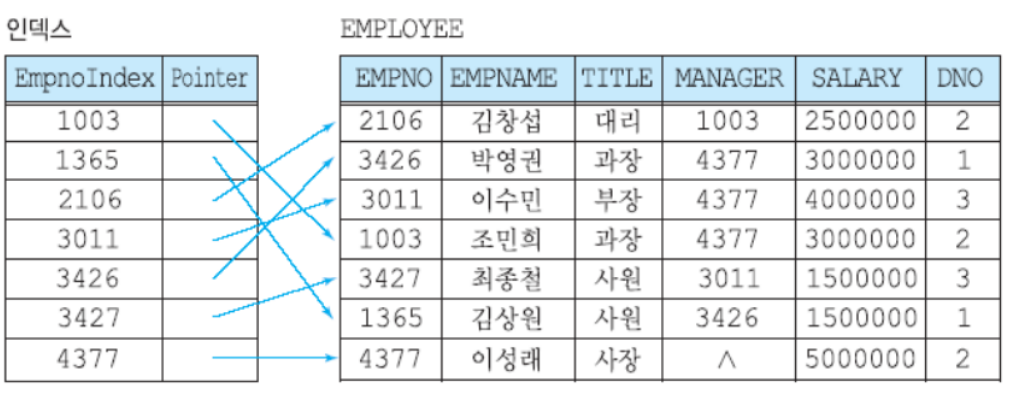
우측의 데이터 파일은 어떠한 기준으로 정렬되어 있지 않고 힙 파일로 구조화 되어 있기 때문에 원하는 값을 찾기 위해서는 전체 레코드를 탐색해봐야 합니다. 만약 이런 데이터 파일에 EMPNO로 자주 접근한다면 이를 인덱스로 지정하여 데이터에 빠른 접근이 가능합니다.
위의 예시의 탐색 키는 기본키로 지정된 속성을 인덱스(기본 인덱스)로 지정하였지만, 꼭 키 속성을 띌 필요는 없습니다. 하지만 효율성으로 고려했을 때 도메인 카디널리티를 고려해 인덱스로 지정합니다.
1.1. 기본 인덱스
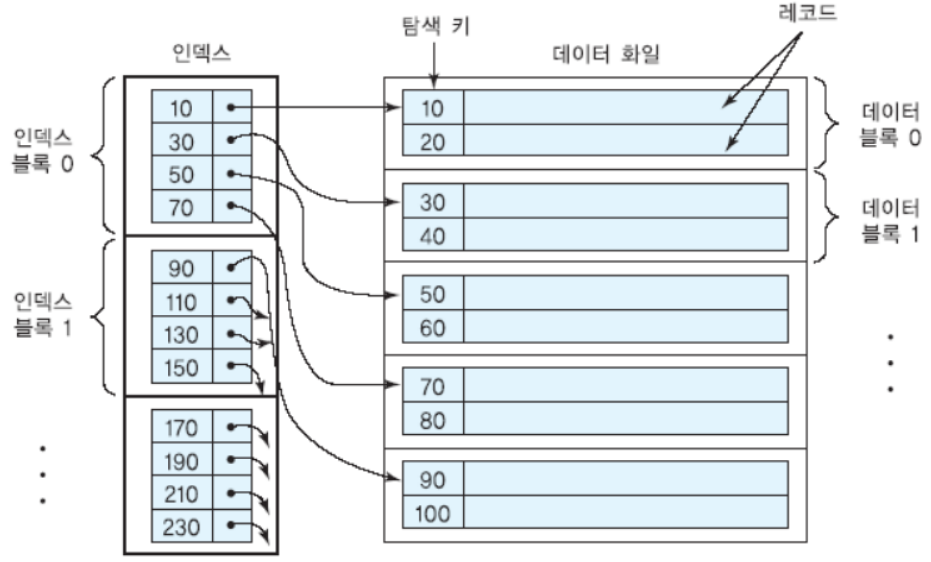
탐색 키가 기본 키인 인덱스에서는 탐색 키 또한 중복이 없습니다. 따라서 희소 인덱스로 유지가 되는데 데이터 블록의 첫번째 값만 인덱스로 사용하는 방법입니다. 하지만 희소 인덱스는 데이터 파일도 기본 키를 기준으로 정렬이 되어 있을때 사용할 수 있습니다.
1.2. 클러스터링 인덱스

기본 인덱스처럼 탐색 키 값에 따라 정렬된 데이터 파일에 대해서 사용할 수 있습니다. 기본 인덱스와 달리 클러스터링 인덱스의 탐색 키값은 데이터 파일 내에 중복으로 존재할 수 있습니다. 클러스터링 인덱스는 범위 질의에 유용합니다.
위의 예시에서 인덱스 파일은 이름을 탐색 키로 생성되어 있습니다. 데이터 파일 또한 이름을 기준으로 정렬되어 있기 때문에 김상원부터 조민희까지 탐색할때 범위 시작 값에 해당하는 김상원을 찾는 다면 데이터 파일을 쭉 읽어오기만 하면 된다.
1.3. 보조 인덱스
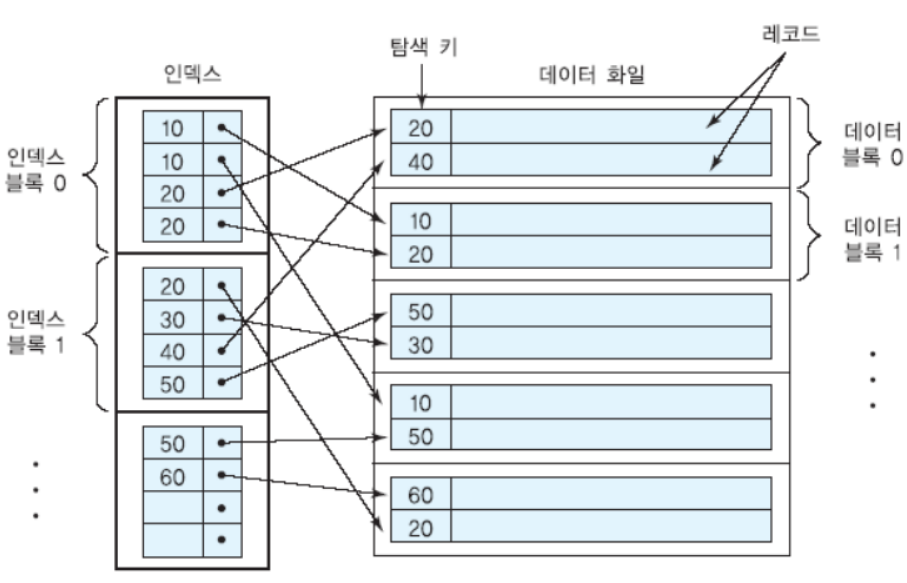
보조 인덱스는 탐색 키 값에 따라 정렬되지 않은 데이터 파일에 대해 정의됩니다. 즉, 기본 키 값이 아닌 다른 속성들로 인덱스를 만들 수 있습니다.
보조 인덱스는 일반적으로 밀집 인덱스이므로 같은 수의 레코드들을 접근할 때 보조 인덱스를 통하면 기본 인덱스를 통하는 경우보다 디스크 접근 회수가 증가할 수 있습니다.
2. 다 단계 인덱스
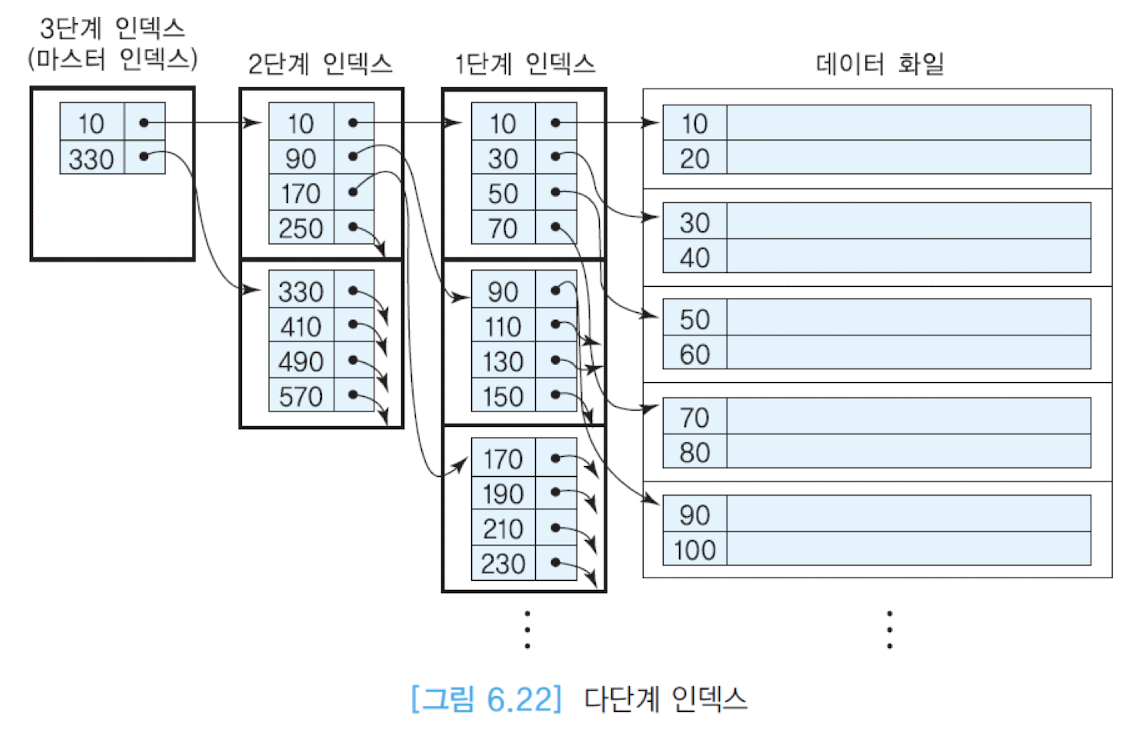
단일 단계 인덱스는 인덱스 자체가 클 경우 인덱스를 탐색하는 시간조차 오래 걸릴 수 있습니다. 이처럼 인덱스 엔트리를 탐색하는 시간을 줄이기 위해서 단일 단계 인덱스에 대해서 다시 인덱스를 정의할 수 있습니다.
다단계 인덱스는 가장 상위 단계의 모든 인덱스 엔트리들이 한 블럭에 들어갈 수 있을 때까지 이 과정을 반복하고 가장 상위 단계 인덱스를 마스터 인덱스라고 부릅니다.
위의 그림에서 처럼 1단계 인덱스들을 인덱스하기 위해 2단계 인덱스를 생성하고 2단계 인덱스를 인덱스하는 3단계 인덱스를 생성하며, 최종 마스터 인덱스가 한 블록안에 들어왔기 때문에 이 과정은 종료됩니다.
인덱스를 구현하기 위해 Hash Table을 이용할수 있지만 이는 등호(=)연산에만 특화되어 있는 자료구조 이기 때문에 부등호 연산(<,>)도 이용할 수 있는 B+ tree구조를 사용합니다.
2.1. B Tree
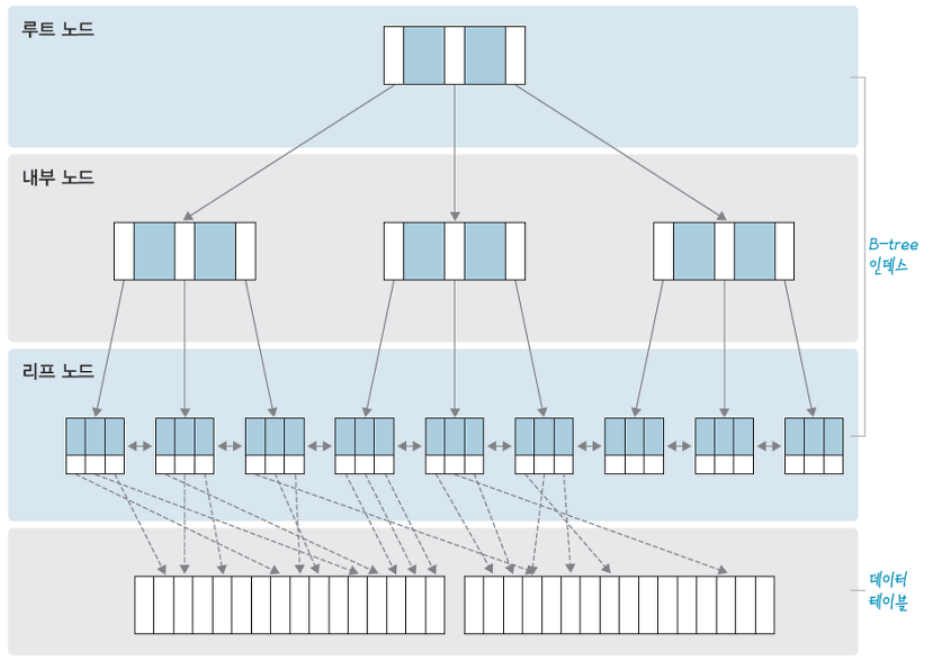
B-Tree는 Balanced Tree 구조의 약자로 편향되지 않은 구조를 가지게 하여 검색의 효율성을 높여주는 자료구조입니다.
B-Tree의 시작은 이진 트리 구조에서 더 많은 자식 노드를 가질 수 없을까라는 생각에서 시작했습니다. 여기서 가지고 싶은 자식 노드의 최대수를 M이라고 한다면 M차 B-Tree라고 표현합니다.
M이 결정되었다면 노드가 가질 수 있는 키(데이터)값도 최대 M-1로 정의됩니다. 또한 최소로 가질 수 있는 자식 노드의 수는 ceil(M/2)**이며(루트와 리프노드 제외) 최소로 가질 수 있는 키값은 ceil(M/2)-1개(루트 노드 제외) 입니다.
위와 같은 특징을 가졌기 때문에 루트 노드를 시작으로 값을 비교하여 빠른 시간에 데이터를 찾을 수 있습니다.
2.2. B+ Tree
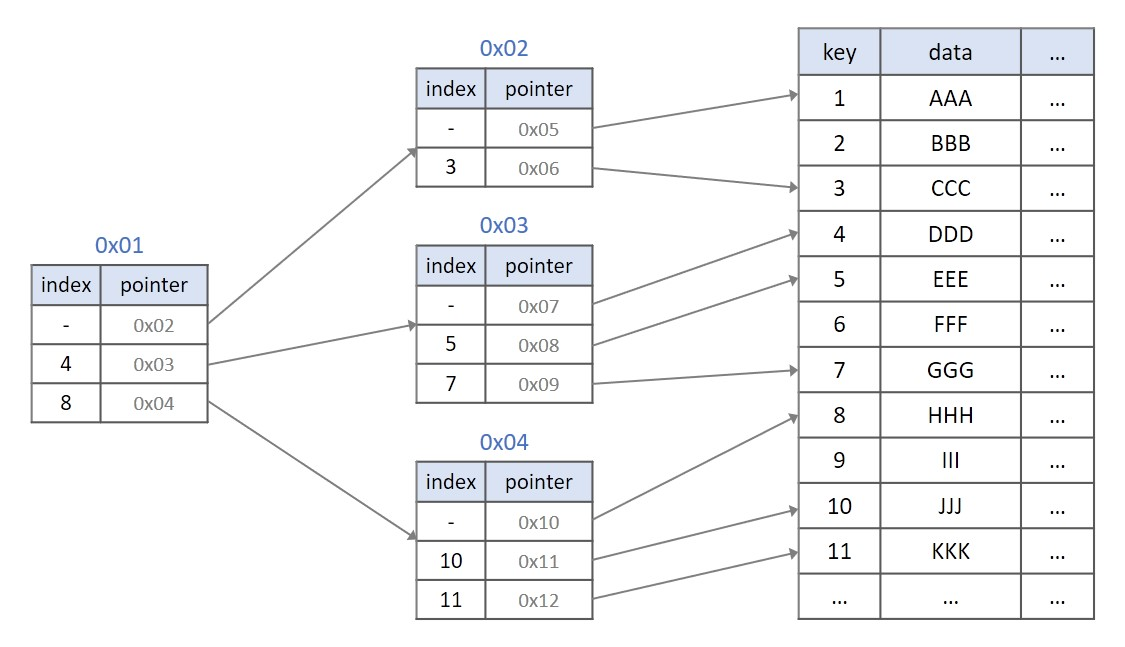
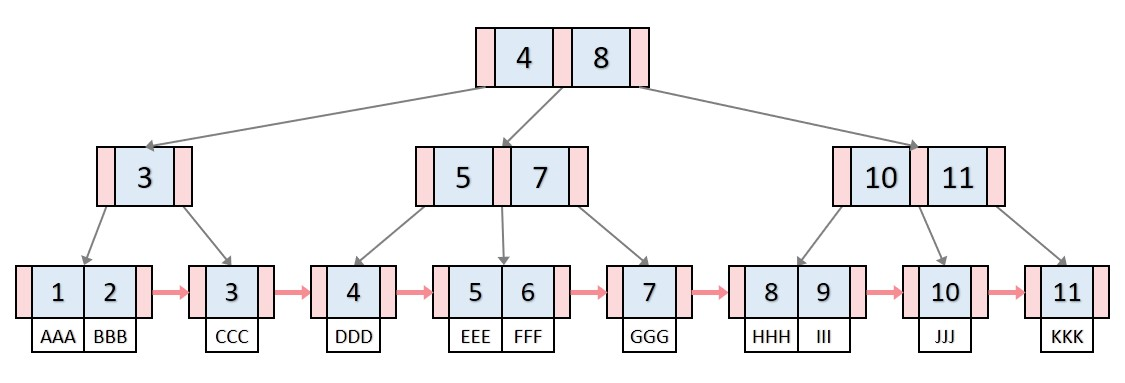
실제 데이터베이스의 인덱스를 B+ Tree구조를 사용합니다. B Tree는 각 노드에 키와 데이터를 가지고 있었다면(그림에는 데이터 제외) B+ Tree는 모든 데이터가 리프 노드에 모여 있습니다. 또한 모든 리프 노드는 링크드 리스트 형태를 띄고 있습니다. 따라서 B Tree의 경우 옆에 있는 리프 노드를 검사할 때 다시 루트노드부터 검사해야 하지만 B+ Tree의 경우 선형검사가 가능합니다. 마지막으로 리프노드의 부모 key는 리프노드의 첫번째 key보다 작거나 같은 특징을 가집니다.
3. 인덱스의 장점과 단점
-
인덱스는 검색 속도를 향상시키지만 인덱스를 저장하기 위한 공간이 추가로 필요하고 삽입, 삭제, 수정연산의 속도는 저하시킨다.
-
소수의 레코드들을 수정하거나 삭제하는 연산의 속도는 향상됨
-
릴레이션이 매우 크고, 질의에서 릴레이션의 튜플들 중에 일부(2%~4%)를 검색하고 WHERE절이 잘 표현되었을 때 특히 성능에 도움이 된다.
