
KOCW - 양희재 교수님 강의를 기반으로 운영체제 정리
이전 시간까지는 운영체제의 CPU를 관리하도록 하는 주요 기능인 Process Management(CPU scheduling, synchronized)에 대해서 학습했습니다. 컴퓨터에는 CPU 만큼 중요한 자원은 메모리입니다. 이번 시간부터는 메인 메모리를 관리하는 Main Memory Management에 대해서 알아보겠습니다.
메모리의 역사
현재의 메모리는 과거에 비해 더 큰 용량을 더 저렴한 가격에 이용할 수 있습니다. 하지만 현재 프로그램들도 크기가 증가했기 때문에 메모리의 용량은 현저히 부족합니다. 따라서, 과거에서부터 현재까지도 메모리를 효율적으로 관리하고 사용하기 위해 다양한 방법들이 연구되어 왔습니다.
메모리 형태의 변천
-
Core memory
-
진공관
-
트랜지스터
-
직접회로 : SRAM, DRAM
메모리 용량의 변천
-
1970년대 : 8-bit PC 64KB
-
1980년대 : 16-bit IBM-PC 640KB > 1MB > 4MB
-
1990년대 : 수MB > 수십MB
-
2000년~ : 수백MB > 수GB
프로그램을 메모리에 올리기
메모리 구조
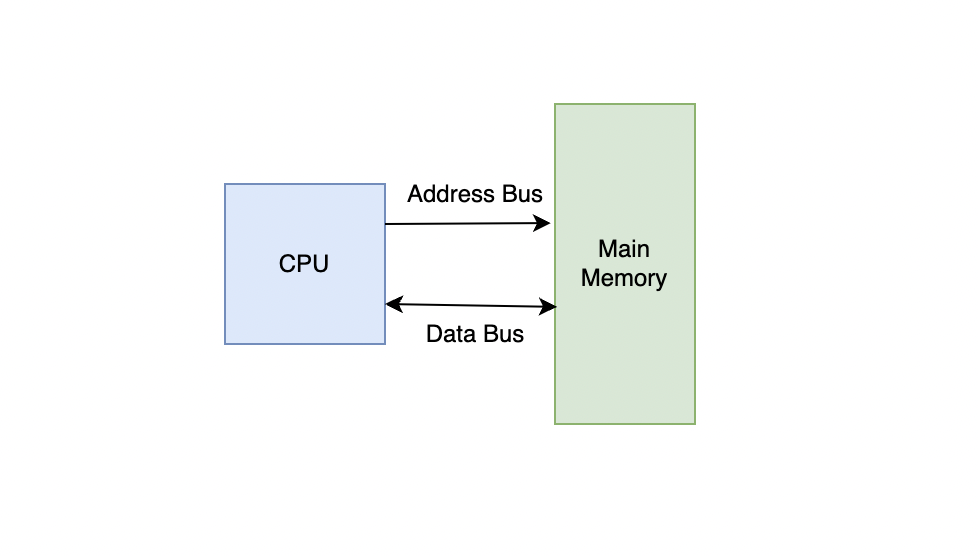
메모리는 기본적으로 주소(Address)와 데이터(Data)로 이루어져 있습니다.
프로그램을 개발하는 과정은 아래와 같습니다.
-
원천파일(Source file) : 고수준언어 또는 어셈블리언어
-
목적파일(Object file) : 컴파일 또는 어셈블 결과
-
실행파일(Executable file) : 링크 결과

-
고수준언어로 작성한 프로그램의 소스코드는 컴파일러에 의해서 목적파일을 생성합니다. 어셈블리어의 경우 어셈블러에 의해서 기계어로 번역됩니다.
-
소스코드에는
print와 같이 소스코드에서는 구현하지 않은 함수들도 포함되어 있는데 목적함수에서 이러한 함수를 사용하기 위해 디스크에서 오브젝트 파일을 모아둔 Library에서 필요한 정보를 추가하여 Linker에 의해 연결되고 실행파일을 만듭니다. -
디스크에 저장된 실행파일을 실행하기 위해서는 메모리에 적재(load)되어야 하는데 이 작업을 Loader가 담당하게 됩니다.
-
프로그램이 실행되기 위해서 실행 파일안에는 code, data, stack 영역이 존재합니다.
현재 실행파일을 실행하게 되면 프로그래머가 직접 메모리 몇 번지에 적재할지 결정하는 것이 아니라 Loader에 의해서 메모리 관리가 이루어집니다. 다중 프로그래밍 환경에서 하나의 프로그램을 어제 실행했을때는 5번지에서 실행되었고 오늘 실행하려고 하니 5번지는 이미 사용중이여서 다른 번지에 실행되어야 하는 경우가 있습니다.

고수준언어에서는 메모리 번지수에 대한 코드가 들어가 있지 않지만 실제 저수준언어에서는 메모리 번지수에 대한 명령어가 포함되어 있습니다. 그렇다면 번지수에 대한 코드가 매번 수정되어야 하는 문제점이 있습니다. 이 문제를 해결 하기 위해 MMU의 재배치 레지스터(Relocation register)를 이용합니다.
하나의 프로그램이 0번지에서 실행된다고 프로그래밍되어 있다고 하겠습니다. 하지만 오늘은 500번지에서 프로그램이 실행되었다면 CPU는 0번지 주소로 가기전 MMU의 재배치 레지스터의 값을 더해주게 됩니다. 따라서, 재배치 레지스터의 값을 500으로 설정해준다면 CPU입장에서 어제, 오늘, 언제든 0번지에서 실행하는 것으로 인식할 수 있습니다.
운영체제의 기능 중에 메모리 보호 기능을 설명한적이 있습니다. 프로세스가 실행되고 CPU에서 메모리 주소에 접근할 때 base 레지스터와 limit 레지스터를 통해 해당 영역안의 메모리 주소만 접근할 수 있도록 제한하고 있습니다. 만약 이 영역을 벗어나게 된다면 운영체제의 특정 루틴이 실행되어 프로세스를 강제 종료시킬 수 있습니다.
이처럼 CPU가 사용하는 주소는 논리 주소를 사용합니다. 실제 프로세스가 적재된 메모리 주소를 사용하지 않고 논리주소를 사용하고 MMU의 base값을 더해 실제 물리 주소에 접근하는 방법을 사용합니다.
Base vs. Relocation
역할을 위해 Base와 Limit, Relocation 3가지로 나누었지만 Base와 Relocation의 사용방법은 같기 때문에 Base 레지스터를 Relocation 레지스터라고도 한다.
메모리 낭비 방지
동적 적재(Dynamic Loading)
운영체제를 메모리에 올리는 작업을 부팅이라고 표현하고 만들어진 실행 파일을 메모리에 올리는 작업을 Load라고 합니다.
동적 적재 방식은 프로그램 실행에 반드시 필요한 코드/데이터만 적재하는 방법입니다. 예를 들어, 파일을 열고 이 파일이 제대로 열리면 특정 작업을 하고 저장하는 코드가 있고 만약 이 파일이 정상적으로 열리지 않았다면(오류) 특정 루틴을 실행하는 코드가 있다고 가정해봅시다.
오류처리 코드가 처음부터 메모리에 적재되었다고 생각했을때 프로그램 종료까지 오류가 일어나지 않는다면 이 코드를 단순히 메모리를 낭비하고 있는 상황으로 생각할 수 있습니다. 또한 하나의 프로그램안에 있는 모든 데이터들이 전부 사용되는 것도 아닙니다. 따라서 동적 적재는 실제로 오류가 일어났을때 해당 코드를 적재하도록 합니다.
과거에는 정적 적재(Static Loading)을 사용했지만 현대의 운영체제는 동적 적재를 사용하고 있습니다.
동적 연결(Dynamic Linking)
여러가지 프로그램을 메모리에 올리는 상황에서 각각의 프로그램이 소스코드에는 포함되어 있지 않는 print라는 메소드를 사용하고 있는 상황입니다. 이 상황에서 프로세스 개수 만큼 공통된 라이브러리를 메모리에 올리는 것은 낭비입니다.
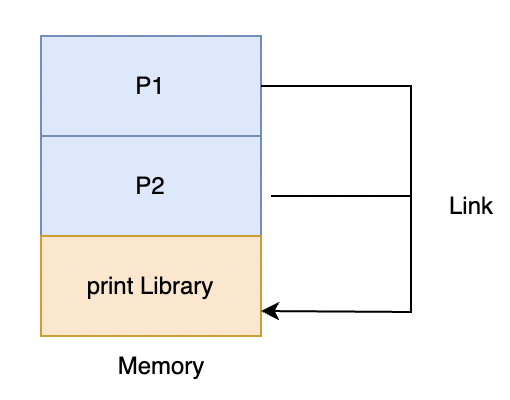
기존의 Link는 메모리에 올리기 전에 오브젝트 파일과 라이브러리를 연결합니다(정적 연결). 하지만 메모리 낭비 방지를 위해 실행 파일을 메모리에 올리고 프로세스가 라이브러리가 필요한 경우 그때 메모리에 라이브러리를 적재하여 서로 Link를 하는 방식을 사용합니다. 따라서 각각의 프로세스는 현재 메모리에 적재된 하나의 라이브러리와 Link가 되어 메모리 낭비를 방지할 수 있습니다. 이처럼 현재 메모리에 적재된 라이브러리를 Linux에서는 공유 라이브러리, Windows에서는 동적 연결 라이브러리(DLL)라고 부릅니다.
Swapping
Swapping은 CPU scheduiling에 대해서 설명했을때 Middle-term scheduling으로 설명했습니다.
Swapping은 현재 메모리에 적재되어 있는 프로세스 중 오랫동안 사용되지 않은 프로세스를 프로세스 이미지로 만든 후 하드디스크(Backing store, swap device)에 이동시킵니다. 이처럼 메모리에서 Backing store로 이동하는 것을 Swap-out, 다시 메모리로 이동시키는 것을 Swap-in이라고 부릅니다.
실행되고 있는 프로세스는 code와 data정보 뿐만 아니라 stack부터 다양한 레지스터에 대한 정보가 있습니다. 이런 모든 상태를 프로세스 이미지라고 표현하고 swapping는 프로세스 이미지를 이동시킵니다.
서버 컴퓨터와 같이 큰 컴퓨터는 파일 시스템을 위한 하드디스크와 swap device를 따로 두지만 일반 PC나 모바일의 경우 현재 하드디스크의 일부를 swap device로 사용합니다. swap device의 크기는 대략 메모리의 크기 정도로 사용할 수 있습니다.
만약 swap-in 과정을 통해 원래 메모리 주소가 변경되었다고 하더라도 MMU의 Relocation register를 사용하여 적재 위치는 문제를 일으키지 않습니다.
마지막으로 프로세스의 크기가 크다면 swap device 입출력에 따른 부담이 큰 기술입니다.
연속 메모리 할당
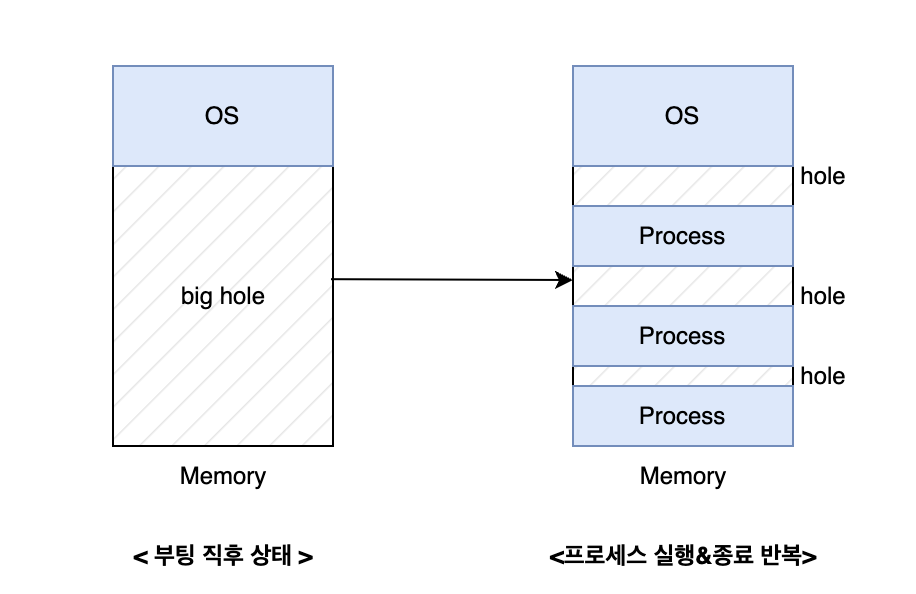
부팅 직후의 메모리는 운영체제의 적재를 제외한 모든 부분이 비어있는 하나의 big hole이 존재합니다. 그 후 프로세스의 생성과 종료가 반복되면서 작은 hole들이 흩뜨려져 있는 scattered hole이 존재하게 됩니다.
Hole들이 불연속하게 흩어져 있기 때문에 메모리가 조각나 있는 상황을 메모리 단편화(Memory fragmentation이라고 합니다. 이런 상황에서 하나의 프로그램을 메모리에 적재하려고 했을때 조각난 메모리 크기를 합치면 적재가 가능하지만 메모리가 조각나 있기 때문에 적재가 불가능한 경우를 외부 단편화라고 합니다.
이 문제를 해결하기 위해 메모리를 할당 하는 방식을 조정하여 이 문제를 해결하고자 했습니다.
최초 적합(First-fit)

최초 적합 방법은 메모리를 위에서 아래로 또는 아래서 위로 읽으면서 현재 프로세스가 적재될 수 있는 공간이 있다면 즉시 할당하는 방법입니다.
이 방법은 위의 예시처럼 남은 공간은 충분하지만 메모리 단편화로 인해 마지막 프로세스를 적재하지 못하는 상황(외부 단편화)가 발생할 수 있습니다.
최적 적합(Best-fit)

최적 적합은 현재 프로세스의 크기와 가장 유사한 크기의 메모리에 할당하는 방식입니다.
최악 적합(Worst-fit)
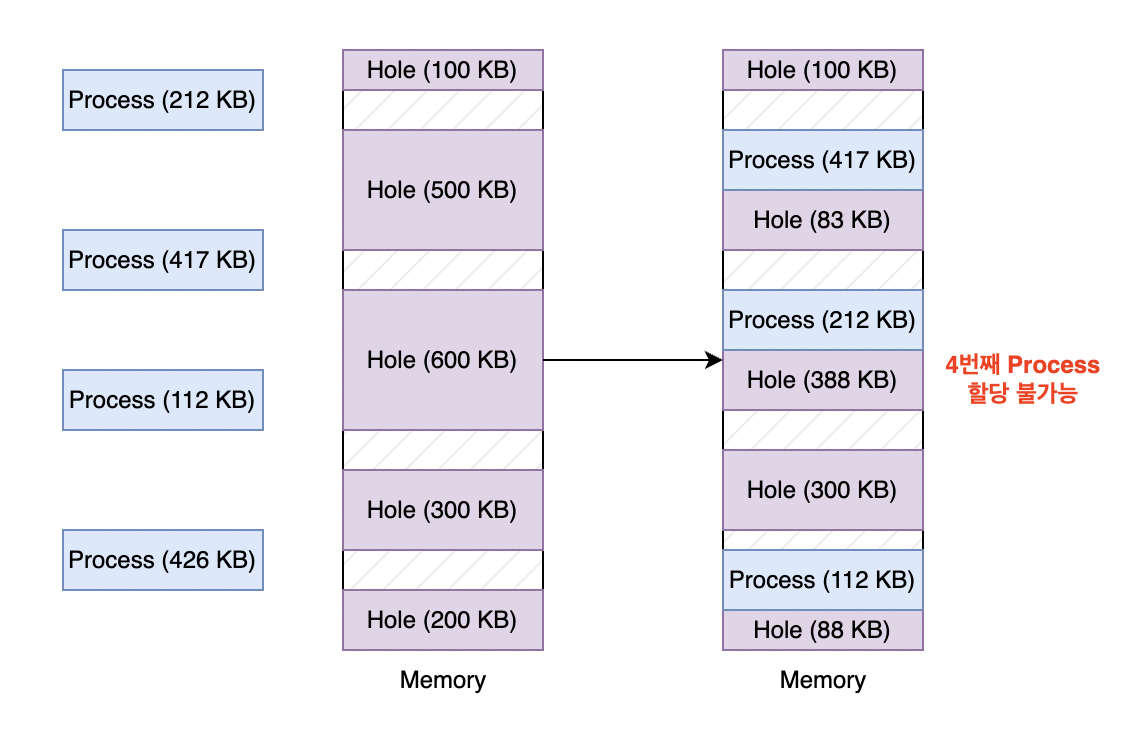
최악 적합은 현재 프로세스의 크기와 가장 차이가 많이 나는 크기의 메모리에 할당하는 방식입니다. 이 방식도 위의 예제 상황에서는 외부 단편화가 발생됩니다.
대부분의 상황에서 속도면에서는 first-fit이 가장 효율이 좋고 메모리 이용률 측면에서는 first-fit과 best-fit이 가장 좋은 성능을 나타냅니다.
best-fit도 무조건 외부 단편화가 발생하지 않는 것은 아닙니다. 일반적으로 외부 단편화로 인한 메모리 낭비는 약 30%정도가 발생한다고 합니다. 따라서 이 문제를 해결하기 위한 방법이 모색되어 왔습니다. 그 중 compaction은 현재 hole이나 process를 옮겨 연속된 메모리를 확보하는 방법입니다. 하지만 상황에 따라 hole을 옮기는게 좋을지 process를 옮기는게 좋을지 계산하는데 부담이 크게 되며 최적의 알고리즘이 존재하지 않다는 단점이 존재합니다.
