review-rethinking pre-training and self-training
abstract
investigate self-tarining ans another method to utilize additional data on the same setup
3 insights
1. stronger data augmentation diminish the value of pre-training even for self-supervised learning
2. self-training is always helpful despite stronger data augmenetation
3. self-training improves on pre-trainingintroduction & related work
최근에 self-supervised learning과 같은 pretraining 방법론이 대두되고 있음.
그러나 막상 실험을 해보면 강력한 augmentation을 사용하거나 label 데이터가 많아지면 무용한 결과가 나타남
self-training은 이것보다 더 유용할 것으로 생각 됨
우리는 self training의 확장성(scalability)과 일반성(generality)을 다뤄볼 예정이다.
Methodology
비교 집단군을 3개로 잡는다.
-
Data Augmenetaion : flipcrop, autoaugment, randaugment
-
pre-training including self-supervised : efficientNet with noisy student method
-
self-training : pseudo labels and human labels jointly
experiment
-
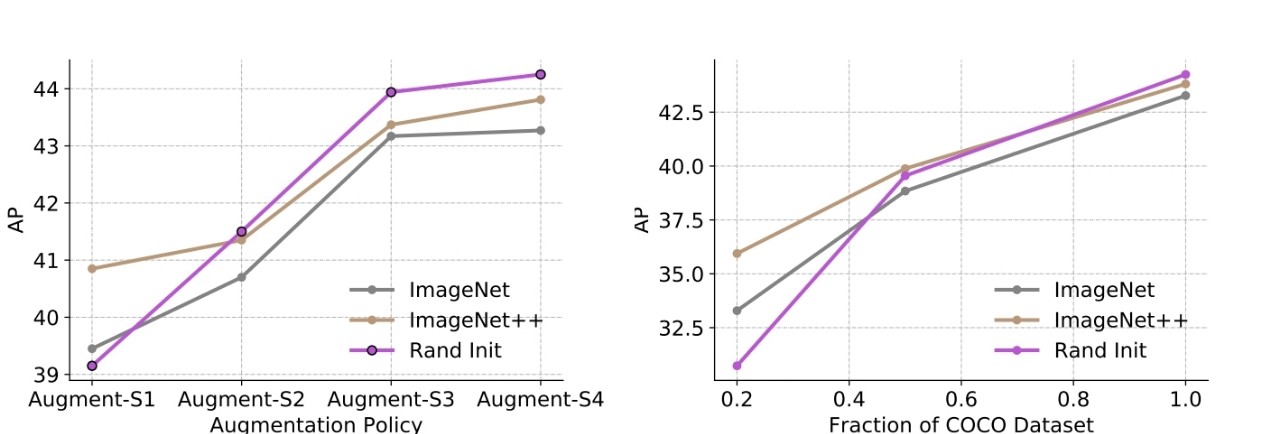
pre-training hurts performance when stronger data augmentation is used.
-
more labels data diminishes the value of pre-training
-
self-training helps in high data/strong augmentation regimes, even when pre-training hurts
-
self-training works across dataset size and is additive to pre-training
-
self-supervised pre-training also hurts when self-training helps in high data/strong augmenetation regimes
Discussion
-
pre-training is not ware of the task of interest and can fail to adapt, otherwise self-training with supervised learning is more adpative to the task of interset(jointly training)
-
pre-training방법론은 사람이 라벨을 많이 넣어주면 오히려 성능에 해가 됨, 그러나 self-training pseudo label은 도움이 됨(additive 함)
- 결론
한계 : self-training은 finetuning보다 더 많은 resource를 요함
장점 : scalability, generality and flexibility of self-training
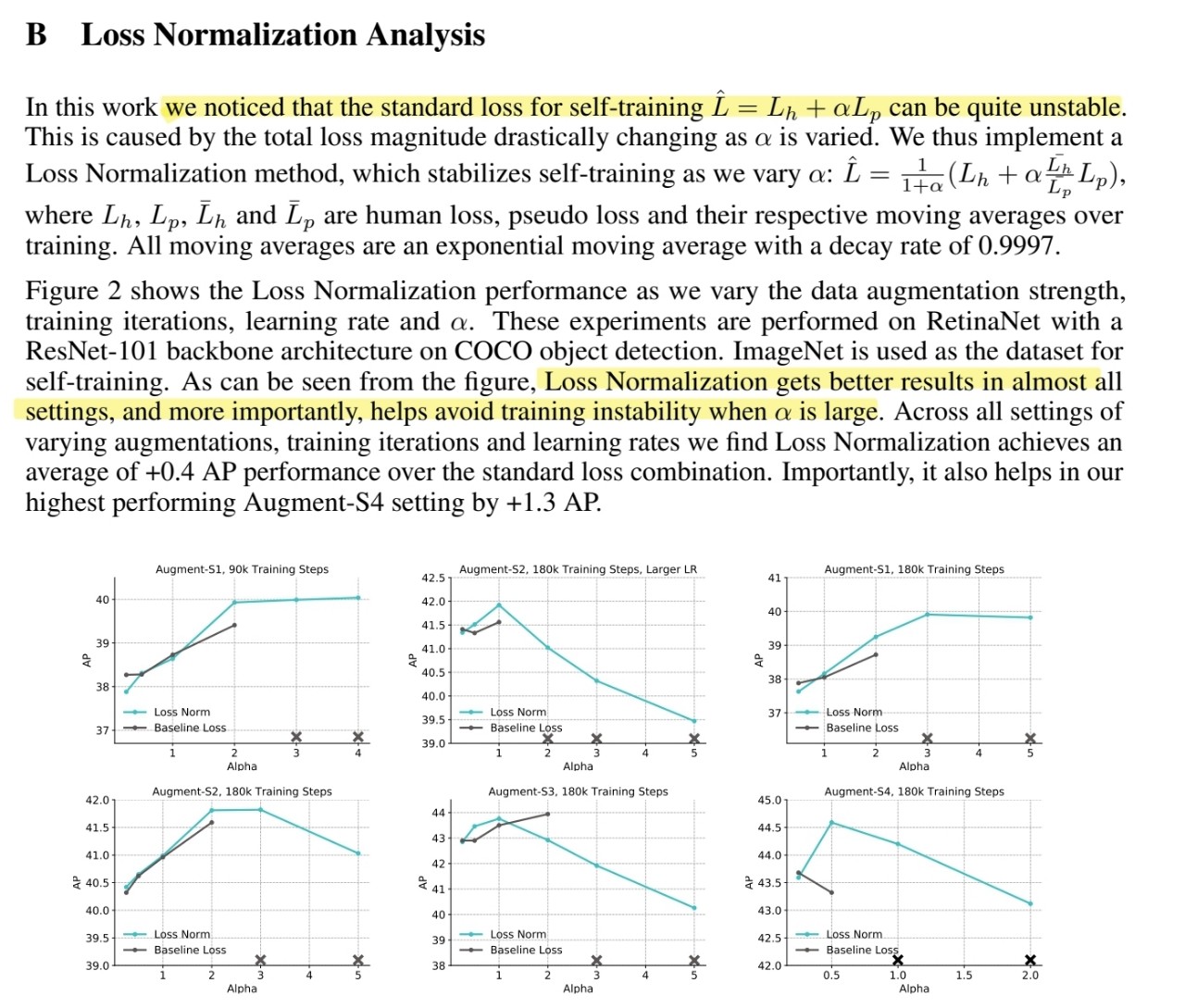
loss normalization of self-training