자연어 처리 분야에 입문을 하면 가장 많이 사용하게 되는 라이브러리 중 하나는 Huggingface이다.
Huggingface에는 다양한 거대 언어모델들의 구조가 구현되어 있고, 사전학습된 가중치들이 업로드 되어있어 편리하게 거대언어모델들을 사용할 수 있게 해준다.
하지만 기본 구조를 가지고 있는 것이기 때문에, 내가 직면한 태스크를 보다 잘 수행하기 위해서는 내부구조를 잘 알고 수정할 수 있어야 한다. 단순히 "from_pretrained("모델명")" 으로 불러다가만 쓰기에는 태스크의 성능을 끌어올리기 매우매우 어려울 수 있다.
자연어 처리 태스크에는 여러가지가 있지만, Huggingface는 대부분 모델들이 유사한 구조로 구현이 되어있기 때문에 하나의 모델만 잘 분석해봐도 다른 모델의 구조를 파악하는 것이 쉬워진다.
그래서 문장 분류 태스크를 수행하기 위해 사용하는 BertForSequenceClassification 클래스를 한번 뜯어보려고 한다.
모델구조(BertEmbedding) 살펴보기
아래 그림은 BertForSequenceClassification을 구조화해 둔것이다.
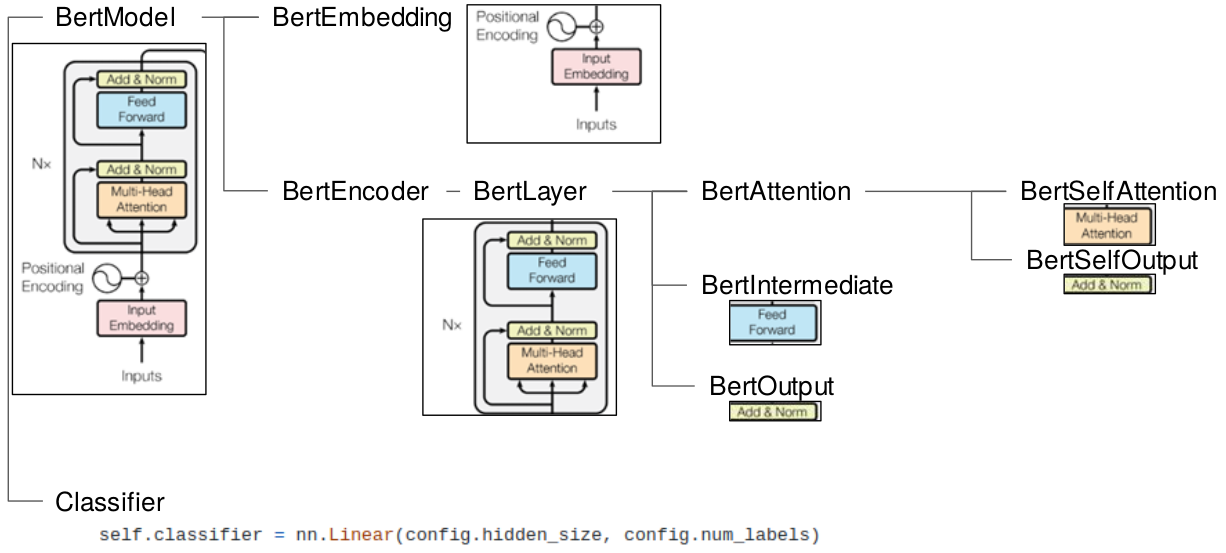
그림을 살펴보면 가장 윗단에서 BertModel과 Classifier로 나뉘게 된다.
BertModel이 Transformer layer가 여러겹으로 쌓여있는 본체이다.
Classifier는 태스크에 따라 달라질 수 있는 task-specific한 부분이라고 생각하면 된다.
BertModel을 조금더 살펴보면, BertEmbedding과 BertEncoder 부분으로 나누어진다.
BertEmbedding은 문장을 입력으로 받아 다음 3개의 임베딩 값을 만들고, 더해서 반환해주는 역할을 한다.
- token embedding (각 토큰들의 임베딩)
- segment embedding (문장이 2개일 경우, 첫번째 문장은 0, 두번째 문장으 1)
- position embedding (토큰의 위치에 따른 임베딩)
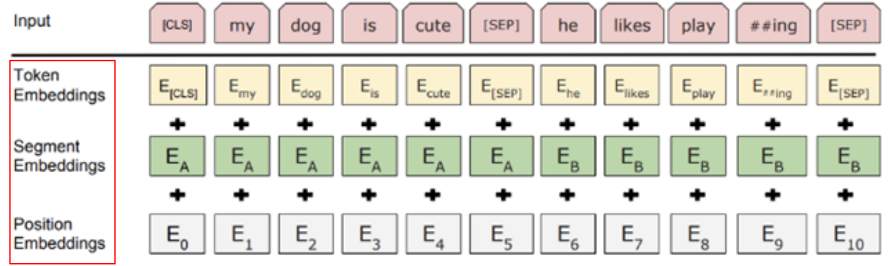
실제로 구현부를 살펴보면, 3개의 임베딩 레이어를 가지고 있는 것을 볼 수 있다.
그리고 forward 부분에서 3개의 임베딩 벡터를 더해서 반환해주는 것도 확인 할 수 있다.
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# ...생략... #
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings수정 및 활용해보기
이제 BertEmbedding의 구조를 파악했으니, 수정도 할 수 있다.
아래처럼 새로운 임베딩 레이어를 정의하는 것으로 쉽게 레이어를 추가할 수 있다.
self.new_embeddings = nn.Embedding(#유니크값 개수#, #임베딩벡터 차원크기#, padding_idx=config.pad_token_id)forward에서도 아래와 같이 기존 임베딩 벡터에 더해주는 방식으로 활용할 수도 있다.
물론 더해주지 않고 평균을 낼수도 있고, 활용방법은 한번 고민해보면 좋을 것 같다.
new_embeddings = self.new_embeddings(new_input)
embeddings = inputs_embeds + token_type_embeddings + new_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings하나의 예시로서, Relation Extraction(RE)이라는 태스크가 있다.
문장이 주어지고, 문장안에서 두개의 엔티티가 주어졌을 때, 두 엔티티 사이의 관계를 예측하는 태스크이다.
- 손흥민의 아버지는 손웅정이다.
- 손흥민 - 손웅정 : 부모관계
RE 데이터셋의 경우 손흥민, 손웅정에게 "사람"이라는 타입이 주어진 데이터셋이 있다고 했을때, 타입에 대한 임베딩 레이어를 만들어 "손흥민" 토큰과 "손웅정" 토큰에 "사람"이라는 임베딩 벡터 값을 더해주어 정보를 추가해줄 수도 있다. (실제로 RE 태스크 논문들에서 많이 활용하고 있다.)
이런식으로 문장을 가지고만 판단을 하던 언어모델에 추가적인 정보를 주는 방식으로 Embedding layer를 수정하고 학습시키는 것이 가능하다.
다음에는 본체인 BertEncoder의 구조를 살펴보자!
