웹과 데이터 계층은 이렇게 동작한다!

언젠가 나도 대규모 시스템을 설계해보고싶다는 꿈을 가지고 책을 구입했다! 다 읽은지는 좀 됐는데 이제서야 정리해서 포스팅중이다.
1. 규모확장성
기초 설계에 대해 정리해보겠다.
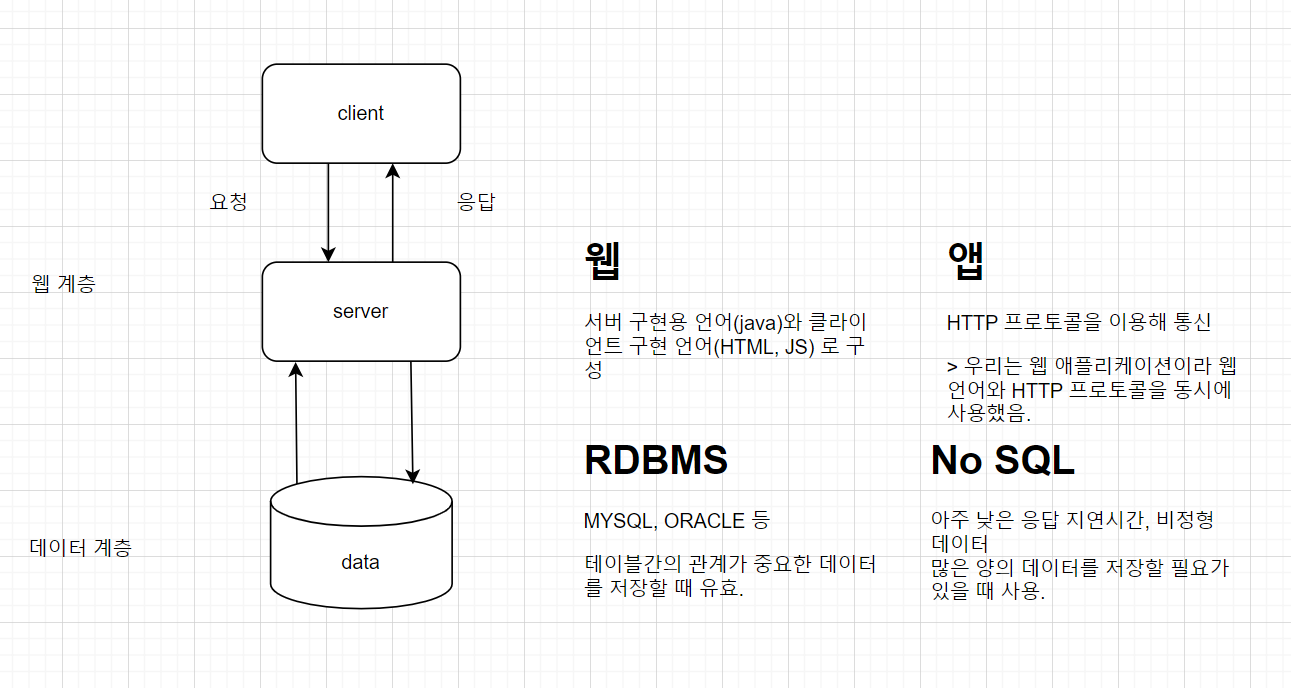
학원에서 진행한 프로젝트는 모두 위와 같은 형태로 시스템이 구성됨.
만약 우리가 기획한 프로젝트가 이용자수가 늘고, 더 이상 하나의 서버에서
정보를 처리할 수 없는 임계점에 도달했다고 가정해보자.
그럼 규모 확장을 고려해야하는데, 먼저 DB쪽에서는
Scale-Up , Scale-Out 방식 이 있음.
수직적 규모확장(Scale-Up)
단순함.
서버의 성능을 올리는 방법.
하드웨어를 추가한다던가 저장스토리지를 추가한다던가.
수평적 규모확장(Scale-Out)
복잡함.
구성에 비용이 들 수 있음.
서버를 추가하는 방법
수직적 규모확장의 문제점
확장에 한계가 존재함, 장애에 대한 자동 복구, 다중화 지원 안함
장애 발생시 서버 다운
그렇다면 수평적 규모확장을 이루었을 때 어떻게 구성되는지?
웹 서버는 로드밸런서를 통해 구조확장을 할 수 있다.
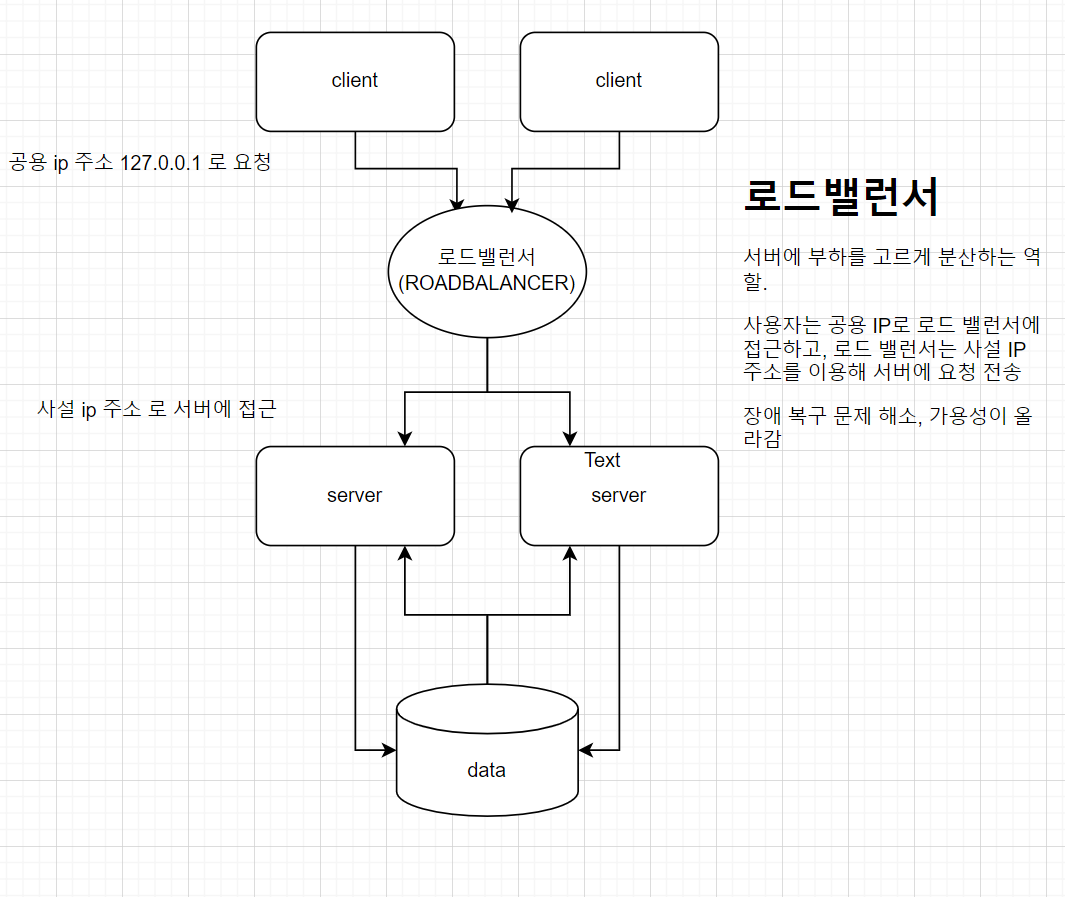
시스템에 로드밸런서를 추가한 설계
그럼 DB는???
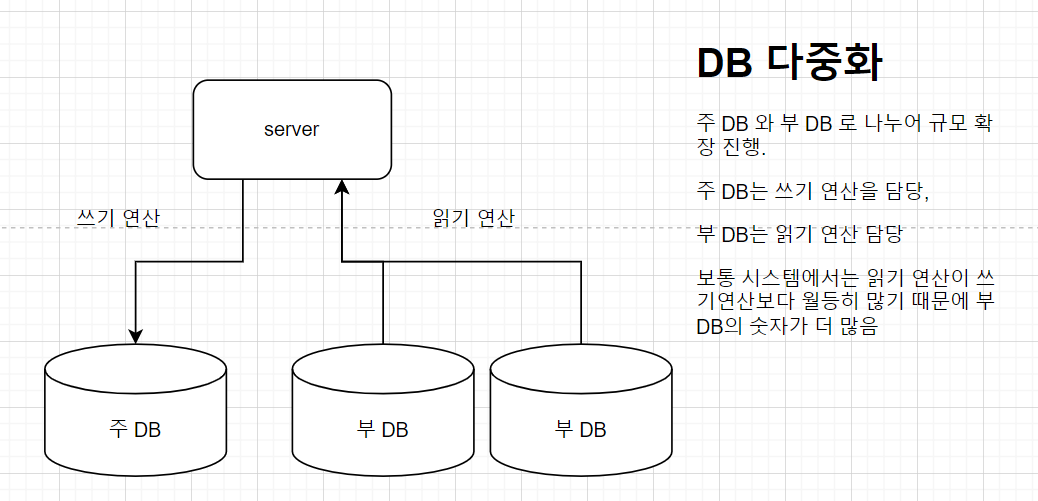
다중화를 통해 데이터 계층을 확장했다.
이를 합쳐보면 아래와 같이 시스템이 구성된다.
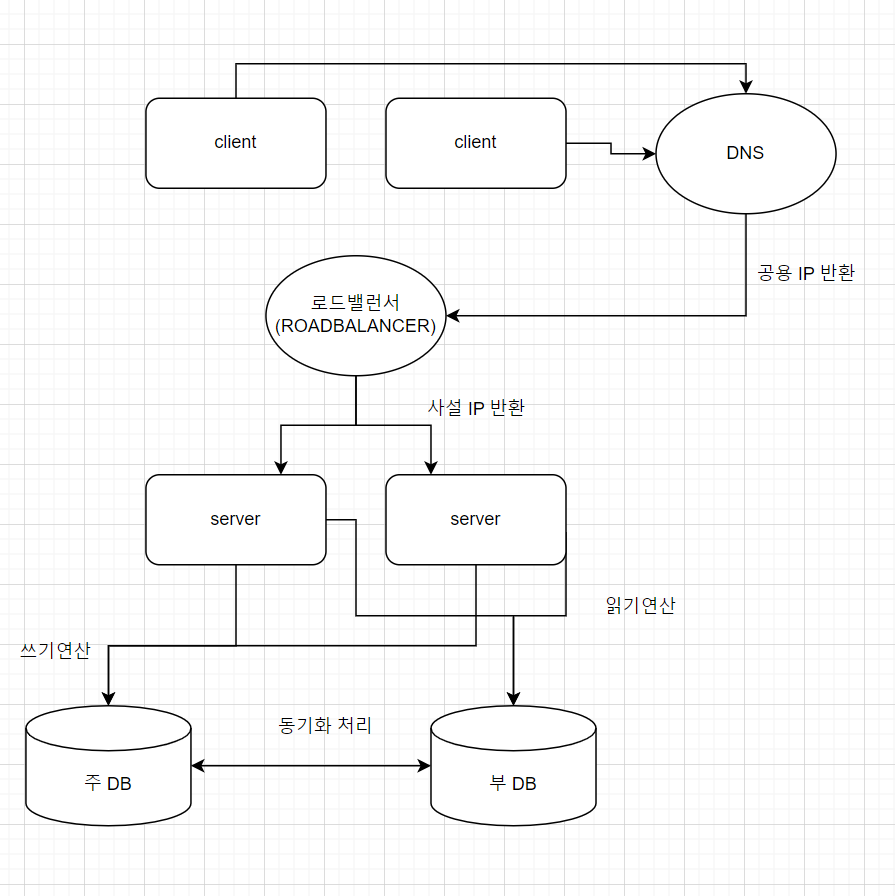
이제 지연시간을 개선해 보자. 캐시를 쓰면 정적콘텐츠를 캐시에 저장해 효과적으로 지연 시간을 개선할 수 있다.
캐시?
데이터가 잠깐 보관되는 곳.
DB 연산을 줄일 수 있음. 캐시 계층의 규모를 독립적으로 확장 가능.
캐시를 사용할 때 고려사항
(복잡하고 어려운 기술이라 고려해야할게 많음)
1. 언제 써야하는가
갱신이 적고 읽기는 많은 데이터를 캐시에 저장해 사용하면 좋다.
-
어떤 데이터를 캐시에 두어야 하는가
영속적인 데이터, 변하지않는 데이터는 캐시에 두면 안댐! 그런 데이터는 DB에 저장하자.
-
캐시는 언제 만료되는가
만료 시간이 너무 짧으면 DB참조가 많아짐
너무 길면 원본과 차이가 발생할 수 있음 -
데이터 일관성은 어떻게?
DB원본과 캐시의 사본이 같은지
저장소의 원본을 갱신하는 연산이 캐시를 갱신하는 연산과 다른 트랜젝션으로 처리될때 일관성이 깨질 수 있음
여러지역에 시스템 확장 시 일관성 유지가 어려워짐
Ø 관련 논문이 페이스북에서 제출 -
장애대처방안
-
캐시 메모리 크기
-
데이터 방출 정책
캐시가 꽉 찼을 때 추가 데이터를 넣어야 할 경우, 기존 데이터를 내보내야 함.
어떤식으로 페이지 교체를 할 건지
LFU,FIFO 등 사용
이런 내용들을 CDN에서 처리한다!
정적 콘텐츠를 캐싱해 저장소에 저장해놓고 사용.
클라이언트가 웹사이트 방문시 가장 가까운 CDN에서 정적 콘텐츠 전송
CDN을 사용하게 되면 정적 컨텐츠를 서버에서 서비스하지않음
CDN으로 더 나은 성능 보장 > 캐시가 DB 부하를 줄여주기 때문
이제 데이터 계층은 확장성있는 구성을 완료했다.
그렇다면 서버 계층은 어떻게 확장성있는 구조를 만들것인가!
웹계층 수평확장
=> 상태정보 제거
상태정보를 RDB나 NOSQL에 저장, 무상태 웹계층(STATELESS)
학원에서 만든 프로젝트의 웹 서버는
A B C 모두 각각의 상태정보를 각각의 서버에 저장했던 것..
상태정보 의존적인 아키텍쳐임!
무상태 아키텍쳐
=> 세션 데이터를 웹 계층에서 분리하고 지속성 DB에 저장하도록 변경
공유 저장소는 RDB, Memcached/redis, Nosql 등
책에서는 Nosql을 사용했음.
Nosql의 장점
규모확장성이 좋음
트래픽에 따라 웹 서버를 자동추가, 삭제하는 자동 규모확장이란 아키텍쳐가 있음,.
상태정보가 제거되어 트래픽 양에 따라 웹서버를 넣거나 빼면 자동으로 규모확장
서비스의 글로벌화
데이터 센터 지원
로드 밸런서를 통해 지리적 라우팅.
1. 트래픽 우회
가장 가까운 DNS로 트래픽 처리
- 데이터 동기화
장애가 생겨 트래픽이 다른 DB로 우회시 해당 데이터 센터에 데이터가 없을 수도 있다..!
=> 데이터 다중화를 통해 해결 - 테스트 및 배포
여러 위치에서 테스트 해보는게 중요함. 또한 배포도구의 자동화 역시 중요한 과제 넷플릭스의 업로드 컨텐츠 동기화에서 배워볼 수 있음,
서비스를 추가로 더 확장하기 위해서는
시스템의 컴포넌트를 분리해 독립적으로 확작되게 만들어야 함.,
=>메시지 큐 활용
로그, 매트릭, 자동화 도구 역시 유지 보수, 관리에 도움이 됨.
로그 :
매트릭 :
자동화도구 :
DB 규모 확장
=> 큰 규모의 시스템을 만들어야 할 경우 시스템을 최적화하고 더 작은 서비스 단위로 분할
1장에서 살펴본 규모확장 기법
1. STATELESS 웹계층
2. 모든 계층을 다중화
3. 가능한 한 많은 데이터를 캐싱
4. 여러 데이터센터 지원
5. 정적 컨텐츠는 CDN 사용
6. 데이터 계층은 샤딩해 DB에 나눠저장
7. 각 계층을 독립적으로 서비스