
뷰 : 가상의 테이블
하나 이상의 테이블을 합하여 만든 가상의 테이블장점
편리성:
자주 사용하는 복잡한 쿼리를 미리 정의
보안성:
각 사용자별로 필요한 데이터만 선별
중요한 쿼리의 경우 암호화 가능
>개인정보같은 민감한 정보 제외 가능
논리적 독립성:
개념 스키마의 데이터베이스 구조가 변해도 외부 스키마에 영향을 주지않음
특징
a. 원본 데이터 값에 따라 같이 변함
b. 독립적인 인덱스 생성이 어려움
c. 삽입, 삭제, 갱신 연산에 많은 제약이 따름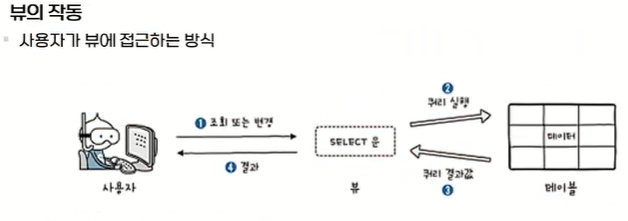
뷰는 읽기 전용으로 사용 (포인터의 개념)
그 위치를 참조한다!
뷰에 접근하면 select가 사용되고 그 내용에 접근함
바로가기 아이콘과 똑같음뷰는 단순 뷰와 복합 뷰로 나뉨
단순 뷰:
하나의 테이블만 참조한 것
복합 뷰:
여러 개의 테이블을 참조한 것
select문이 간단해질 수 있다!


ALTER
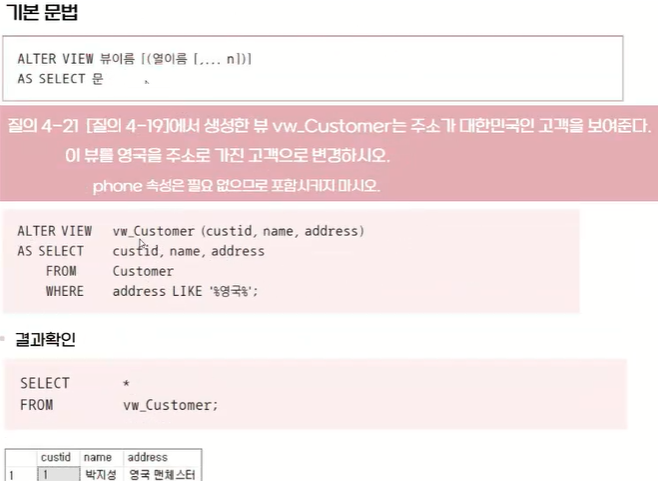
DROP

인덱스
검색시 결과를 빠르게 찾아내기 위해 사용
데이터의 양이 많을수록 인덱스의 효율성이 증가한다.
DBMS는 데이터를 고유한 방식으로 저장하여 관리
보조기억장치:
실제 데이터가 저장되는 곳
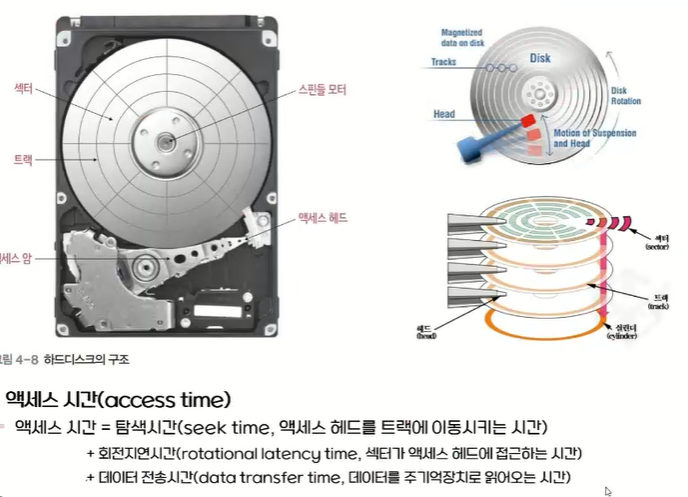
하드디스크:
가장 많이 사용되는 장치
하드디스크의 구조
버퍼 :
임시 저장 장치, 스택
로그 :
서버에서 더 자세히 배워보자
트랜잭션:
SQL문을 처리하는 가장 작은 단위
인덱스의 필요성
속도를 빠르게 하기 위한 개념
인덱스
데이터베이스에서 인덱스는 원하는 데이터를 빨리 찾기위해
튜플의 키 값에 대한 물리적인 위치를 기록해둔 자료구조 > B-TREE
B-TREE
관계 데이터베이스에서 대부분 인덱스는 B-TREE형태
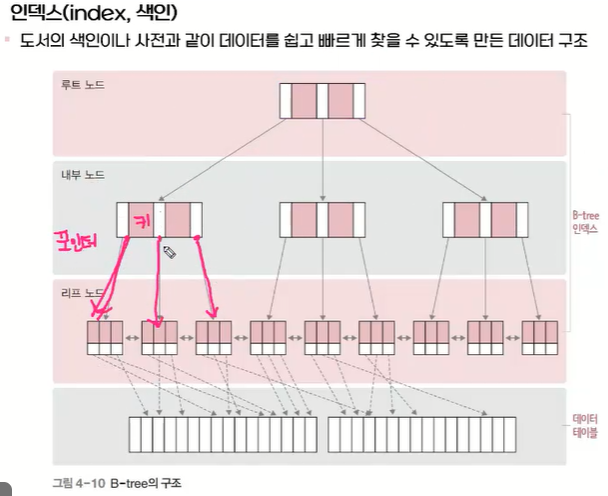
내가 가리킨 값의 정보가 나오게 된다인덱스
각 노드는 키값과 포인터를 가진다(키값은 오름차순으로 저장)
키 값 좌우에 있는 포인터는 각각 키값보다 작은 값과 큰 값을 가진 다음 노드를 가리킨다
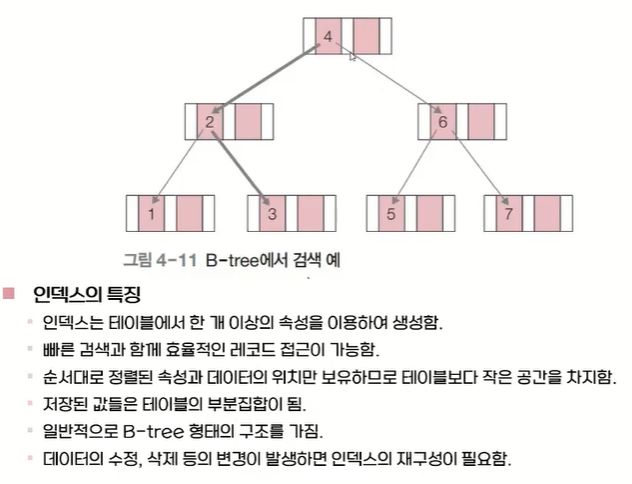
키값을 비교해서 다음단계, 이전단계의 노드(값)을 빠르게 찾을 수 있다어떤 구조인지는 몰라도 된다 잘 쓰기만 하면 됨!
클러스터드 인덱스:
연속된 키 값의 레코드를 묶어서 같은 블록(같은 열)에 저장하는 방법
테이블당 하나만 생성가능
기본 키로 지정하면 자동으로 생성됨
인덱스로 정렬됨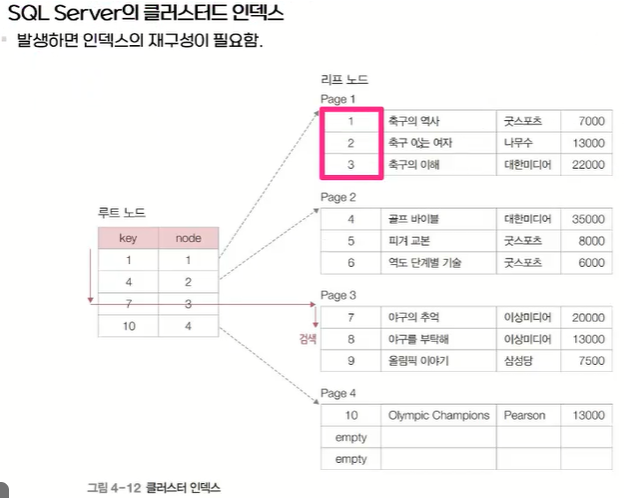
보조인덱스
클러스터드 인덱스가 아닌 모든 인덱스
참조형태이다. 위치를 저장하고 있음(포인터)
인덱스는 필요한 인덱스 한두개만 만드는게 좋음
많이 만들수록 여러 번 반복해야하기때문에 속도가 느려진다
고려사항
인덱스는 WHERE절에서 자주 사용됨
속성이 가공되는 경우 사용하지않음
속성의 선택도가 낮을 때 유리함(속성의 모든 값이 다른 경우
가공 : 연산과정이 들어간 경우
선택도 : 남자 여자 기타 => 선택도가 매우 높다
1서로 다른 값의 개수 생성 문법


워크밴치를 이용해서 만드는경우가 더 많음데이터베이스 프로그래밍
프로그래밍
프로그램을 설계하고 소스코드를 작성하여 디버깅하는 과정
데이터베이스 프로그래밍
일반 프로그래밍과 다른 SQL언어를 포함함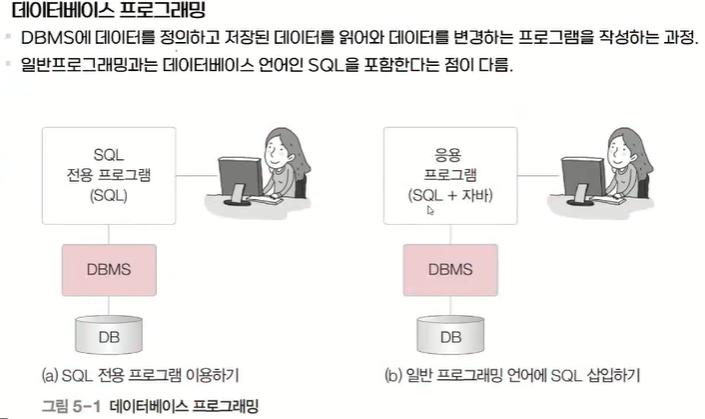
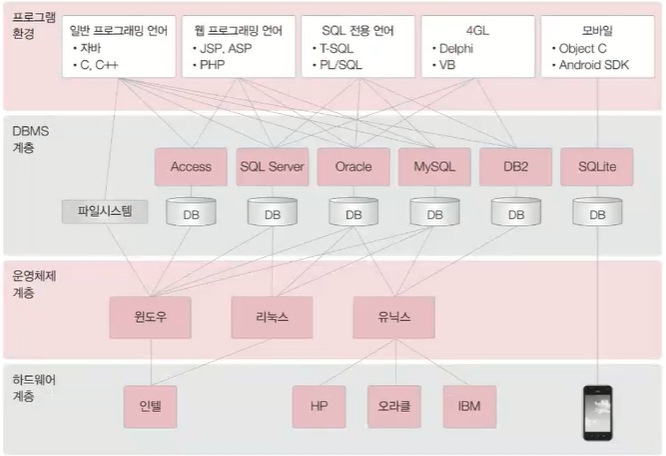
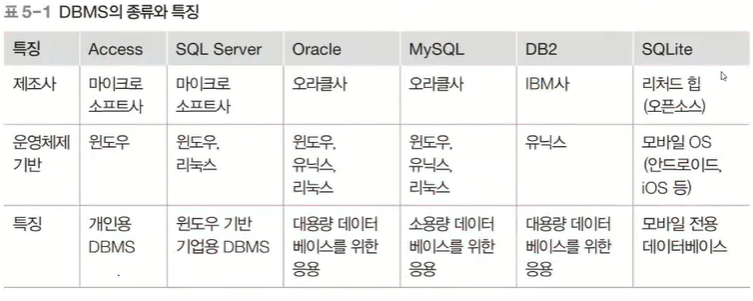
MYSQL 또는 ORACLE을 사용하게 될 것프로시저
거의 안씀 우린 서버딴에서 함수를 이용할 것이야
정처기 준비!
매개변수 >> 파라미터

커서 :
실행결과 테이블을 한번에 한 행씩 처리하기 위하여 테이블의 행을 순서대로 가리키는데 사용
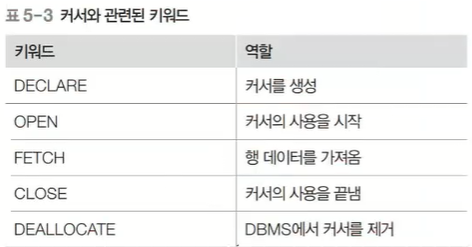

자바에서 ITERATOR 와 유사함
트리거
데이터의 변경문이 실행 될 때 자동으로 따라서 실행되는 프로시저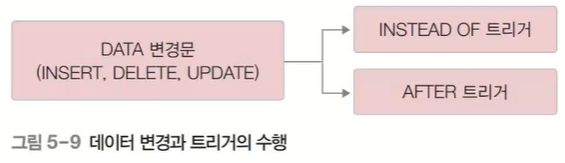


사용자 정의함수
입력된 값을 가공하여 결과 값을 되돌려줌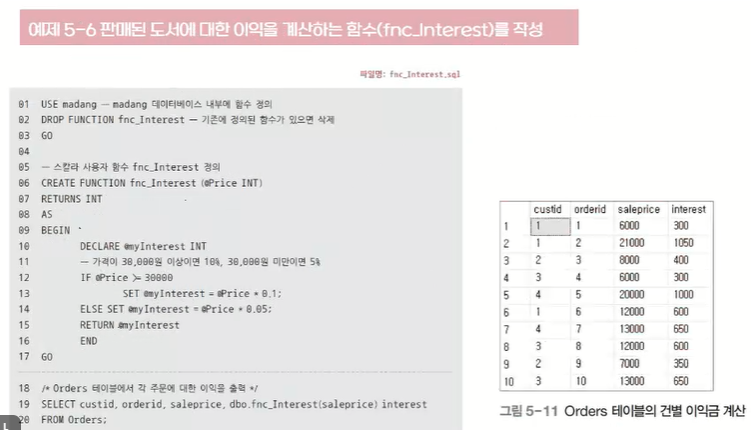

트리거 부분은 기억해둘 것!
T/SQL 문법 요약

자바 연동

JDBC 드라이버
데이터베이스와 자바를 연결하는 드라이버이후 서버딴에서 자세히 할 것임

개발자가 되려는 학생입니다