우연한 기회로 읽게 된 내용인데 흥미로워서 가져왔다. 출처
Quick sort와 Merge sort는 nlogn의 시간복잡도를 가지는 대표적인 정렬 방법이다.
일반적으로 Quick sort가 Merge sort보다 크다. 그 이유는 Locality와 관련이 있다. Locality의 개념을 알아보고 왜 Quick sort가 더 빠른지 알아보도록 하자.
Locality
지역성(Locality)은 CPU가 짧은 시간 범위 내에 일정 구간의 메모리 영역을 반복적으로 엑세스하는 경향을 말한다.
메모리 내의 정보를 균일하게 엑세스 하는게 아닌, 짧은 시간내에 특정 부분을 집중적으로 참조하는 특성이다.
void f()
{
//간단한 작업을 수행
}
void g()
{
int arr[1000];
for(int i=0;i<1000;++i){
//arr참조
}
}
int main(void)
{
f();
g();
return 0;
}위 코드는 메모리의 모든 부분을 균일하게 엑세스 하지않다. 거의 f함수나 g함수 내에서 대부분의 실행이 이루어 진다. 현재 프로세스의 실행 패턴을 보고 가까운 미래에 프로세스의 코드와 데이터를 합리적으로 사용할 수 있도록 예측 할 수있다. 그래서 해당 코드와 데이터를 캐시에 올린다면 아주 빠른 성능을 얻을 수 있게 된다. 위의 함수 g에서, i와 array는 반복적으로 CPU가 엑세스 한다. 해당 변수를 캐시에도 올린다면 아주 큰 효과를 얻을 수 있다.
여기에 demand paging의 개념으로 확장해보자.
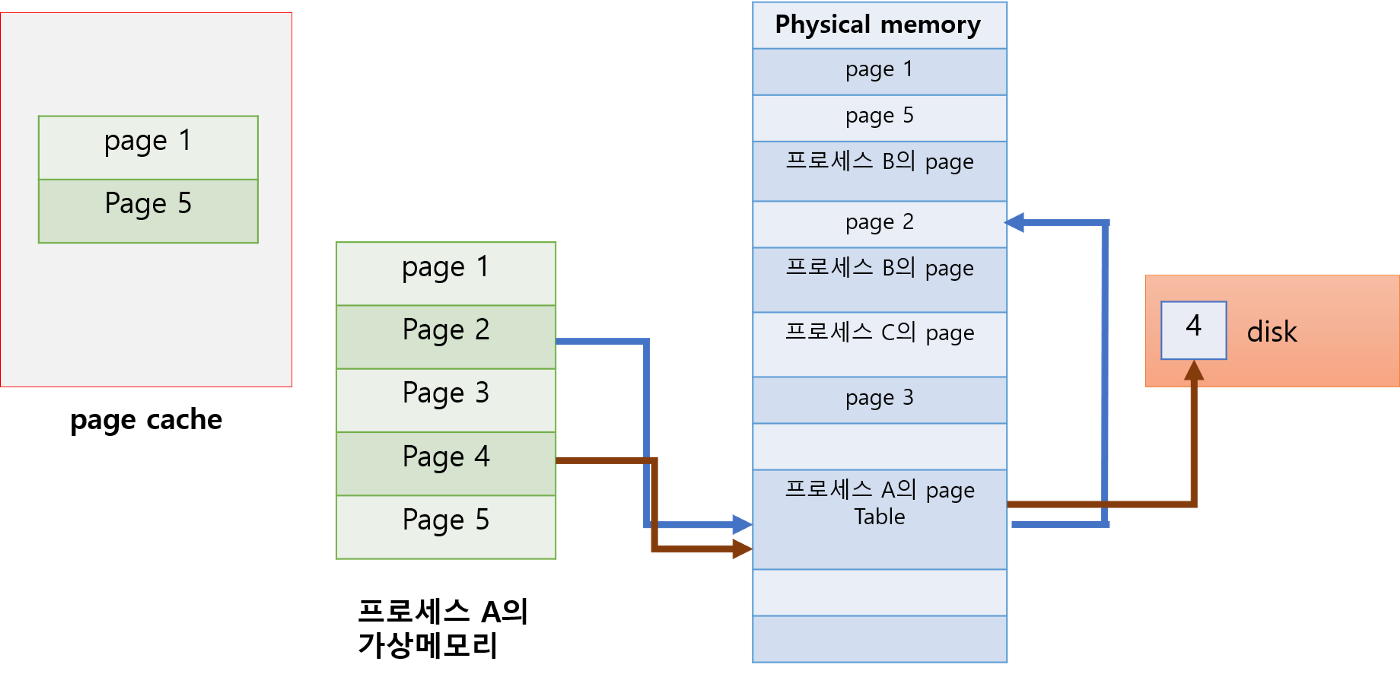
자주 사용되는 페이지는 물리 메모리에만 두는게 아니라, 캐시에도 둔다. 그래서 빠르게 해당 페이지에 접근하게 된다.
하지만, 지역성의 정도가 떨어질 때(=여러 페이지에 있는 코드 및 데이터들을 접근할 때) cache에 해당 페이지를 올려도 의미가 없어진다. 캐시를 접근하는게 아니라 메인메모리를 접근하기 때문이다. 결국, cache에 해당 페이지가 있을 수록 더 빠른 데이터 접근을 할 수 있게 된다.
정렬 알고리즘 평가 기준
Locality
왜 Locality가 정렬 알고리즘의 평가 기준이 될 수 있을까?
정렬하려고 하는 데이터들이 다른 페이지로 이동하는 것 없이, 자신의 페이지에서 계속 있는게 좋다. 다른 캐쉬에 없는 페이지로 이동하면 page cache hit 비율이 떨어지게 된다. 그래서 결국 physical memory로 접근을 해야 하기 때문에 시간이 상대적으로 오래 걸린다. 만약 자신의 페이지에 계속 있는다면, cache에서 반복적으로 접근하기 때문에 시간이 덜 걸린다. 결국 데이터가 이동하지 않을 수록 좋다.
비교, swap 횟수
평소 알고리즘 전공수업에 했던 방법이다.
정렬 알고리즘의 평가는 알고리즘의 비교, swap 횟수를 이용할 수 있다.
//bubble sort
for(int i=0;i<n-1;++i) {
for(int j=0;j<n-1-i;++j) {
if(arr[j]>arr[j+1]) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}위 알고리즘은 구현이 간단하지만 시간복잡도는 n²인 버블 정렬이다. 버블 정렬은 비교 횟수 n², swap횟수 n²이다. 알고리즘의 평가가 단순히 코드상으로 몇 번 비교및 swap 되는 지를 통해서 정렬 알고리즘을 평가한 것이다.
머지, 퀵정렬은 재귀함수로 구현되어 있다. 이 함수들의 시간복잡도를 구하려면 반복대치 방법을 이용하면 된다.
Sort animation
Merge sort
애니메이션 효과를 보면, 끝과 끝을 계속 왔다 갔다하면서 데이터를 탐색한다. 또한, 내부적으로 해당 데이터들을 복사해야하기 때문에 시간이 더 오래걸린다. 한 개의 사각형들이 한 개의 페이지라면, 캐쉬의 페이지가 계속해서 바뀌기 때문에 locality의 효과가 떨어지게 된다. 캐쉬에 5개의 페이지가 들어간다면, 그 접근하려는 페이지들이 계속 캐쉬 hit이 되지 않기 때문에 계속 바뀐다.
Quick sort
처음에 전체 탐색을 하면서 pivot을 기준으로 좌우로 나눈다. 그 후, 좌우로 나눠서 재귀적으로 pivot을 기준으로 좌우를 나눈다. 해당 과정을 반복하면 정렬이 끝난다.
각 데이터들이 넓은 범위에서 움직이지 않는다. 병합정렬은 좌우로 계속 움직이면서 정렬한다. 반면, 퀵 정렬은 한정적인 범위에서 데이터들이 움직인다. 그래서 자주 캐시에 있는 페이지들을 바꿀 필요가 없다. (병합정렬에 비해서) 퀵정렬은 하드웨어적으로 더 효율적인 정렬 방법이다.
정리
대부분의 프로그램들은 짧은 시간동안 반복적으로 접근하는 데이터들이 있다. 이 성질을 참조의 지역성이라고 한다. 그래서 지역성을 띄는 데이터들을 더 빠르게 접근하기 위해서 캐쉬라는 하드웨어를 이용한다. 메인메모리보다 더 빨리 접근하기 위해서 만든 하드웨어이다. 위에서 살펴 본 것과 같이, 퀵정렬은 병합정렬보다 더 참조의 지역성의 성질을 띤다. 즉, 캐쉬의 도움을 더욱 받을 수 있게 된다. 그래서 일반적으로 퀵정렬이 더 빠르다.
출처
why is quicksort better than mergesort //stackoverflow
https://www.geeksforgeeks.org/quicksort-better-mergesort/
merge sort, quick sort //wikipedia
