김영환님의 강의 자바 ORM 표준 JPA 프로그래밍 - 기본편 보면서 공부한 내용입니다.
🏊♀️ 섹션 1
JPA 소개
📝 JPA란?
- Java persistence API
- 자바 진영의 ORM 기술 표준
💡 ORM이란?
- Object-relational mapping(객체 관계 매핑)
- 객체는 객체대로 설계
- 관계형 데이터베이스는 관계형 데이터베이스대로 설계
- ORM 프레임워크가 중간에서 매핑
→ 패러다임 불일치 해결- 대중적인 언어에는 대부분 ORM 기술이 존재
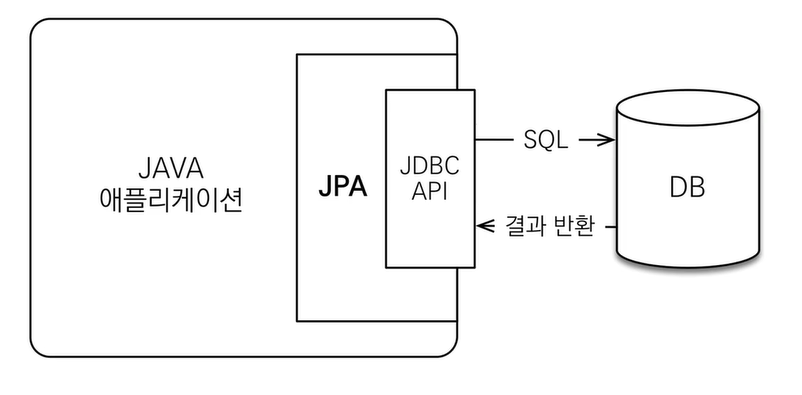
📝 JPA는 애플리케이션과 JDBC 사이에서 동작
- JAVA 애플리케이션과 DB가 통신하려면
JDBC API를 사용하는데 개발자가 직접 사용했다면, JPA는 개발자 대신 사용한다.
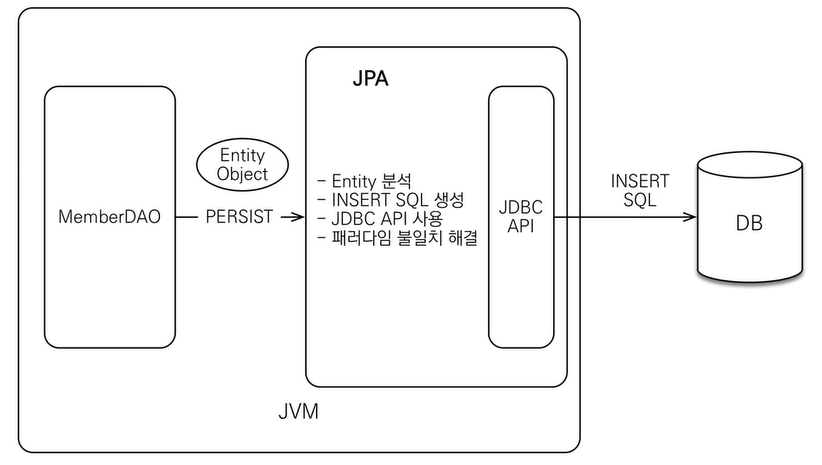
JPA동작 - 저장
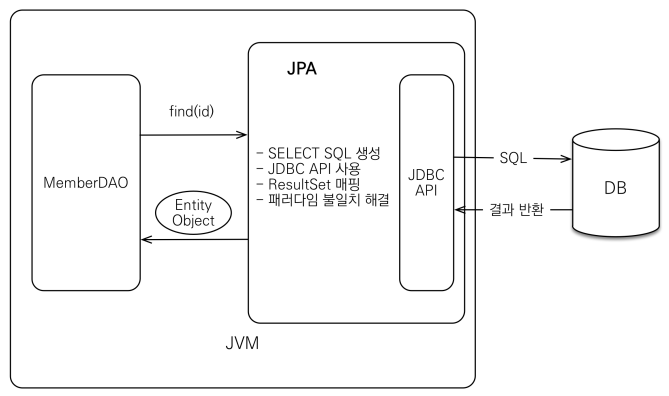
JPA동작 - 조회
JPA는 인터페이스의 모음 (하이버네이트, EclipseLink, DataNucleus)
📝 JPA를 왜 사용해야 하는가?
- SQL 중심적인 개발에서 객체 중심으로 개발
- 생산성

- 유지보스
- 기존 : 필드 변경시 모든 SQL 수정
- JPA : 필드만 추가하면 됨, SQL은 JPA가 처리
- 패러다임의 불일치 해결
- 상속

✅ 조회시 JOIN도 알아서 해준다

-
연관관계, 객체 그래프 탐색

-
신뢰할 수 있는 엔티티, 계층
✅ 지연로딩(Lazy Loading)이라는 기술로 가능하다

-
비교하기

- 성능
-
1차 캐시와 동일성 보장
✅ 첫번째 조회시 sql 쿼리로 조회한 후에 두번째 조회시 jpa가 가지고있는 메모리상(캐시)에서 반환한다

-
쓰기 지연


-
지연 로딩과 즉시 로딩
✅ 지연 로딩 : 객체가 실제 사용될 때 로딩
(ex : member만 먼저 조회하고 team을 후에 사용할 때)
✅ 즉시 로딩 : JOIN SQL로 한번에 연관된 객체까지 미리 조회
(ex : member와 team을 조회할 때 거의 같이 조회할 때)

- 데이터 접근 추상화와 벤더 독립성
- 표준
🏊♀️ 섹션 2
JPA 시작하기
📝 프로젝트 생성
💡 H2 데이터베이스 설치와 실행
- JPA는 데이터베이스 기반 개발을 해야 하기 때문에 h2database를 사용
- 최고의 실습용 DB
- 가볍다.(1.5M)
- 웹용 쿼리툴 제공
- MySQL, Oracle 데이터베이스 시뮬레이션 기능
- 시퀀스, AUTO INCREMENT 기능 지원
💡 메이븐
- http://maven.apache.org/
- 자바 라이브러리, 빌드 관리
- 라이브러리 자동 다운로드 및 의존성 관리
- 최근에는 그래들(Gradle)이 점점 유명
- 라이브러리 추가 - pom.xml
✅ h2데이터베이스의 버전은 내가 설치한 버전과 꼭 동일하게 해야한다
h2에SELECT H2VERSION() FROM DUAL;를 입력하면 설치한 버전을 확인할 수 있다
<dependencies>
<!-- JPA 하이버네이트 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>5.3.10.Final</version>
</dependency>
<!-- H2 데이터베이스 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.200</version>
</dependency>
</dependencies>- JPA 설정하기 - /META-INF/persistence.xmlMpersistence.xml
✅ javax로 시작 : jpa 인테페이스 중 어떤 것을 써도 문제 없음(그대로 적용됨. 즉, 표준)
✅ hibernate로 시작 : jpa 인테페이스를 바꾸면hibernate로 써진 설정을 모두 바꿔야함(즉, hibernate 전용 옵션)
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<property name="javax.persistence.jdbc.driver" value="org.h2.Driver"/>
<property name="javax.persistence.jdbc.user" value="sa"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/~/test"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<!-- 옵션 -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.use_sql_comments" value="true"/>
<!--<property name="hibernate.hbm2ddl.auto" value="create" />-->
</properties>
</persistence-unit>
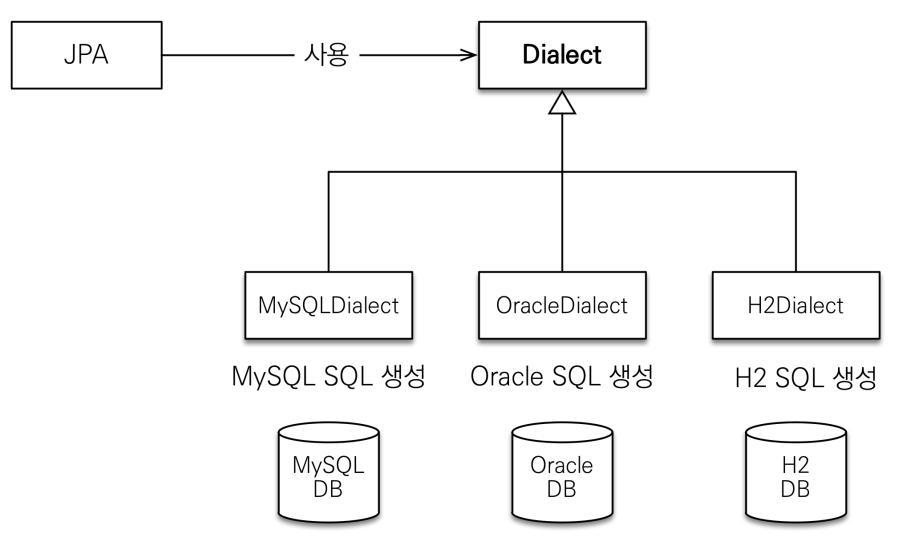
</persistence>📝 데이터베이스 방언
-
JPA는 특정 데이터베이스에 종속 X
-
각각의 데이터베이스가 제공하는 SQL 문법과 함수는 조금씩 다름
- 가변 문자: MySQL은 VARCHAR, Oracle은 VARCHAR2
- 문자열을 자르는 함수: SQL 표준은 SUBSTRING(), Oracle은 SUBSTR()
- 페이징: MySQL은 LIMIT , Oracle은 ROWNUM
-
방언: SQL 표준을 지키지 않는 특정 데이터베이스만의 고유한 기능
애플리케이션 개발
📝 JPA 구동방식
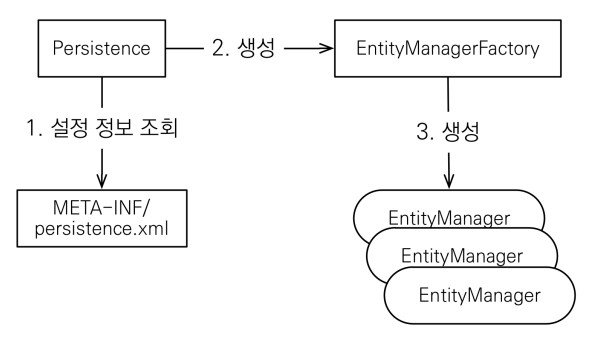
💡 주의
- 엔티티 매니저 팩토리는 하나만 생성해서 애플리케이션 전체에서 공유
- 엔티티 매니저는 쓰레드간에 공유X (사용하고 버려야 한다).
- 왜? 엔티티 매니저는 고객의 요청이 올 때 마다 계속 사용 및 완료를 실행하기 때문- JPA의 모든 데이터 변경은 트랜잭션 안에서 실행
오류 발생
-
Module ex1-hello-jpa SDK 17 does not support source version 1.5.
java Compiler을 1.5에서 8로 수정하여 해결
참고 : https://zion830.tistory.com/114 -
'org.h2.jdbc.JdbcSQLNonTransientConnectionException: Connection is broken: "java.net.SocketException: 현재 연결은 사용자의 호스트 시스템의 소프트웨어의 의해 중단되었습니다:'
h2에서 url을 pom.xml과 동일한 버전으로 맞춘뒤 실행하여 해결 -
exception in thread "main" java.lang.noclassdeffounderror:
persistence.xml의 javax부분을 jakarta로 수정하여 해결💡 도와주신 천사님 왈 :
최신 버전 기준으로 하실거면 javax보다 jakarta 가 좋다고 하네요 이클립스에서 javax 이제 관리 안 한다구..
📝 JPQL 소개
- 가장 단순한 조회 방법
- EntityManager.find()
- 객체 그래프 탐색(a.getB().getC())
List<Member> result = em.createQuery("select m from Member as m", Member.class)
.getResultList();
// jpa는 코드를 짤 때 테이블 대상으로 짜지 않는다. 즉, Member객체를 대상으로 쿼리를 짠다
for(Member member : result){
System.out.println("member.name = " + member.getName());
}
// 결과물
select
m1_0.id,
m1_0.name
from Member m1_0 offset ? rows fetch first ? rows only- JPA를 사용하면 엔티티 객체를 중심으로 개발
- 문제는 검색 쿼리
- 검색을 할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색
- 모든 DB 데이터를 객체로 변환해서 검색하는 것은 불가능
- 애플리케이션이 필요한 데이터만 DB에서 불러오려면 결국 검색 조건이 포함된 SQL이 필요
- JPA는 SQL을 추상화한 JPQL이라는 객체 지향 쿼리 언어 제공
- SQL과 문법 유사, SELECT, FROM, WHERE, GROUP BY, HAVING, JOIN 지원
- JPQL은 엔티티 객체를 대상으로 쿼리
- SQL은 데이터베이스 테이블을 대상으로 쿼리
- 테이블이 아닌 객체를 대상으로 검색하는 객체 지향 쿼리
- SQL을 추상화해서 특정 데이터베이스 SQL에 의존X
- JPQL을 한마디로 정의하면 객체 지향 SQL
🏊♀️ 섹션 3
영속성 컨텍스트1
📝 JPA에서 가장 중요한 2가지
- 객체와 관계형 데이스 매팅파이(ORM)
- 영속성 컨텍스트
💡 영속성 컨텍스트란?
- "엔티티를 영구 저장하는 환경"이라는 뜻
- EntityManager.persist(entity);
- 엔티티 매니저를 통해서 영속성 컨텍스트에 접근
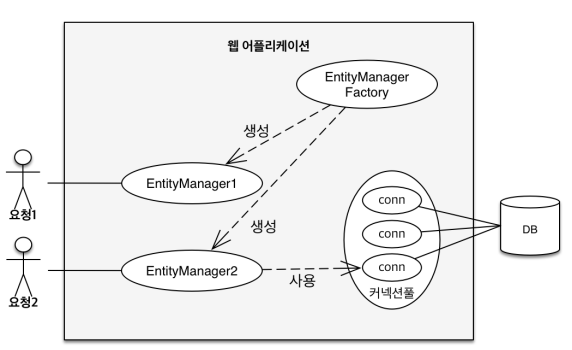 | 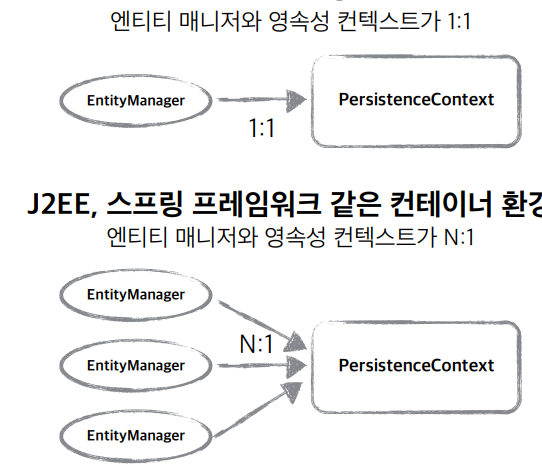 |
|---|
📝 엔티티의 생명주기
- 비영속 (new/transient)
✅ 영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
//객체를 생성한 상태 (jpa와 전혀 관계 없는 상태)
Member member = new Member();
member.setId(1L);
member.setName("userA");- 영속 (managed)
✅ 영속성 컨텍스트에 관리되는 상태
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
//객체를 저장한 상태(영속)
em.persist(member)- 준영속 (detached)
✅ 영속성 컨텍스트에 저장되었다가 분리된 상태
// 회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태
em.detach(member)- 삭제 (removed)
✅ 삭제된 상태
em.remove(member);📝 영속성 컨텍스트의 이점
- 1차 캐시
✅ 1차 캐시에 저장하고, 또 사용하면 그걸 조회(데이터베이스에서 조회 X)
✅ 똑같은 것을 2번 조회할 때 첫 번째는 쿼리, 두 번째는 1차 캐시에서 조회
// 비영속
Member member = new Member();
member.setId(101L);
member.setName("HelloJPA");
// 영속
em.persist(member); // 1차 캐시에 저장돼서 db에서 select 쿼리를 통해서 조회안함
Member findMember = em.find(Member.class, 101L);
System.out.println("findMember.id = " + findMember.getId());
System.out.println("findMember.name = " + findMember.getName());Member findMember1 = em.find(Member.class, 101L); // 쿼리를 통해 조회
Member findMember2 = em.find(Member.class, 101L); // 1차 캐시를 통해 조회
결과물 : 쿼리 한 번만 조회됨
select
m1_0.id,
m1_0.name
from
Member m1_0
where
m1_0.id=?- 동일성(identity) 보장
✅ 1차 캐시로 반복 가능한 읽기(REPEATABLE READ) 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공
System.out.println("result = " + (findMember2 == findMember1));
결과물
result = true- 트랜잭션을 지원하는 쓰기 지연(transactional write-behind)
✅ 버퍼링 기능 (insert 쿼리를 모았다가 한 번에 db에 저장)
//엔티티 매니저는 데이터 변경시 트랜잭션을 시작해야 한다.
tx.begin(); // [트랜잭션] 시작
em.persist(memberA);
em.persist(memberB);
//여기까지 INSERT SQL을 데이터베이스에 보내지 않는다.
//커밋하는 순간 데이터베이스에 INSERT SQL을 보낸다.
tx.commit(); // [트랜잭션] 커밋- 변경 감지
✅ JPA 값을 변경하면 transaction이 commit되는 시점에 변경
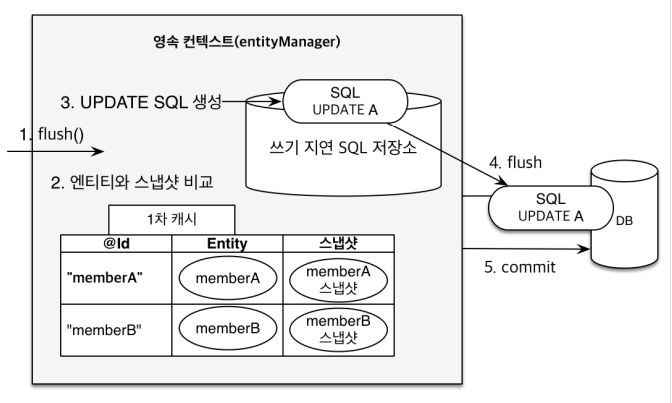
플러시
📝 플러시란?
- 영속성 컨텍스트의 변경 내용을 데이터 베이스에 반영(동기화)
- 영속성 컨텍스트를 비우는 것이 아님
- 트랜잭션이라는 작업 단위가 중요 → 커밋 직전에만 동기화하면 됨
📝 플러시 발생
- 변경 감기
- 수정된 엔티티 쓰기 지연 SQL 저장소에 등록
- 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송 (등록, 수정, 삭제 쿼리)
📝 영속성 컨텍스트르 플러시하는 방법
- em.flush() : 직접 호출
- 트랜잭션 커밋 : 플러시 자동 호출
- JPQL 쿼리 실행 : 플러시 자동 호출
💡 플러시를 하는 경우
: 지연SQL, 쓰기지연SQL에 저장된 쿼리를 DB로 전송하는 것이지 commit이 되는 것은 아니므로 commit까지 진행되어야 DB에 반영됨
📝 플러시 모드 옵션
em.setFlushMode(FlushModeType.COMMIT)
- FlushModeType.AUTO
✅ 커밋이나 쿼리를 실행할 때 플러시 (기본값) - FlushModeType.COMMIT
✅ 커밋할 때만 플러시
준영속 상태
📝 준영속 상태란?
- 영속 → 준영속으로 변경
- 영속 상태의 엔티티를 영속성 컨텍스트에서 분리(detach)하는 것
- 영속성 컨텍스트가 제공하는 기능을 사용하지 못함(당연함)
📝 준영속 상태롤 만드는 방법
- em.detach(entity)
✅ 특정 엔티티만 준영속 상태로 전환 - em.clear()
✅ 영속성 컨텍스트를 완전히 초기화
✅ 1차 캐시 관계 없이 테스트 케이스 작성할 때 도움됨 - em.close()
✅ 영속성 컨텍스트를 종료
🏊♀️ 섹션 4
객체와 테이블 매핑
📝 엔티티 매핑
1. 객체와 테이블 매핑 : @Entity, @Table
2. 필드와 칼럼 매핑 : @Column
3. 기본 키 매핑 : @Id
4. 연관관계 매핑 : @ManyToOne, @JoinColumn
📝 객체와 테이블 매핑
- @Entity
- @Entity가 붙은 클래스는 JPA가 관리, 엔티티라 한다.
- JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 필수
💡 주의
• 기본 생성자 필수(파라미터가 없는 public 또는 protected 생성자)
• final 클래스, enum, interface, inner 클래스 사용X
• 저장할 필드에 final 사용 X - 속성: name
- JPA에서 사용할 엔티티 이름을 지정한다.
- 기본값: 클래스 이름을 그대로 사용(예: Member)
- 같은 클래스 이름이 없으면 가급적 기본값을 사용한다.
- @Table
- @Table은 엔티티와 매핑할 테이블 지정
데이터베이스 스키마 자동 생성
- DDL을 애플리케이션 실행 시점에 자동 생성
- 테이블 중심 → 객체 중심
- 데이터베이스 방언을 활용해서 데이터베이스에 맞는 적절한
DDL 생성 - 이렇게 생성된 DDL은 개발 장비에서만 사용
- 생성된 DDL은 운영서버에서는 사용하지 않거나, 적절히 다듬
은 후 사용
// persistence.xml 파일에 아래 문구 추가
<property name="hibernate.hbm2ddl.auto" value="create" />
// 파일 실행 시 기존 테이블 삭제 후 새로운 테이블 생성
drop table if exists Member cascade
create table Member (
id bigint not null,
name varchar(255),
primary key (id)
)
Hibernate:
/* insert for
hellojpa.Member */insert
into
Member (name,id)
values
(?,?)💡 주의
- 운영 장비에는 절대 create, create-drop, update 사용하면
안된다.- 개발 초기 단계는 create 또는 update
- 테스트 서버는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
필드와 컬럼 매핑
- @Column : 컬럼 매핑
- @Temporal : 날짜 타입 매핑
- @Enumerated : enum 타입 매핑
💡 주의! ORDINAL 사용 X
→ 데이터 추가 시 위치에 따라 enum이 생성되기 때문에 운영시 문제생김
✅ EnumType.ORDINAL: enum 순서를 데이터베이스에 저장
✅ EnumType.STRING: enum 이름을 데이터베이스에 저장
💥 EnumType.STRING 개발하기 - @Lob : BLOB, CLOB 매핑
- @Transient : 특정 필드를 컬럼에 매핑하지 않음(매핑 무시)
- 메모리에서만 사용 (DB에 생성되지 않음)
