Raw Data Load(원시 데이터 로드)
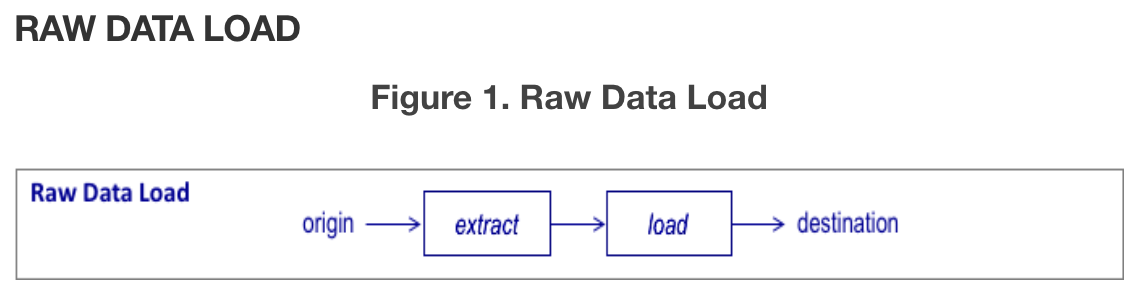
- 원시 데이터 로드 데이터 파이프라인은 한 데이터베이스에서 다른 데이터베이스로 데이터를 이동하도록 한다. 데이터 마이그레이션에 필요한 대량 데이터 이동을 수행한다. 일반적으로 일회성 실행을 위해 구축되며 주기적 또는 반복적인 일정으로 실행되는 경우는 드물다.
ETL And Variations
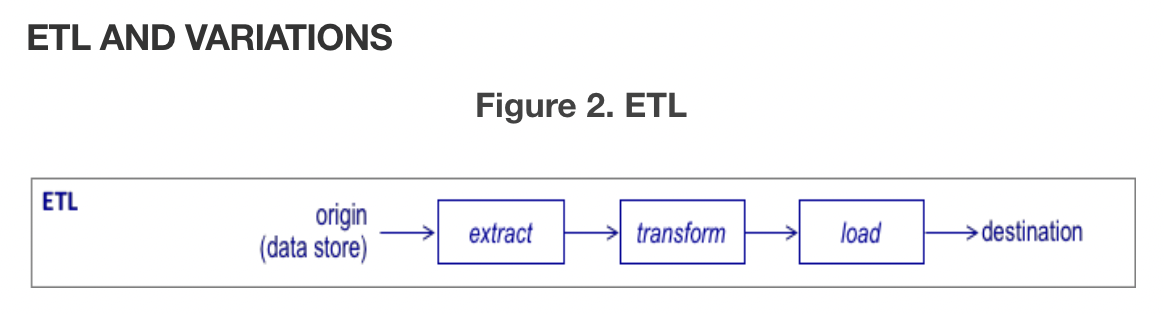
- ETL(Extract-Transform-Load)은 가장 널리 사용되는 데이터 파이프라인 패턴이다. 운영 데이터베이스와 같은 데이터 저장소에서 데이터를 추출한 다음 대상 데이터베이스에 로드 하기 전에 정제, 표준화 및 통합하도록 변환합니다. ETL은 복잡한 데이터 변환이 필요할 때, 모든 데이터 소스가 동시에 준비되지 않는 경우에 사용하기 적합하다. 모든 원본 데이터 추출이 완료되면 전체 데이터 집합의 변환 및 로드와 함께 처리된다.
Streaming ETL
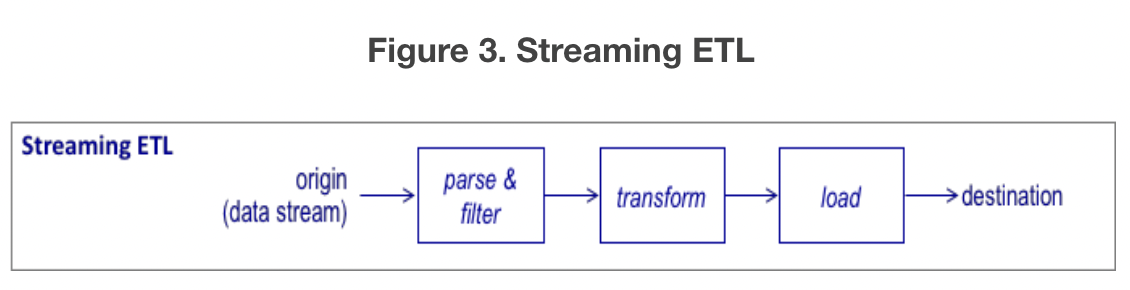
- 데이터 저장소에서 추출하는 대신 스트리밍 데이터를 구문 분석하여 개별 이벤트를 고유한 레코드로 분리한 다음 필터링하여 필요한 이벤트 및 필드를 사용한다. 데이터의 양이 크고 적은 수의 필드에만 초점을 맞추는 기계 학습용 데이터 파이프라인으로 사용하면 좋다.
ELT
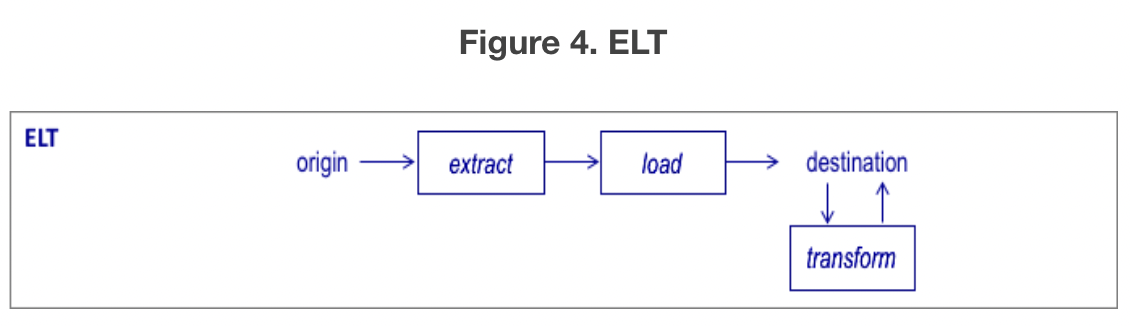
- ETL(Extract-Load-Transform)은 ETL 처리로 인해 발생하는 대기 시간을 없애기 위해 고안된 ETL의 변형이다. ELT를 사용하면 데이터 웨어하우스가 데이터 스테이징 역할을 하고 모든 소스가 로드되면 데이터 웨어하우스에서 데이터 변환이 수행된다. 데이터 품질 및 데이터 개인 정보보호를 고려해야 고민을 해봐야 한다.
ETLT
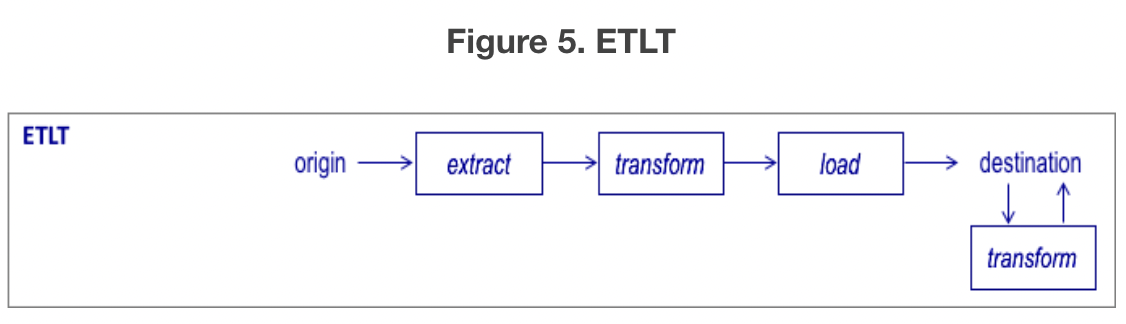
- ETLT(Extract-Transform-Load-Transforo) 패턴은 ETL과 ELT의 하이브리드이다. 데이터가 로드되기 전에 데이터 정리, 형식 표준화 및 민감한 데이터 마스킹과 같은 "가벼운" 데이터 변환이 수행된다. 로드가 완료되면 2단계 변환이 수행된다.
Data Virtualization
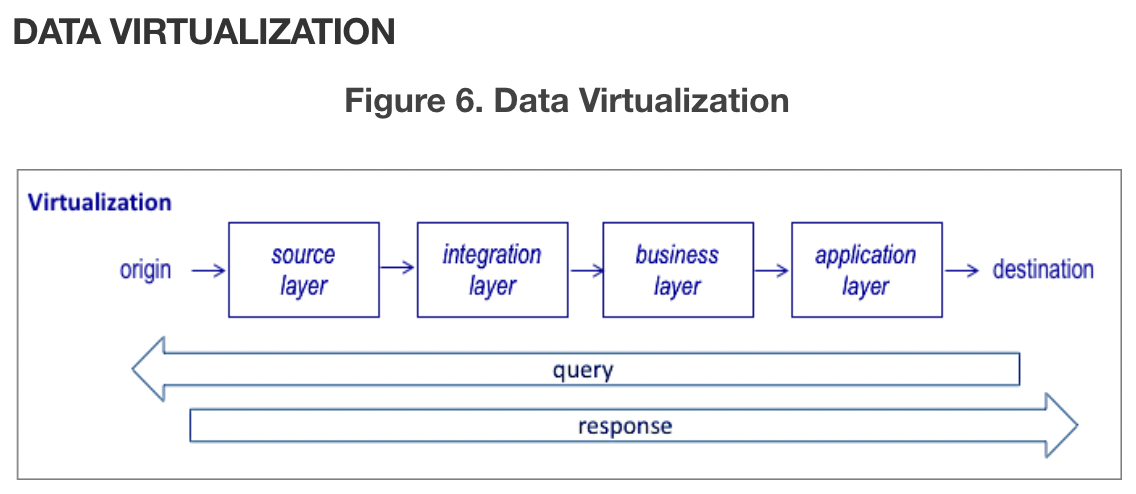
- 대부분의 데이터 파이프라인은 데이터 웨어하우스, 데이터 레이크 등에 데이터의 물리적 복사본을 생성한다. 가상화는 물리적으로 저장하지 않고 보여주는 방식으로 데이터를 제공한다. source Layer는 데이터 소스의 데이터를 볼 수 있도록 하고, integration Layer는 ETL처리의 변환 결과와 유사한 데이터를 볼 수 있도록 하고 서로 다른 소스 데이터들을 결합한다. business Layer는 의미론적 컨텍스트(semantic context)로 데이터를 제공하고 Application Layer는 특정 사용 사례에 대한 의미론적 보기(semantic view)를 구성한다.
가상화 프로세스는 쿼리에 의해 시작한다. 쉬운 변환과 적당한 데이터 볼륨에서는 잘 작동하지만 복잡한 변환을 수행하거나 쿼리에 응답하는 데 많은 데이터가 필요한 경우에는 사용하기 어렵다.
Data Stream Processing
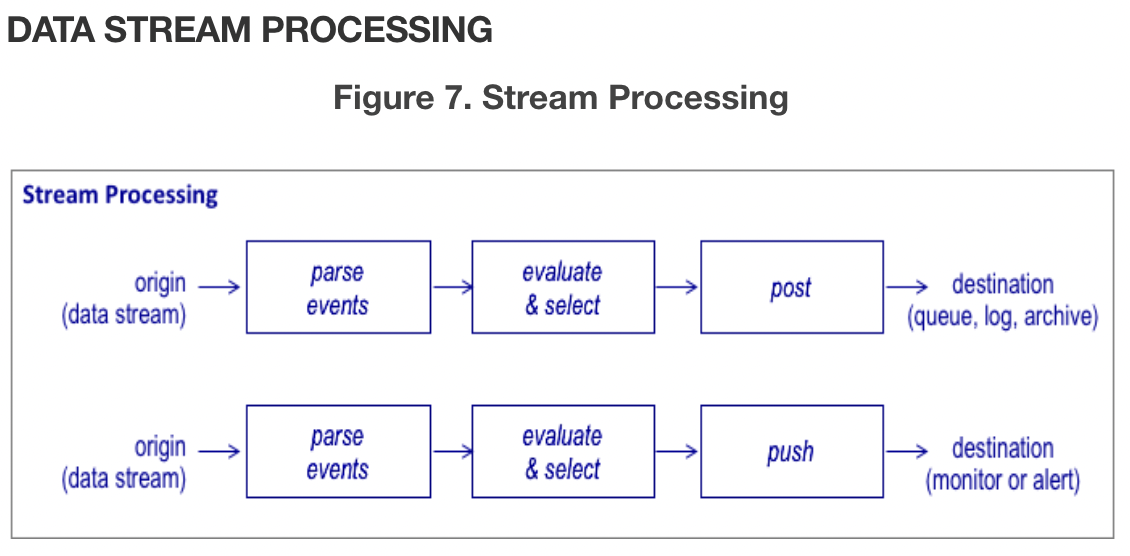
- 구문 분석한 개별 이벤트를 검사하여 사용 사례에 맞는 이벤트에 맞게 처리를 할 수 있다. 일부는 queue, log, archive에 보내 다른 데이터 파이프라인의 소스 또는 입력이 될 수 있다. 다른 경우는 시스템의 상태에 대한 정보가 실시간으로 전달되는 모니터링 또는 알람 애플리케이션에 이벤트를 push하는 것이다. 보통 센서 및 사물 인터넷(IoT)데이터에 사용된다.
Change Data Capture
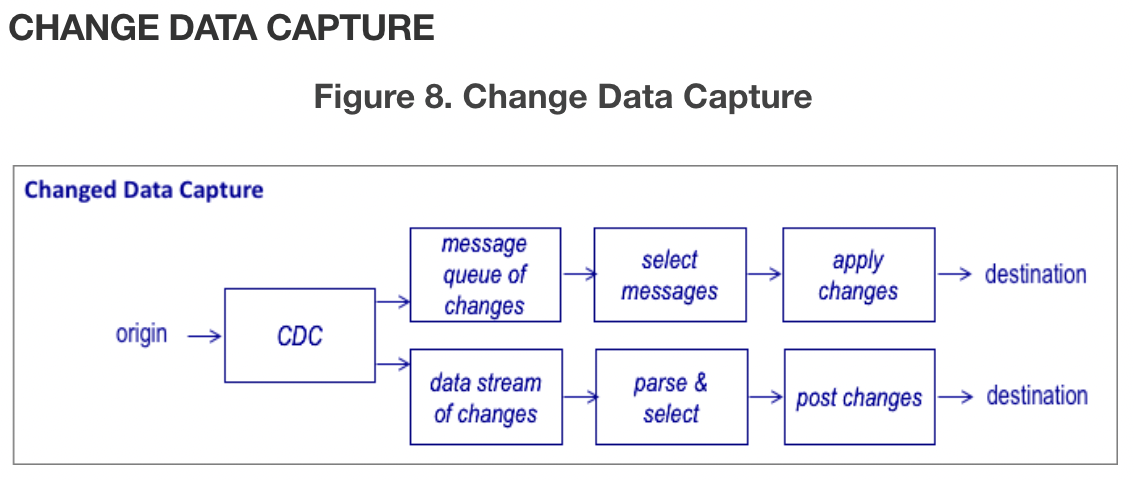
- 변경 데이터 캡처(CDC)는 일반적으로 데이터의 신선도를 높이는 데 사용할 수 있는 기술이다. 운영 데이터베이스에서 발생하는 데이터 변경 사항이 실시간으로 destination 데이터베이스로 수집된다.
Reference

2023