Kaggle
Playground Series - Season 3, Episode 11
Playground Series - Season 3, Episode 11
Food Mart (CFM) is a chain of convenience stores in the United States. The private company's headquarters are located in Mentor, Ohio, and currently, approximately 325 stores are located in the US. Convenient Food Mart operates on the franchise system.
Food Mart was the nation's third-largest chain of convenience stores as of 1988.
The NASDAQ exchange dropped Convenient Food Mart the same year when the company failed to meet financial reporting requirements.
Carden & Cherry advertised Convenient Food Mart with the Ernest character in the 1980s.
Your Task is to devise a Machine Learning Model that helps us predict the cost of media campaigns in the food marts on the basis of the features provided.
DataSet
input
train.csv : the training dataset; cost is the target
test.csv : the test dataset; your objective is to predict cost
sample_submission.csv : a sample submission file in the correct format
Columns Description
store_sales(in millions) - store_sales(in million dollars)
unit_sales(in millions) - unit_sales(in millions) in stores Quantity
Total_children - TOTAL CHILDREN IN HOME
avg_cars_at home(approx) - avg_cars_at home(approx)
Num_children_at_home - num_children_at_home AS PER CUSTOMERS FILLED DETAILS
Gross_weight - gross_weight OF ITEM
Recyclable_package - FOOD ITEM IS recyclable_package
Low_fat - LOW_FAT FOOD ITEM IS LOW FAT
Units_per_case - UNITS/CASE UNITS AVAILABLE IN EACH STORE SHELVES
Store_sqft - STORE AREA AVAILABLE IN SQFT
Coffee_bar - COFFEE BAR available in store
Video_store - VIDEO STORE/gaming store available
Salad_bar - SALAD BAR available in store
Prepared_food - food prepared available in store
Florist - flower shelves available in store
Target Variable
Cost - COST ON ACQUIRING A CUSTOMERS in dollars
Code
import numpy as np
import pandas as pdLoad Data
train = pd.read_csv("../input/playground-series-s3e11/train.csv")
test = pd.read_csv("../input/playground-series-s3e11/test.csv")
submission = pd.read_csv("../input/playground-series-s3e11/sample_submission.csv")# Target Variable Select
target_variable = 'cost'Data preprocessing
Null Check
print(train.isnull().sum(), test.isnull().sum())
>>> 0 , 0Colunm Rename
# Column Rename
train = train.rename(columns={'unit_sales(in millions)':'unit_sales',
'store_sales(in millions)':'store_sales', 'total_children':'total_child',
'num_children_at_home':'num_child', 'avg_cars_at home(approx).1':'avg_cars'})
test = test.rename(columns={'unit_sales(in millions)':'unit_sales',
'store_sales(in millions)':'store_sales', 'total_children':'total_child',
'num_children_at_home':'num_child', 'avg_cars_at home(approx).1':'avg_cars'})Data Normalization
def min_max_normalization(data):
min_val = min(data)
max_val = max(data)
normalized_data = []
for value in data:
normalized_value = (value - min_val) / (max_val - min_val)
normalized_data.append(normalized_value)
return normalized_data
for column in train.columns:
if column == 'cost':
pass
else:
data = train[column].values.tolist()
normalized_data = min_max_normalization(data)
train[column] = normalized_data
for column in test.columns:
if column == 'cost':
pass
else:
data = test[column].values.tolist()
normalized_data = min_max_normalization(data)
test[column] = normalized_dataEDA
Heatmap
plt.figure(figsize=(12,8))
sns.heatmap(train.corr().abs(), cmap="terrain", annot=True, fmt='.2f')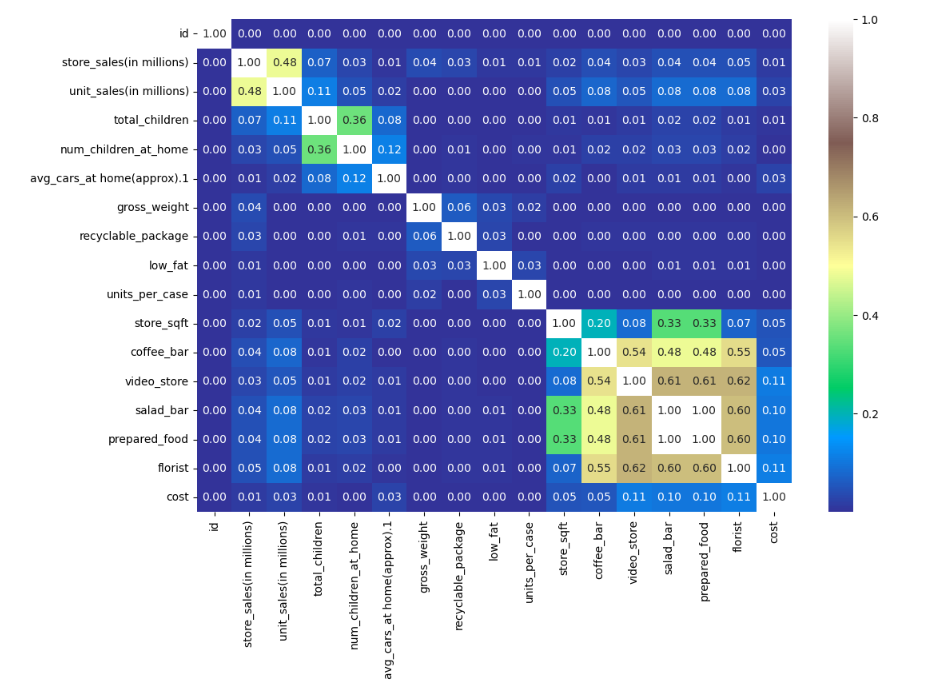
salad_bar column 과 prepared_food 의 상관관계가 '1.00` 이므로 VIF 를 확인해 봐야함
Feature Engneering (Select)
VIF(Variance Inflation Factor)
from statsmodels.formula.api import ols
from statsmodels.stats.outliers_influence import variance_inflation_factor as VIF
import statsmodels.api as smmodel = ols('cost ~ store_sales + unit_sales + total_child + num_child + avg_cars + gross_weight + \
recyclable_package + low_fat + units_per_case + store_sqft + coffee_bar + video_store + salad_bar + prepared_food + florist', train)
res = model.fit()
res.summary()df = train[['store_sales', 'unit_sales', 'total_child', 'num_child',
'avg_cars', 'gross_weight', 'recyclable_package', 'low_fat',
'units_per_case', 'store_sqft', 'coffee_bar', 'video_store',
'salad_bar', 'prepared_food', 'florist', 'cost']]
vif_df = pd.DataFrame()
vif_df['feature'] = df.columns
vif_df['VIF'] = [VIF(df.values, i) for i in range(len(df.columns))]
vif_df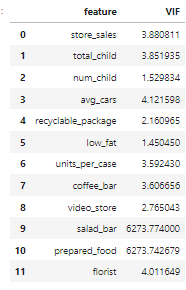
salad_bar column 과 prepared_food 의 VIF가 하늘로 승천,, 하기 때문에 둘 중 하나를 drop 시키기로 함
Feature Importance
from sklearn.feature_selection import mutual_info_regression
from sklearn.ensemble import RandomForestRegressor# MI Score
X_m = train[['store_sales', 'unit_sales', 'total_child', 'num_child',
'avg_cars', 'recyclable_package', 'low_fat',
'units_per_case', 'store_sqft','coffee_bar', 'video_store',
'prepared_food', 'florist']]
y_m = train[target_variable]
mi_scores = mutual_info_regression(X_m, y_m)
mi_scores = pd.Series(mi_scores, name='MI Scores', index=X_m.columns)
mi_scores = mi_scores.sort_values(ascending=False)
print(mi_scores)
>>>
store_sqft 2.705048
florist 0.629897
prepared_food 0.610278
coffee_bar 0.595099
video_store 0.516344
total_child 0.119929
avg_cars 0.090661
num_child 0.087432
unit_sales 0.082803
store_sales 0.027371
low_fat 0.000244
recyclable_package 0.000000
units_per_case 0.000000
Name: MI Scores, dtype: float64Feature Select
features = [
'total_child',
'num_child',
'avg_cars',
'store_sqft',
'coffee_bar',
'video_store',
'prepared_food',
'florist',
]Model Select and Lerning
import Libabry
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import optunaCode
X = train[features]
y = train[target_variable]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)CatBoost
import Libabry
!pip install catboostfrom catboost import CatBoostRegressor
Code
def objective_catboost(trial):
params = {
'iterations': trial.suggest_int('iterations', 500, 3000),
'learning_rate': trial.suggest_loguniform('learning_rate', 0.0001, 0.5),
'depth': trial.suggest_int('depth', 4, 16),
'l2_leaf_reg': trial.suggest_loguniform('l2_leaf_reg', 1e-6, 10),
'random_strength': trial.suggest_loguniform('random_strength', 1e-6, 100),
'bagging_temperature': trial.suggest_loguniform('bagging_temperature', 0.01, 10),
'od_type': 'Iter',
'od_wait': 50,
'eval_metric': 'RMSE',
'loss_function': 'RMSE',
'verbose': False,
'random_state': 42,
'rsm': trial.suggest_uniform('rsm', 0.5, 1.0)
}
model = CatBoostRegressor(**params)
model.fit(X_train, y_train, eval_set=[(X_test, y_test)], early_stopping_rounds=50)
y_pred = model.predict(X_test)
return mean_squared_error(y_test, y_pred)
study_catboost = optuna.create_study(direction='minimize')
study_catboost.optimize(objective_catboost, n_trials=30)
print("CatBoost - Best trial:")
print(study_catboost.best_trial.params)
print("CatBoost - Best MSE:")
print(study_catboost.best_value)
best_iterations = study_catboost.best_trial.params['iterations']
best_learning_rate = study_catboost.best_trial.params['learning_rate']
best_depth = study_catboost.best_trial.params['depth']
best_l2_leaf_reg = study_catboost.best_trial.params['l2_leaf_reg']
best_random_strength = study_catboost.best_trial.params['random_strength']
best_bagging_temperature = study_catboost.best_trial.params['bagging_temperature']
best_rsm = study_catboost.best_trial.params['rsm']
catboost = CatBoostRegressor(iterations=best_iterations,
learning_rate=best_learning_rate,
depth=best_depth,
l2_leaf_reg=best_l2_leaf_reg,
random_strength=best_random_strength,
bagging_temperature=best_bagging_temperature,
rsm = best_rsm)
catboost.fit(X_train, y_train)
y_pred_catboost = catboost.predict(X_test)
mse_catboost = mean_squared_error(y_test, y_pred_catboost)
print("CatBoost - Test MSE:", mse_catboost)RMSLE
y_true = y_test
y_pred = catboost.predict(X_test)
rmsle = np.sqrt(mean_squared_error(np.log1p(y_true), np.log1p(y_pred)))
print('RMSLE:', rmsle)
>>> RMSLE: 0.2964250404796346
dump
pred_cat = pd.DataFrame(y_pred_catboost)
test_pred_cat =pd.DataFrame(catboost.predict(test[features]))
pred_cat = pred_cat.rename(columns={0: 'pred_cat'})
test_pred_cat = test_pred_cat.rename(columns={0: 'pred_cat'})
pred_cat.to_csv("pred_cat.csv", index=False)
test_pred_cat.to_csv("test_pred_cat.csv", index=False)
LightGBM
import Libabry
import lightgbm as lgbCode
def objective_lgbm(trial):
params = {
'objective': 'regression',
'metric': 'rmse',
'boosting_type': 'gbdt',
'num_leaves': trial.suggest_int('num_leaves', 10, 500),
'learning_rate': trial.suggest_loguniform('learning_rate', 0.001, 0.1),
'max_depth': trial.suggest_int('max_depth', 3, 10),
'min_child_samples': trial.suggest_int('min_child_samples', 1, 100),
'reg_alpha': trial.suggest_loguniform('reg_alpha', 1e-5, 10),
'reg_lambda': trial.suggest_loguniform('reg_lambda', 1e-5, 10),
'subsample': trial.suggest_uniform('subsample', 0.1, 1.0),
'colsample_bytree': trial.suggest_uniform('colsample_bytree', 0.1, 1.0),
'random_state': 42,
'n_jobs': -1
}
model = lgb.LGBMRegressor(**params)
model.fit(X_train, y_train, eval_set=[(X_test, y_test)], early_stopping_rounds=50, verbose=False)
y_pred = model.predict(X_test)
return mean_squared_error(y_test, y_pred)
study_lgbm = optuna.create_study(direction='minimize')
study_lgbm.optimize(objective_lgbm, n_trials=30)
print("LGBMRegressor - Best trial:")
print(study_lgbm.best_trial.params)
print("LGBMRegressor - Best MSE:")
print(study_lgbm.best_value)best_num_leaves = study_lgbm.best_trial.params['num_leaves']
best_learning_rate = study_lgbm.best_trial.params['learning_rate']
best_max_depth = study_lgbm.best_trial.params['max_depth']
best_min_child_samples = study_lgbm.best_trial.params['min_child_samples']
best_reg_alpha = study_lgbm.best_trial.params['reg_alpha']
best_reg_lambda = study_lgbm.best_trial.params['reg_lambda']
best_subsample = study_lgbm.best_trial.params['subsample']
best_colsample_bytree = study_lgbm.best_trial.params['colsample_bytree']
lgbm = lgb.LGBMRegressor(num_leaves=best_num_leaves, learning_rate=best_learning_rate, max_depth=best_max_depth,
min_child_samples=best_min_child_samples, reg_alpha=best_reg_alpha,
reg_lambda=best_reg_lambda, subsample=best_subsample,
colsample_bytree=best_colsample_bytree, random_state=42, n_jobs=-1)
lgbm.fit(X_train, y_train)
y_pred_lgbm = lgbm.predict(X_test)
mse_lgbm = mean_squared_error(y_test, y_pred_lgbm)
print("LGBMRegressor - Test MSE:", mse_lgbm)RMSLE
y_true = y_test
y_pred = lgbm.predict(X_test)
rmsle = np.sqrt(mean_squared_error(np.log1p(y_true), np.log1p(y_pred)))
print('RMSLE:', rmsle)dump
pred_lgbm = pd.DataFrame(y_pred_lgbm)
test_pred_lgbm = pd.DataFrame(lgbm.predict(test[features]))
pred_lgbm = pred_lgbm.rename(columns={0: 'pred_lgbm'})
test_pred_lgbm = test_pred_lgbm.rename(columns={0: 'pred_lgbm'})
pred_lgbm.to_csv("pred_lgbm.csv", index=False)
test_pred_lgbm.to_csv("test_pred_lgbm.csv", index=False)Ridge & Lasso
import Libabry
from sklearn.linear_model import Ridge, Lasso
Code
def objective_ridge(trial):
alpha = trial.suggest_loguniform('alpha', 1e-5, 100)
max_iter = trial.suggest_int('max_iter', 100, 1000)
tol = trial.suggest_loguniform('tol', 1e-5, 1e-1)
ridge = Ridge(alpha=alpha, max_iter=max_iter, tol=tol)
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
return mean_squared_error(y_test, y_pred)
def objective_lasso(trial):
alpha = trial.suggest_loguniform('alpha', 1e-5, 100)
max_iter = trial.suggest_int('max_iter', 100, 1000)
tol = trial.suggest_loguniform('tol', 1e-5, 1e-1)
lasso = Lasso(alpha=alpha, max_iter=max_iter, tol=tol)
lasso.fit(X_train, y_train)
y_pred = lasso.predict(X_test)
return mean_squared_error(y_test, y_pred)
study_ridge = optuna.create_study(direction='minimize')
study_ridge.optimize(objective_ridge, n_trials=30)
study_lasso = optuna.create_study(direction='minimize')
study_lasso.optimize(objective_lasso, n_trials=30)
print("Ridge - Best trial:")
print(study_ridge.best_trial.params)
print("Ridge - Best MSE:")
print(study_ridge.best_value)
print("Lasso - Best trial:")
print(study_lasso.best_trial.params)
print("Lasso - Best MSE:")
print(study_lasso.best_value)best_alpha_ridge = study_ridge.best_trial.params['alpha']
best_max_iter_ridge = study_ridge.best_trial.params['max_iter']
best_tol_ridge = study_ridge.best_trial.params['tol']
ridge = Ridge(alpha=best_alpha_ridge, max_iter=best_max_iter_ridge, tol=best_tol_ridge)
ridge.fit(X_train, y_train)
best_alpha_lasso = study_lasso.best_trial.params['alpha']
best_max_iter_lasso = study_lasso.best_trial.params['max_iter']
best_tol_lasso = study_lasso.best_trial.params['tol']
lasso = Lasso(alpha=best_alpha_lasso, max_iter=best_max_iter_lasso, tol=best_tol_lasso)
lasso.fit(X_train, y_train)
y_pred_ridge = ridge.predict(X_test)
mse_ridge = mean_squared_error(y_test, y_pred_ridge)
print("Ridge - Test MSE:", mse_ridge)
y_pred_lasso = lasso.predict(X_test)
mse_lasso = mean_squared_error(y_test, y_pred_lasso)
print("Lasso - Test MSE:", mse_lasso)RMSLE
y_true = y_test
y_pred = ridge.predict(X_test)
rmsle = np.sqrt(mean_squared_error(np.log1p(y_true), np.log1p(y_pred)))
print('RMSLE:', rmsle)
y_true = y_test
y_pred = ridge.predict(X_test)
rmsle = np.sqrt(mean_squared_error(np.log1p(y_true), np.log1p(y_pred)))
print('RMSLE:', rmsle)dump
preds_ridge = pd.DataFrame(y_pred_ridge)
preds_lasso = pd.DataFrame(y_pred_lasso)
test_pred_ridge = pd.DataFrame(ridge.predict(test[features]))
test_pred_lasso = pd.DataFrame(lasso.predict(test[features]))
preds_ridge = preds_ridge.rename(columns={0: 'preds_ridge'})
preds_lasso = preds_lasso.rename(columns={0: 'preds_lasso'})
test_pred_ridge = test_pred_ridge.rename(columns={0: 'preds_ridge'})
test_pred_lasso = test_pred_lasso.rename(columns={0: 'pred_lgbm'}
preds_ridge.to_csv("pred_ridge.csv", index=False)
preds_lasso.to_csv("pred_lasso.csv", index=False)
test_pred_ridge.to_csv("test_pred_ridge.csv", index=False)
test_pred_lasso.to_csv("test_pred_lasso.csv", index=False)Model Select
RMSLE 가 전반적으로 낮은 ridge, lasso와 MetaModel로 사용하기 위한 LGBM은 Basic Model로 사용하지 않았다.
따라서 다른 팀원들의 Adaboost, XGBoost, KNN과 나의 Catboost 까지 총 4개를 Stacking을 하고자 함
Stacking Ensemble (Meta Model : LGBM)
import Libabry
import lightgbm as lgbDataLoad
filepath = "/kaggle/input/stackplz/"pred_cat = pd.read_csv(filepath3 + "pred_cat.csv")
pred_xgb = pd.read_csv(filepath + "pred_xgb.csv")
pred_ada = pd.read_csv(filepath + "pred_ada.csv")
pred_knn = pd.read_csv(filepath + "pred_knn.csv")
test_pred_cat = pd.read_csv(filepath3 + "test_pred_cat.csv")
test_pred_xgb = pd.read_csv(filepath + "test_pred_xgb.csv")
test_pred_ada = pd.read_csv(filepath + "test_pred_ada.csv")
test_pred_knn = pd.read_csv(filepath + "test_pred_knn.csv")Stacking
train_stack = pd.concat([pred_cat['pred_cat'], pred_xgb['xg_cost'], pred_ada['pred_xgb'],pred_knn['pred_xgb']], axis=1)
test_stack = pd.concat([test_pred_cat['pred_cat'],test_pred_xgb['test_xg_cost'],test_pred_ada['pred_xgb'],test_pred_knn['pred_xgb']], axis=1)new_column_names = ['pred_cat','pred_xgb','pred_ada','pred_knn']
train_stack = pd.DataFrame({new_column_names[i]: train_stack.iloc[:, i] for i in range(train_stack.shape[1])})
test_stack = pd.DataFrame({new_column_names[i]: test_stack.iloc[:, i] for i in range(test_stack.shape[1])})
Learning
X = train[features]
y = train[target_variable]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)meta_model = lgb.LGBMRegressor()
meta_model.fit(train_stack,y_test)final_predictions = meta_model.predict(test_stack)dump
submission['cost'] = final_predictions
submission.to_csv("submission.csv", index=False)
Result


Public Score의 경우 200등 중반까지 가서 목표는 달성..! 했으나 Private Score의 경우 대회 막바지 제출 버닝 + 대회 끝난 이후 고인물들의 제출로 인해 순위가 떨어졌다.
개인으로는 첫 kaggle 참여인만큼 나쁘지 않은 결과여서 만족하나 진행하면서 내 부족함을 너무 느꼈다..
Kaggle NoteBook
https://www.kaggle.com/code/keejuneman/stacking-cat
https://www.kaggle.com/keejuneman/stacking-lgbm
https://www.kaggle.com/keejuneman/stacking-lasso-ridge
https://www.kaggle.com/code/keejuneman/stacking-real

IPTV services are perfect for movie and show enthusiasts. With on-demand access to the latest releases and classic favorites, you can enjoy a vast library of content at your fingertips. This convenience makes IPTV an ideal choice for binge-watchers.