
컴퓨터구조론 개정5판을 정리합니다.
(아아... 이 묵직하고 서늘한 감각...)


CPU는 기억장치에 저장되어 있는 프로그램 코드인 명령어들을 실행함으로써 프로그램 수행이라는 기본적인 기능을 수행한다. 이를 위해 CPU가 수행하는 세부적인 동작들을 순서대로 나열하면,
- Instruction Fetch(명령어 인출) : 기억장치(RAM)로 부터 명령어를 읽어온다.
- Instruction Decode(명령어 해독) : 수행해야 할 동작을 결정하기 위해 명령어를 해독한다.
(여기서 1번 2번 동작은 모든 명령어가 공통 수행한다.)- Data Fetch(데이터 인출) : 명령어 실행을 위해 데이터가 필요한 경우에는 기억장치 혹은 I/O 장치로부터 그 데이터를 읽어온다.
- Data Process(데이터 처리) : 데이터에 대한 산술적 혹은 논리적 연산을 수행한다.
- Data Store(데이터 저장) : 수행한 결과를 저장한다.
(3, 4, 5번 동작은 필요한 경우에만 수행한다.)
1. CPU의 기본 구조
CPU(코어)는 산술논리연산장치(ALU : Arithmetic Logic Unit)와 레지스터 세트 및 제어 유닛으로 구성된다.
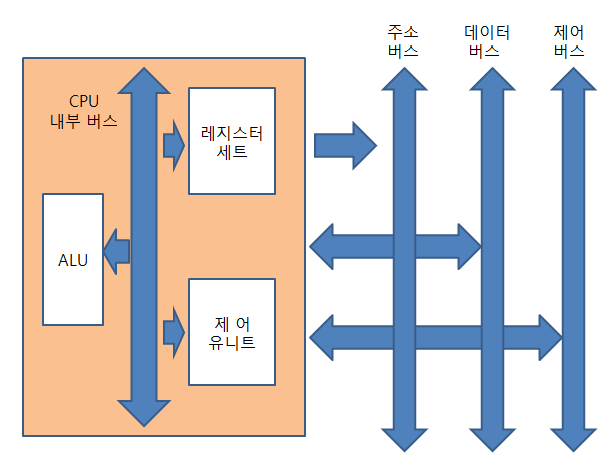
1) ALU
ALU는 각종 산술 연산(사칙연산)들과 논리 연산(AND, OR, NOT ...)들을 수행하는 회로들로 이루어진 하드웨어 모듈이다.
2) Register
Register는 CPU 내부에 위치한 기억장치로, 엑세스 속도가 컴퓨터의 기억장치들 중에서 가장 빠르다. 그러나 레지스터는 내부 회로가 복잡하여 비교적 큰 공간을 차지하기 때문에 많은 수의 레지스터들을 CPU 내부에 포함시키지 않는다. 따라서 지정된 용도로만 사용되는 특수 목적 레지스터들과 적은 수의 일반 목적용 레지스터들만이 포함된다.
3) Control Unit
제어 유닛은 프로그램 코드(명령어)를 해석하고 그것을 실행하기 위한 제어 신호들(control signals)을 순차적으로 발생하는 하드웨어 모듈이다. CPU가 제공하는 명령어들의 수가 많아질수록 제어 유닛의 내부 회로는 더 복잡해진다. 최근에는 명령어의 수를 가능한 한 줄이고 명령어 형식을 단순화함으로써 하드웨어만으로 명령을 실행할 수 있도록 하는 RISC(Reduced Instruction Set Computer) 설계 개념이 많이 사용된다.
4) CPU Internal Bus
CPU 내부 버스는 ALU와 Register 간의 데이터 이동을 위한 데이터 선들과 주소 선들, 그리고 제어 유닛으로 부터 발생되는 제어 신호들을 전송하는 선들로 구성된다. 이러한 내부 버스 선들은 외부의 시스템 버스와는 직접 연결되지 않으며 반드시 버퍼 레지스터 혹은 인터페이스 회로를 통해 시스템 버스와 접속된다.
2. 명령어 실행
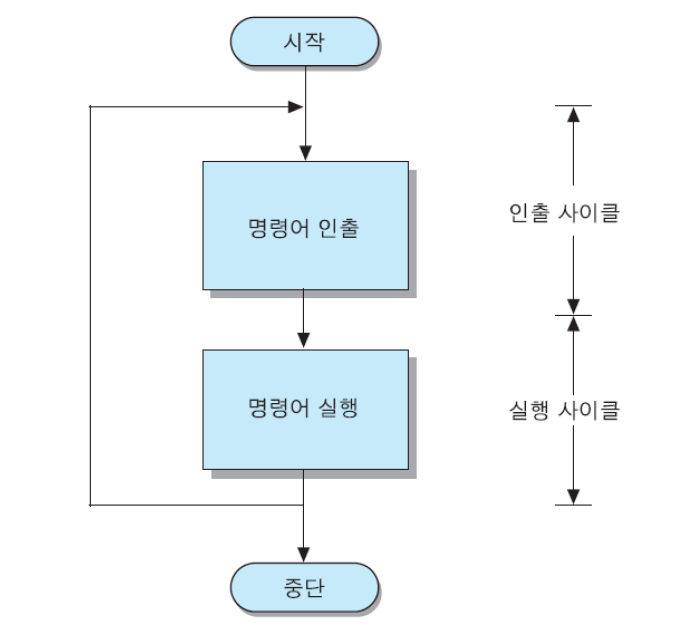
CPU는 RAM(SRAM)에 저장되어 있는 명령어들을 인출하여 실행함으로써 작업을 수행한다.
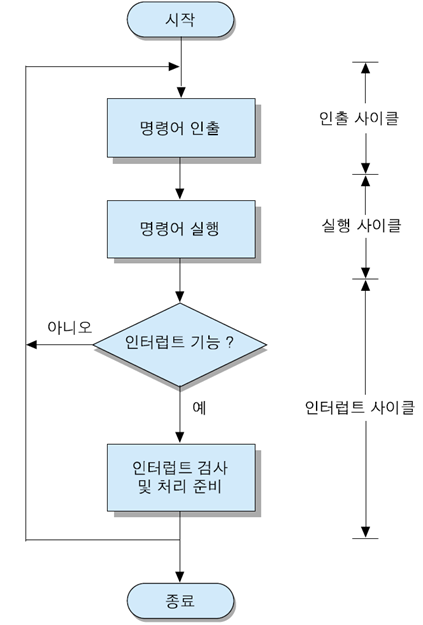
CPU가 한 개의 명령어를 실행하는 데 필요한 전체 과정을 Instruction Cycle(명령어 사이클)이라고 한다. 그리고 명령어 사이클은 CPU가 기억장치로부터 명령어를 읽어 오는 Instruction Fetch(명령어 인출) 단계와 인출된 명령어를 실행하는 Instruction Execution(명령어 실행) 단계로 이루어진다. 이 때, 각각의 subcycle을 Fetch Cycle(인출 사이클)과 Execution Cycle(실행 사이클)이라고 한다.
명령어 사이클은 프로그램 실행을 시작한 순간부터 전원을 끄거나 회복이 불가능한 오류가 발생하여 중단될 때까지 반복하여 수행된다.
명령어를 실행하기 위해 기본적으로 필요한 CPU 내부 레지스터는 다음과 같다.
1. PC(Program Counter) : 다음에 인출될 명령어의 주소를 가지고 있는 레지스터. 각 명령어가 인출된 후에는 그 내용이 자동적으로 1(혹은 명령어 길이에 해당하는 주소 단위의 수(word) 만큼)이 증가되며, Branch(분기, Jump - Interrupt) 명령어가 실행되는 경우에는 그 목적지 주소로 갱신된다.
2. AC(Accumulator : 누산기) : 데이터(계산결과)를 일시적으로 저장하는 레지스터. 직접 계산하기도 한다. AC의 비트 수는 CPU가 한 번에 연산 처리할 수 있는 데이터 비트의 수(word의 길이)와 같다.
3. IR(Instruction Register : 명령어 레지스터) : 가장 최근에 인출된 명령어(MBR)가 저장되어 있는 레지스터.
4. MAR(Memory Address Register : 기억장치 주소 레지스터) : PC에 저장된 명령어 주소가 시스템 주소 버스로 출력되기 전에 일시적으로 저장되는 주소 레지스터.(PC -> MAR -> RAM)
이 레지스터의 출력 선들이 주소 버스 선들과 직접 접속된다.
5. MBR(Memory Buffer Register : 기억장치 버퍼 레지스터) : 기억장치에 저장될 데이터 혹은 기억장치로부터 읽혀진 데이터가 일시적으로 저장되는 버퍼 레지스터.(RAM -> MBR -> AC)
이 레지스터의 입력 및 출력 선들은 데이터 버스 선들과 직접 접속된다.
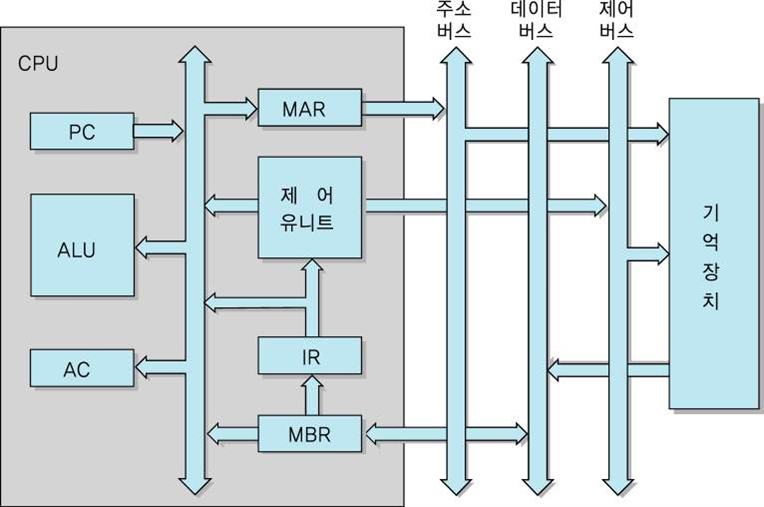
1) 인출 사이클
CPU가 기억장치의 지정된 위치로부터 명령어를 읽어오는 과정
CPU는 각 명령어 사이클의 시작 단계에서 PC가 가리키는 기억장치의 위치로부터 명령어를 인출해 온다. 그런 다음에 CPU는 PC의 내용을 1씩 증가시킴으로써 명령어들을 기억장치에 저장되어 있는 순서대로 읽어올 수 있도록 해준다.
- 어떤 컴퓨터에서 현재 PC의 내용이 '215'라고 가정한다.
- 명령어 사이클이 시작되면 CPU는 기억장치의 215번에 저장된 명령어를 인출해온다.
- PC의 내용을 '216'으로 증가시킨다.
- 다음 명령어 사이클에서는 216번의 명령어가 인출된다.
- 반복 -> CPU는 차례대로 명령어들을 인출하게 된다.
마이크로 연산
t = CPU 클록의 각 주기 (인출 사이클은 3ns)
t0 : MAR <- PC
t1 : MBR <- M[MAR], PC <- PC + 1
t2 : IR <- MBR
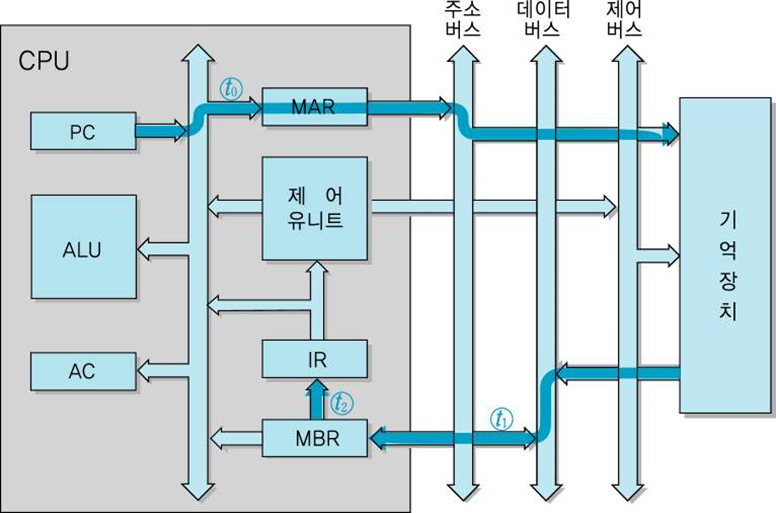
2) 실행 사이클
CPU가 인출된 명령어 코드를 decode하고 그 결과에 따라 필요한 연산을 수행하는 과정
실행 사이클에서 수행되는 마이크로 연산들은 명령어의 종류에 따라 달라진다.
✅ 참고
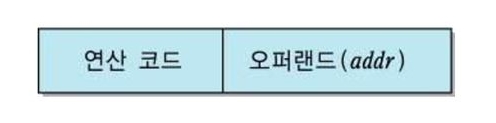
명령어 = 연산코드 + 오퍼랜드(addr)
- 연산코드 : CPU가 수행할 연산을 지정한다.
- 오퍼랜드(addr) : 명령어가 사용할 데이터와 데이터가 저장되어있는 기억장치의 주소를 가진다.
-
데이터 이동
LOAD addr
IR에 저장된 명령어의 오퍼랜드(addr)를 MAR을 통해 기억장치로 보내어 데이터를 인출.t0 : MAR <- IR(addr)
t1 : MBR <- M[MAR]
t2 : AC <- MBR -
데이터 저장
STA addr
AC 레지스터의 내용을 기억장치에 저장.t0 : MAR <- IR(addr)
t1 : MBR <- AC
t2 : M[MAR] <- MBR -
데이터 처리
ADD addr
기억장치에 저장된 데이터를 AC 레지스터의 값과 더하고 그 결과를 다시 AC 레지스터에 저장.t0 : MAR <- IR(addr)
t1 : MBR <- M[MAR]
t2 : AC <- AC + MBR (ALU가 연산 or AC 자체 연산) -
프로그램 제어
JUMP addr
현재의 PC 내용이 가리키는 위치가 아닌 다른 위치의 명령어로 실행 순서를 바꾸도록 해주는 명령어(분기(branch) 명령어)t0 : PC <- IR(addr) (RAM -> MBR -> IR -> PC)
3) 인터럽트 사이클
1️⃣ 인터럽트
대부분의 컴퓨터들은 프로그램 처리 중에 CPU로 하여금 순차적인 명령어 실행을 중단하고 다른 프로그램을 처리하도록 요구할 수 있는 메커니즘을 제공한다. 이것을 Interrupt라고 한다.
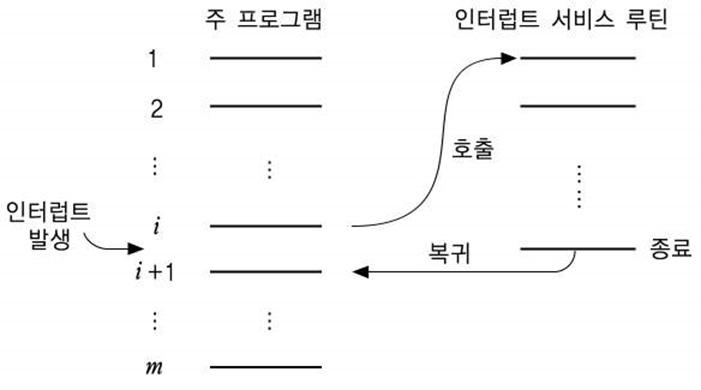
2️⃣ 인터럽트 서비스 루틴
CPU가 어떤 프로그램을 순차적으로 수행하는 도중에 외부로부터 인터럽트 요구가 들어오면 CPU는 원래의 프로그램 수행을 중단하고 요구된 인터럽트를 처리해주기 위한 프로그램을 먼저 수행한다. 이를 ISR(Interrupt Service Routine : 인터럽트 서비스 루틴)이라고 한다.
그리고 인터럽트에 대한 처리가 끝나면 CPU는 원래의 프로그램으로 복귀하여 수행을 계속한다.
3️⃣ 인터럽트 사이클
인터럽트 요구가 들어왔을 때 CPU의 동작
1. 다음에 실행할 명령어의 주소를 가리키는 현재의 PC내용을 stack에 저장한다. 이것은 인터럽트 처리를 완료한 후에 복귀할 주소를 저장해두기 위해서다.
2. 해당 인터럽트 서비스 루틴을 호출하기 위해 그 루틴의 시작 주소를 PC에 적재한다. 이 때 시작 주소는 인터럽트를 요구한 장치로부터 전송되거나 미리 정해진 값으로 결정된다.
이와 같이 인터럽트 요구 신호를 검사하고 현재의 PC 내용을 stack에 저장한 다음, PC에 해당 ISR의 시작 주소를 적재하는 과정을 Interrupt Cycle이라고 한다.
t0 : MBR <- PC (MBR <- MAR <- PC)
t1 : MAR <- SP, PC <- ISR의 시작 주소
t2 : M[MAR] <- MBR, SP <- SP - 1
여기서 SP는 CPU 내부에 있는 특수 목적용 레지스터들 중 하나인 Stack Pointer를 의미하는데 그 내용은 항상 TOS(Top of Stack)의 주소를 가리킨다. 일반적으로 스택으로는 주기억장치의 끝 부분이 사용되기 때문에 SP의 초깃값은 주기억장치의 마지막 주소로 set된다.
4️⃣ 다중 인터럽트
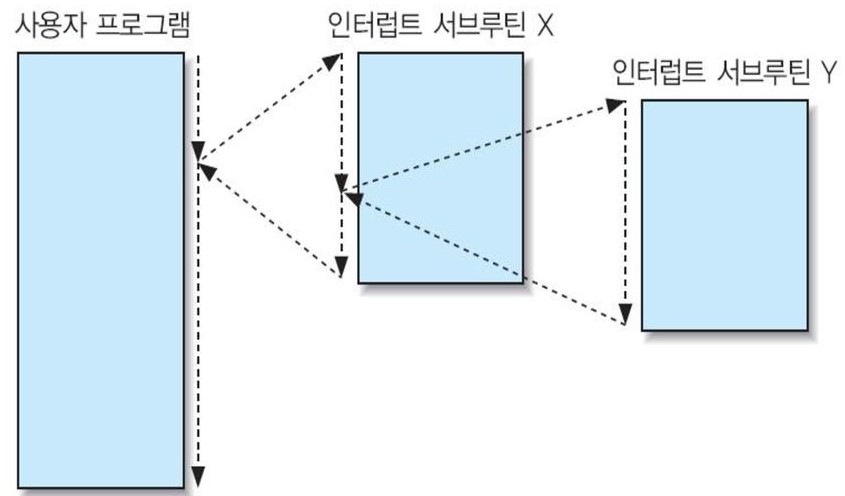
어떤 외부 장치를 위한 인터럽트 서비스 루틴의 명령어들이 실행되고 있는 동안에 다른 외부 장치가 인터럽트 요구를 발생할 수도 있는데 이를 Multiple Interrupt라고 한다.
다중 인터럽트를 처리하는데에는 2가지 방법이 있다.
- 방법 1 : CPU가 인터럽트 서비스 루틴을 처리하고 있는 도중에는 새로운 인터럽트 요구가 들어오더라도 인터럽트 사이클을 수행하지 않도록 한다.(Interrupt Disabled <-> Interrupt Enabled)
- 방법 2 : 인터럽트 요구들 간에 우선순위를 정하고 우선순위가 낮은 이터럽트 요구를 처리하고 있는 동안에 우선순위가 더 높은 인터럽트 요구가 들어오면 현재의 인터럽트 서비스 루틴의 수행을 중단한 후, 새로운 인터럽트를 처리한다.
4) 간접 사이클
실행 사이클에서 사용될 데이터의 실제주소(유효주소)를 기억장치로 부터 읽어오는 과정
인출 사이클과 실행 사이클 사이에 위치한다.
간접 사이클은 항상 수행되는 것은 아니며 명령어 내의 특정비트(ex : I비트)가 1로 set된 경우에만 수행된다. 이 사이클은 간접 주소지정 방식에서 사용된다.
t0 : MAR <- IR(addr)
t1 : MBR <- M[MAR]
t2 : IR(addr) <- MBR
3. 명령어 파이프라이닝
4. 명령어 세트
