앞서 포스팅에서 살펴봤듯이 컴퓨터는 0과 1로 표현되는 정보만을 인식할 수 있다고 하였다.
구체적인 예시로 숫자와 문자를 0과 1로 어떻게 표현하고 있는지 살펴보자.
0과 1로 숫자를 표현하는 방법
컴퓨터는 0과 1로 표현된 정보 즉, 2진수만을 인식할 수 있다.
그렇다면 15와 같은 숫자는 1과 5로 표현되어있는데 어떻게 인식할 수 있는것일까?
사람들은 숫자를 십진법으로 표현하며 소통한다.
15는 사람들이 인식하기 편하도록 십진법으로 표현된 숫자이다.
십진법으로 표현된 15라는 숫자는 컴퓨터가 곧이 곧대로 알아들을 수 없고 2진수로 변환되어야 컴퓨터가 인식할 수 있다.
15라는 숫자는 2진수로 표현하자면 1111 로 표현될 수 있다.
2진수란?
2진수란 각 자릿수를 2의 지수단위로 표현한 숫자이다.
각 자리마다 숫자는 0,1로만 표현할 수 있고 1이 넘어가면 다음 자릿수로 넘어간다.
0이라면 해당 자리에 값이 없는 것이고 1이라면 해당 자리에 값이 있는 것이다.
예를 들어, 7이라는 숫자를 2진수로 표현한다면 111 로 표현할 수 있다.
첫번째 자리는 2⁰ ,두번째 자리는 2¹,세번째 자리는 2²,........n번째 자리는 2의 n-1 제곱이 되는 것이다.
이렇게 이진수로 숫자를 표현하는 방법을 2진법이라고 한다.
비트
컴퓨터가 표현할 수 있는 가장 작은 단위를 비트라고 한다.
즉, 비트만이 컴퓨터가 인식할 수 있는 표현 단위이다.
비트는 2진수로써 0과 1로 표현할 수 있는 가장 작은 단위이다.
1비트는 2가지 정보를 표현할 수 있는 데이터 크기이다.
2비트는 4가지 정보를 표현할 수 있고 3비트는 8가지 정보를 표현할 수 있다.
즉, n비트는 2ⁿ값을 갖는다.
하지만 파일,이미지,프로그램 등은 수십,수백만개의 비트로 이루어져있기 때문에 사람들이 이를 간편히 표현하기 위해 이보다 큰 단위들을 사용한다.
단위 종류는 다음과 같다.
- Byte
- KB
- MB
- GB
- TB
Byte
Byte는 8개의 비트를 하나로 묶은 데이터 단위이다.
즉, 1byte는 2⁸이다.
KB
KB는 1000Byte를 하나로 묶은 데이터 단위이다.
1KB = 1000byte
MB
MB는 1000KB를 하나로 묶은 데이터 단위이다.
1MB = 1000KB
GB
GB는 1000MB를 하나로 묶은 데이터 단위이다.
1GB = 1000MB
TB
TB는 1000GB를 하나로 묶은 데이터 단위이다.
1TB = 1000GB
프로그램,파일,동영상 등의 데이터 크기가 커질수록 비트로 표현하기에는 숫자가 너무 거대해져 사람들끼리 규약을 맺어놓은 위 단위로 데이터 단위를 표현한다.
워드
워드란 CPU가 한 번에 처리할 수 있는 비트의 크기이다.
워드의 크기가 클수록 CPU가 한 번에 처리할 수 있는 비트의 크기가 크다.
즉, 워드가 높을수록 좋은 성능을 가진 컴퓨터라고 생각할 수 있겠다.
워드는 CPU가 한번에 처리할 수 있는 비트 크기를 32비트로 기준으로 하여 구분지을 수 있다.
- 하프 워드 : 16비트
- 풀 워드 : 32비트
- 더블 워드 : 64비트
예를 들어, 인텔 x86 CPU는 풀 워드이고 x64 CPU는 더블 워드이다.
내 컴퓨터 워드

내 컴퓨터의 경우에는 x64이기 때문에 CPU가 한번에 64비트를 처리할 수 있다.
2진법
앞서 봤듯이 컴퓨터는 0과 1의 조합으로 표현한 숫자를 2진수라고 하였다.
이렇게 0과 1로 숫자를 표현하는 방법을 이진법이라고 한다.
십진법
우리는 보통 숫자를 표현할 때 십진법을 사용한다.
십진법은 자릿수마다 숫자 9가 넘어갈 때 자릿수를 올림해준다.
9 다음에 한 자릿수를 올려 10, 99 다음에 한 자릿수를 올려 100 이런 식으로 말이다.
이진법은 숫자가 1이 넘어가는 시점에 올림을 해주면 된다.
예를 들어, 숫자 2는 첫째 자릿수에서 숫자 1이라는 숫자가 넘었기 때문에 다음 자릿수로 넘겨 10(2진법)이라고 표현할 수 있다.

숫자 3은 11(2진법)으로 표현한다.
첫째 자릿수로 1을 표현하고 둘째 자릿수로 2를 표현한다.
그리고 각 자릿수로 표현한 숫자를 더하여 3이 된다.
숫자 4는 첫째 자릿수,둘째 자릿수만으로 표현하기에 둘 다 1을 초과하기 때문에 셋째 자릿수로 넘어가야하여 100(2진법)으로 표현해야한다.
위 예제에서 살펴보면 알겠지만 2진법으로 표현한 숫자의 각 자릿수는 2의 지수가 되는 것을 알 수 있다.
이진법상으로 첫째 자릿수가 1일 때는 2⁰이다.
둘째 자릿수가 1일 때는 2¹이다.
셋째 자릿수가 1일 때는 2²이다.
이진법의 각 자릿수가 0이 아닌 1일 때 해당 자릿수의 값을 알고 싶다면 자릿수에서 -1을 한만큼을 2의 지수로 달아주면 된다.
이진법상 넷째 자릿수가 1이라면 해당 값은 넷째 자릿수에서 -1을 한 3이니깐 2³ => 8이라는 값을 가진다.
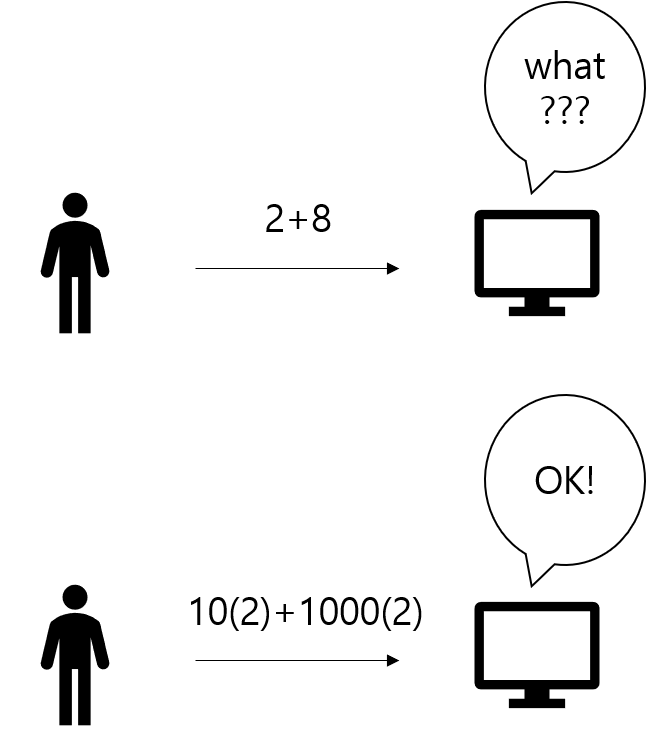
하지만 우리가 숫자10을 볼 때 이 숫자가 십진법으로 표현한건지 이진법으로 표현한건지 알 수 없다.
때문에 해당 숫자를 2진법으로 표현했을 경우, 따로 첨자를 붙여준다.
수학적으로 표기했을 경우에는 숫자 끝에 아래 첨자 (2)를 붙여주고 코드상으로 표현할 때는 숫자 앞에 0b를 붙여준다.
숫자 10을 이진법으로 표현했을 경우, 수학적으로 표기했을 때에는 1010(2),코드상으로 표현했을 때는 0b1010라고 표현할 수 있다.
16진법
어떠한 데이터를 2진법으로 표현하고 소통하기에는 숫자가 너무 길어진다.
이를 위해서 16진법이라는 표현 방법을 사용하기도 한다.
(컴퓨터는 앞서 말했듯 2진법으로 표현된 숫자만 인식할 수 있다.
결국 16진법으로 표현된 수도 2진법으로 변환되어야한다.
다만, 표현하기 편하기 위해서 16진법을 사용하는 것이다.)
16진법은 16의 제곱단위로 자릿수가 끊어지며 10부터는 알파벳으로 표현된다.
예를 들어 10을 16진법으로 표현할 때에는 A라고 표현되고
30을 16진법으로 표현하면 1E라고 표현할 수 있다.
2진수의 음수표현
16진법
2진수 <=> 16진수
문자를 표현하는 방법
문자 또한 컴퓨터가 0과 1로 표현되는 2진법으로 인식할 수 있다.
즉, 컴퓨터상에서 우리가 사용하고 있는 문자는 이진법으로 변환될 수 있기에 컴퓨터가 문자를 인식할 수 있는 것이다.
컴퓨터가 문자를 표현하고 인식하는데에 있어서 사람들끼리 소통하기 위한 개념들이 있는데 다음과 같다.
문자 집합(Character Set)
컴퓨터가 인식하고 표현할 수 있는 문자들의 집합
문자 인코딩(character encoding)
문자를 컴퓨터가 인식할 수 있는 0과 1로 이루어진 2진법으로 변환하는 과정
문자 디코딩(character decoding)
컴퓨터가 인식할 수 있는 0과 1로 이루어진 2진법을 문자로 변화하는 과정
ASCII(American Standard Code Information Interface)
아스키코드는 미국에서 최초로 만든 문자집합이다.
총 127가지의 문자를 표현할 수 있고 하나의 문자에 할당되는 데이터는 1byte(8비트)이다.
아스키 코드는 영어 알파벳 소/대문자와 0~9까지 숫자 등 키보드에 있는 특수문자들은 대부분 표현할 수 있지만 영어 알파벳이외 다른 나라의 문자와 특수 문자, 이모티콘은 표현할 수 없다.
우리 나라(한국)의 문자를 표현할 수 없다는 것이 가장 큰 단점이다.
코드 포인트
문자에 할당되어 있는 십진법으로 표현된 숫자값이며 해당 숫자값은 컴퓨터가 인식할 수 있도록 2진법으로 변환된다.
EUC-KR(Extend Unix Code)
아스키 코드가 한글을 표현할 수 없다는 단점에서 고안되어 만들어진 문자집합이 EUC-KR이라는 문자집합이다.
EUC-KR은 한글을 표현할 수 있다는 장점은 가졌지만 모든 한글 음절을 표현할 수 없다는 단점을 가졌다.
예를 들어, 쀍,쀓 와 같은 문자는 표현할 수 없었다.
때문에 특수한 문자를 표현하는 경우에 문자가 깨지는 불편한 점들이 발생하곤 했다한다.
EUC-KR은 하나의 글자당 2byte의 데이터 크기를 부여한다.
유니코드
EUC-KR의 단점을 보완하여 나온 문자집합이다.
대중적으로 많이 사용하는 문자 집합이며 컴퓨터가 거의 모든 나라들의 문자를 표현하고 인식할 수 있다.
EUC-kr에서 표현할 수 없었던 한글 음절을 표현할 수 있게 되어 모든 한글 문자를 표현할 수 있게 되었고 특수문자,이모티콘 등 대부분의 문자들을 표현할 수 있게 되었다.
UTF-8(Unicode Transformation Format)
유니코드를 인코딩하는 방식이다.
하나의 문자에 1byte부터의 데이터 크기가 할당된다고 하여 UTF-8이다.
하나의 문자마다 1byte ~ 4byte까지의 데이터 크기를 할당하며 문자에 따라 할당되는 데이터 크기가 다르다.
한글은 대부분 인코딩될 때에 글자마다 3byte의 데이터 크기가 할당된다.
UTF-16은 하나의 문자에 할당되는 데이터 크기가 2byte부터 시작되고 UTF-32는 하나의 문자에 할당되는 데이터 크기가 4byte부터 시작된다.
