[논문 리뷰] Anomaly detection in video using predictive convolutional long short-term memory networks
2022 하계 Paper Review

본 Paper Review는 고려대학교 스마트생산시스템 연구실 2022년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
-
단순한 이미지가 아닌 연속적인 Sequence에 의해 구성된 영상에서 이상을 탐지하는 것은 쉬운 일이 아님. 이유는 이상 행동을 정의하는 것이 모호하기 때문에 실제로 라벨값도 주어져 있지 않은 경우가 대부분이기 때문.
-
따라서 본 논문의 저자는 composite Convolutional Long Short-Term Memory (Conv-LSTM) 네트워크 구조를 제시함으로써 라벨이 충분히 주어져있지 않은 상황에도 이상 행동을 탐지하는 방법론을 제시함.
-
해당 네트워크 구조는 input으로 과거 및 현재의 데이터가 주어졌을 때, (1) 이를 다시 reconstruct하는 기능, (2) 미래를 예측하여 generate하는 기능을 동시에 수행 가능하기에 Composite한 구조임.
-
끝으로 qualitatively, quantitatively 각각의 관점에서 모델을 평가함.
1. Introduction
영상 속 Anomalies: unusual하며 irregular한 behavior
이를 사전에 탐지하는 것은 중요하며, 다양한 분야에서 활용될 수 있음.
ex) surveillance, intrusion detection, health monitoring, event detection

단순히 영상 속 Action을 Recognition하는 방법론은 행동이 명확하기 때문에 더 쉬움.
하지만 영상 속 Action이 Anomaly인지를 파악하는 방법론은 이상 행동이 모호할 뿐더러 규정되지 않은 넓은 범위의 행동이 존재하기 때문에 까다로움.
또한 특히 어려운 이유는 spatio-temporal 즉 시,공간적으로 이상 행동을 탐지해야 하기 때문.
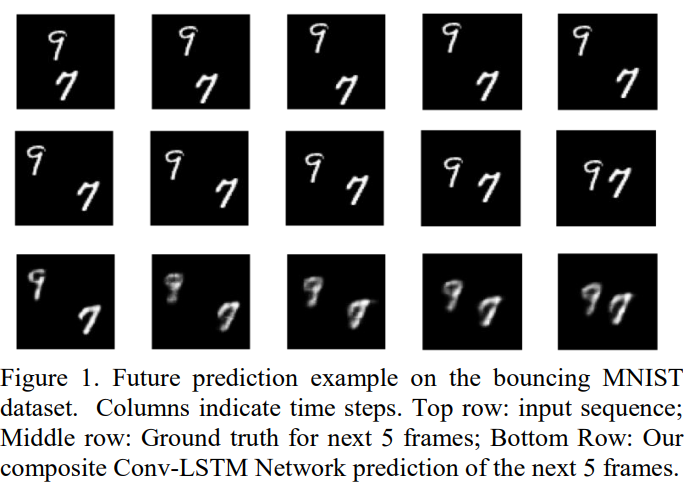
위에서 제시된 Figure 1은 현재의 정보(가장 윗 줄)이 주어지면 5 프레임 후의 모습을 모델이 예측하는 것을 보여줌.
5 프레임 후의 실제값(두번째 줄)과 모델이 예측한 5 프레임 후의 예측값(세번째 줄)이 어느 정소 유사함.
이처럼 영상에서 이상을 탐지하거나, 영상을 예측하기 위해서는 시,공간적으로 재구성 혹은 예측해야할 필요가 있음.
본 논문에서는 두가지의 Contribution을 제시함.
1) composite Conv-LSTM 네트워크 구조를 통해 생성 모델을 구성하여 input으로 주어진 데이터를 재복원하거나 이를 토대로 미래의 정보를 예측할 수 있음.
2) 해당 네트워크 구조를 사용하여 영상 속 anomalous한 부분을 regularity evlaution 알고리즘을 통해 검출해낼 수 있음.
2. Related Works
기본적으로 Anomaly Detection (이상 탐지) 방법론은 정상 데이터의 양은 충분하나 비정상 데이터의 양이 몹시 적을 때 둘을 분류하고자 고안된 것임.
지도 (Supervised), 반지도 (Semi-supervised), 비지도 (Unsuperviesed) 학습 방식으로 여러 개의 모델들이 제안되어 왔음.
위 세가지 학습 방식 내 모델들은 각자의 방법대로 이상을 탐지하는데, 본 논문의 저자는 그 중 reconstruction error 기반 Semi-supervised 방법론을 고려함.
Reconstruction error 기반으로 이상을 탐지하는 대표적인 네트워크 구조는 Autoencoder가 있음.
그 중 『Learning Temporal Regularity in Video Sequences』 논문에서는 CNN 구조를 사용하여 Reconstruction error를 구하고 이를 기반으로 regularity score를 도출함.
저자는 이미지에 특히 적합한 CNN에 추가로 시계열적 특성을 띄는 데이터를 학습하는 데에 적합한 LSTM 구조를 접목한 Conv-LSTM 방식을 토대로 generative model을 구성하고자 함.
2.1 Convolutional LSTM Units
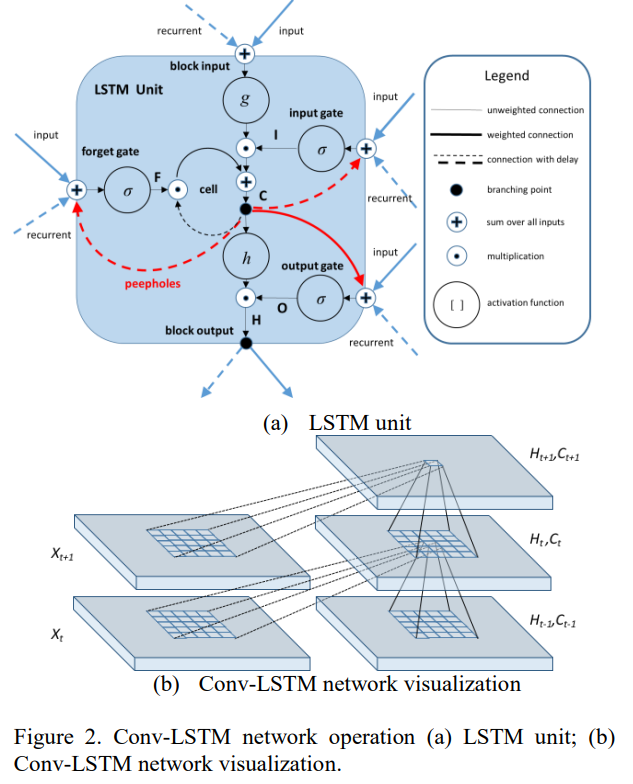
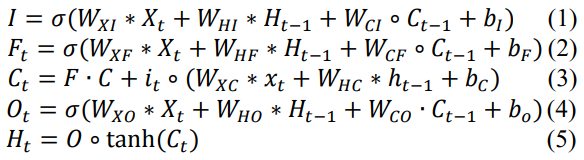
Conv-LSTM의 네트워크 구조는 그렇게 복잡하지 않음.
Fully connected LSTM (FC-LSTM)에서 다음 timestep으로 정보를 전달할 때 Convolutional filter를 거쳐서 넘기도록 변경하면 됨.
따라서 위 (1)~(5)까지의 수식은 기존 LSTM에서 Input, Forget, Cell, Output gate 및 Hidden state를 정의하는 방식을 따름.
Figure 2와 같이 네트워크를 구성한다면, spatial한 정보를 temporally하게 전달하여 학습을 시킬 수 있음.
이 때 모든 timestep에서 동일한 parameter 공유하도록 구성.
Figure 2의 (b)는 영상으로 생각한다면 다음 프레임으로 넘어갈 때의 temporally하게 movement를 반영한다고 볼 수 있음.
2.2 Future Video Prediction
앞서 말한 네트워크 구조를 바탕으로 영상에 접목하여 학습, 예측, 복원한다면 다음과 같음.
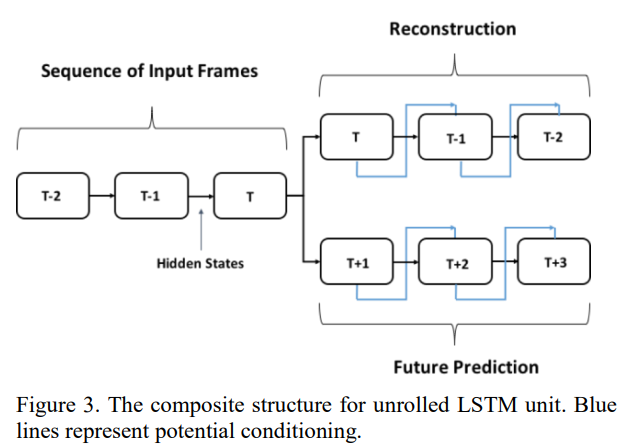
동일한 Input이 주어졌을 때, Target output을 어떤 것으로 하느냐에 따라서 모델의 목적이 달라짐.
1) Target = Input : Reconstruction (input 자체를 복원하는 방법)
2) Target = subsequent frames : Prediction (future sequence를 예측하는 방법)
단순히 복원하는 작업보다 미래의 sequence를 예측하는 작업이 더 많은 정보를 필요로 하고 까다로움.
이를 위해 장기 의존성 (Long-term dependency) 문제를 해결하고자 제안된 방법론인 LSTM을 사용하는 것.
과거로부터의 정보를 잃지 않고 학습을 진행하여 미래를 정확하게 예측할 수 있다면 모델이 복원 및 예측하는 성능을 향상시킬 수 있을 것.
『Convolutional LSTM network: A machine learning approach for precipitation nowcasting』 논문에 따르면, Conv-LSTM 구조를 encoder-decoder 방식으로 사용하는 것이 spatio-temporal 정보를 학습하는 데에 더 효과가 좋음.
추가적으로 위 논문에서는 decoder에서 output을 산출하기 전 1x1 convolutional 작업을 거치도록 함.
해당 모델은 video sequence를 예측하는 LSTM에 비해 뛰어난 성능을 보였음.
3. Anomaly Detection with Conv-LSTMs
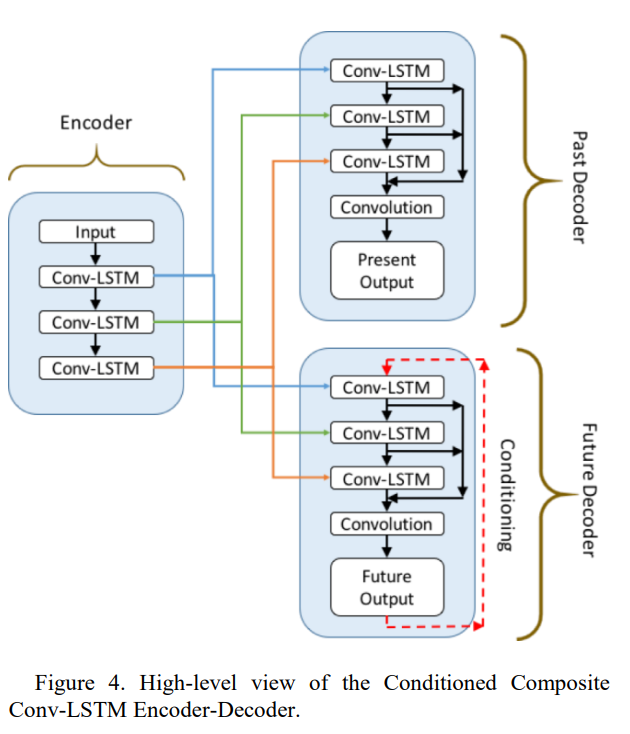
3.1 Composite Conv-LSTM Encoder-Decoder
본 논문에서 non-overlapping patch로 프레임을 자르고 이를 Composite Conv-LSTM Encoder-Decoder 구조를 거쳐 영상의 regularity을 학습할 수 있도록 방법론을 제안함.
학습 (Train) 시에는 정상 행동만을 담은 영상들을 사용하고, 예측 및 복원 시에는 정상과 비정상 행동 모두를 사용함.
Figure 4에서 알 수 있듯 해당 네트워크 구조는 end-to-end로 학습 및 복원, 예측하며 encoder와 decoder 구조로 짜여져 있음.
Encoder
발생 순서에 따라 프레임들을 non-ovelapping하게 patch로 잘라 input으로 사용.
또한, reshape하여 정보를 어느 정도로 포함 혹은 잃을 지를 결정.
각 마지막 timestep에서의 Conv-LSTM layer의 output을 encoding으로 사용하여 Decoder에 전달.
기존의 CNN 방법론과 다르게, Max-pooling layer는 미사용.
Decoder
Decoder는 크게 두가지 구조로 사용.
(input으로 주어진 과거 영상 sequence 복원 & 미래 영상 sequence 예측)
(1) Past Decoder (복원)
각 layer에서의 output을 concatenate한 후 1x1 convolutional filter를 거쳐서 복원함.
(2) Future Decoder (예측) --> Uncoditioned & Conditioned
Uncoditioned decoder의 경우 Past Decoder와 같은 구조를 띔.
반면, Conditioned decoder는 Future Output으로 나오는 summed ouput을 다시 first layer에 input으로 사용.
Past Decoder와 달리 Future Decoder에서만 "Conditioning"을 사용하는 이유는 Past Decoder는 하나의 결과만을 복원하는 반면, Future Decoder는 여러 결과가 예측될 수 있기 때문.
따라서 Conditioning으로 예측될 수 있는 결과에 제한을 두는 것.
3.2 Anomaly Evaluation Algoritm
Anomaly를 판단하는 방법은 크게 Qualitative 방법과 Quantitative 방법으로 나눌 수 있음.
(1) Qualitative 방법
- Using Mean Square Error (MSE)
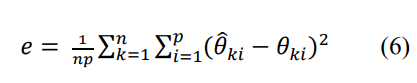
정상만을 사용하여 모델을 학습했기 때문에 비정상을 예측 혹은 복원할 때는 MSE 값이 정상을 예측, 복원할 때보다 눈에 띄게 클 것임.
(2) Quantitative 방법
- Using regularity score
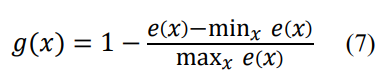
Error 값이 주어지면 이를 0과 1 사이의 값으로 정규화 시킴.
Normal의 경우 g(x) 값이 1에 가깝고, Abnormal의 경우 g(x) 값이 0에 가까움.
추가적으로 Persistence 1D algorithm 방식 (Persistence1D: Extracting and filtering minima and maxima of 1d functions) 을 통해 local minima와 local maxima를 계산할 수 있음.
특정 threshold를 정하고 각 프레임의 regularity score g(x)를 대입시켜서 anomaly를 판단할 수 있음.
결론적으로, local minima 값을 갖는 프레임은 anomaly, local maxima 값을 갖는 프레임은 normal로 판단하여 이상 행동이 보이는 구간을 설정할 수 있음.
예측된 구간과 실제 ground truth anomaly 구간이 어느 정도 겹치는 지에 따라서 모델의 성능을 평가.
4. Results
4.1 Experimental Setup
논문에서 사용된 데이터셋
- UCSD Pedestrian Datasets
--> Pedestrian 1
--> Pedestrian 2
도로에 따라서 구분 - Avenue Dataset
- Subway Datasets
--> Entrance gate
--> Exit gate
위 데이터셋들을 사용하여 qualitatively 하게 visualization하고, quantitatively하게 average loss와 detection rate을 계산하여 평가.
4.2 Parameter Selection
Model Parameter
- input image : 224x224 pixels, grayscale
- 64 patches로 사용
- total # of filters : 512 (image size에 따라 결정)
- input, output, forget gate : sigmoid 사용 / hidden, cell gate : tanh 사용
- final convolutional layer : sigmoid 사용
- Padding 사용 (image size 유지하기 위해)
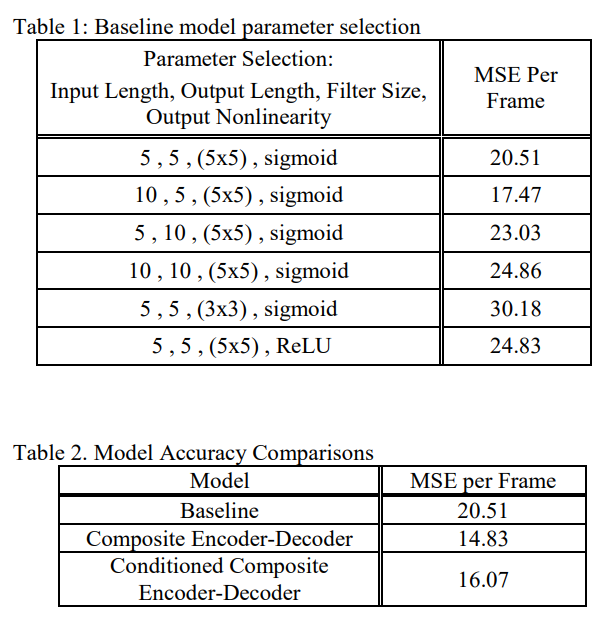
Table 1에서는 input, output 길이와 filter size 그리고 final convolutional layer에서 sigmoid 대신 ReLU를 사용했을 시의 MSE 값들을 비교함.
input의 길이를 길게 하면 더 좋은 성능을 보이지만 학습 시간이 약 1.5배가 되는 tradeoff 존재.
또한, 필터 사이즈를 작게하는 것과 final convolutional layer에서 ReLU를 사용하는 것은 효과적이지 못함.
Table 2에서는 unconditioned Encoder-Decoder 구조가 가장 좋은 성능을 보임.
Optimization and Initialization
- RMSProp --> Adagrad와 Adam 보다 좋은 성능
- learning rate : 10-4 / decay rate : 0.9
- 미니 배치 사용 & 25,000 iteration
- Early stopping 사용
- 가중치 초기화 : Xavier 알고리즘
- input-to-hidden & hidden-to-hidden 모두 같은 크기의 convolutional filters 사용
Evaluation Parameters
- local minima 앞 뒤로 50 프레임 : anomalous regions
- 실제와 50% 겹치면 옳게 탐지한 것을 판단.
4.3 Predicting the Future of a Video Sequence

Pedestrian 1 데이터셋을 학습해서 복원 및 예측한 결과는 위와 같음.
보행자를 정상, 그 밖의 vehicle과 같은 사물을 비정상으로 간주. 정상인 보행자만을 사용해서 학습 진행.
그 결과, 과거 시점의 abnormal인 차량은 noisy하기는 하지만 정답을 복원하는 과정이기에 어느 정도는 유사하게 복원.
반면, 미래 시점의 abnormal인 차량은 제대로 예측이 되지 못하며 정상인 보행자와 유사하게 예측됨을 알 수 있음.
4.4 Anomalous Event Detection
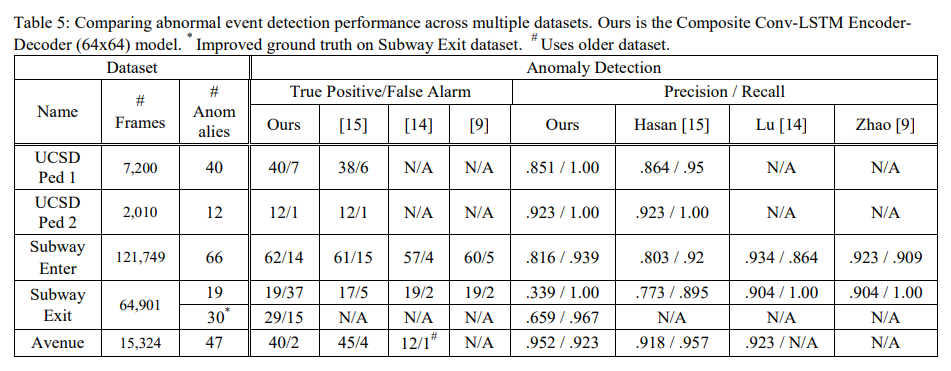
4.4 절에서는 각 데이터셋에 따른 논문에서 제시한 모델의 성능과 기존 방법론과의 비교가 이루어짐.
기존 SOTA 방식은 위 표에서 [15] 부분.
결론적으로 본 논문에서 제시된 composite Conv-LSTM 방법론은 기존 SOTA 방법론과 비교했을 때 유사하거나 더 좋은 성능을 보임.
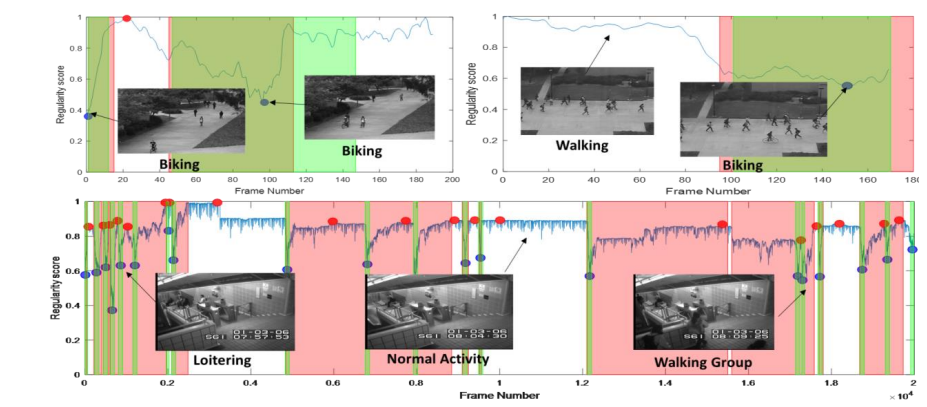
추가적으로, 본 논문의 방법론을 사용했을 시 위 그림과 같이 Local maxima 및 local minima를 시각적으로 파악하여 어느 timestep 구간에 anomaly가 발생했는지에 대한 alarm을 제공할 수 있음.
5. Conclusions
- label이 충분하게 주어지지 않은 영상에서 abnormal을 탐지하기 위해 composite Conv-LSTM 네트워크 구조의 방법론을 제시.
- 과거 및 현재 시점의 영상 sequence를 복원하고 동시에 미래 시점의 영상 sequence를 예측할 수 있다는 데에 의의가 있음.
- 이상 탐지 성능 또한 기존 SOTA 방법론과 견줄만 함.
함께 읽으면 좋을 논문
『Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals』
(리뷰) Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals
