
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2022년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
-
Object detection을 direct set prediction problem으로 간주하고 해결
-
Prior knowledge (NMS, anchor genetration)를 사용하지 않아 detection pipeline을 간소화
-
제안된 모델은 DEtection TRansformer (DETR)
-
제안하는 것: Partite matching (이분매칭) & Transformer encoder-decoder architecture
-
객체 쿼리를 고정해놓고, 객체간 관계와 Prediction을 병렬적으로 추론 가능
-
SOTA baseline 모델 중 하나인 Faster R-CNN과 견주어도 부족함 없음
-
나아가, 객체 검출 외에 Segmentation에서도 generalize 될 수 있음
1. Introduction
Object Detection은 bounding box와 category label의 집합을 찾는 과정입니다.
기존에는 해당 집합들을 예측하기 위해서 indirect한 방법을 주로 사용했습니다.
ex) surrogate regression and classification problems on a large set of proposals, anchor, window centers
집합을 예측하는 것이기에 순서, 중복은 허용되지 않습니다.
따라서 중복 예측을 피하기 위해서 직접 anchor sets을 정하고 휴리스틱하게 target box를 정하는 postprocessing 단계가 필수적이었습니다.
반면 본 논문의 모델은 앞선 과정들을 간소화하기 위해 direct set prediction approach를 제안합니다.
다른 분야에서는 많이 쓰였을지 몰라도 object detection에서는 새로운 방법으로 제안된 것이입니다.
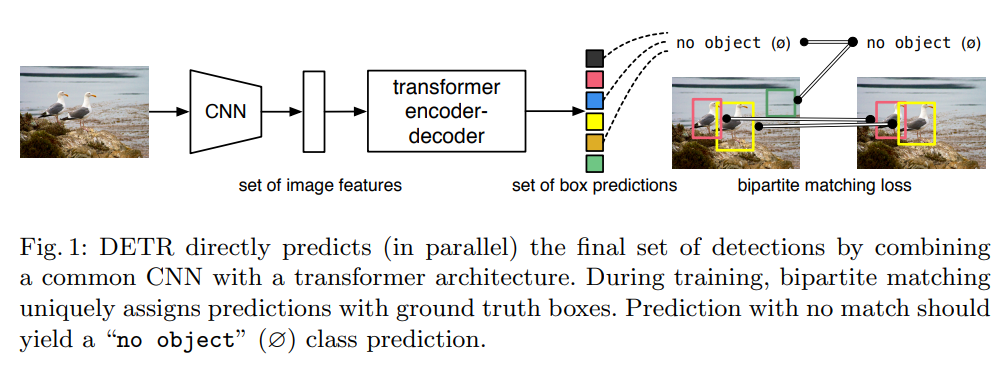
위 도식에서 알 수 있듯이, 본 논문의 모델은 transformer 기반의 encoder-decoder 구조를 채택했고 이는 sequence prediction에 적합한 모델입니다.
특히 Transformer를 채택했기 때문에 전반적인 인스턴스간의 상호작용을 잘 파악할 수 있도록 해주고 각 픽셀별 연관성 정보도 제공하는 self-attention mechanism을 활용할 수 있게 됩니다.
결론적으로 Set prediction에서 필요했던 중복 예측 제거 기능을 수행할 수 있습니다.
제안된 DEtection TRansformer (DETR) 모델은 예측된 object와 ground truth object간의 Partite matching (이분매칭)을 수행하는 set loss function을 사용해서 end-to-end하게 학습이 이루어집니다.
장점은 직접 manually하게 정했던 spatial anchors나 NMS같은 prior knowledge가 필요가 없다는 것입니다.그리고 customized된 layers도 따로 정해줄 필요없이 손쉽게 standard CNN과 transformer 구조를 사용하면 됩니다.
DETR의 가장 큰 특징 두 가지는 Partite matching (이분매칭)과 병렬처리가 가능한 Transformer 구조입니다. 이는 기존의 autoregressive하게 학습하는 RNNs 구조를 사용하는 것이 아니라 병렬적으로 decoding을 수행한다는 것입니다. 따라서 순서에 영향받지 않는 Set prediction에 적합합니다.
마지막으로 본 논문은 가장 유명한 object detection datasets인 COCO를 사용해서 모델의 성능을 검증하였고, 개선된 Faster R-CNN에 견주었을 때 더 좋은 성능을 보임을 증명해냅니다.
특히 larget object에 대해서 높은 성능을 거두었는데, 이는 transformer의 non-local computation에 의해 나온 결과입니다.
반면 small object에 대해서는 상대적으로 좋지 못한 성능을 보였는데 이는 앞으로 개선해나가야 할 부분입니다.
Training setting의 측면에서도 DETR은 다른 object detectors와 달랐는데, 특히나 extra-long training schedule 즉 너무 긴 학습시간이 소모되었고, 보조적인 decoding loss를 transformer에 추가했다고 합니다.
Ablation study를 통해서 왜 DETR이 좋은 성능을 보였는지에 대한 부가적인 설명을 하고자 합니다.
마지막으로 DETR은 다양한 Task로 확장이 가능한데, 대표적으로 Segmentation 문제에 대해서도 확장이 가능합니다.
2. Related work
2.1 Set Prediction
Directly하게 집합을 예측하기 위해서 딥러닝 모델을 사용하는 것은 정석적인 것은 아니었습니다.
먼저 기본적인 set prediction을 위한 노력으로는 multilabel classification이 있었습니다.
하지만 해당 방법론으로는 요소간의 잠재적인 구조를 파악해야하는 detection 문제에 적합하지 않았고,
near-duplicates 문제를 해결하지도 못했습니다.
이러한 문제들을 해결하기 위해서 non-maximal suppression (NMS)와 같은 방법론들이 사용되었고,
이는 postprocessing 작업이 필수적이었습니다.
하지만 Direct하게 set prediction을 한다면 이러한 postprocessing 작업이 불필요하게 됩니다.
이러한 측면에서 중복을 피하기 위해 모든 예측된 요소들간의 상관관계를 모델링 하는 global inference가
필요하게 되었고, 이를 위해 auto-regressive sequence 모델과 같은 RNN 계열 모델들이 사용되었습니다.
그리고 집합에 대한 예측이기 때문에 예측의 순서에 따라서 loss function이 일정해야합니다.
본 논문에서는 Hungarian algorithm 기반으로 loss function을 구성하였고, 그에 따라서
ground-truth와 prediction에 대한 Partite matching (이분매칭)할 수 있게됩니다.
결론적으로 본 논문은 Set Prediction 관점에서 이분매칭을 통해 예측의 순서와 상관없이 loss function을 최소화시킬 수 있었고 추가적으로 transformers를 통해 병렬적인 학습이 가능하게 했습니다.
2.2 Transformers and Parallel Decoding
다음으로 트랜스포머에 대한 간략한 설명과 본 논문에서 어떻게 활용했는지가 소개됩니다.
Attention Is All You Need 논문을 살펴보면 트랜스포머에 대한 전반적인 지식을 얻을 수 있습니다.
기본적으로 Attention은 전체적인 input sequence에서의 정보를 활용하고자 합니다.
그리고 Transformer는 self-attention layers를 사용합니다. 이를 통해 whole sequence에 대한 정보로 업데이트하게 됩니다.
그래서 실제로 long sequence를 가지는 task에 활용이 많이 되고 있습니다.
결과적으로 트랜스포머는 long sequence의 정보를 처리하는 데에 용이하고 병렬적인 학습이 가능해서 computing resource를 크게 절약할 수 있기에 본 논문에서 채택했습니다.
2.3 Object detection
최근에 Object detection (사물 검출) 분야가 각광받으면서 많은 Detector들이 제안되고 있습니다.
크게 proposals (후보)와 관련해서 박스를 만들어서 예측하는 Two-stage detectors와
anchors나 사물의 중심에 대한 grid와 관련하여 예측하는 Single-stage methods가 존재합니다.
이러한 방법론들은 처음 guess를 어떻게 하는가에 대해서 성능이 크게 좌우됩니다.
본 논문의 방법론은 이러한 손수 처리해줘야하는 수고를 덜고, anchor 대신
input image에 관련해서 absolute box prediction으로 직접적으로 set을 detection할 수 있게 됩니다.
Set-based loss
몇몇 detectors들은 이분매칭 loss를 사용하긴 합니다.
하지만 해당 방법론들은 convolutional 또는 fully-connected layers로만 모델링 되어있으며,
수작업으로 NMS post-processing이 이들의 성능을 높여주곤 했습니다.
즉, 비록 Set-based loss를 사용하고 있었을지라도, 여전히 manually하게 처리해야만 성능을 높일 수 있었습니다.
Recurrent detectors
end-to-end set predictions 그리고 instance segmentation이 본 논문의 방법론과 유사하긴 합니다.이분매칭 loss를 사용하고, CNN 기반의 encoder-decoder 구조로 직접적으로 bounding box를 생성합니다.
하지만 이들은 small dataset에만 나쁘지 않은 성능을 보였고 modern baseline보다는 성능이 떨어집니다.
따라서 RNN 기반의 autoregressive model들이 제안되곤 했는데, 본 논문은 그보다 더 좋은 성능을 보여주기 위해서, 병렬적인 학습이 가능한 transformers를 활용하고자 합니다.
3. The DETR model
DETR 모델은 direct set predictions을 하기 위해서 두가지 정도의 방법을 사용합니다.
(1) Predicted된 box와 Ground truth box 간의 unique한 matching을 하기 위한
set prediction loss를 사용
(2) set of objects을 예측하고 그들의 관계를 모델링 하는 architecture 사용
따라서 이를 도식화하면 다음과 같습니다.
3.1 Object detection set prediction loss
DETR은 먼저 충분히 큰 N개 종류의 predictions이 이루어진다고 가정합니다.
그러고 나서 예측된 값과 실제값을 이분 매칭하게되고, 이를 최적화하게 됩니다.
이를 위한 수식은 다음과 같습니다.
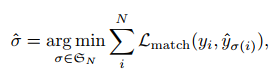
수식을 살펴보면, y hat 값은 예측값 집합, 그냥 y 값은 실제값 집합입니다.
그래서 매칭 loss 값의 합을 가장 작게 만들어주는 sigma를 찾아주면 되는데,
여기서 sigma는 말 그대로 매칭된 결과로 볼 수 있겠습니다.
매칭된 loss 값은 pair-wise한 matching cost입니다.
결과적으로 sigma를 찾는 task는 최적 할당 문제로 생각할 수 있고,
다시 말해 가중 이분 매칭입니다. 이는 Hungarian algorithm에 따라 이루어집니다.
해당 Task를 수행하면서 결과적으로 생성되는 output은 Class와 Bounding boxes가 나옵니다.
그리고 Bounding box는 일반적으로 중심 좌표, 높이, 너비에 대한 정보를 담습니다.
본 논문에서는 Bounding box 관련 값들을 0과 1 사이로 normalize 합니다.
그리고 매칭된 loss 값의 수식도 존재하는데요, 이는 다음과 같습니다.
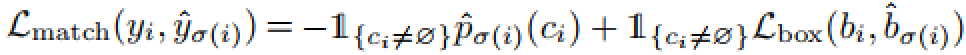
이는 class가 잘 맞고, bounding box 또한 잘 맞혔다면 Loss 값이 줄어드는 형태를 띕니다.
Bounding box에 대한 Loss 수식은 다음과 같습니다.
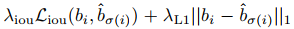
전자, 즉 iou에 대한 Loss는 크기와 상관없이 bounding box를 많이 겹칠 수 있도록 해줍니다.
그리고 L1에 대한 Loss 값 또한 두 개의 bounding box가 유사해지도록 하는 역할을 수행합니다. 대신 크기에 영향을 받곤 합니다.
위에서 살펴본 이분 매칭을 통해 기존 region proposal 혹은 anchor와 같은 heuristic한 방법론과도 잘 맞는다는 것을 알 수 있습니다.
이분 매칭의 결과로 set prediction의 중복된 결과를 피할 수 있게 됩니다.
앞서 말한 내용을 종합한 전체 Hungarian Loss는 다음과 같이 정리가 가능합니다.
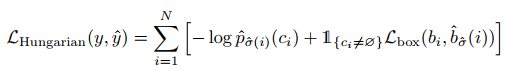
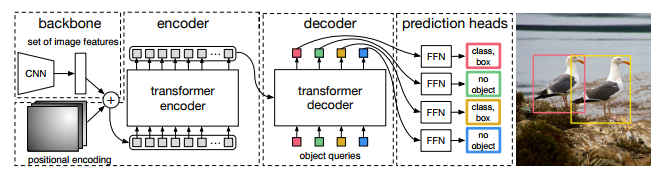
3.2 DETR architecture
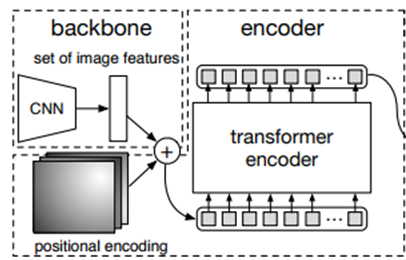
DETR의 전체적인 architecture는 위 그림과 같습니다.
본 논문에서는 해당 구조에 대해서 간단한 구조를 가지고 있으며
구현 또한 파이토치로 50 lines가 안된다고 합니다.
해당 구조에 대해서 간단하게 살펴보겠습니다.
- Backbone
먼저 backbone 구조는 어떤 feature를 추출하기 위해서 사용되는 구조로,
Activation map을 뽑을 수 있도록 합니다.
- Transformer encoder
Backbone에서 뽑힌 Activation map은 Transformer에 들어가기 위해서 형태가 또 바뀔 필요가 있습니다.
Sequential한 데이터 형태로 feature 값을 가지고 있도록 하기 위해서 encoder 파트 전에
1x1 Convolution을 이용하게 됩니다.

따라서 위와 같이 dxWH 차원의 새로운 feature map으로 변형됩니다.
그래서 기본적으로 standard 형식의 encoder layer에 넣기 전에 알맞는 형태로 바꿨습니다.
여기서 standard 형식이라는 것은 multi-head self-attention module과 Feed forward network로 이루어져있음을 뜻합니다.
- Transformer decoder
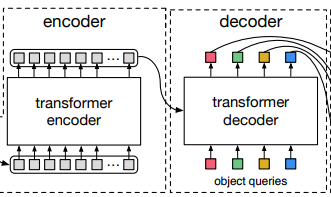
Encoding을 마친 뒤 decoder 파트에 들어가게 되는데요, Decoder 파트는
각 N개의 object queries가 존재한다고 했을 때, 그들이 각각 병렬적으로 decoding이 되어서
해당 정보들이 기본적으로 하나의 인스턴스가 되어서 Prediction 되게 됩니다.
여기서 object query는 학습이 가능한 positional embedding 이고,
인스턴스는 Class가 같다고 하더라도 개별적인 사물 하나하나를 의미하게 됩니다.
특히 DETR에서는 self-attention 그리고 encoder-decoder attention을 사용하기 때문에,
global하게 사물을 추론하면서 결과적으로 분리가 되도록 만들어줍니다.
구체적인 내용 (ex. detailed parameter)은 논문의 부록 파트에서 자세하게 설명이 되고 있고, 현재의 간단한 리뷰에서는 다루지 않겠습니다.
- Prediction feed-forward networks (FFNs)
Decoding을 거쳐 최종적으로 예측되는 정보는 중심 정보(x, y), 높이, 너비와 클래스입니다.
이는 3-layer perceptron with ReLU 함수를 거쳐서 계산됩니다.
만약 클래스가 없다면 "no object"로 결과가 산출되고 이미지 상 Background에 해당합니다.
추가적으로 본 논문에서는 Auxiliary decoding losses를 사용해서 성능을 높였다고 합니다.
4. Experiments
본 논문에서 COCO 데이터셋을 사용해서 정량적으로 Faster R-CNN과의 성능 비교를 보입니다.
나아가 architecture와 loss에 관한 Ablation study를 진행해서 정성적인 성능 또한 보여줍니다.
결과적으로 DETR이 가변적이며, 확장 가능한 모델임을 강조하며 panoptic segmentation 결과 또한 보여줍니다.
Dataset
데이터셋으로는 COCO를 사용했고, 이는 약 12만개 정도의 Train data와 5천개 정도의 평가 데이터가 있습니다.
평균적으로 이미지에 존재하는 인스턴스는 7개, 최대는 63개로 알려져있습니다.
Technical details
여기 파트는 실제 학습을 위한 하이퍼파라미터 설정 사항에 대한 내용입니다.
논문을 참고하면 자세히 알 수 있습니다.
간단히만 말하자면, 실제 네트워크 구조는 Resnet 기반으로 이루어져있습니다.
그래서 모델 이름 또한 DETR-R101과 같게 설정되었습니다.
그리고 추가로 작은 image에 대해서 낮은 성능을 보이는 한계점을 극복하고자
Dilation을 적용했고 이에 따른 모델들은 DETR-DC5, DETR-DC5-R101과 같습니다.
4.1 Comparison with Faster R-CNN
모델의 성능 평가 지표는 Average Precision (AP)가 사용되었습니다.
이는 Recall 값과 Precision 값을 동시에 고려한 지표로
Recall 값에 따른 Precision 값의 평균 정도로 생각하면 되겠습니다.
계산은 precision-recall 곡선에서 그래프 선 아래 쪽의 면적입니다.
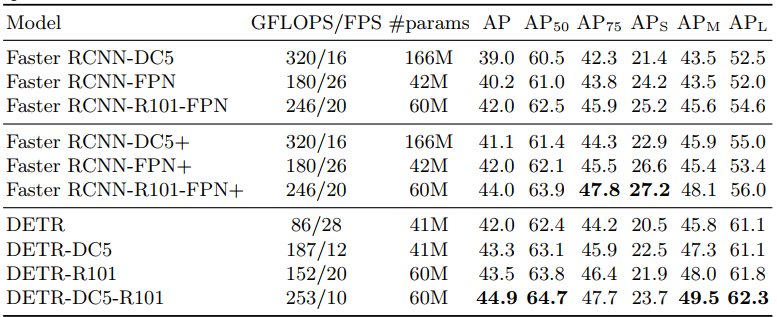
위 테이블만 봐도 알 수 있듯이, DETR의 경우 Faster R-CNN과 유사한 개수의 parameter를 학습에 사용했음에도 불구하고 Competitive한 결과를 도출해냄을 알 수 있습니다.
AP 옆에 붙는 숫자는 IoU로 보면 됩니다.
즉, AP75는 75% 겹치면 맞힌 것으로 보겠다는 뜻입니다.
그리고 S, M, L 은 Object의 Size로 생각하면 됩니다.
따라서, 큰 object의 경우 DETR이 잘 구분하지만, 작은 object는 상대적으로 구분을 못합니다.
결론적으로 Object Detection 분야에서 State-of-the-art라고 볼 수 있는
Faster R-CNN에 비교해서 충분히 경쟁력 있는 결과를 보였으며
특히 Size가 큰 Object에 대해서는 높은 성능의 구분을 수행했음을 알 수 있습니다.
4.2 Ablations
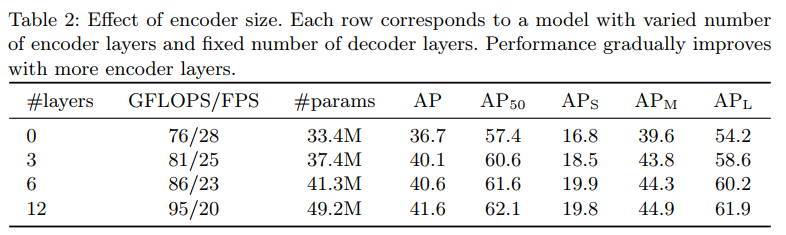
Encoder 구조는 global한 scene reasoning을 수행해서 object 들을 구별하는 데에 중요한 역할을 합니다.
따라서 위 테이블에서도 알 수 있듯이 많은 encoder layer를 사용할 때의 성능이 향상되는 것을 알 수 있습니다.

실제로 마지막 encoder layer에서의 activation map을 시각화해보면
어떻게 self-attention이 이루어지고 있는지를 확인할 수 있습니다.
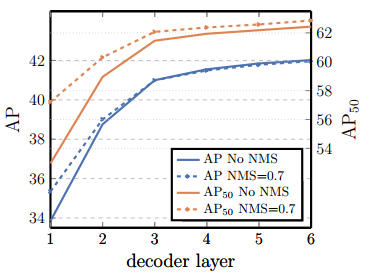
그리고 Decoder 또한 충분한 수의 layer를 사용해야 좋은 성능을 거둘 수 있음을 확인했습니다.
논문에서도 두개 혹은 그 이상의 연속적인 layer를 쌓아야 인스턴스가 중복되는 현상을 억제하여 좋은 탐지 성능을 보장할 수 있다고 합니다.
결론적으로 본 논문을 집필한 Facebook 팀은
Encoder는 global attention을 통해 각각의 인스턴스를 잘 분리해줄 수 있게되고,
Decoder는 각각의 Extremities (말단 정보) 사용해서 클래스를 잘 구분하고 boundary 또한 잘 얻을 수 있게 된다고 합니다.

FFNs 구조도 좋은 성능을 내기 위해서는 중요하다고 합니다.
그리고 중요한 점 중 하나로, 이미지에서 상대적인 위치 정보를 처리하기 위해서
Positional encoding 정보가 필요합니다.
그 이유는 Transformer 같은 경우, RNN과 비교했을 때 Recursive하게 각각의 output 정보를 활용하지 않기 때문에 별도로 position 정보를 줄 필요가 있다고 합니다.

위 테이블에서 알 수 있듯이 positional encoding이 주어졌을 때의 성능 향상이 가장 큽니다.
여기까지 Ablation study를 통해 살펴봤을 때, Transformer를 구성하는 요소들은 전부
성능 향상을 위해 필수적인 요소임을 확인할 수 있었습니다.
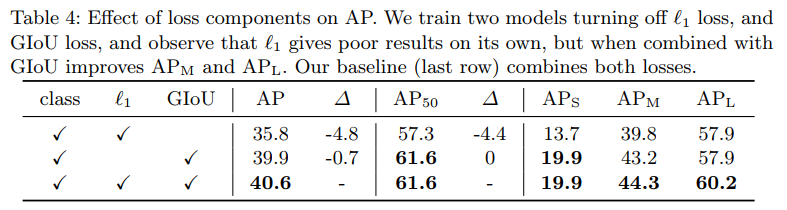
마지막으로 어떤 loss 함수의 구성을 사용했을 시에 AP 성능이 좋아지는 지를 확인하는 결과입니다. 결론적으로는 L1 loss와 GIoU loss를 전부 사용했을 시에 가장 좋은 성능을 보입니다.
4.3 Analysis

DETR은 각각의 object query가 개별적으로 역할을 잘 수행하고 있는데요,
이는 위 그림을 시각화가 가능합니다.
그림에서 점들은 각각 bounding box의 center 값으로 보면 됩니다.
각각 서로 다른 different area와 box size를 가지게 되도록 학습이 됩니다.
즉, N개의 object query는 이미지가 주어졌을 때 각각 다른 영역과 박스 크기에 관심을 가졌다.
라고 볼 수 있습니다.

나아가 Train 데이터에 포함되어있지 않은 Unseen 데이터셋에 대해서도
일반화 성능이 상당히 높게 나왔습니다.
4.4 DETR for panoptic segmentation
픽셀 단위로 semantic segmentation하는 Task에 대해서도 확장이 가능합니다.
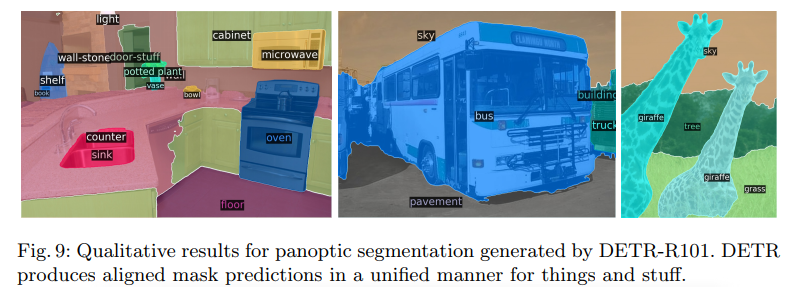
Semantic segmentation에서는 Stuff와 Things를 구별하는데,
전자의 경우 배경과 관련된 요소, 후자는 각각 객체에 대한 요소입니다.
이들을 개별적으로 각각 평가하기도 하고 종합적으로 평가하기도 합니다.
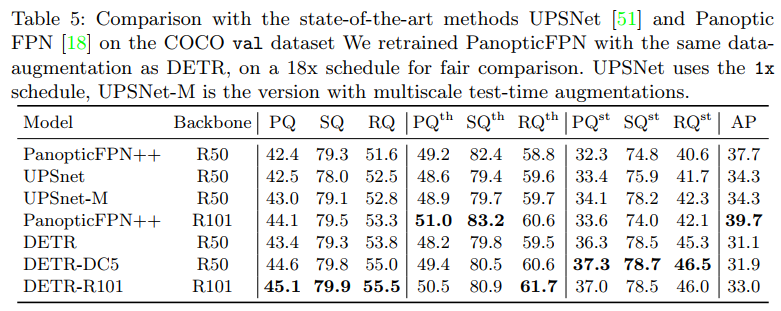
결과적으로 DETR은 SOTA 모델이었던 UPSNet과 비교했을 때 충분히 경쟁력있는 높은 성능을 보였습니다.
PQ, SQ, RQ는 각각 Panoptic Quality, Segmentation Quality, Recognition Quality로
Semantic Segmentation에서 자주 사용되는 Metric 입니다.
th가 붙으면 things만, st가 붙으면 stuff만 평가한다는 뜻입니다.
5. Conclusion
-
Partite matching (이분매칭) & Transformer encoder-decoder architecture 를 활용했다는 점이 가장 큰 특징
-
결과를 확인해보았을 때 큰 object에 대해서는 탐지 성능이 좋지만 작은 object에 대해서는 상대적으로 안 좋은 탐지 성능을 보임
함께 읽으면 좋을 논문
Unet 3+: A full-scale connected unet for medical image segmentation
(리뷰) Unet 3+: A full-scale connected unet for medical image segmentation
