논문 선택이유 및 글의 목적
요즘 GNN이 Recommendatin에서 안쓰이는 곳이 없는 것 같아서 관련 논문을 찾아보던 중에 알게되어 논문을 읽게 되었다. 특별히 Attention을 사용했다길래 어떤 내용을 담아냈을까 궁금했다.
결론부터 얘기하면, 내 생각에는 이 논문은 굉장히 짜임새(?) 있게 쓰여진 글이라고 생각한다.
저자가 어떤 고민을 갖고 이 글을 논리적으로 전개하려고 했는지 나름 엿볼 수 있어서 좋았다.
이 글의 목적은 공부한 내용을 기록하여 재사용이 가능하도록 하는 것과 동시에 많은 사람들에게 이 논문을 알리기 위함이다.
논문 링크
Abstract
1) Problem Definition
- 저자는 Recommendation에서 user-item interaction과 side information(e.g., profile, feature attribute)등이 함께 사용될 때, accurate,diverse,explainable이 가능하다고 설명한다.
- 기존 모델중 FM, NFM과 같은 모델들을 SL(Supervised Learning) 모델로 정의하는데, 이러한 모델들은 user-item interaction을 독립적인 관계로 이해하기 때문에, 여기서 collborative signal을 distill하는 것이 불충분하다고 설명한다.
- 이때 collborative signal이란 유저들의 collaborative behaviors로부터 온다. 예를 들면, user1-item1-attribute1의 관계만을 고려한다면 사실 attribute1은 다른 유저들과 아이템들에 대해서도 충분히 관계성을 가진다. 그러나 SL 모델들이 이를 '독립'으로 표현함으로써 이와 같은 관계성이 충분히 사용되지 못하는 것이다)
2) Solution
이 부분에 대한 설명은 논문에 있는 내용을 그대로 가져왔는데, 구체적인 설명은 이후에 설명하도록 하겠다.
- 제안: Collaborative Knowledge Graph
Knowledge Graph와 User-Item Graph를 함께 사용하는 hybrid한 그래프를 제안하였다.
- 구현:
1) it recursively propagtes the embeddings from a node's neighbors
2) and employs an attention mechanism
- 기여:
explicitly models the high-order connectivities in KG in and end-end fashion
1. Introduction
기존 방법론들의 문제점
1) Collaborative Filtering (CF)
Side information(e.g., profile, attribute) 등을 모델링하기가 어려움
2) Supervised Learning (SL)
Attribute-based Colloborative Signal이 충분히 전달되지 않음.
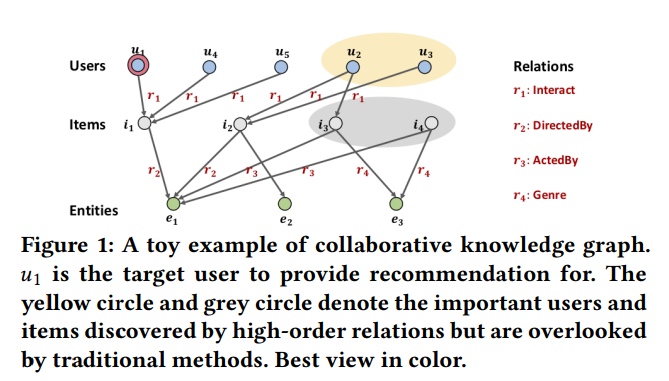
위 설명을 그림을 통해 제대로 이해해보자. 아래 그림은 user1-item1을 targeting하고 있고 이를 그래프로 시각화하였다.
기존 CF모델은 user-item graph상에서 i1을 소비하는 u1과 비슷한 다른 유저들(u4,u5)에 대해 관심이 있었다. 반면 SL모델은 knowledge graph상에서 i1과 같은 relation을 e1(attribute)에 대해 갖는 i2에 대해 관심이 있었다.
그러나 이와 같은 관계에서 other movie인 i2를 소비하는 (u2,u3)와 other common relation을 갖는 (i3,i4)에 대한 connection을 고려하지 않는다.
따라서 논문에서는 이러한 connection을 고려하고자 CKG(collaborative Knowlege Graph)를 제안하였고, 결과적으로 high order realtion(connectivity)를 fully exploit하게 되었다.
Challenges
논문에서 제안된 방법을 고안하기 위해서 두 가지 고려해야할 점이 있었다.
1) computation
한 노드에 대한 high-order relation이 dramatically하게 커질 수 있다는 지점이다.
(relation이 많게 되면 그만큼 계산량이 복잡해질 것이다)
2) unequally weight
high-order realtion에서 각 edge들이 불균형하게 weight를 갖다보니 이부분에 대해서 care가 요구되 었다. --> 결론적으로 attention mechanism으로 해결하였다.
기존 CKG 방법론들의 문제점
사실 CKG 방식은 이전에도 연구가 진행되어왔다. 저자들은 기존 연구들을 크게 두 가지로 분류하였다.
각 방식에 대한 설명과 문제점에 대해서 살펴보자.
1) Path-Based methods
high-order information에 대한 path를 extract하여 이를 feed-forwarding시키는 방식이다.
이를 위해서 path-selection 알고리즘을 사용하거나, meta-apth pattern을 이용한다고 한다.
그러나 이는 two-stage방식(path select -> 학습)은 path를 선택하는 것이 모델성능에 지대한 영향을 미치게 되고, path를 select하는 과정에서 domain 지식이 요구됌에 따라 labor-intensive하다는 문제가 있다.
2) Regularization-based methods
two-tasks를 수행하는데, recommendation과 KG completion이 그것이다. 이 방식의 문제점은 KG completion도 학습의 과정에서 만들어지다 보니, high-order relation을 모델에 explicit한 방식이 아니라, implicit하게 준다. (KG completion이 학습과정에서 아마 optimal할 것이라는 전제를 가지고 recommendation이 이뤄지니까 high-order relation을 제대로 capture한다고 보기 어렵다)
-> 따라서 논문에서 제시된 collaborative Knowledge Graph는
Efficient (path 방식의 labor-intensive하다는 문제점 극복) +
Explicit (Regularization 방식의 implicit하다는 문제점 극복) +
End-To-End (path 방식의 two-stage 문제점 극복) 형태로 고안되었다.
2. Task Formulation
Collaborative Knowledge Graph (CKG)
논문에서는 Collaborative Knowledge Graph를 user-item graph와 Knowledege graph의 hybrid한 구조로 제시한다. 두 개의 그래프를 Combine시킨 구조로 이해하면 되겠다. 구체적인 수식은 아래와 같다.
이때, G는 CKG를 의미하고, h와 t는 각각 head와 tail entity를 의미하고 r은 두개의 노드의 관계를 의미한다. E는 Entity(e.g., attribute)를, U는 User를 의미한다. R은 Item과 Entity간의 관계를 의미하고, Interact는 실제 Item과 User의 관계를 표현하고 있다.
Task
CKG과 주어졌을 때, 특정 유저와 특정 아이템이 얼마나 연관있을지에 대한 probability를 prediction하는 것이다. Implicit feedback이 주요 테스크라고 생각하면 되겠다.
3. Methodology
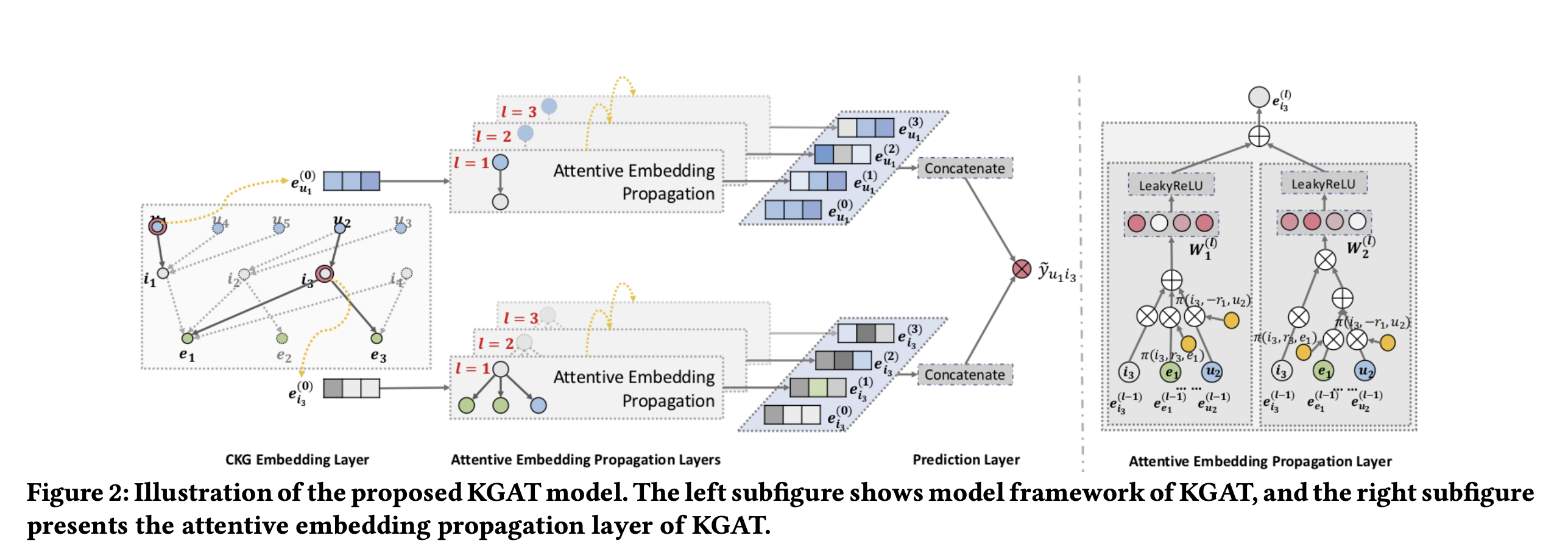
이 부분은 크게 세 가지 파트로 나누어진다.
1) embedding layer: 각 노드를 vectorization
2) attentive embedding propagation layers: node의 neighbor들로부터 embedding을 propagate 시키는 구조이다. 이때 각 neighbor들은 서로 다른 weight를 갖고 propagate를 진행하게 되는데, 이 부분이 attention mechanism으로 학습된다.
3) prediction layer: 모든 layers로부터 얻은 embedding들을 aggregate시키고, 이후 predicted matching score를 산출한다.
3.1 Embedding layer
이 부분에서 중요한 부분은 Knowledge Graph상에 존재하는 모든 Entity와 Relation을 어떻게 embedding시킬 것인지에 대한 부분이다.
논문에서는 TransR [15' AAAI]에서 나오는 방식을 이용해서 plausibility score를 사용했다고 한다.
이때 TransR에서 이라는 translation principle을 따른다고 한다. 그러므로 g(h,r,t)값이 작을수록 triplet이 실제 존재할 가능성이 높다고 판단한다.
이때 본 논문은 pairwise ranking loss를 이용해서 (아마도 BPR Loss와 비슷한 형태로 보인다) 아래와 같은 Loss를 학습에 포함시켰다고 설명하고 있다.
이때 g(h,r,t')은 실제 그래프상에 존재하지 않는 triplet이라고 생각하면 되고, g(h,r,t)는 실제 존재하는 것으로 생각하면 된다.
3.2 Attentive Embedding Propagation Layers
해당 부분은 크게 네 가지 파트로 나누어지는데, Information Propagation,Knowledge-aware Attention, Information aggregation, High-order Propagation이 그것이다.
1) Information Propagation
해당 파트에서 제일 중요한 키워드는 "ego-network"라는 것인데, 특정 head의 neighbor로부터 propagate되는 모든 embedding을 표현한 수식이다.
2) Knowledge-aware Attention
1번식을 보면 라는 weight값이 tail의 embedding과 결합되어서 propagate되는 것을 확인할 수 있다. 이때 해당 weight값은 attention mechanism을 통해서 학습이 가능하다.
이때 논문에서는 nonlinear activation function을 사용하기 위해서 tanh을 사용하였고, 이라는 learnable한 parameter를 이용해서 inner product방식으로 attention weight를 부여하였는데, 이 부분을 Future work로 두었다.
최종적으로 attention weight는 하나의 고정된 head와 이것과 연관된 neighbor tail의 모든 weight를 softmax의 형태로 표현하여 구하게 된다.
3) Information aggregation
이 부분에서는 최종적으로 entitiy representation 와 그것의 ego network인 를 어떻게 aggregation할 것인지에 대해서 다룬다. 결론부터 얘기하면 본 논문에서는 Bi-Interaction Aggregator가 다른 방법론(e.g., GCN(만 이용) or GraphSage(을 concat함)방식보다 더 좋은 성능을 가졌다고 주장한다.
이때, 는 elementwise-product를 의미한다. 결과적으로 Bi-interaction에서 두 embedding의 sum과 elementwise-product라는 두 가지 관계를 모두 이용이 가능하다.
이를 통해서 결과적으로 얻는 값은 이라고 할 수 있다.
4) High-order Propagation
이 부분에서는 propagation layer를 여러개의 stack으로 쌓는 것을 의미한다.
결과적으로 이 부분은 3)에서 aggregation을 통해 얻은 결과값에 대한 generalize라고 할 수 있다.
3.3 Model Prediction
최종적인 output을 어떻게 도출할 것인가에 대한 부분이다. 이때 우리는 여러개의 embedding layer로부터 얻은 embedding들을 memorize시킨 뒤, 이들을 concat하는 방식으로 수행할 수 있다. 이렇게 하는 이유는 더 풍부한 information을 가질 수 있고, 또한 layer의 개수(L)를 조절함으로써 strength of propagtaion을 control이 가능하다.
이후 두 개의 embedding을 inner-product하면 최종적으로 prediction score를 도출할 수 있다.
3.4 Optimization
optimization부분이다. 사실 이 부분에서는 다뤄지는 주요 내용은 주어진 모델의 object function(loss function)을 어떻게 define했는지가 핵심이라고 할 수 있다. 결론부터 얘기하면 KGAT에서는 multi-task형태로 Loss를 만들었다.
이때 는 3.1 embedding layer에서 도출된 Loss를 의미하고, 는 BPR Loss (pairwise형태로 제시되는 bayes rule기반의 loss)를 기반으로 아래와 같이 주어진다.
참고로 논문에서는 L(KG)를 embedding loss, L(CF)를 prediction loss라고 표현한다.
4 Experiments
실험파트에서는 크게 세가지 질문을 갖고 실험을 진행했다. (이부분에서 그냥 실험을 진행한 것이 아니라, 특정목적을 갖고 실험을 진행하여 결론을 도출했다는 지점이 굉장히 흥미로웠다)
이 파트에서는 해당 질문에 대한 내용만 소개하고, 구체적인 부분은 독자 여러분께 맡기도록 하겠다.
RQ1: KGAT모델의 기존 sota knowledge-aware recommendation에 비교했을 때 성능
RQ2: KGAT의 각 요소(embedding, attention mechanism, aggregator)등이 미치는 영향
RQ3: KGAT이 reasonable explanation을 주는가?
5 Conclusion and Future Work
KGAT이 가지는 의미는 다음과 같다. end-end, explicit, efficient한 collective knowlede graph를 만들었다는 것이다. 또한 기존 user-item graph와 knowledge graph를 combine함으로써 high-order connectivity를 더 잘 capture할 수 있었고, 이를 통해 collaborative signal이 잘 전달될 수 있도록 하였다.
또한 attention mechanism을 사용함으로써 추천에서 reasonable한 explanation을 줄 수 있었다.
