논문정보
- 학회: WWW'18
- 저자: Hongwei Wang et al
- 저자소속: Shanghai Jiao Tong University & Microsoft Research Asia(Bejing)
- 링크: https://dl.acm.org/doi/pdf/10.1145/3178876.3186175
1. Introduction
Main task
특정 News에 대한 User의 Click-through Rate (CTR) Prediction
Motivation
News 추천은 기본적으로 News의 수가 User보다 훨씬 많이 존재한다고 가정한다. 따라서 이를 위해서 유저의 흥미를 기반으로 적절한 뉴스를 추천해주는 것이 필요하다.
Problem Definition
논문에서 저자들은 News Recommendation이 가지는 Challenge에 대해서 설명하는데, 크게 세 가지로 표현된다.
1) Time-sensitive
2) Topic-sensitvie
3) news language is highly condensed and comprised of a large amount of knowledge entities and common sense
이와 같은 문제를 해결하기 위해서 본 논문에서는 Knowledge-aware Convolutional Neural Network (KCNN) 및 attention module을 제안한다. 결론부터 얘기하면, KCNN을 통해서 뉴스 title을 구성하는 word(semantic) represenation + knowledge graph를 이용한 entity representation + 각 entity의 이웃을 이용한 context represenation을 모두 incorporate 시킴으로써 주어진 news를 fine-grained한 embedding으로 만들 수 있었다. (이는 3번째 문제를 해결한 것으로 보인다)
더불어서 attention을 이용해서 candidate news와 user가 이전에 clicked한 news들 간의 관계가 고려되면서 user의 interst가 반영되어 CTR을 더 잘 예측하게 된다. (이는 1,2번째 문제를 다룬것으로 보인다)
2. Key Idea
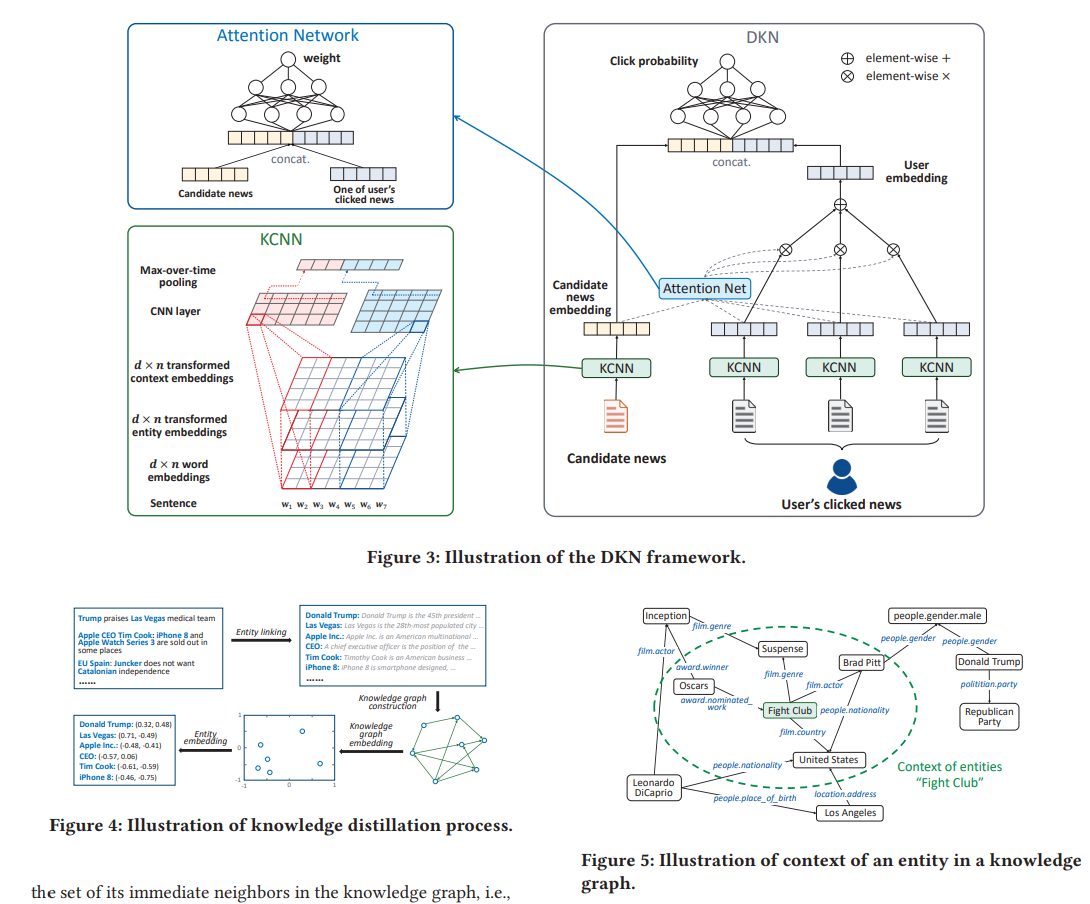
이 그림만 잘 이해하면, 이 논문의 모든 것을 이해한거나 다름없다.
Figure3의 오른쪽 그림을 밑에서부터 위쪽 방향으로 전반적인 Framework가 진행된다.
먼저 각 아이템(News)들이 KCNN을 통과함으로써 하나의 representation(embedding)으로 표현된다.
KCNN을 위해서는 먼저 Figure4에 있는 Knowledge Distillation Process가 수행되어야 한다. (Note: 여기서 언급된 Knowledge Distillation은 Knowledge Graph의 지식을 가지고 어떻게 item의 embedding을 잘 표현할 것인지를 다룬다. 우리가 흔히 아는 Teacher model의 지식을 Student에게 전달하는 Concept과는 다르다... 사실 나도 KD의 관점에서 해당 논문을 읽을려고 한건데 결론적으로 낚인 것 같다)
Figure4를 이해해보자.
- 먼저 주어진 News의 title들이 기존에 존재하는 Entity와 연결이 된다. (예를 들면, Trump는 Donald Trump, Las는 Las Vegas, Vegas는 Las Vegas 이런 식으로..)
- 주어진 Entity들을 통해 KG를 만든다.
- KG를 잘 학습시킨다. (Traslation 기반의 Model을 이용하면 됌)
- 각 Entity의 embedding을 얻는다 (예를 들면, Donald Trumpy에 대한 embedding으로 (0.32, 0.48)라는 vector를 얻었다)
이렇게 하면 우리는 특정 News의 title을 구성하는 word들을 (아마도 유의미한 word만을 이용) Entity로 변환하여 이에 해당하는 embedding을 얻을 수 있게 된다. (Trumpy -> Donal Trumpy (0.32, 0.48))
그런데 이렇게 얻은 entity와 주어진 words들을 단순히 concat해서 해당 item에 대한 embedding을 표현하게 되면 문제가 발생한다. ( 1*이 부분은 concat연산이 주어진 word에 mapping되는 entity에 대해서 connection이 깨지게 되고, 2* word와 entity를 표현하는 optimal한 embedding size가 다른데 concat을 하면 이를 강제로 맞춰져야하는 문제가 생기고, 3* 서로가 다른 방식으로 학습이 되었기 때문에 meaning이 다르다)
따라서 저자는 이를 해결하기 위해서 Multi-channel이라는 것을 고려하게 되었고 그것이 Figure3에서 KCNN 방식을 확대해서 보여준 그림이다. 이미지에서 RGB 3개의 channel을 통해서 이미지가 표현되는 것처럼 주어진 item을 이와 같은 방식으로 표현해서 Convolution을 통과해서 결과적으로 high quality의 embedding을 만들겠다는 것이다!
여기서 entity embedding은 위에서 설명한 Trumpy -> Donald Trumpy가 되어서 표현한 embedding을 의미하고, context embedding은 Donald Trumpy와 관계를 갖는 이웃 node들을 의미한다. (예를 들면, Donald Trumpy는 남성이자 정치인이자 미국과 같은 여러 node들과 관계를 맺고 있으므로 이러한 이웃노드들의 embedding에 average를 취해서 context embedding을 정의하였다)
그리고 이렇게 만들어진 3개의 channel을 CNN에 통과시킴으로써 Feature map이 나오면 이를 max-pooling을 통해서 represenation을 얻는다. 이때 여러 개의 output channel을 갖는 CNN layer를 만들 수 있을 것이다. (CNN을 여러 층으로 쌓으면 성능에 어떤 영향을 줄까?)
이렇게 하면 KCNN에 대한 설명이 모두 끝이난다. KCNN은 사실 이 논문의 가장 핵심적인 아이디어라고 볼 수 있는데, 이 부분에서 가장 Novelty한 부분은 주어진 item을 마치 이미지의 형태로 embedding을 만들어서 이미지 Task에서 수행하듯이 CNN을 통과시켜서 나온 output을 추천 input으로 사용하는 방식이다.
그리고 나서 candidate news와 user's clicked news간의 attention weight를 구해서 (softmax이용한다) useer embedding을 만들어서 이를 Candidate news와 concat해서 FFN을 통과시키면 결과적으로 Click Probability (0~1)값을 구하게 된다.
3. Pros and Cons
Pros
1) 주어진 item을 이미지의 형태로 표현해서 CNN을 통과한 output으로 embedding을 만들었다.
2) Mult-channel을 이용해서 Word(semantic), Entity, Context와 같은 정보들을 모두 이용했다. (그래서 이 논문은 CF가 아닌 Contents-based라고 주장한다)
Cons
1) 시간에 대한 고려, history의 순서간 고려가 있는가? (예를 들면, 유저가 클릭한 아이템중에 시간순으로 봤을 때 가장 최근에 있는 item에 대한 weight를 더 줘야하는 게 아닌가..? 유저의 취향이 시간에 따라서 바뀌었을 수도 있는데.. 아무튼 이 논문에서 처음 문제로 제기한 time-sensitive issue가 잘 다뤄졌다고 보기는 어려운 것 같다)
2) 뉴스의 title만을 고려하는 방식이 과연 뉴스가 가지는 contents들이 온전히 반영되는가? (뉴스의 title이 주어진 기사의 핵심이라고 할 수 있지만, 사실 이게 진짜 Contents based가 되려면 기사에 담긴 글을 바탕으로 embedding이 만들어져야 되지 않을까 생각이 든다)
3) 기존의 KG를 기반으로 Entity embedding이 만들어지니까 이게 너무 제한된 형태로 representation을 만드는게 아닌가 (물론 transform을 시켰다고는 하지만..), 그리고 기존 Entity에 matching이 안되면 Entity는 물론 Context를 모두 zero로 만들었다고 하는데.. 이건 너무 risky한 방식이지 않을까 싶다.
4) 여기서 얘기하는 Knowledge Distillation Process를 거치는데 시간이 엄청 오래 걸릴 것 같다고 생각이 들었다. (주어진 뉴스 타이틀을 유의미한 단어로 구분한 뒤, 단어들을 각각 Entity로 매칭시킨후, KG 만들고, KG embedding 시키고, entity embedding을 구하는 방식이 생각보다 복잡하고 시간도 오래걸릴 것 같다)
4. Conclusion
KG를 이용해서 추천에 사용하는 게 이 시기에는 그렇게까지 대두가 되지는 않았었나 보다. 사실 회사 입장에서는 가지고 있는 모든 데이터를 활용해서 personalized를 시키면 좋으니까, KG분야가 industry관점에서는 더 활발하게 연구가 되는 것 같다.
그렇지만 우리같은 Research 분야에서는 Knowledge Graph를 갖출만큼 잘 정제된 데이터를 갖기가 어렵다. 또 아무래도 user나 item이 갖는 feature 정보를 이용하니까, 이 부분에 대한 전처리및 학습데이터 구성하는 것만으로도 상당한 시간이 걸릴 것 같다. 이로 인해 결과를 빨리 뽑아내기가 어렵다보니 Research 분야에서 KG를 다루기가 상당히 까다로운 것 같다.
그래도 이와 같은 논문을 통해 KG에 대한 더 넓은 식견을 가질 수 있었고, 특히 주어진 Item을 이미지와 같은 형태로 CNN을 통해 특징을 추출하여 item의 embedding으로 사용하는 방식이 흥미로웠다.
