논문정리
- 학회: ICDM'19
- 저자: Jae-woong Lee et al.,
- 링크: https://arxiv.org/pdf/1911.05276.pdf
1. Motiviation
기존의 Knowledge Distillation (KD) 모델이 Recommendation에서 다뤄야 하는 문제점으로 아래와 같은 것들이 있다.
1) sparsity of postive feedback (user-item간의 interaction이 기본적으로 굉장히 sparse함)
2) ambiguty of missing feedback (missing feedback을 negative로 볼 것인지 or not-aware로 볼 것인지)
3) ranking problem associated with the top-N recommendation (상위 N개에만 집중하는 문제)
기존 SOTA 모델인 RD [KDD'18] 논문이 teacher model로부터 얻은 상위 N개 item을 hard label(1)로 표현하여, 이러한 item들이 Student 모델에서 얼마 interaction이 있는지에 대해서 Negative Log Likelihood를 이용해서 문제를 해결했었다. 그러나, 이는 hard label을 사용함으로써 soft target(logit일수도 있고 확률 값일 수도 있고)값들은 전혀 사용이 안되었다. 그러다 보니 item들간의 correlation이 제대로 catch가 안된다는 한계점을 지닌다.
그래서 이 논문은 RD방식의 문제점을 개선하고자 soft target을 적극적으로 활용한다.
2. Method
일단 이 논문에서 다루고자 하는 Loss는 아래와 같이 정의되어 Student를 학습시킨다.
(Teacher는 이미 offline상황에서 pretrain되었다고 가정한다)
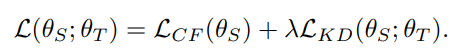
이 논문에서 제안하는 Method는 크게 세가지가 있다.
1) Collaborative Filtering Loss: Postive item만을 사용해서 Negative log likelihood Loss를 구성하였다.

2) Knowledge Distillation Loss: rank-aware sampling을 이용해서 Negative item 중에서 가장 score가 높은 top-N개의 item을 뽑아서 이들에 대한 Negative log likelihood값을 뽑아 내는 것이다.
(이때 와 는 다르게 표현된다)
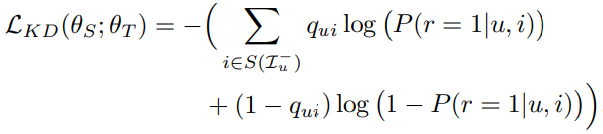
알고리즘을 보면 다음과 같다. 먼저 Teacher model에서 unlabelded items들에 대한 rank를 모두 매긴다. 그러면 각 item이 뽑힐 확률을 정할 수 있게 된다. (rank가 작다는 말은, 높은 순위를 가지는 것을 의미하므로 더 높은 확률을 갖는다. 이는 formula 8,9,10을 참고하길 바란다)
이후 rank가 높은 item을 targeting해서 하나씩 iterative하게 돌리면서 (3번 line)
복원추출로 뽑힌 item간의 rank를 비교해서 target item의 rank가 더 작으면 (5번 line)
6번에서 sample의 element로 target item을 추가한다.
이렇게 하게 되면 결과적으로 우리는 rank가 높은 item들로 K개의 item을 구성할 수 있다.
(이때 주의할 점은 반드시 상위 K개가 차례대로 구성되는 것이 아니라, 어느 정도 순서가 고려된 sample들로 구성이 된다. 예를 들어 K가 5이면 1,2,3,4,5번 아이템이 순서대로 Set을 구성할 수도 있지만, 1,2,3,5,7과 같이 순서가 고려된 set도 충분히 가능하다)

그리고 이들에 대해서 Temperature Scaling을 적용해서 를 만드는데, 그 이유는 student의 output으로 나오는 distribution이 굉장히 sharp할 수 있기때문에 이를 smooth시켜줘야 한다고 주장한다 (그런가?). 이때 T1으로 scaling을 시켜주고, T2로 shift를 시켜준다고 표현한다. (T1이 기울기이고, T2가 절편이니까?)
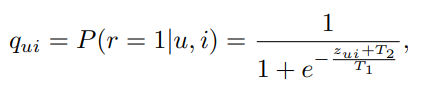
3) Interactive Training Tactics
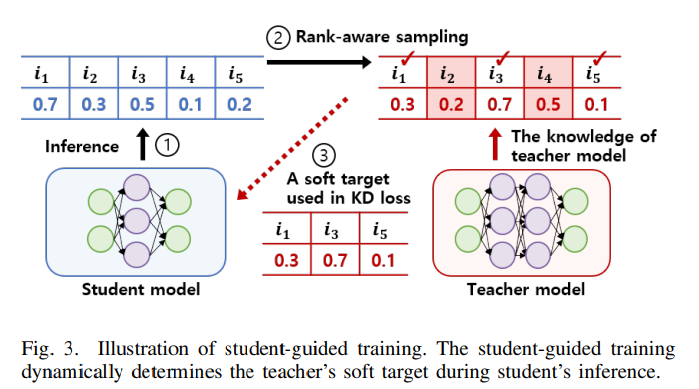
이 논문의 세번째 method로 teacher-guided training방식과 studnet-guided training방식을 구분해서 설명했다는 것이다. 먼저 2번에서 보여준 알고리즘이 teacher-guided training방식인데, teacher에서 ranking을 매긴 item들을 기반으로 sample을 구성하기 때문이다. 이는 수동적인 방식이지만 studnet model에 intervention없이 온전히 teacher model에서 sampling이 가능하다.
그러나 student-guided 모델에서는 student가 계속해서 teacher에게 물어보는 방식으로 학습이 진행된다. 이게 되게 신기한 지점은 student 모델을 통해서 rank-aware sampling을 진행해서 나온 일부 item이 존재하면(i1, i3, i5) 이를 teacher에게 물어봐서, teacher의 logit값으로 studnet 모델을 학습하겠다는 것이다. (이게 과연 효과가 좋을까?)
이 논문에서는 teacher-guided training방식과 student-guided 방식을 따로 구분지어서 성능을 비교하였다.
3. Pros and Cons
이 논문이 가지는 Novelty한 부분은 아무래도
1) rank-aware sampling을 진행했다는 지점
2) student-guided 방식으로 teacher의 logit을 사용하려고 했다는 부분
3) 기존 RD에서 hard label을 사용했던 부분에서 Original KD와 같이 soft target을 이용해서 item들간의 corrleation을 잡으려고 했다는 지점
이 논문이 가지는 Cons 부분은
1) 과연 Student-guided방식이 효과가 얼마나 있는건가..? Teacher guided와 Studnet guided를 multi-task로 돌리면 어떨지 궁금하다.
2) Temperature Scaling을 사용한 방식의 효과에 대한 report가 없는 것 같다.
3) missing feedback에 대한 ambigity를 지적했는데, 이 부분이 KD Loss에서 각 item이 postive일수도 있고 혹은 Negative일수도 있다는 고려하에 Loss가 구성되었는데 이게 얼마나 효과가 있는지 궁금하다.
4) CF loss에서 postive item만을 이용하는데, 기본적으로 postive item들이 sparse하다고 그랬는데, sparse한 item들만 사용하는게 맞는가 싶다. (아마 이를 극복하기 위해서 missing feedback을 KD Loss에서 사용한 것 같긴하다)
4. Conclusion
그래도 KD의 전반적인 내용을 이해할 수 있었던 시간이었다.
그리고 무엇보다 적극적으로 수업에서 선생님과 interaction을 하는 Student Model을 딥러닝에 접목시켰다는 것이 굉장히 흥미로웠던 것 같다.. 연구에 대한 인사이트는 삶에도 내제하는 것 같기도 하다...
