-
블록 버퍼링
- 사용자입장에서는 동시에 수행 되지만 실제로는 번갈아 수행되는경우가 있고, 실제로도 동시에 실행되는 경우가 있다.
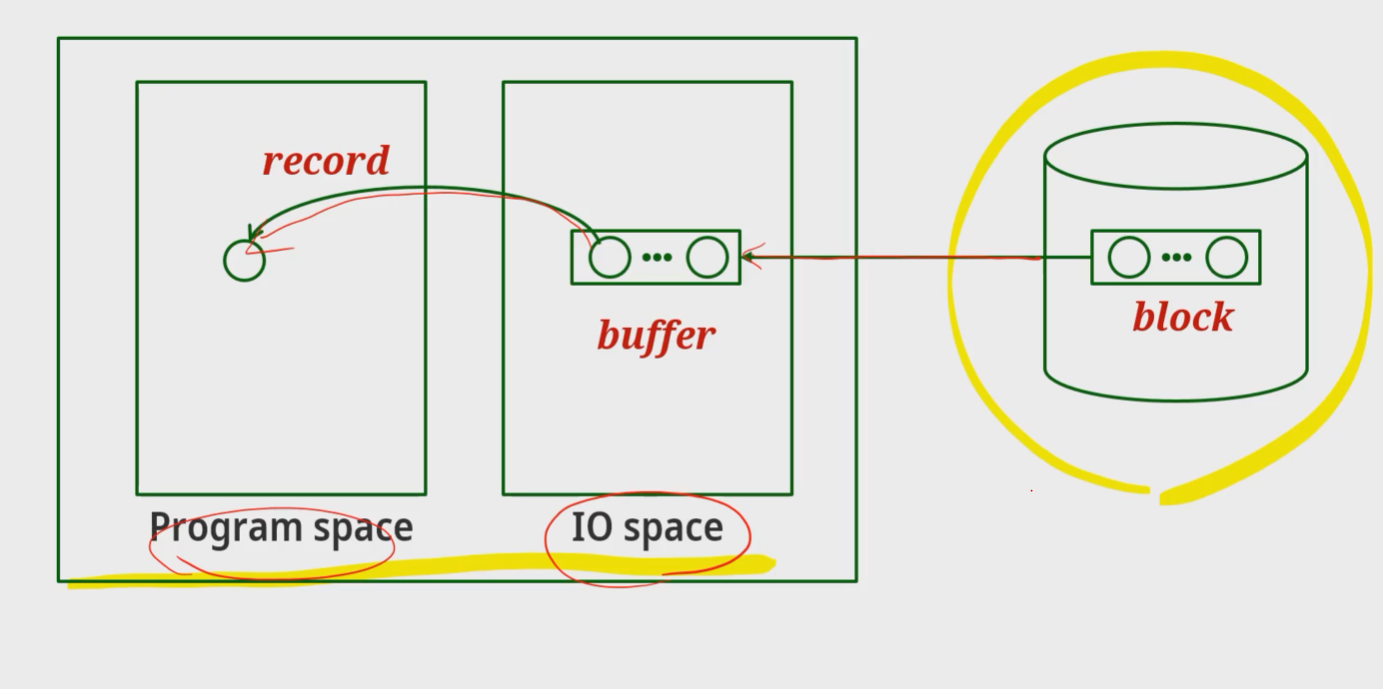
- 디스크속에 있는 버퍼를 읽어 들이고, cpu는 버퍼를 하나씩 처리하는 과정으로 진행한다.
- 버퍼가 하나있는것을 single buffering, 두개있는것을 double buffering이라고 한다.
- 더블 버퍼링을 쓰면 연속된 입출력을 가능하게 한다. waiting time을 줄인다.
- 사용자입장에서는 동시에 수행 되지만 실제로는 번갈아 수행되는경우가 있고, 실제로도 동시에 실행되는 경우가 있다.
-
버퍼 매니지먼트
- 버퍼가 쓸수있는공간 : buffer pool
- 가능한 한 최고의 효율을 내도록 버퍼의 활동을 조율한다.
- pin count : 현재 해당되는 버퍼를 몇개의 프로세스가 쓰고있는지 카운트 한다.
- dirty bit : 비트가 업데이트가 되었는지 확인, 업데이트가 되었다면 rewrite로 갱신해줘야 한다.
-
버퍼 교체 전략
- LRU
- Clock policy
- FIFO
- MRU
-
레코트 & 레코드 타입
- 디스크 속에 저장되는 기법을 고려해야함
- 고정 길이 레코드와 가변길이 레코드가 존재한다.
- 가변길이에서는 setvalue & 다른 타입이 저장될 수 있다.
- 가변길이는 Separator Characters 로 레코드가 끝난 것을 표시해준다.
-
레코드 Blocking, 신장, 비신장 방법
- 블록 : 데이터 전송의 단위
- 비신장은 낭비되는 부분의 단점이 생기고, 신장은 두개의 블록에 접근해야하는 어려움이 있다.
-
파일의 블록을 할당하는 방법
- 연속 할당 방법 : 순서대로 일 경우 매우 효율적
- 연결 할당 방법 : 블록들을 연결리스트로 연결하는것, 읽는 속도는 느리지만 확장성이 뛰어나다.
- 두개방법을 합친 방법 : 블록의 cluster들 사이에 연결리스트를 두는 것
- 인덱스 할당 : 인덱스 블록이 하나의 블록의 포인터를 가리키는 것
-
파일 헤더
- 파일헤더 or 디스크립터 : 파일의 레코드에 접근할 수 있는 파일에 대한 정보를 갖고 있는 것
-
파일의 연산
- 기본적으로 검색연산과 갱신연산이 존재
- 갱신은 값을 지우거나, 수정하는 것
- 고치고자 하는 값의 검색이나 필터링이 사전에 진행되어야함
- Open,Close
- Record -at-a-time : 초기화, 찾기, 읽기등 하나의 레코드를 한번에 실행하는것
- Set-at-a-time : 전제검색, 전체정렬등 작업을 실행하는것
- Scan : 스트림처럼 연속적인 작업을 처리하는것
-
파일 구성 방법
- 파일속에 있는 레코드, 블록,접근구조로 파일을 조직 하는것
- 실제 저장장치에 위치시키는, 서로 연결시키는 것을 포함함
- Access method : 파일 에 적용될 수 있는 연산의 그룹
-
Heap or Pile File
- 레코드가 삽입된 순서대로 저장되는 방법
- 레코드를 단순 수집하는 방법에 많이 사용됨
- 수정은 해당 메모리를 가져와서 삭제하고 다시 rewrite를 하는 방법으로 진행된다. 이후 수정된 레코드를 마지막 블록에 추가한다.
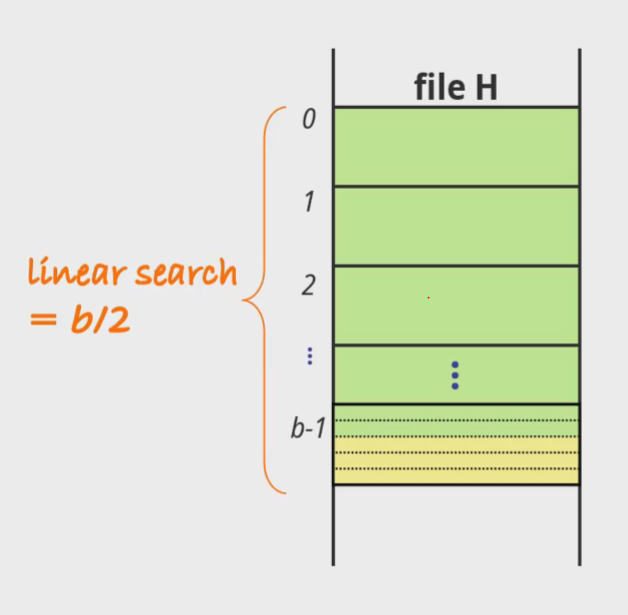
- 선형 검색은 평균 b/2횟수가 소요된다.
- 삭제는 삭제할 레코드 위치를 찾고 그 부분을 지운 후 rewrite를 한다. 삭제한 곳은 deletion marker가 붙고 다시 쓰이지 않아 메모리가 낭비된다.
- 가변길이의 경우도 삭제한 후 reinsert하는 식으로 진행한다.
- heapfile은 sorting이 되어 있기 때문에 매우 긴 읽는 속도를 방지하기 위해 외부적으로 sorting을 하는 tempfile을 만들어 읽는 경우가 비용이 더 적게 소요된다.
-
외부정렬
- 내부 정렬은 메인메모리에 모두 데이터를 올려놓고 정렬하는것
- 외부정렬은 파일을 이용해서 메인메모리 밖에서 정렬을 진행하는것이다.
- 파일에서 메인메모리의 데이터를 정렬하여 run메모리에 저장한다(sorted subfile) 차례대로 생성된 run을 merge sort를 통해 정렬이 이루어진다.
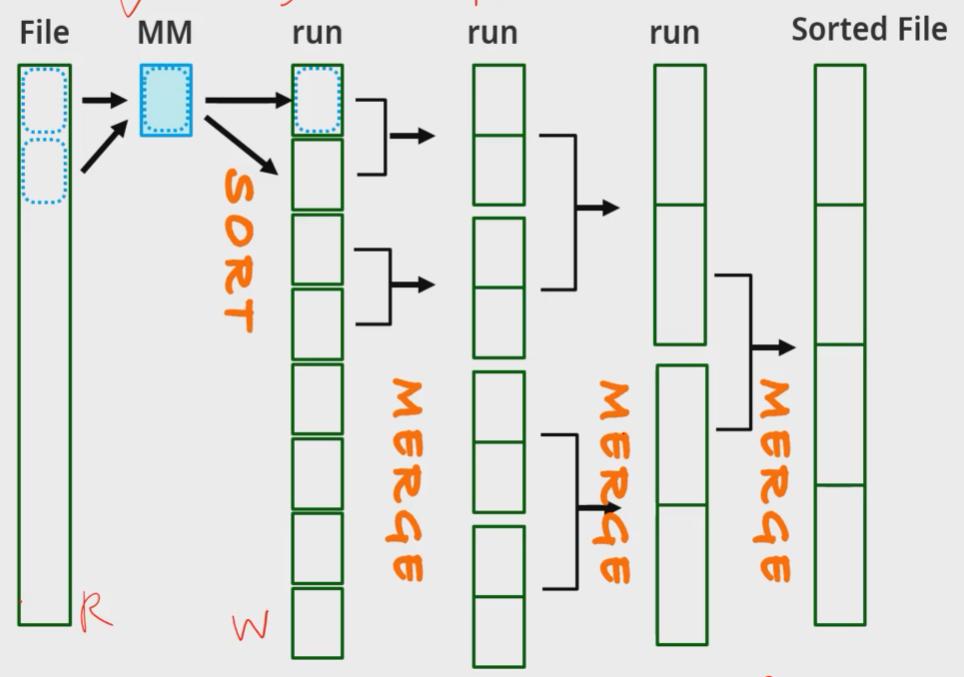
- 레코드가 100개면 100번을 읽어야 하기 때문에, 공간, 시간적인 부담이 크다.
-
상대, 직접 파일
- 한블럭 당 몇개의 레코드가 들어가는 지 알기때문에 특정 위치의 블록이 몇번째 블록인지 알 수 있다.(/bfr)
-
순차파일
- 특정 필드의 값에 따라 정렬이 된 파일을 말한다.
- 레코드를 차례대로 읽는 데 매우 편리하다.
-
이진 탐색
- log(n)이 소요, 선형탐색보다 효율적
- 파일의 효율적 탐색에 이용된다.
-
순차파일의 검색
- 특정 레코드를 찾으려면 주변을 탐색하면 효율적이다.
- 랜덤액세스나 정렬기준이 다른것을 탐색할때는 다른 정렬 기준을 갖는 temp file을 이용해 정렬하는것도 효율적이다.
-
순차탐색 삽입, 삭제
- 나머지 뒤는 전부 밀리거나 당기기 때문에 매우 비효율적이다.
- 중간 빈 곳에 작업을 하거나
- 별도의 새로운 공간에 임시로 보관을 하고 이후에 재구성을 하는 방법을 고려한다.
- delete의 경우도 marker를 표시하고 이후에 재구성하는 방법도 고려한다.
- 삽입, 삭제를 고려해 예비공간을 처음부터 고려하여 구성한다.
-
트랜잭션 파일의 사용
-
수정된 내용을 임시로 저장하는 일시적인 파일을 사용한다.
-
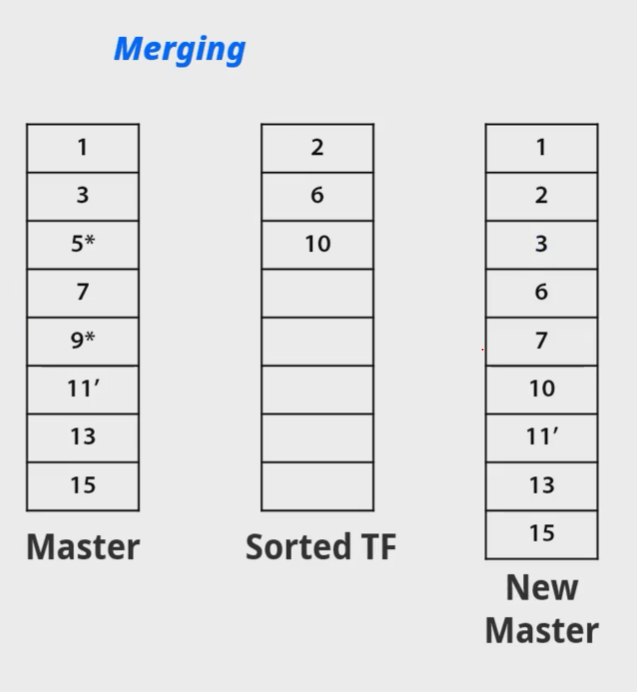
main,master의 수정 내용을 트랜잭션 파일에 보관했다가 이후에 합치는 과정을 진행한다.
-
탐색의 경우 main파일을 찾고 없다면 트랜잭션 파일을 통해 탐색이 이루어진다.
-
주기적으로 트랜잭션 파일과 메인 파일을 merge를 해줘야한다.
-
두개의 파일은 자연스럽게 백업파일의 역할을 하게 된다.
-

백엔드 & 전공 공부