Word2Vec Embedding과 RAG의 관계: LLM 시대의 핵심 기술

Word2Vec Embedding과 RAG의 관계: LLM 시대의 핵심 기술
"Embedding은 단어를 벡터로 바꾸는 것 이상의 의미를 지닙니다.
그것은 LLM과 현실을 연결하는 다리입니다."
1. 왜 임베딩이 중요한가?
LLM이나 RAG에 대해 공부하다 보면, 자연스럽게 Embedding이라는 단어를 자주 접하게 됩니다. 특히 Retrieval-Augmented Generation(RAG) 구조를 이해하려면, 임베딩의 개념과 원리에 대한 이해가 필수입니다.
그렇다면, 임베딩이란 무엇일까요?
간단히 말해, 기계가 인간의 언어를 이해할 수 있도록 단어, 문장 등을 수치(벡터)로 표현하는 방법입니다.
️ 왜 벡터화가 필요한가요?
컴퓨터는 문자 대신 숫자를 이해합니다. 하지만 단순히 임의의 숫자를 할당하는 방식은 단어 간의 의미적 관계를 담지 못합니다.
예를 들어:
| 단어 | 단순 숫자 표현 |
|---|---|
| 좋다 | 1 |
| 멋지다 | 2 |
| 나쁘다 | 3 |
이런 표현은 좋다와 멋지다가 유사한 감정을 전달하는 단어라는 점을 반영하지 못합니다.
2. Embedding의 개념
Embedding은 각 단어를 고차원 의미 공간의 벡터로 표현하여, 의미가 비슷한 단어끼리는 서로 가깝게 위치하도록 학습된 표현 방식입니다.
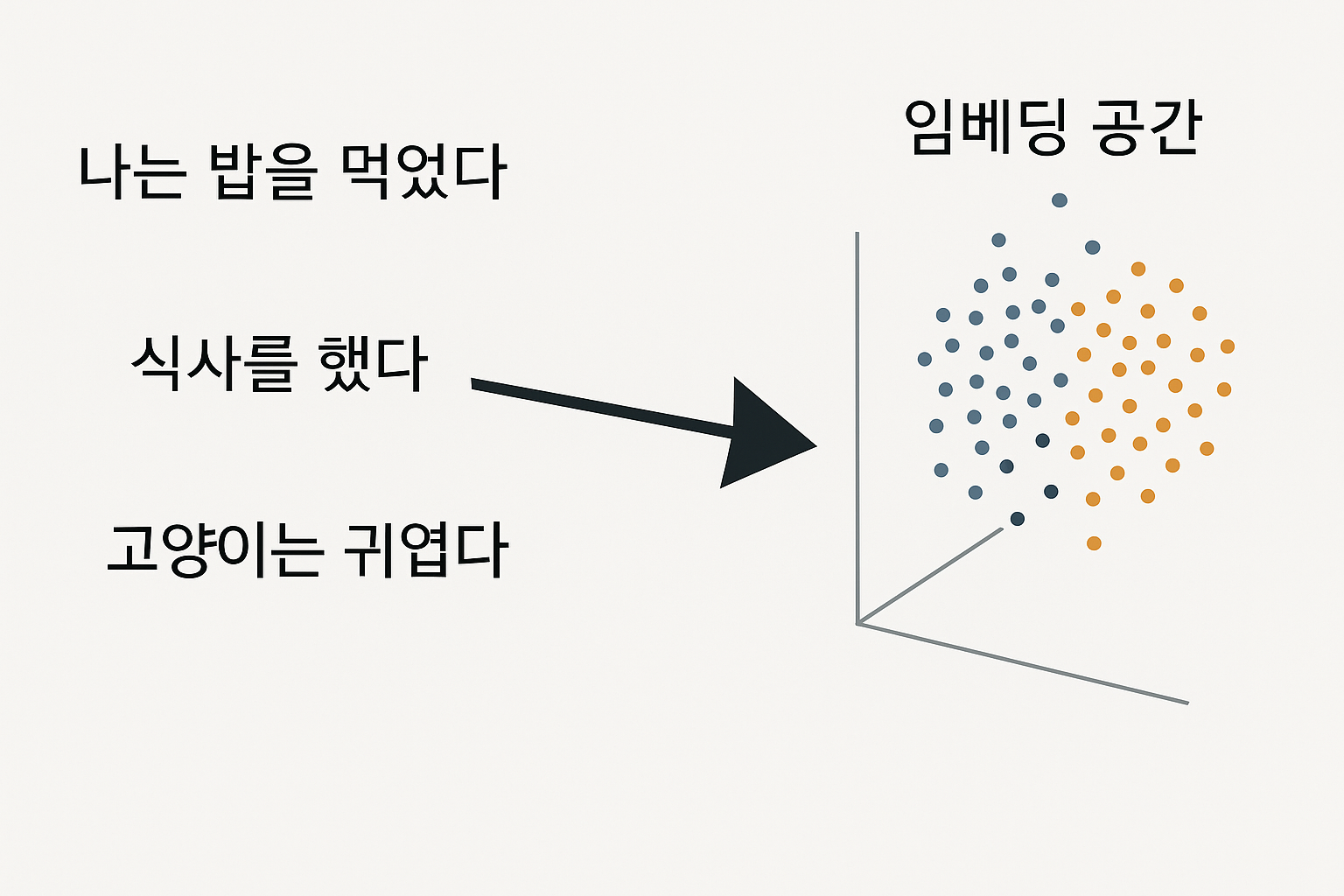
3. 과거 표현 방식: One-Hot Encoding
초기 NLP에서는 다음과 같은 방식으로 단어를 표현했습니다:
| 단어 | One-hot 벡터 |
|---|---|
| 고양이 | [1, 0, 0, 0] |
| 강아지 | [0, 1, 0, 0] |
하지만 이런 방식에는 치명적인 한계가 있습니다:
- 단어 간 의미적 유사성 없음
- 차원이 너무 큼 (희소 벡터)
- 계산 비효율
4. Word2Vec: 의미를 반영한 벡터화
Google이 2013년 발표한 Word2Vec은 이러한 문제를 해결한 기념비적인 임베딩 모델입니다.
| 단어 | Word2Vec 벡터 예시 |
|---|---|
| 고양이 | [0.72, -0.14, ..., 0.55] |
| 강아지 | [0.74, -0.13, ..., 0.53] |
예시 연산
왕 - 남자 + 여자 ≈ 여왕
서울 - 한국 + 일본 ≈ 도쿄
즉, 단어 간 의미적 연산도 가능해집니다.
5. Word2Vec 학습 방식
Word2Vec은 다음 두 가지 방식으로 학습됩니다:
| 방식 | 설명 |
|---|---|
| CBOW | 주변 단어로 중심 단어 예측 |
| Skip-Gram | 중심 단어로 주변 단어 예측 |
학습은 다음과 같이 진행됩니다:
- 문장 토크나이징
- 숫자 벡터 변환 (임베딩)
- 신경망을 통해 예측 (softmax)
- 역전파 (loss 계산)
- 최종 벡터 저장
6. 효율적인 학습: Negative Sampling
Word2Vec은 모든 단어에 대해 softmax를 계산하기엔 너무 느립니다.
그래서 일부 정답과 일부 오답만 사용해 빠르게 학습하는 방식인 Negative Sampling을 사용합니다.
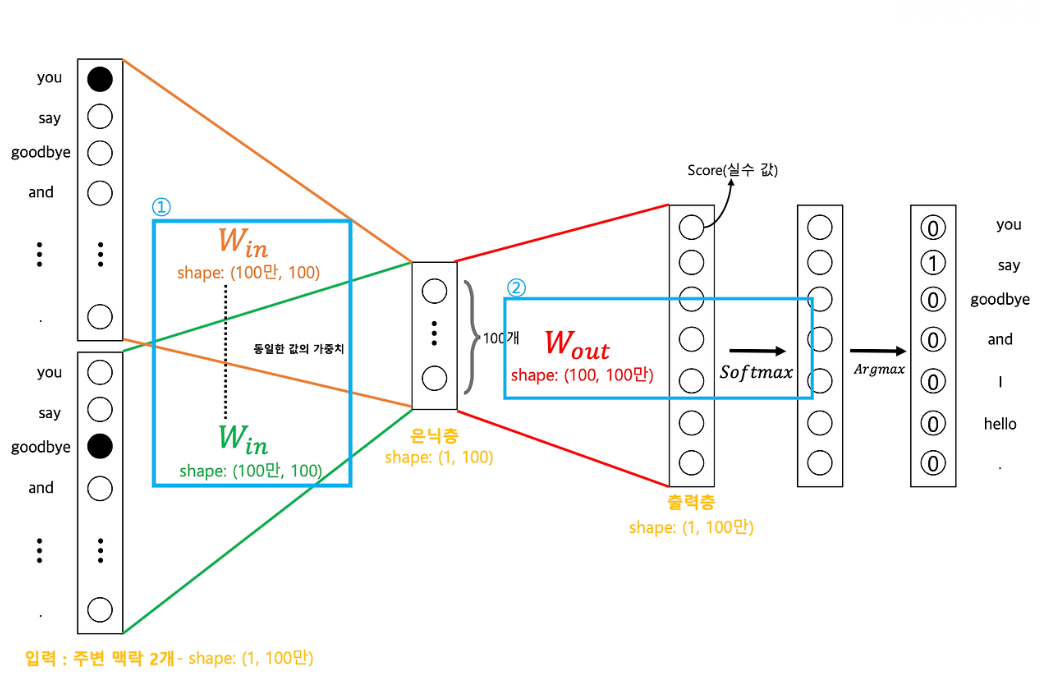
7. 시각적으로 이해하는 임베딩
8. 다양한 임베딩 모델 비교
| 구분 | Word2Vec / GloVe | BERT | Sentence-Transformers |
|---|---|---|---|
| 벡터 유형 | 정적 벡터 | 문맥 기반 동적 벡터 | 문장 전체 의미 기반 |
| 특징 | 빠르고 가볍다 | 문맥 이해 가능 | 의미 기반 검색 최적화 |
| 사용 예시 | 단어 유사도 검색 | QA, 번역, 요약 등 | RAG 쿼리 벡터화 |
9. Embedding과 RAG의 연결 고리
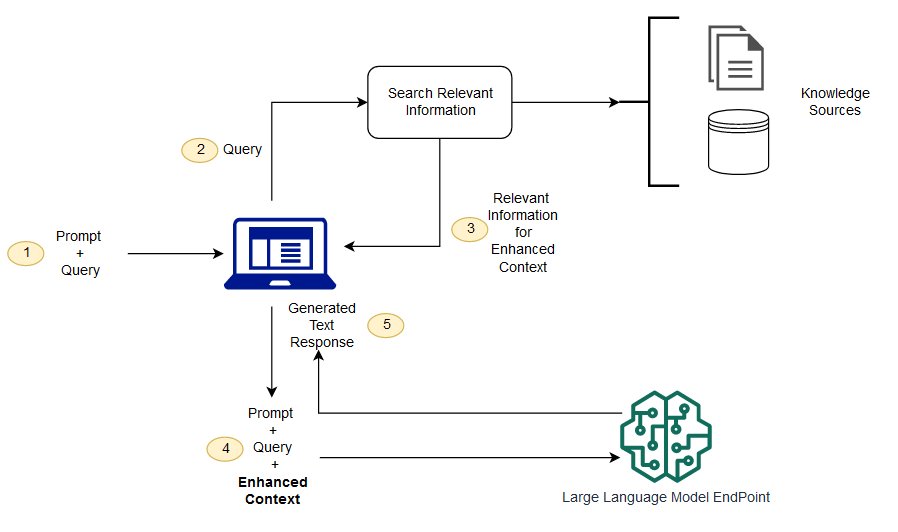
LLM의 한계
- GPT는 2023년까지의 정보만 보유
- 최신 정보나 사내 문서는 학습 불가능
- LLM만으로는 부족한 현실 반영
그래서 나온 해결책: RAG
RAG는 LLM이 몰라도 되는 정보를, 벡터 검색으로 찾아서 LLM이 이해하도록 돕는 방식입니다.
- 사용자의 질문 → 벡터화
- 유사한 문서 검색 (코사인 유사도)
- 해당 문서를 LLM에게 전달
- LLM은 그 문서를 바탕으로 응답 생성
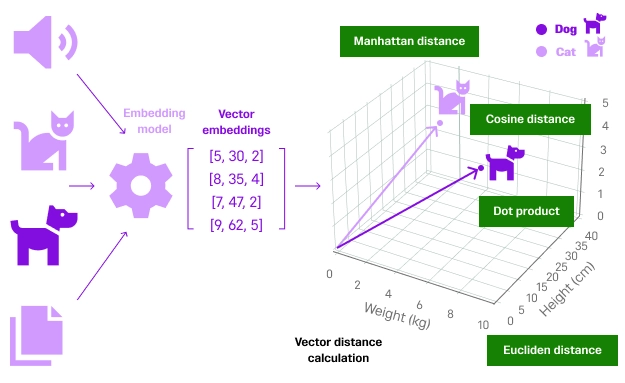
즉, 임베딩 품질이 곧 검색 정확도이며, RAG의 성능을 좌우합니다.
10. 결론: Embedding은 단순한 벡터가 아니다
Embedding은 단어를 벡터로 표현하는 것 이상의 의미를 갖습니다.
그것은 의미를 수치화하고, LLM이 외부 지식을 활용할 수 있도록 현실과 모델을 연결하는 핵심 기술입니다.
추가 참고 자료
️ 마무리하며
Word2Vec을 시작으로 Embedding 기술은 AI의 이해력과 응답력을 크게 끌어올렸습니다.
지금은 단어 수준을 넘어서 문장, 문서, 멀티모달까지 확장되고 있으며,
RAG 시스템과 결합하여 지식 기반 LLM 시스템의 필수 구성 요소로 자리잡았습니다.
Embedding을 이해하면,
"LLM이 어떻게 세상을 더 잘 이해하게 되는가?"라는 질문에
당신만의 답을 줄 수 있게 됩니다.
