📝대회 개인 회고
역할
- Generation based MRC 구현, BM25 구현, Elastic Search 구현, 하이퍼 파라미터 튜닝
이번 대회 개인 목표
- Open Domain Question Answering task를 완벽하게 이해하기
- 체계적인 실험관리 하기
- 다양한 실험해보기
대회에서 시도해본 것과 결과
-
Hyperparameter Tuning
- doc_stride & max_len
- context가 max_len을 넘길 때 겹치는 부분의 하이퍼 파라미터로 클수록 no_answer 비율이 많아짐을 확인
- KLUE 논문에서 max_len을 512로 설정하여 KLUE/RoBERTa-Large 모델을 사용할 때 그대로 적용
- public EM 기준 (max_len: 384 → 512, doc_stride: 128 → 32)
- 56.1 → 60.8
- doc_stride & max_len
-
Generation Based-MRC
- ensemble시에 모델의 다양성을 늘리기위해 generation 모델을 사용하여 실험 진행.
- google/mt5-base 모델 이용
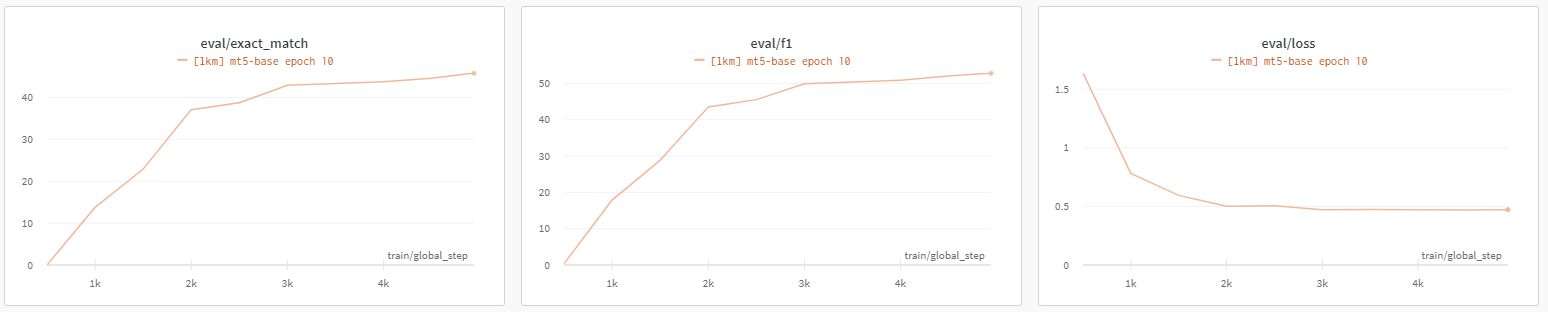
- loss의 경우 안정적으로 나왔지만, EM과 f1이 기존 Extractive 모델에 비해 현저히 낮게 나와 실제로 이용하기에는 힘들다고 판단.
- 적용하는 모델이 multilingual 모델이였고, fine-tuning하기에 너무 부족한 데이터(3900개)를 갖고 있어서 원하는 만큼 성능이 안 나왔다고 생각.
-
BM25
- TF-IDF의 개념을 바탕으로, 문서의 길이까지 고려하여 점수를 매기는 방식으로 TF-IDF보다 retrieval 성능이 좋게 나올 것이라 생각하여 실험 진행.
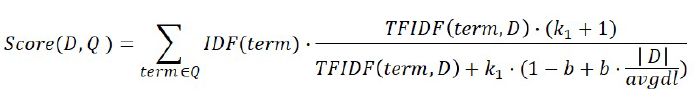
- retrieval accuracy (train + validation)
- top_k 10: 54.9 (TF-IDF: 63.5)
- top_k 20: 64.1 (TF-IDF: 72.7)
- top_k 100: 72.9 (TF-IDF: 87.2)
- TF-IDF를 개선한 방식이라 TF-IDF보다 좋은 성능을 가질 것이라 기대했지만, 생각과 다르게 낮은 성능을 보여줌.
- BM25로 유사도를 구할 때 사용한 corpus나 question에 따로 전처리를 하지 않아서 예상과 다른 결과가 나온 것으로 판단.
- TF-IDF의 개념을 바탕으로, 문서의 길이까지 고려하여 점수를 매기는 방식으로 TF-IDF보다 retrieval 성능이 좋게 나올 것이라 생각하여 실험 진행.
-
Elastic Search
- 기존 Sparse retrieval보다 빠르고 좋은 성능을 보여줄 것으로 생각하여 실험 진행.
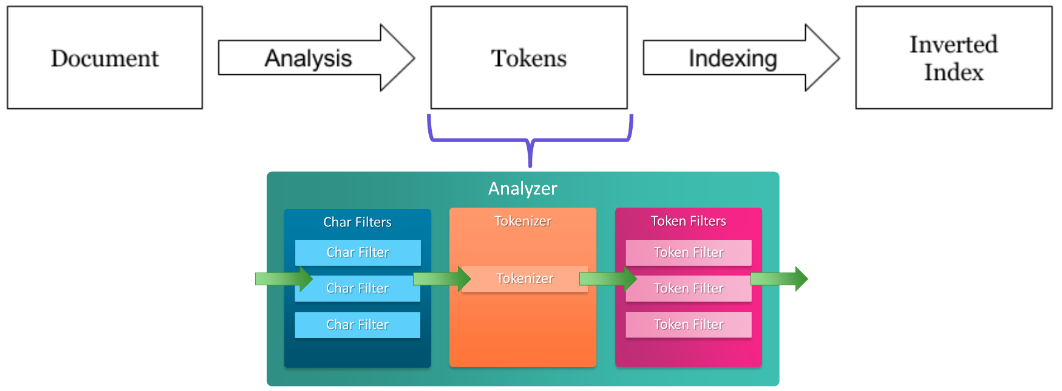
- Tokenizer: nori_tokenizer 사용 (한글 데이터를 다룰 때 많이 사용하는 형태소 분석기)
- Filter: shingle 사용 (문자 단위로 N-gram을 적용한 방식)
- 유사도 계산: BM25
- retrieval accuracy (train + validation)
- top_k 10: 89.9 (TF-IDF: 63.5)
- top_k 20: 92.6 (TF-IDF: 72.7)
- top_k 30: 93.3 (TF-IDF: 80)
- top_k 50: 95.1 (TF-IDF: 84.5)
- 기존의 Sparse retrieval (TF-IDF, BM25)보다 빠르고 높은 정확도를 보여주었다. 토크나이저와 토큰 필터링을 이용하여 높은 성능을 보여주었다고 분석.
- top_k를 50으로 했을 때 retrieval 성능이 가장 높았지만 실제 reader와 결합했을 때는 top_k가 30일 때가 가장 성능이 좋았다. 너무 긴 context가 오히려 학습에 방해가 되었다고 생각.
- 기존 Sparse retrieval보다 빠르고 좋은 성능을 보여줄 것으로 생각하여 실험 진행.
아쉬웠던 점
- Task의 충분한 이해없이 급하게 실험 진행
- 이전 KLUE 대회에서 기초 하이퍼 파라미터 세팅이 중요하다는 것을 깨달아 이번 대회에서도 대회 시작 후 바로 하이퍼 파라미터 튜닝 작업에 들어갔다. 하지만, 이번 대회는 기존 대회와 다르게 reader와 retrieval가 합쳐져서 결과가 나오기에 reader만 튜닝해도 올바른 튜닝을 했다고 단정하기 어려웠다. 급하게 실험을 진행하여 task의 이해 없이 reader의 하이퍼 파라미터 튜닝을 진행하였고, 당연히 retrieval의 성능이 좋지 않아 제대로 된 결과를 얻을 수 없었다. 초반에 task의 이해와 베이스라인의 이해를 완벽하게 하고 실험을 진행하지 못한 점이 아쉬웠다.
- Generation based MRC를 빠르게 포기한 점
- 이번 대회에서는 외부 데이터도 사용할 수 있었고 다른 팀원분께서 data augmentation 작업도 하고 있었다. 하지만, generation 모델이 extractive 모델에 비해 낮은 점수가 나와 개선할 생각은 안하고 빠르게 포기하고 다른 task를 도전하려고 했다. 외부 데이터나 data augmentation으로 generation 모델의 성능을 개선하지 못한 점이 아쉬웠다.
- 체계적이지 못한 시간관리
- 각 팀원마다 task를 분배하는 것은 쉬웠지만, 맡은 task별로 시간관리는 어려웠다. 팀원별로 맡은 task의 난이도도 다르고 각자의 역량도 달라 언제까지 task를 끝내야할지 시간을 정하는 것이 어려웠다. 정확한 시간을 정하지 않으니 늘어지는 경향이 있었고, 전체적으로 봤을 때 시간 낭비가 꽤 있었다고 생각한다.
다음에 시도해보고 싶은 것들
- 한 task로 다른 팀원과 협업
- 지금까지는 하나의 task당 한명이 맡아서 진행했는데, 이번 대회에서 두 분이 하나의 task를 같이 작업하는 것을 보고 진정한 협업을 한다고 느꼈다.
- 베이스라인의 커스텀화
- 지금까지는 베이스라인에 벗어나지 않도록 코드를 짜려고 하였다. 하지만, 스페셜 피어세션이나 다른 조들과 대화해본 결과 베이스라인의 구조를 팀에 맞게 바꾸는 작업이 좋은 경험이 됨을 깨달았다.
- 라이브러리 코드 분석
- 지금까지 사용한 huggingface의 함수나 클라스들은 공식문서에 나와있는 정보만 알고 사용하였다. 하지만, 좀 더 자유롭게 다루려면 각각의 내부구조를 아는 것이 중요하다는 것을 느꼈다.

함께 자라기