✏️학습 정리
1. 인공지능과 자연어처리
-
인공지능
- 인간의 지능이 가지는 학습, 추리, 적응, 논증 따위의 기능을 갖춘 컴퓨터 시스템
-
자연어처리
-
인간
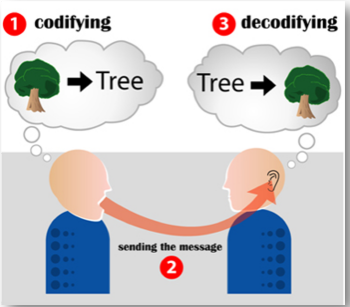
-
컴퓨터
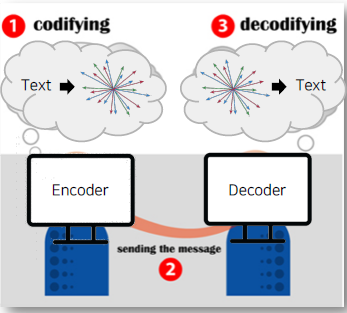
-
응용분야

-
-
단어 임베딩
-
분류를 위해선 데이터를 수학적으로 표현 (그래프 위에 표현 → 대상들의 경계를 나눌 수 있음)
-
feature extraction, classification이 기계학습의 핵심
-
Word2Vec
- 자연어의 의미를 벡터 공간에 임베딩
- 한 단어의 주변 단어들을 통해, 그 단어의 의미 파악 (skip gram 방식)
- 장점
- 단어간의 유사도 측정 용이
- 단어간의 관계 파악 용이
- 벡터 연산을 통한 추론 가능 (한국 - 서울 + 도쿄 = ?)
- 단점
- 단어의 subword 정보 무시 (서울, 서울시), 용언 표현들이 서로 독립된 vocab
- out of vocabulary 문제
-
FastText
-
단어를 n-gram으로 분리를 한 후, 모든 n-gram vector를 합산한 후 평균을 통해 단어 벡터 획득
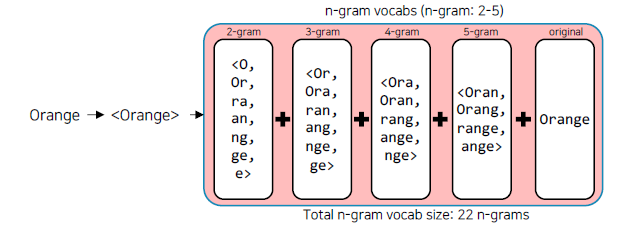
-
오탈자, OOV, 등장 회수가 적은 학습 단어에 대해서 강세
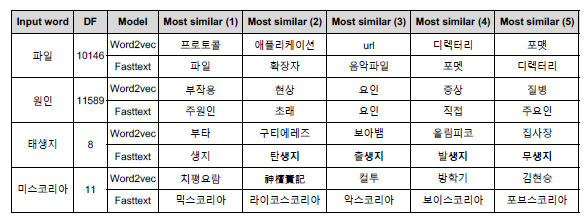
-
-
한계점
- 동형어, 다의어 등에 대해서 embedding 성능이 좋지 못함
- 주변 단어를 통해 학습이 이루어지기 때문에, 문맥을 고려할 수 없음
-
-
언어모델
-
자연어의 법칙을 컴퓨터로 모사한 모델
-
마르코프 체인 모델(Markov Chain Model)
- 다음 단어나 문장이 나올 확률을 통계와 단어의 n-gram을 기반으로 계산
-
RNN (Recurrent Neural Network)
- 이전 state 정보가 다음 state를 예측하는데 사용됨으로써, 시계열 데이터 처리에 특화
- 마지막 출력은 앞선 단어들의 문맥을 고려해서 만들어진 최종 출력 vector (context vector)
-
Seq2Seq (RNN 기반)
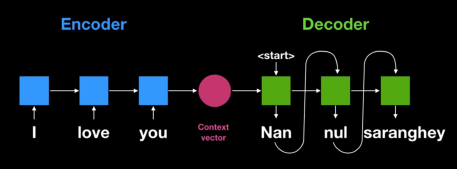
- Encoder layer: RNN 구조를 통해 context vector 획득
- Decoder layer: context vector를 입력으로 출력을 예측
-
Attention 모델
-
기존 RNN 문제: long term dependency, 고정된 context vecotr 사이즈로 sequence 정보 함축 어려움, 중요하지 않은 token도 영향을 줌
-
중요한 feature는 더욱 중요하게 고려하는 방식
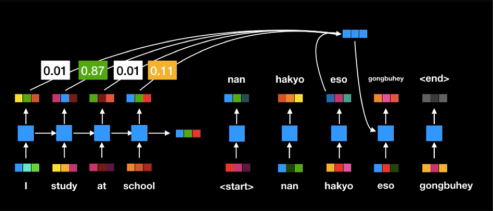
-
하지만, 여전히 RNN이 순차적으로 연산이 이뤄짐에 따라 연산 속도 느림
-
-
Self-Attention
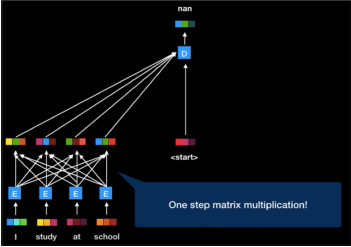
-
Transformer
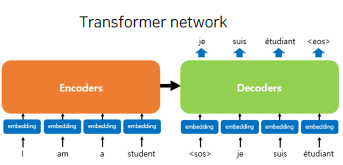
-
-
- 다양한 언어모델
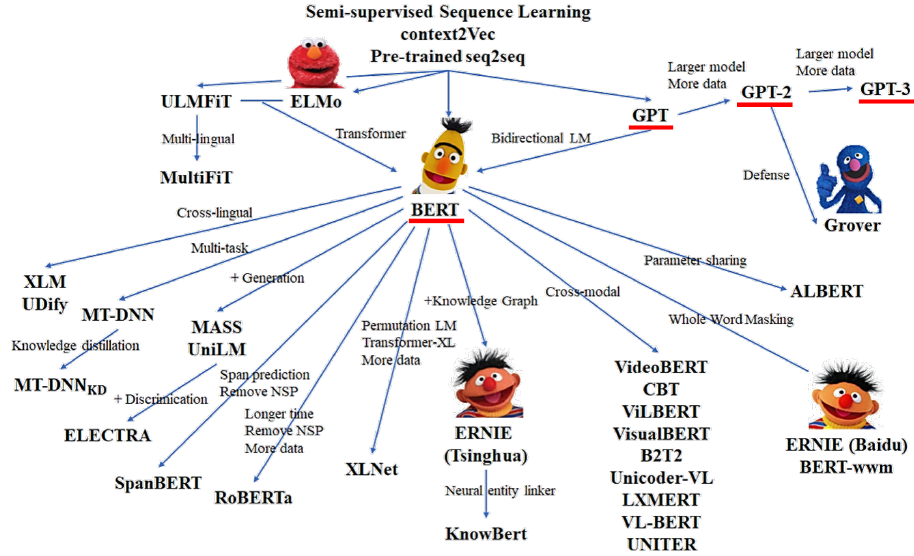
2. 자연어 전처리
-
전처리
- raw data를 모델에 학습하는데 적합하게 만드는 프로세스
- 학습에 사용될 데이터를 수집, 가공하는 모든 프로세스
-
자연어처리 단계
- Task 설계
- 필요 데이터 수집
- 통계학적 분석
- 전처리
- Tagging
- Tokenizing (어절, 형태소, wordpiece...)
- 모델 설계
- 모델 구현
- 성능 평가
- 완료
-
한국어 토큰화
- 토큰화(Tokenizing)
- 주어진 데이터를 토큰이라 불리는 단위로 나누는 작업
- 토큰 기준은 다양 (어절, 단어, 형태소, 음절, 자소 등..)
- 문장 토큰화 (문장 분리)
- 단어 토큰화 (구두점 분리, 단어 분리)
- 한국어는 조사나 어미를 붙여서 말을 만드는 교착어로, 띄어쓰기로만으로는 부족
- 한국어에서는 어절이 의미를 가지는 최소 단위인 형태소로 분리
- 토큰화(Tokenizing)
실습
-
한국어 전처리 실습
- 문장 분리
- Normalizing
- Filtering
- 유니코드 기반 filtering
-
한국어 Tokenizing
- 어절 단위
- 형태소 단위
- 음절 단위
- 자소 단위
- WordPiece
🗣️피어세션
- 대회 그라운드 룰 설정
- 대회 제출 룰: 매일 밤 9시 슬랙 봇이 올리는 설문에 답변(오늘 제출 했는지/할 예정인지, 제출 안 할 것인지 → 이를 통해 여분의 제출횟수가 나오고, 이걸 쓴 사람은 스레드로 보고하기)
- validation 데이터 고정하기 (
StratifiedShuffleSplit사용) - 팀 대회 리더보드 실험 로그엔 본인이 제출한 모델의 정보만 올릴 것 → 각자의 자잘한 실험 로그는 개인 실험 로그에 따로 기록

함께 자라기