
Image Classification
Challenges ) 보는 시각, 조명, 형태의 변형, 은폐은닉, 배경과 구분 안되는 이미지, 고양이 클래스 중에서도 구분하기(ex. 품종 구분)
Nearest Neighbor Classifier
사실상 아무도 사용하지 않음.
- train) 모든 학습용 이미지와 레이블을 기억하게 함.
- predict) input을 모든 training 이미지와 다 비교하고, 가장 비슷한 training 이미지 label을 결과값으로 리턴
- How to compare test img와 training img의 대응하는 픽셀 값의 차를 구하고 그 값을 모두 더함
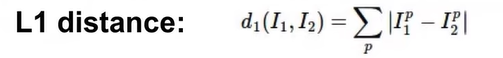
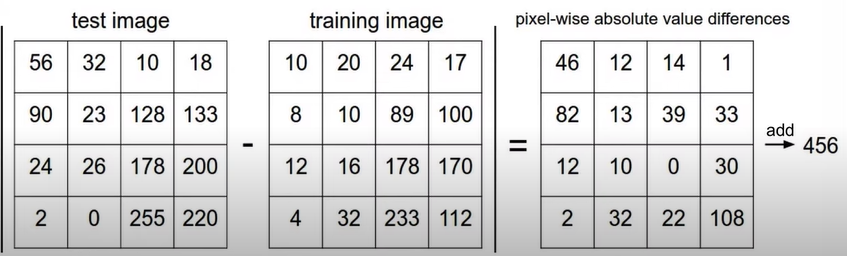
→ training데이터 사이즈에 따라 분류속도는 선형적으로 증가함.
→ 당연함~ training data 데이터와 다 비교하기 때문~ = training 속도↑ test 속도↓
- Train time= O(1)
포인터 이용하면, 데이터의 크기와 상관없이 상수시간으로 끝남 - Test time = O(n)
N개의 학습 데이터 전부를 테스트 이미지와 비교
▶ Train TIme < Test TIme “뒤집어진” 것!
K- Nearest Neighbor Classifier
KNN
k개의 가장 가까운 이미지를 찾고, k개의 이미지들이 다수결로 vote를 함.
→ 가장 많이 나온 것으로 결과값 리턴.
Distance metrix를 이용해서 가까운 이웃을 K개 만큼 찾고, 이웃끼리 투표함.
→ 가장 많은 득표수를 획득한 레이블로 결과값 예측
일반적으로는 NN보다 성능이 좋다고 알려짐
투표 방법에도 여러개 有 (ex. 거리별 가중치 고려)
가장 잘 동작하고 가장 쉬운 방법 = 득표수만 고려하자~
- 거리 척도에 따라서 결정경계의 모양이 달라짐
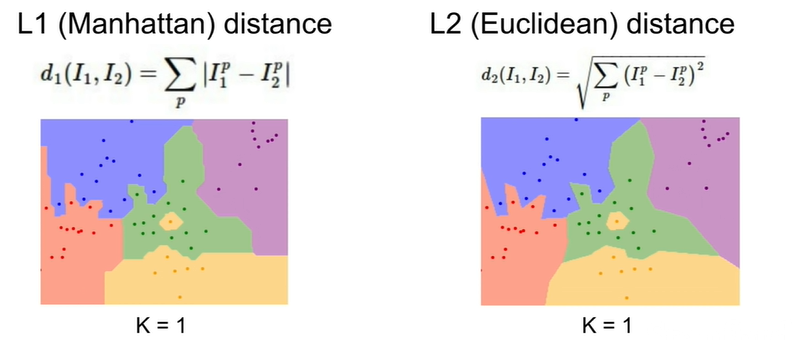
→ L1 : 좌표 축에 영향을 받음
→ L2 : 좌표 축 영향 X , 경계가 조금 더 자연스러움
**언제 L1이 더 좋은가?
기본적으로 problem-dependent
“각 요소가 특별한 의미를 가지고 있다면” 더 괜찮을지도~?
- Hyperparameter → problem dependent! 가장 간단한 방법: 다 해봐! 다양한 하이퍼파라미터값 시도해보고 젤 좋은거 픽
- distance
- k
- Training /Test Data test 데이터로 train하면 절대 안돼~
- Cross-validation

- Cross-validation
Linear Classification
이미지 내의 모든 픽셀값들에 대해 가중치를 곱한 값들의 합!!
각각 다른 공간적 위치에 있는 “컬러”들을 카운팅 한 것
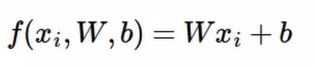
“컬러” 중요!
구분 어려운 것들
→ 흑백사진 : 텍스처나 디테일 기준으로 봄 → 성능 떨어짐
→ 정반대의 색상 → 형태는 인식하나 컬러는 전혀 반대라 구분 어려움
→ 텍스쳐가 형태는 다르지만 생각은 같을 경우
But!
→ 강아지가 왼쪽. 오른쪽 이런 식으로 치우쳐있는건 잘함!
