
💜 Ponitor
이렇게나 귀여운 내가 벌써 3학년 2학기가 돼서 졸업프로젝트를 시작했다.
우리 팀은 대면편취형 보이스피싱을 예방하기 위한 모니터링 서비스를 기획했다.
최근, 검찰청 자료에 따르면 "대면편취형" 보이스피싱이 증가하고 있는데, 이러한 대면편취형 보이스피싱의 경우 피해자가 직접 돈을 출금해 가해자에게 전달하기 때문에 마땅한 구제방안이 없는 상황이다.
또한 skt, 후후, 토스 등 기업에서 다양한 보이스피싱 예방 서비스를 제공하고 있지만, 모두 "출금 과정"에 대한 솔루션은 아니다.
우리는 이러한 부분에 집중해 대면편취형 보이스피싱의 가장 마지막 단계인 피해금 출금 과정에 대한 예방 서비스를 제공하고자 한다.
아, Ponitor는 Phishing + Monitor의 합성어다! 히히🥰
💜 How to Predict Victims
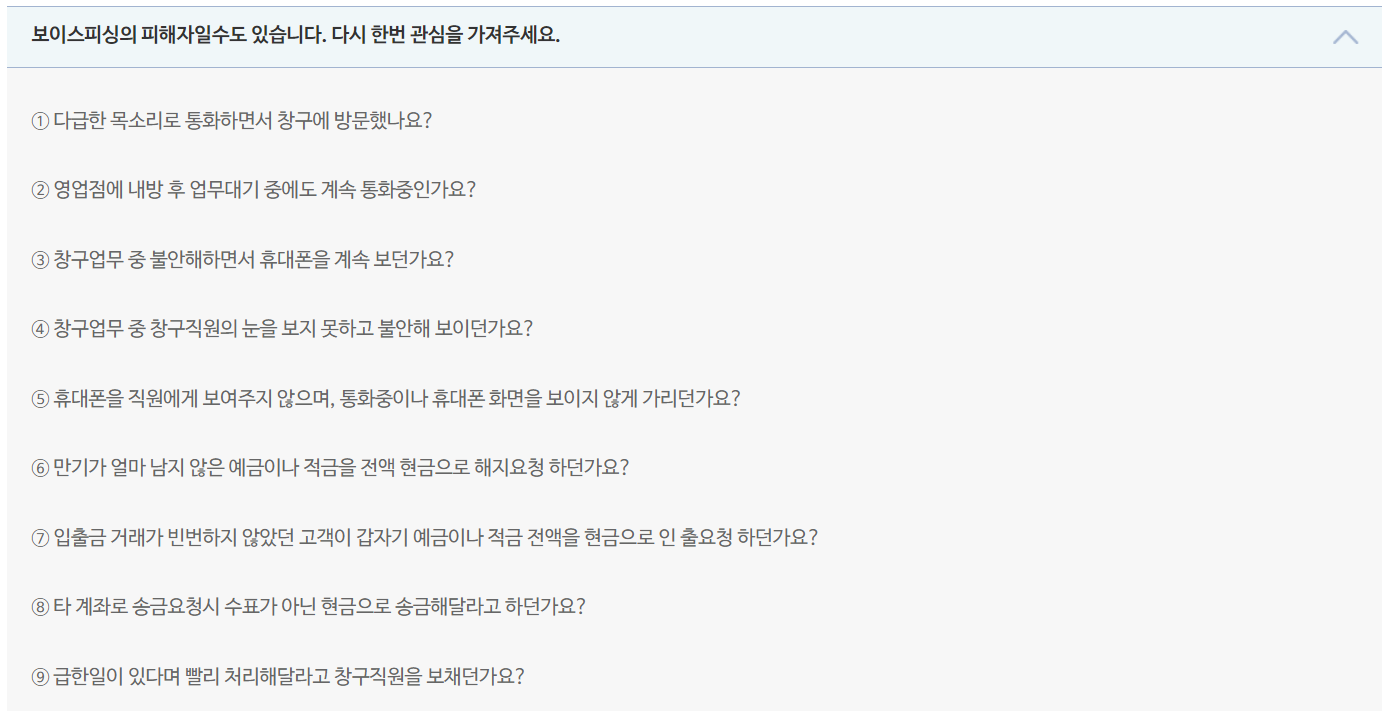
보이스피싱 피해자의 특징에는 크게 두가지가 있다.
1. 불안, 다급한 모습 등 불안정한 감정상태
2. 지속적인 통화 및 휴대폰 사용
위의 두가지 특징은 저축은행중앙회의 [피해금 창구 인출 의심 주요 유형]에서 참고했다.
자료 찾아준 연주언니 THANK YOU SO MUCH
이에 따라 ATM 카메라를 통해 사용자의 감정 및 통화여부를 판단하여 보이스피싱 피해 가능성을 예측한다.
피해자로 예측된 사용자에게는 ATM 화면에 관련 알림창을 띄운다.
💜 Emotion Recognition
ATM 카메라 인풋을 통해 사용자의 감정을 인식, 불안 등의 부정적인 감정을 Detection 한다.
하지만 여전히 여러 문제가 존재한다.
Problem
코로나19로 인한 마스크 착용의 일상화로 "표정" 데이터만 가지고 감정을 인식하는 것은 정확도가 떨어질 수 있다.
Solution
- Facial expression + α (ex. 행동/몸짓)으로 감정을 인식하기
- Mask Detection 후, 신원확인을 위해 마스크를 벗어달라고 안내 후에
마스크를 벗었을 때부터 ATM 이용이 가능하도록 구성하기.
➡️ 사용자의 편의를 고려했을 때, 1번 솔루션이 더 적절하다 판단했다.
📌 Model
멘토님과의 피드백 후, SOTA에서 관련 좋은 모델이 있는지 찾아보았다.
그 결과 찾은 모델은 다음과 같다.
Context Based Emotion Recognition using EMOTIC Dataset
아래에 나오는 이미지들은 모두 위의 논문에서 참조했다.
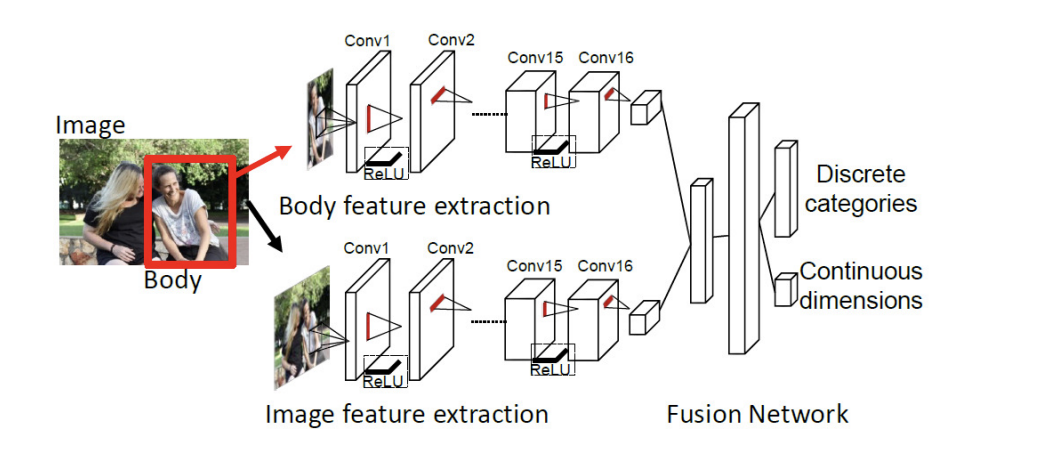
위 모델은 하나의 이미지에서 Body feature와 image feature, 총 2개의 feature를 추출한다. 이 두개의 feature는 마지막 3번째 fusion Network 모듈에서 continuous dismension과 discrete categories를 예측하는데 사용된다.
⚙️ 개발 환경
- IDE :
- vscode- Dependencies:
- Python 3.9.13
- Pythorch
- YOLOv3
- OpenCV
- numpy
- matplotlib- Reference
- Source code & Data
📌 About Data
데이터의 경우, 비상업적 연구의 목적으로 신청하면 dataset access mail를 받을 수 있고 여기서 다운로드 받을 수 있다.
해당 데이터셋은 23,571개의 이미지와 그에 해당하는 34,320개의 annotated people로 구성되어 있다. 데이터셋의 일부는 구글의 서치엔진을 사용하였고, 다양한 장소와 사회적 환경, 활동들과 감정상태가 포함되어 있다.
아래는 데이터셋의 일부를 이미지로 보여준 것이다.

위의 Model의 마지막 문장에서 "continuous dismension과 discrete categories를 예측하는데 사용된다"고 했다.
여기서
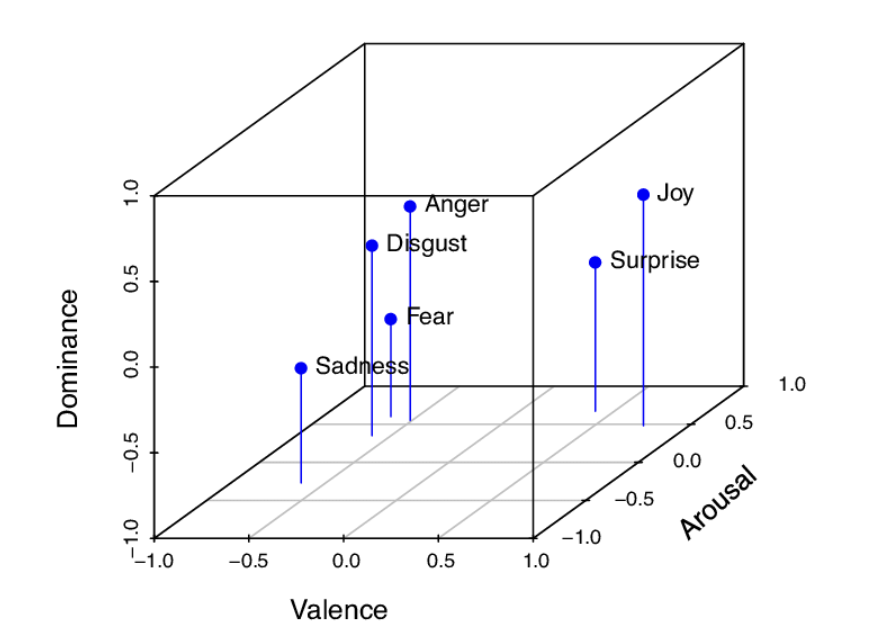
✅ Continuous dismension란
감정을 3차원의 연속적 공간인 “Valence, Arousal, Dominance” 의 위에서 표현한 것으로 모두 1에서 10 사이의 값을 가지며 각각
Valence: 감정이 얼마나 유쾌/불쾌한지
Arousal: 감정으로 인해 얼마나 신체적 흥분상태가 되었는지
Dominance: 감정으로 인해 얼마나 통제력을 잃었는지
를 의미한다.
감정을 정의하는 것은 어려운 일이다. 단순하게 "즐겁다" "아니다" 라고 이분법으로 나누기에는 한계가 있기 때문이다. 따라서 복합적인 감정을 체계적으로 모델링하려면 연속적인 공간위에서 이해하는 것이 필요하고 이에 해당하는 것이 VAD 모델이다.
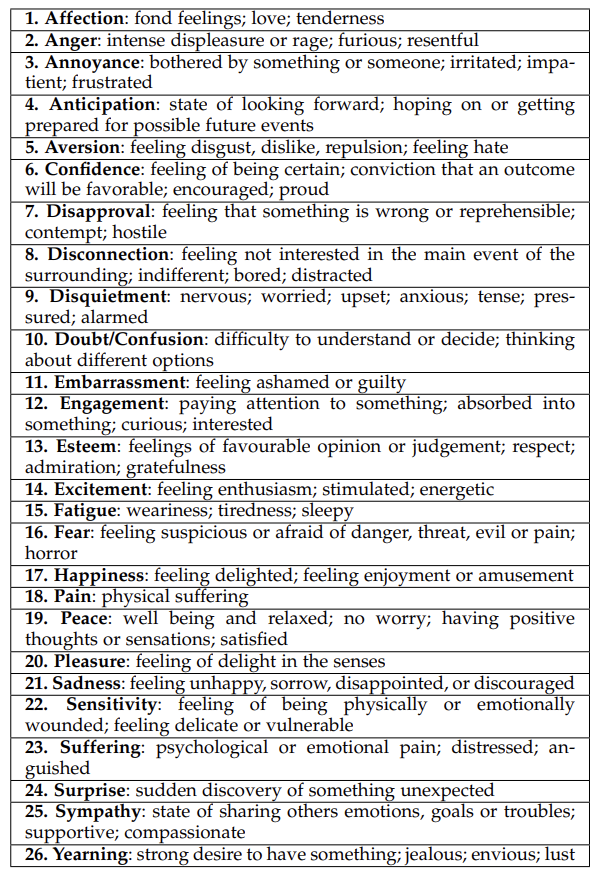
✅ Discrete Catagories란
말 그대로 개별 카테고리고, 감정을 아래와 같이 26개의 카테고리로 나누었다.
우리 서비스에서 감정 인식은 상당히 비중을 차지하는 기술이기 때문에 감정 카테고리가 자세하게 나눠져 있는 것은 모델 선택에 있어서 중요한 요소였다.
📌 Preprocessing
데이터셋을 다운로드 받고 전처리를 하기 위해 폴더 구조를 다음과 같이 정리해줘야 한다.
Annotation이 mat형식이기 때문에 이를 csv파일로 변경하기 위해 mat2py.py를 실행시킨다.
training과 test할 때 npy파일이 쓰이기 때문에 generate_npy를 True로 전달해줘야 한다.
따라서 다음과 같은 명령어를 터미널에 입력해 mat2py.py를 실행시킨다.
data_dir : 데이터셋을 포함하는 폴더 경로
python mat2py.py --data_dir proj/data/emotic19 --generate_npy
mat2py.py 中 prepare_data()
def prepare_data(data_mat, data_path_src, save_dir, dataset_type='train', generate_npy=False, debug_mode=False):
'''
csv 파일 생성과 전처리 데이터를 npy 파일에 저장한다.
:param data_mat: Mat 형식의 라벨 데이터
:param data_path_src: 데이터셋이 저장되어있는 최상위 폴더 경로
:param save_dir: csv, npy files를 저장할 폴더 경로
:param dataset_type: 데이터셋의 타입 (train or val or test) - 파일의 이름으로 들어감
:param generate_npy: True이면 데이터를 전처리하고 npy 형식으로 저장함. 나중에 training할 때 사용
'''
data_set = list()
if generate_npy:
context_arr = list()
body_arr = list()
cat_arr = list()
cont_arr = list()
to_break = 0
path_not_exist = 0
cat_cont_zero = 0
idx = 0
for ex_idx, ex in enumerate(data_mat[0]):
nop = len(ex[4][0])
for person in range(nop):
if dataset_type == 'train':
et = emotic_train(ex[0][0],ex[1][0],ex[2],ex[4][0][person])
else:
et = emotic_test(ex[0][0],ex[1][0],ex[2],ex[4][0][person])
try:
image_path = os.path.join(data_path_src,et.folder,et.filename)
if not os.path.exists(image_path):
path_not_exist += 1
print ('path not existing', ex_idx, image_path)
continue
else:
context = cv2.cvtColor(cv2.imread(image_path),cv2.COLOR_BGR2RGB)
body = context[et.bbox[1]:et.bbox[3],et.bbox[0]:et.bbox[2]].copy()
context_cv = cv2.resize(context, (224,224))
body_cv = cv2.resize(body, (128,128))
except Exception as e:
to_break += 1
if debug_mode == True:
print ('breaking at idx=%d, %d due to exception=%r' %(ex_idx, idx, e))
continue
if (et.cat_annotators == 0 or et.cont_annotators == 0):
cat_cont_zero += 1
continue
data_set.append(et)
if generate_npy == True:
context_arr.append(context_cv)
body_arr.append(body_cv)
if dataset_type == 'train':
cat_arr.append(cat_to_one_hot(et.cat))
cont_arr.append(np.array(et.cont))
else:
cat_arr.append(cat_to_one_hot(et.comb_cat))
cont_arr.append(np.array(et.comb_cont))
if idx % 1000 == 0 and debug_mode==False:
print (" Preprocessing data. Index = ", idx)
elif idx % 20 == 0 and debug_mode==True:
print (" Preprocessing data. Index = ", idx)
idx = idx + 1
# for debugging purposes
if debug_mode == True and idx >= 104:
print (' ######## Breaking data prep step', idx, ex_idx, ' ######')
print (to_break, path_not_exist, cat_cont_zero)
cv2.imwrite(os.path.join(save_dir, 'context1.png'), context_arr[-1])
cv2.imwrite(os.path.join(save_dir, 'body1.png'), body_arr[-1])
break
print (to_break, path_not_exist, cat_cont_zero)
csv_path = os.path.join(save_dir, "%s.csv" %(dataset_type))
with open(csv_path, 'w') as csvfile:
filewriter = csv.writer(csvfile, delimiter=',', dialect='excel')
row = ['Index', 'Folder', 'Filename', 'Image Size', 'BBox', 'Categorical_Labels', 'Continuous_Labels', 'Gender', 'Age']
filewriter.writerow(row)
for idx, ex in enumerate(data_set):
if dataset_type == 'train':
row = [idx, ex.folder, ex.filename, ex.im_size, ex.bbox, ex.cat, ex.cont, ex.gender, ex.age]
else:
row = [idx, ex.folder, ex.filename, ex.im_size, ex.bbox, ex.comb_cat, ex.comb_cont, ex.gender, ex.age]
filewriter.writerow(row)
print ('wrote file ', csv_path)
if generate_npy == True:
context_arr = np.array(context_arr)
body_arr = np.array(body_arr)
cat_arr = np.array(cat_arr)
cont_arr = np.array(cont_arr)
print (len(data_set), context_arr.shape, body_arr.shape)
np.save(os.path.join(save_dir,'%s_context_arr.npy' %(dataset_type)), context_arr)
np.save(os.path.join(save_dir,'%s_body_arr.npy' %(dataset_type)), body_arr)
np.save(os.path.join(save_dir,'%s_cat_arr.npy' %(dataset_type)), cat_arr)
np.save(os.path.join(save_dir,'%s_cont_arr.npy' %(dataset_type)), cont_arr)
print (context_arr.shape, body_arr.shape, cat_arr.shape, cont_arr.shape)
print ('completed generating %s data files' %(dataset_type))성공적으로 실행되면 pre 폴더가 생성되고 하위에 다음과 같은 Anotation 파일들이 생성된다.
📌 Training
데이터 전처리까지 끝났으니 training을 시켜보자!
mode: 메인 파일에서 돌릴 모드 → train
data_path: 전처리된 데이터(npy)와 csv파일이 저장된 폴더 경로
experiment_path: experiment directory의 경로명으로 학습된 모델과 결과, 로그가 저장됨
각 파라미터에 해당하는 경로명을 넣어 아래의 명령어를 터미널에 입력하자.
python main.py --mode train --data_path proj/data/emotic_pre --experiment_path proj/debug_exptrain.py 中
def train_data(opt, scheduler, models, device, train_loader, val_loader, disc_loss, cont_loss, train_writer, val_writer, model_path, args):
'''
Training emotic model on train data using train loader.
:param opt: Optimizer object.
:param scheduler: Learning rate scheduler object.
:param models: List containing model_context, model_body and emotic_model (fusion model) in that order.
:param device: Torch device. Used to send tensors to GPU if available.
:param train_loader: Dataloader iterating over train dataset.
:param val_loader: Dataloader iterating over validation dataset.
:param disc_loss: Discrete loss criterion. Loss measure between discrete emotion categories predictions and the target emotion categories.
:param cont_loss: Continuous loss criterion. Loss measure between continuous VAD emotion predictions and the target VAD values.
:param train_writer: SummaryWriter object to save train logs.
:param val_writer: SummaryWriter object to save validation logs.
:param model_path: Directory path to save the models after training.
:param args: Runtime arguments.
'''
model_context, model_body, emotic_model = models
emotic_model.to(device)
model_context.to(device)
model_body.to(device)
print ('starting training')
for e in range(args.epochs):
running_loss = 0.0
running_cat_loss = 0.0
running_cont_loss = 0.0
emotic_model.train()
model_context.train()
model_body.train()
#train models for one epoch
for images_context, images_body, labels_cat, labels_cont in iter(train_loader):
images_context = images_context.to(device)
images_body = images_body.to(device)
labels_cat = labels_cat.to(device)
labels_cont = labels_cont.to(device)
opt.zero_grad()
pred_context = model_context(images_context)
pred_body = model_body(images_body)
pred_cat, pred_cont = emotic_model(pred_context, pred_body)
cat_loss_batch = disc_loss(pred_cat, labels_cat)
cont_loss_batch = cont_loss(pred_cont * 10, labels_cont * 10)
loss = (args.cat_loss_weight * cat_loss_batch) + (args.cont_loss_weight * cont_loss_batch)
running_loss += loss.item()
running_cat_loss += cat_loss_batch.item()
running_cont_loss += cont_loss_batch.item()
loss.backward()
opt.step()
if e % 1 == 0:
print ('epoch = %d loss = %.4f cat loss = %.4f cont_loss = %.4f' %(e, running_loss, running_cat_loss, running_cont_loss))
train_writer.add_scalar('losses/total_loss', running_loss, e)
train_writer.add_scalar('losses/categorical_loss', running_cat_loss, e)
train_writer.add_scalar('losses/continuous_loss', running_cont_loss, e)
running_loss = 0.0
running_cat_loss = 0.0
running_cont_loss = 0.0
emotic_model.eval()
model_context.eval()
model_body.eval()
with torch.no_grad():
#validation for one epoch
for images_context, images_body, labels_cat, labels_cont in iter(val_loader):
images_context = images_context.to(device)
images_body = images_body.to(device)
labels_cat = labels_cat.to(device)
labels_cont = labels_cont.to(device)
pred_context = model_context(images_context)
pred_body = model_body(images_body)
pred_cat, pred_cont = emotic_model(pred_context, pred_body)
cat_loss_batch = disc_loss(pred_cat, labels_cat)
cont_loss_batch = cont_loss(pred_cont * 10, labels_cont * 10)
loss = (args.cat_loss_weight * cat_loss_batch) + (args.cont_loss_weight * cont_loss_batch)
running_loss += loss.item()
running_cat_loss += cat_loss_batch.item()
running_cont_loss += cont_loss_batch.item()
if e % 1 == 0:
print ('epoch = %d validation loss = %.4f cat loss = %.4f cont loss = %.4f ' %(e, running_loss, running_cat_loss, running_cont_loss))
val_writer.add_scalar('losses/total_loss', running_loss, e)
val_writer.add_scalar('losses/categorical_loss', running_cat_loss, e)
val_writer.add_scalar('losses/continuous_loss', running_cont_loss, e)
scheduler.step()
print ('completed training')
emotic_model.to("cpu")
model_context.to("cpu")
model_body.to("cpu")
torch.save(emotic_model, os.path.join(model_path, 'model_emotic1.pth'))
torch.save(model_context, os.path.join(model_path, 'model_context1.pth'))
torch.save(model_body, os.path.join(model_path, 'model_body1.pth'))
print ('saved models')
def train_emotic(result_path, model_path, train_log_path, val_log_path, ind2cat, ind2vad, context_norm, body_norm, args):
''' Prepare dataset, dataloders, models.
:param result_path: Directory path to save the results (val_predidictions mat object, val_thresholds npy object).
:param model_path: Directory path to load pretrained base models and save the models after training.
:param train_log_path: Directory path to save the training logs.
:param val_log_path: Directoty path to save the validation logs.
:param ind2cat: Dictionary converting integer index to categorical emotion.
:param ind2vad: Dictionary converting integer index to continuous emotion dimension (Valence, Arousal and Dominance).
:param context_norm: List containing mean and std values for context images.
:param body_norm: List containing mean and std values for body images.
:param args: Runtime arguments.
'''
# Load preprocessed data from npy files
train_context = np.load(os.path.join(args.data_path, 'train_context_arr.npy'))
train_body = np.load(os.path.join(args.data_path, 'train_body_arr.npy'))
train_cat = np.load(os.path.join(args.data_path, 'train_cat_arr.npy'))
train_cont = np.load(os.path.join(args.data_path, 'train_cont_arr.npy'))
val_context = np.load(os.path.join(args.data_path, 'val_context_arr.npy'))
val_body = np.load(os.path.join(args.data_path, 'val_body_arr.npy'))
val_cat = np.load(os.path.join(args.data_path, 'val_cat_arr.npy'))
val_cont = np.load(os.path.join(args.data_path, 'val_cont_arr.npy'))
print ('train ', 'context ', train_context.shape, 'body', train_body.shape, 'cat ', train_cat.shape, 'cont', train_cont.shape)
print ('val ', 'context ', val_context.shape, 'body', val_body.shape, 'cat ', val_cat.shape, 'cont', val_cont.shape)
# Initialize Dataset and DataLoader
train_transform = transforms.Compose([transforms.ToPILImage(),transforms.RandomHorizontalFlip(), transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4), transforms.ToTensor()])
test_transform = transforms.Compose([transforms.ToPILImage(),transforms.ToTensor()])
train_dataset = Emotic_PreDataset(train_context, train_body, train_cat, train_cont, train_transform, context_norm, body_norm)
val_dataset = Emotic_PreDataset(val_context, val_body, val_cat, val_cont, test_transform, context_norm, body_norm)
train_loader = DataLoader(train_dataset, args.batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, args.batch_size, shuffle=False)
print ('train loader ', len(train_loader), 'val loader ', len(val_loader))
# Prepare models
model_context, model_body = prep_models(context_model=args.context_model, body_model=args.body_model, model_dir=model_path)
emotic_model = Emotic(list(model_context.children())[-1].in_features, list(model_body.children())[-1].in_features)
model_context = nn.Sequential(*(list(model_context.children())[:-1]))
model_body = nn.Sequential(*(list(model_body.children())[:-1]))
for param in emotic_model.parameters():
param.requires_grad = True
for param in model_context.parameters():
param.requires_grad = True
for param in model_body.parameters():
param.requires_grad = True
device = torch.device("cuda:%s" %(str(args.gpu)) if torch.cuda.is_available() else "cpu")
opt = optim.Adam((list(emotic_model.parameters()) + list(model_context.parameters()) + list(model_body.parameters())), lr=args.learning_rate, weight_decay=args.weight_decay)
scheduler = StepLR(opt, step_size=7, gamma=0.1)
disc_loss = DiscreteLoss(args.discrete_loss_weight_type, device)
if args.continuous_loss_type == 'Smooth L1':
cont_loss = ContinuousLoss_SL1()
else:
cont_loss = ContinuousLoss_L2()
train_writer = SummaryWriter(train_log_path)
val_writer = SummaryWriter(val_log_path)
# training
train_data(opt, scheduler, [model_context, model_body, emotic_model], device, train_loader, val_loader, disc_loss, cont_loss, train_writer, val_writer, model_path, args)
# validation
test_data([model_context, model_body, emotic_model], device, val_loader, ind2cat, ind2vad, len(val_dataset), result_dir=result_path, test_type='val')
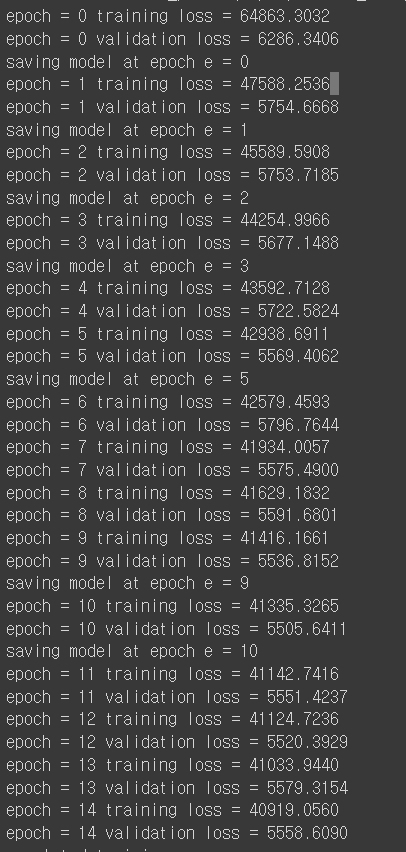
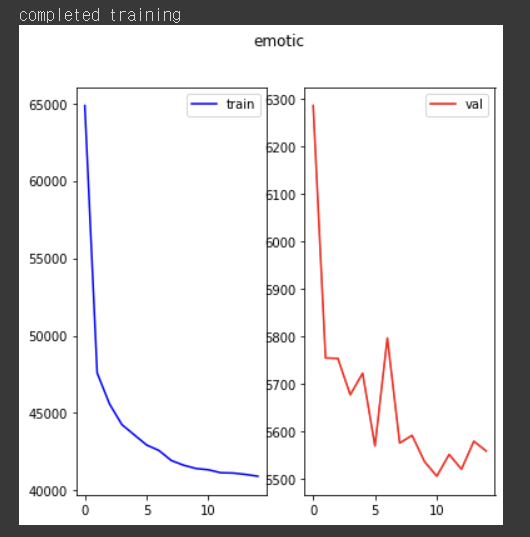
나는 15번 학습시켰다.
15 epoch 동안의 training loss와 vaildation loss 변화는 아래와 같다.
위의 결과를 그래프로 나타낸 것
📌 Test
training을 시켰다면 test를 해보자!
mode: 메인 파일에서 돌릴 모드 → test
data_path: 전처리된 데이터(npy)와 csv파일이 저장된 폴더 경로
experiment_path: experiment directory의 경로명으로 학습된 모델이 저장되어 있음
python main.py --mode test --data_path proj/data/emotic_pre --experiment_path proj/debug_exptest.py 中
def test_scikit_ap(cat_preds, cat_labels, ind2cat):
''' Calculate average precision per emotion category using sklearn library.
:param cat_preds: Categorical emotion predictions.
:param cat_labels: Categorical emotion labels.
:param ind2cat: Dictionary converting integer index to categorical emotion.
:return: Numpy array containing average precision per emotion category.
'''
ap = np.zeros(26, dtype=np.float32)
for i in range(26):
ap[i] = average_precision_score(cat_labels[i, :], cat_preds[i, :])
print ('Category %16s %.5f' %(ind2cat[i], ap[i]))
print ('Mean AP %.5f' %(ap.mean()))
return ap
def test_vad(cont_preds, cont_labels, ind2vad):
''' Calcaulate VAD (valence, arousal, dominance) errors.
:param cont_preds: Continuous emotion predictions.
:param cont_labels: Continuous emotion labels.
:param ind2vad: Dictionary converting integer index to continuous emotion dimension (Valence, Arousal and Dominance).
:return: Numpy array containing mean absolute error per continuous emotion dimension.
'''
vad = np.zeros(3, dtype=np.float32)
for i in range(3):
vad[i] = np.mean(np.abs(cont_preds[i, :] - cont_labels[i, :]))
print ('Continuous %10s %.5f' %(ind2vad[i], vad[i]))
print ('Mean VAD Error %.5f' %(vad.mean()))
return vad
def get_thresholds(cat_preds, cat_labels):
''' Calculate thresholds where precision is equal to recall. These thresholds are then later for inference.
:param cat_preds: Categorical emotion predictions.
:param cat_labels: Categorical emotion labels.
:return: Numpy array containing thresholds per emotion category where precision is equal to recall.
'''
thresholds = np.zeros(26, dtype=np.float32)
for i in range(26):
p, r, t = precision_recall_curve(cat_labels[i, :], cat_preds[i, :])
for k in range(len(p)):
if p[k] == r[k]:
thresholds[i] = t[k]
break
return thresholds
def test_data(models, device, data_loader, ind2cat, ind2vad, num_images, result_dir='./', test_type='val'):
''' Test models on data
:param models: List containing model_context, model_body and emotic_model (fusion model) in that order.
:param device: Torch device. Used to send tensors to GPU if available.
:param data_loader: Dataloader iterating over dataset.
:param ind2cat: Dictionary converting integer index to categorical emotion.
:param ind2vad: Dictionary converting integer index to continuous emotion dimension (Valence, Arousal and Dominance)
:param num_images: Number of images in the dataset.
:param result_dir: Directory path to save results (predictions mat object and thresholds npy object).
:param test_type: Test type variable. Variable used in the name of thresholds and predictio files.
'''
model_context, model_body, emotic_model = models
cat_preds = np.zeros((num_images, 26))
cat_labels = np.zeros((num_images, 26))
cont_preds = np.zeros((num_images, 3))
cont_labels = np.zeros((num_images, 3))
with torch.no_grad():
model_context.to(device)
model_body.to(device)
emotic_model.to(device)
model_context.eval()
model_body.eval()
emotic_model.eval()
indx = 0
print ('starting testing')
for images_context, images_body, labels_cat, labels_cont in iter(data_loader):
images_context = images_context.to(device)
images_body = images_body.to(device)
pred_context = model_context(images_context)
pred_body = model_body(images_body)
pred_cat, pred_cont = emotic_model(pred_context, pred_body)
cat_preds[ indx : (indx + pred_cat.shape[0]), :] = pred_cat.to("cpu").data.numpy()
cat_labels[ indx : (indx + labels_cat.shape[0]), :] = labels_cat.to("cpu").data.numpy()
cont_preds[ indx : (indx + pred_cont.shape[0]), :] = pred_cont.to("cpu").data.numpy() * 10
cont_labels[ indx : (indx + labels_cont.shape[0]), :] = labels_cont.to("cpu").data.numpy() * 10
indx = indx + pred_cat.shape[0]
cat_preds = cat_preds.transpose()
cat_labels = cat_labels.transpose()
cont_preds = cont_preds.transpose()
cont_labels = cont_labels.transpose()
print ('completed testing')
# Mat files used for emotic testing (matlab script)
scipy.io.savemat(os.path.join(result_dir, '%s_cat_preds.mat' %(test_type)), mdict={'cat_preds':cat_preds})
scipy.io.savemat(os.path.join(result_dir, '%s_cat_labels.mat' %(test_type)), mdict={'cat_labels':cat_labels})
scipy.io.savemat(os.path.join(result_dir, '%s_cont_preds.mat' %(test_type)), mdict={'cont_preds':cont_preds})
scipy.io.savemat(os.path.join(result_dir, '%s_cont_labels.mat' %(test_type)), mdict={'cont_labels':cont_labels})
print ('saved mat files')
test_scikit_ap(cat_preds, cat_labels, ind2cat)
test_vad(cont_preds, cont_labels, ind2vad)
thresholds = get_thresholds(cat_preds, cat_labels)
np.save(os.path.join(result_dir, '%s_thresholds.npy' %(test_type)), thresholds)
print ('saved thresholds')
def test_emotic(result_path, model_path, ind2cat, ind2vad, context_norm, body_norm, args):
''' Prepare test data and test models on the same.
:param result_path: Directory path to save the results (val_predidictions mat object, val_thresholds npy object).
:param model_path: Directory path to load pretrained base models and save the models after training.
:param ind2cat: Dictionary converting integer index to categorical emotion.
:param ind2vad: Dictionary converting integer index to continuous emotion dimension (Valence, Arousal and Dominance).
:param context_norm: List containing mean and std values for context images.
:param body_norm: List containing mean and std values for body images.
:param args: Runtime arguments.
'''
# Prepare models
model_context = torch.load(os.path.join(model_path,'model_context1.pth'))
model_body = torch.load(os.path.join(model_path,'model_body1.pth'))
emotic_model = torch.load(os.path.join(model_path,'model_emotic1.pth'))
print ('Succesfully loaded models')
#Load data preprocessed npy files
test_context = np.load(os.path.join(args.data_path, 'test_context_arr.npy'))
test_body = np.load(os.path.join(args.data_path, 'test_body_arr.npy'))
test_cat = np.load(os.path.join(args.data_path, 'test_cat_arr.npy'))
test_cont = np.load(os.path.join(args.data_path, 'test_cont_arr.npy'))
print ('test ', 'context ', test_context.shape, 'body', test_body.shape, 'cat ', test_cat.shape, 'cont', test_cont.shape)
# Initialize Dataset and DataLoader
test_transform = transforms.Compose([transforms.ToPILImage(),transforms.ToTensor()])
test_dataset = Emotic_PreDataset(test_context, test_body, test_cat, test_cont, test_transform, context_norm, body_norm)
test_loader = DataLoader(test_dataset, args.batch_size, shuffle=False)
print ('test loader ', len(test_loader))
device = torch.device("cuda:%s" %(str(args.gpu)) if torch.cuda.is_available() else "cpu")
test_data([model_context, model_body, emotic_model], device, test_loader, ind2cat, ind2vad, len(test_dataset), result_dir=result_path, test_type='test')
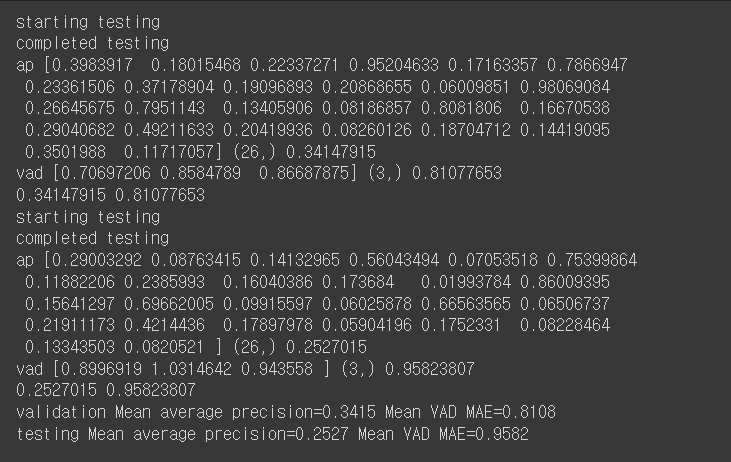
📌 Inference
간단하게 입력 이미지에 대한 VAD와 category만 보고 싶다면 아래의 명령어를 실행하면 된다.
inference_file : txt파일로 테스트하고 싶은 이미지나 영상의 경로명이 저장되어 있음
experiment_path : experiment directory의 경로명으로 학습된 모델이 저장되어 있음
python main.py --mode inference --inference_file proj/debug_exp/inference_file.txt --experiment_path proj/debug_exp입력 이미지에 사람 객체를 탐지해 bounding box를 그리고 추론한 VAD값과
category를 알고 싶다면 yolo_inference.py를 실행시키면 된다.
video_file: 입력 비디오 파일의 경로
python yolo_inference.py --experiment_path proj/debug_exp --video_file C:\emotic-master\assets\video_file.mp4🚨 피해자 경고 기준
아직 팀원들과 정확하게 피해자 예측 기준을 정하지 않았지만,
기술 검증 단계이기 때문에 우선 임의로 정했다.
부정적인 감정 중, 보이스피싱 피해자가 느낄 듯한 감정 리스트를 뽑아보았다.
- Anger
- Annoyance
- Disapproval
- Disquietment
- Doubt/Confusion
- Sadness
- Suffering
이 중 4개가 동시에 인식되면 보이스피싱 피해자로 예측, 경고메세지를 띄웠다.
내가 테스트한 파일이 비디오이기 때문에 해당 핵심 함수만 가져왔다.
yolo_inference 中
def yolo_video(video_file, result_path, model_path, context_norm, body_norm, ind2cat, ind2vad, args):
''' Perform inference on a video. First yolo model is used to obtain bounding boxes of persons in every frame.
After that the emotic model is used to obtain categoraical and continuous emotion predictions.
:param video_file: Path of video file.
:param result_path: Directory path to save the results (output video).
:param model_path: Directory path to load models and val_thresholds to perform inference.
:param context_norm: List containing mean and std values for context images.
:param body_norm: List containing mean and std values for body images.
:param ind2cat: Dictionary converting integer index to categorical emotion.
:param ind2vad: Dictionary converting integer index to continuous emotion dimension (Valence, Arousal and Dominance).
:param args: Runtime arguments.
'''
#보이스피싱 WARNING
warning_cat = [ 'Anger', 'Annoyance', 'Disapproval', 'Disquietment', 'Doubt/Confusion', 'Sadness', 'Suffering']
device = torch.device("cuda:%s" %(str(args.gpu)) if torch.cuda.is_available() else "cpu")
yolo = prepare_yolo(model_path)
yolo = yolo.to(device)
yolo.eval()
#모델 불러오기
thresholds = torch.FloatTensor(np.load(os.path.join(result_path, 'val_thresholds.npy'))).to(device)
model_context = torch.load(os.path.join(model_path,'model_context1.pth')).to(device)
model_body = torch.load(os.path.join(model_path,'model_body1.pth')).to(device)
emotic_model = torch.load(os.path.join(model_path,'model_emotic1.pth')).to(device)
model_context.eval()
model_body.eval()
emotic_model.eval()
models = [model_context, model_body, emotic_model]
#video 읽어오기
video_stream = cv2.VideoCapture(video_file)
writer = None
print ('Starting testing on video')
while True:
(grabbed, frame) = video_stream.read()
if not grabbed:
break
image_context = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
try:
warn_num = 0
bbox_yolo = get_bbox(yolo, device, image_context)
for pred_idx, pred_bbox in enumerate(bbox_yolo):
pred_cat, pred_cont = infer(context_norm, body_norm, ind2cat, ind2vad, device, thresholds, models, image_context=image_context, bbox=pred_bbox, to_print=False)
#VAD 값 출력
'''
write_text_vad = list()
for continuous in pred_cont:
write_text_vad.append(str('%.1f' %(continuous)))
write_text_vad = 'vad ' + ' '.join(write_text_vad)
image_context = cv2.rectangle(image_context, (pred_bbox[0], pred_bbox[1]),(pred_bbox[2] , pred_bbox[3]), (255, 0, 0), 3)
cv2.putText(image_context, write_text_vad, (pred_bbox[0], pred_bbox[1] - 5), cv2.FONT_HERSHEY_PLAIN, 3, (255, 255, 0), 2)
'''
#Emotion Categpry 출력
for i, emotion in enumerate(pred_cat):
cv2.putText(image_context, emotion, (pred_bbox[0], pred_bbox[1] + (i+1)*35), cv2.FONT_HERSHEY_PLAIN, 3, (255, 255, 0), 4)
if emotion in warning_cat:
warn_num= warn_num+1
## warn Category에 해당하는 감정이 4개 이상이면 WARNING 문구 띄우기
if(warn_num>3):
cv2.putText(image_context, " WARNING! WARNING! WARNING! ", (pred_bbox[0], pred_bbox[3]- 70), cv2.FONT_HERSHEY_PLAIN, 3, (255, 0, 0), 8)
except Exception:
pass
if writer is None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(os.path.join(result_path, 'result_vid.avi'), fourcc, 30, (image_context.shape[1], image_context.shape[0]), True)
writer.write(cv2.cvtColor(image_context, cv2.COLOR_RGB2BGR))
writer.release()
video_stream.release()
print ('Completed video')중간에 다줄 주석차리한 부분이 있는데, VAD값을 출력하는 부분을 지웠다.
우리는 실시간 영상 분석을 해야하기 때문에 연산 속도가 중요한데 생각보다 연산량이 많아서인지 속도가 오래걸려서 불필요한 연산은 제외할 것을 고려하고 있는데, vad의 정확도와 필요성에 대해 다시금 생각해보고 팀원들과 추가적인 의논이 필요할 것 같다.
결과물은 ./model/result에 영상은 result_vid.avi, 이미지는 img_0.jpg로 저장된다.
📌 Result
우리가 테스트한 영상에 대한 결과물은 아래와 같다!

보이스피싱 피해자 영상 데이터를 구하는 것은 어렵기 때문에 부득이하게ㅎㅎ...
한 팀원이 피해자 연기를 했다.
사실 나도 했는데 연기 부족으로 테스트 영상에서 탈락했다.ㅎㅅㅎ
의도대로 마스크를 쓰고 있음에도 여러 불안정한 감정들이 잘 탐지되었고
현재 보이스피싱 피해자로 예측되는 조건에 해당하면 WARNING-경고 메세지도 잘 뜨고 있음을 확인할 수 있다.
💜 Cell Phone Detection
실시간 객체 탐지에 용이한 YOLOv5 모델을 사용할 것이다.
관련 POC는 다른 팀원이 담당했다.
YOLOv5 Custom dataset 학습 및 Object detection
Reference
보이스피싱 계좌 더 묶는다…현금 직접 전달 때도 추진
피해금 창구 인출 의심 주요 유형
Context Based Emotion Recognition using EMOTIC Dataset
감정의 경계를 넘어


아주~ 잘 읽었어요. Outstanding.