
캐시 메모리
캐시(Cache)
자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 장소
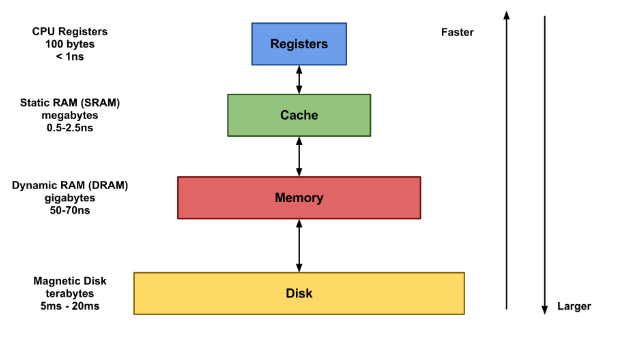
위와 같은 메모리 계층구조에서 확인할 수 있듯이
캐시는 저장 공간이 작고 비용이 비싸지만 성능이 빠르다
캐시의 주요 목적은 더 느린 기본 스토리지 계층에 엑세스해야 하는 필요를 줄임으로써 데이터 검색 성능을 높이는 것!
✅ 캐시 데이터는 일반적으로 램(RAM)처럼 빠르게 엑세스할 수 있는 하드웨어에 저장된다.
소프트웨어 구성 요소와 함께 사용될 수도 있음!
✅ 속도를 위해 용량을 절충하는 캐시는 일반적으로 데이터의 하위 집단을 일시적으로 저장한다.
보통 완전하고 영구적인 데이터가 있는 데이터 베이스와 대조적!!
따라서 다음과 같은 경우에 사용을 고려하면 좋다.
- 접근 시간에 비해 원래 데이터를 접근하는 시간이 오래걸리는 경우 (서버의 균일한 API 데이터)
- 반복적으로 동일한 결과를 돌려주는 경우 (이미지/썸네일)
캐시 적중률(Hit Rate)
캐시 적중(Cache Hit), 캐시 누락(Cache Miss)
캐시 적중이란 캐시에서 파일이 요청되고 캐시가 해당 요청을 이행할 수 있을 때 발생함!
Ex)
사용자가 피아노를 연주하는 고양이 사진을 표시해야 하는 웹 페이지를 방문하는 경우,
브라우저에서는 이 사진에 대한 요청을 웹페이지의 CDN(콘텐츠 전송 네트워크)에 보낼 수 있다.
내가 몰라서 정리하는CDN이란..
사용자가 물리적으로 위치한 곳으로 콘텐츠를 더 빠르게 전달하기 위해 함께 작동하는 연결된 캐싱 서버의 글로벌 네트워크
▶️ CDN의 스토리지에 그림 사본이 있는 경우 요청은 캐시 적중으로 이어지고 그림이 브라우저로 전송됨.
▶️ 반대로 현재 CDN 캐시에 그림 사본이 없으면, 캐시 누락이 발생하고
요청은 원본 서버로 전달된다!
CDN서버는 원본 서버가 응답하면 사진을 캐시하므로 추가요청으로 인해 캐시 적중이 발생한다.
캐시 적중률이란?
수신한 요청 수와 비교하여 캐시가 성공적으로 채울 수 있는 콘텐츠 요청 수를 측정한 것

캐시 적중률이 높다 = CDN이 효과적이다 ?
캐시 적중률 != CDN 성능
다른 요소들도 CDN의 효과를 평가하는데 아주 중요하다.
예를 들어, 콘텐츠가 제공되는 위치도 중요함.
이상적으로 CDN은 최종 사용자와 가장 가까운 CDN 서버의 콘텐츠를 제공
만약 그렇지 않으면 CDN의 성능이 최적이 아님
캐싱은 CDN이 하는 일의 중요한 부분이지만,
주요 목적은 일반적으로 웹 자산을 더 빠르고 안정적으로 만드는 것이다.
다양한 성능 메트릭이 CDN이 웹 앱/웹 사이트의 속도를 높이는데 얼마나 도움이 되었는지 측정하는데 도움이 된다.
캐시의 지역성 (시간적, 공간적)
✅ 캐시가 효율적으로 작동하기 위해서는 캐시의 적중률을 극대화 시켜야 함
즉, 캐시에 저장할 데이터가 지역성을 가져야 함
여기서 지역성이란?
기억장치 내의 정보를 균등하게 엑세스하는 것이 아닌,
어느 한 순간에 특정 부분을 집중적으로 참조하는 특성!
시간적 지역성
➡️ 최근에 참조된 데이터가 곧 다시 참조되는 특성
- 메모리상의 같은 주소에 여러 차례 읽기 쓰기를 수행하는 경우,
상대적으로 작은 크기의 캐시를 사용해도 효율성을 꾀할 수 있다!
공간적 지역성
➡️ 최근에 참조된 데이터와 인접한 데이터가 참조될 가능성이 높은 특성
- CPU 캐시나 디스크 캐시의 경우, 한 메모리 주소에 접근할 때 그 주소 뿐만 아니라 해당 블록을 전부 캐시에서 가져오게 된다.
- 이때 메모리 주소를 오름차순이나 내림차순으로 접근하면!
캐시에 이미 저장된 같은 블록의 데이터를 접근하게 되므로 캐시의 효율성이 크게 향상됨!!
가상 메모리
등장 배경
일반적으로 한 시스템의 여러 프로세스들은 CPU, 메인 메모리를 공유한다.
그런데 여기서 메모리가 여유가 없이 지나치게 많은 요구에 의해 오염될 경우, 프로그램의 논리와 무관하게 오류가 난다.
예를 들어,
A팀, B팀, C팀이 강당에 모여있다고 하자.
A,B,C팀 인원이 지나치게 많아진 나머지 C팀 인원 일부가 인파에 몰려 A팀으로 가버리고, A팀도 덩달아 B팀으로 가버리는 중구난방, 흡사 시장통과 같은 상황을 생각하면 된다.
당연히 서로 섞여버렸기 때문에 A팀 조장이 "A팀 18번!"을 불렀을 때 대답이 없거나(해당 메모리의 주소 호출 불가)
또는 대답을 하더라도 얼떨결에 A팀의 18번 자리에 서있는 C팀의 18번이 대답을(잘못된 메모리 참조) 하게 되는 것이다.
➡️ 이를 방지하기 위한 기술이 가상메모리
✅ 가상 메모리 기법은 애플리케이션을 실행하는 데 얼마나 많은 메모리가 필요한지에 집중하지 않고, 대신 애플리케이션을 실행하는 데 최소한 얼마만큼의 메모리가 필요한가에 집중함!
- 이렇게 어플리케이션의 일부분만 메모리에 올려진다면,
메모리에 올라가지 않는 나머지는 어디에 위치할까 ➡️ 보조 기억장치인 디스크 - 가상 메모리의 핵심은 보조 기억장치!
가상메모리란?
메모리가 실제 메모리보다 많아 보이게 하는 기술
어떤 프로세스가 실행될 때 메모리에 해당 프로세스 전체가 올라가지 않더라도 실행이 가능하다는 점에 착안하여 고안됨
- 애플리케이션이 실행될 때,
실행에 필요한 일부분만 메모리에 올라가며 애플리케이션의 나머지는 디스크에 남음.
➡️ 디스크가 RAM의 보조 기억장치(backing store)처럼 작동!
결국 빠르고 작은 기억장치(RAM)을 크고 느린 기억장치(디스크)와 병합하여, 하나의 크고 빠른 기억장치(가상 메모리)처럼 동작하게 하는 것
📌 가상 메모리를 구현하기 위해서는 컴퓨터가 특수 메모리 관리 하드웨어 = MMU를 갖추고 있어야 함
MMU
- 가상주소를 물리주소로 변환하고, 메모리를 보호하는 기능 수행
- MMU를 사용하게 되면, CPU가 각 메모리에 접근하기 이전에 메모리 주소 번역 작업이 수행됨.
- 그러나 메모리를 일일이 가상 주소에서 물리적 주소로 번역하게 되면 작업 부하가 너무 높아지므로, MMU는 RAM을 여러 부분(pages)로 나누어 각 페이지를 하나의 독립된 항목으로 처리
- 페이지 및 주소 번역 정보를 기억하는 작업이 가상 메모리를 구현하는 데 있어 결정적인 절차임.
메모리 단편화(Memory Fragmentation)
RAM에서 메모리의 공간이 작은 조각으로 나뉘어져
사용가능한 메모리가 충분히 존재하지만!
할당(사용)이 불가능한 상태
내부 단편화 (Internal Fragmentation)
메모리를 할당할 때 프로세스가 필요한 양보다 더 큰 메모리가 할당되어서 프로세스에서 사용하는 메모리 공간이 낭비 되는 상황
▶️ 예를 들어, 메모장을 켰는데 OS가 4kb를 할당해줌
그런데 사실상 1kb만큼만 사용하고 있다면 내부 단편화가 3kb만큼 생긴 것
외부 단편화 (External Fragmentation)
메모리가 할당되고 해제되는 작업이 반복될 때 작은 메모리가 중간중간 존재하게 되는데.
이 때 중간중간에 생긴 사용하지 않는 메모리가 많이 존재해서 총 메모리 공간은 충분하지만 실제로 할당할 수 없는 상황
▶️ 예를 들어, 메모리 처음 주소에 8mb짜리 프로세스가 할당되었고
바로 이어서 16mb짜리 프로세스가 할당되었다고 하자.
이때 8mb짜리 프로세스를 종료시키면 메모리 처음 주소부터 8mb만큼 공간이 생긴다.
이런 식으로 계속해서 빈 메모리가 쌓이는데
이러한 빈 메모리의 공간중에 제일 큰 빈 메모리가 8mb라고 한다면 9mb짜리 프로세스를 할당을 해야할 때
마땅한 공간은 없지만 전체적으로 메모리 여유는 있을 때 외부단편화가 생겼다고 한다.
페이징 기법 (Paging)
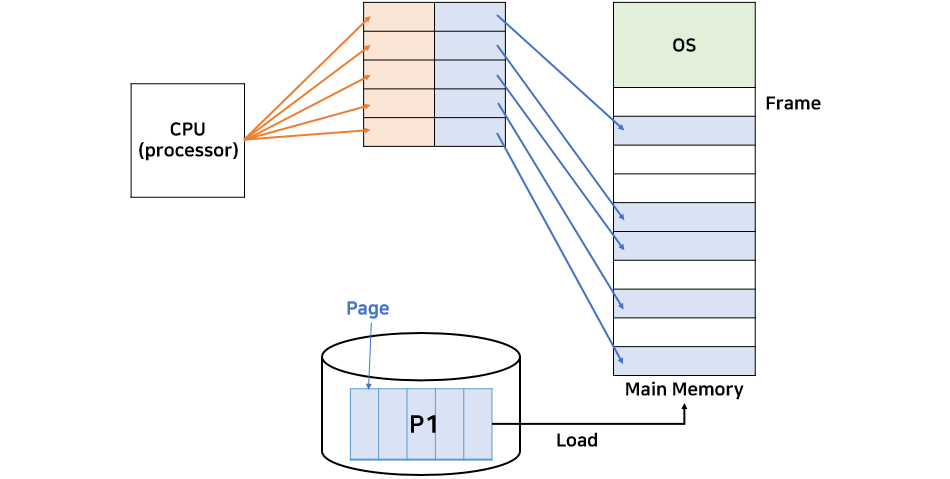
- 프로세스의 주소 공간을 고정된 사이즈의 페이지 단위로 나누어 물리적 메모리에 불연속적으로 할당하는 방식
- 메모리는 Frame이라는 고정크기로 분할되고, 프로세스는 Page라는 고정크기로 분할됨
- 페이지와 프레임은 크기가 같음
- 페이지와 프레임을 대응시키는 page mapping 과정이 필요하여 paging table을 생성해야 함
- 연속적이지 않은 공간도 활용할 수 있기 때문에 외부 단편화 문제 해결
- 페이지 테이블에는 각 페이지 번호와 해당 페이지가 할당된 프레임의 시작 물리 주소를 저장
‼️ 프로세스의 크기가 페이지 크기의 배수가 아닐 경우 마지막 페이지에 내부 단편화가 발생하고 페이지의 크기가 클수록 내부 단편화가 커질 수 있다.
❗️ 페이지 단위를 작게 하면 내부 단편화 문제도 해결할 수 있겠지만,
page mapping 과정이 많아지므로 효율이 떨어짐
세그멘테이션 기법 (Segmentation)
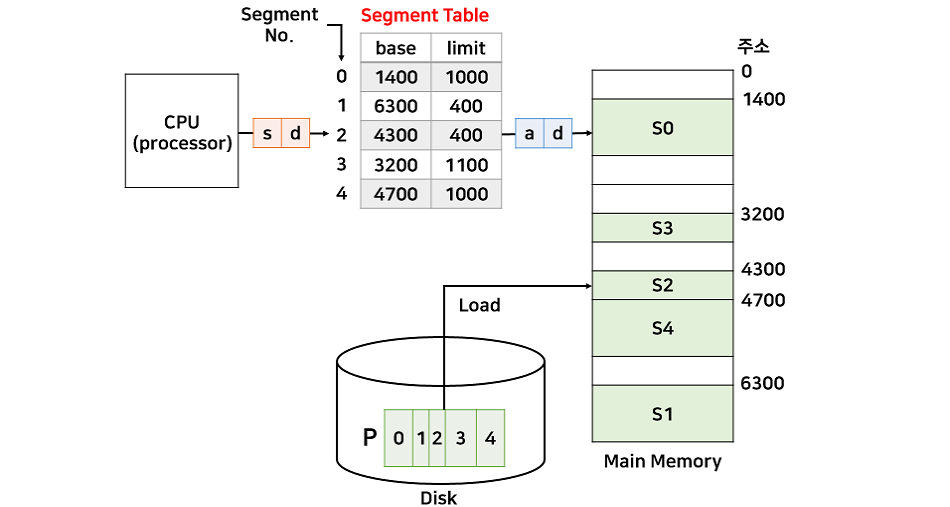
- 프로세스를 서로 크기가 다른 논리적인 블록 단위인 세그먼트(Segment)로 분할하여 메모리에 할당
- 각 세그먼트는 연속적인 공간에 저장
- 세그먼트들의 크기가 서로 다르기 때문에 프로세스가 메모리에 적재될 때 빈 공간을 찾아 할당하는 기법
- 페이징과 마찬가지로 mapping을 위한 segment table 필요
‼️ 프로세스가 필요한 메모리 공간만큼 메모리를 할당해주기 때문에 내부 단편화 문제는 발생하지 않지만, 중간에 메모리를 해제하면 생기는 외부 단편화 문제가 발생할 수 있다!
Reference
https://aws.amazon.com/ko/caching/
https://mangkyu.tistory.com/69
https://www.cloudflare.com/ko-kr/learning/cdn/what-is-a-cache-hit-ratio/
https://namu.wiki/w/가상%20메모리
https://jeong-pro.tistory.com/91
