Comma Seperate Values (CSV)
- 필드를 쉼표(,)로 구분한 텍스트 파일
- 엑셀 양식의 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식
- 탭(TSV), 빈칸(SSV) 등으로 구분해서 만들기도 함
- 통칭하여 character-separated values (CSV)라고도 부름
- 엑셀에서는 ‘다른 이름 저장’ 기능으로 사용 가능
엑셀로 CSV 파일 만들기
-
파일 다운로드
-
파일 열기
-
파일 → 다른 이름으로 저장 → CSV(쉼표로 분리) 선택 후 → 파일명 입력
-
엑셀 종료 후 notepad로 열어보기

파이썬으로 CSV 파일 다루기
- Text 파일 형태로 데이터 처리 예제
- 예제 데이터: customer.csv
CSV 읽기
line_counter = 0 # 파일의 총 줄 수를 세는 변수
data_header = [] # data의 필드값을 저장하는 list
customer_list = [] # customer 개별 list를 저장하는 list
with open("customers.csv") as customer_data: # customer.csv 파일을 customer_data 객체에 저장
while True:
data = customer_data.readline() # customer.csv에 한 줄씩 data 변수에 저장
if not data: break # 데이터가 없을 때 loop 종료
if line_counter == 0: # 첫 번째 데이터는 데이터의 필드
data_header = data.split(".") # 데이터 필드는 data_header list에 저장, 데이터 저장시 ","로 분리
else:
customer_list.append(data.split(",")) # 일반 데이터는 customer_list 객체에 저장, 데이터 저장시 ","로 분리
line_counter += 1
print("Header :\t", data_header) # 데이터 필드값 출력
for i in range(10): # 데이터 출력 (샘플 10개만)
print("Data", i, ":\t\t", customer_list[i])
print(len(customer_list)) # 전체 데이터 크기 출력- 일반적인 textfile을 처리하듯 파일을 읽어온 후, 한 줄씩 데이터를 처리
CSV 쓰기
line_counter = 0 # 파일의 총 줄 수를 세는 변수
data_header = [] # data의 필드값을 저장하는 list
employee = []
customer_USA_only_list = [] # customer 개별 list를 저장하는 list
customer = None
with open("customers.csv", "r") as customer_data: # customer.csv 파일을 customer_data 객체에 저장
while True:
data = customer_data.readline() # customer.csv에 한 줄씩 data 변수에 저장
if not data: break # 데이터가 없을 때 loop 종료
if line_counter == 0: # 첫 번째 데이터는 데이터의 필드
data_header = data.split(".") # 데이터 필드는 data_header list에 저장, 데이터 저장시 ","로 분리
else:
customer = data.split(",")
if customer[10].upper() == "USA": # customer 데이터의 offset 10번째 필드값
customer_USA_only_list.append(customer) # country 필드가 "USA"인 것만
line_counter += 1
print("Header :\t", data_header) # 데이터 필드값 출력
for i in range(10): # 데이터 출력 (샘플 10개만)
print("Data", i, ":\t\t", customer_USA_only_list[i])
print(len(customer_USA_only_list)) # 전체 데이터 크기 출력
with open("customers_USA_only.csv", "w") as customer_USA_only_csv:
for customer in customer_USA_only_list:
customer_USA_only_csv.write(",".join(customer).strip('\n') + '\n')csv 객체로 CSV 처리
import csv
goyang_data = []
header = []
row_num = 0
with open("korea_foot_traffic_data.csv", "r", encoding="utf8") as p_file:
csv_data = csv.reader(p_file) # csv 객체 이용해 csv_data 읽기
for row in csv_data: # 읽어온 데이터 한 줄씩 처리
if row_num == 0:
header = row # 첫 번째 줄은 데이터 필드로 따로 저장
location = row[7] # '행정구역' 필드 데이터 추출, 한글 처리로 유니코드 데이터를 utf8로 변환
if location.find(u"고양시") != -1:
goyang_data.append(row) # '행정구역' 데이터에 성남시가 들어가 있으면 seoungnam_data list에 추가
row_num += 1
with open("goyang_foot_traffic_data.csv", "w", encoding="utf8") as g_p_file:
writer = csv.writer(g_p_file, delimiter='\t', quotechar="'", quoting=csv.QUOTE_ALL)
# csv.writer를 사용해서 csv 파일 만들기
# delimiter: 필드 구분자, quotechar: 필드의 각 데이터를 묶는 문자, quoting: 묶는 범위
writer.writerow(header)
for row in goyang_data:
writer.writerow(row)- Text 파일 형태로 데이터 처리시 문장 내 존재하는 ‘
,’ 등에 대해 전처리 필요 - 파이썬은 간단히 CSV 파일을 처리하기 위해
csv객체를 제공 - 예제 데이터: korea_foot_traffic_data.csv
- 국내 주요 상권의 유동인구 현황 정보
- 한글로 되어 있기 때문에 한글 처리 필요
웹 (Web)
- World Wide Web (WWW), 줄여서 웹이라고 부름
- 인터넷 공간의 정식 명칭
- 팀 버너스리에 의해 1989년 처음 제안되었으며, 원래는 물리학자들 간의 정보 교환을 위해 사용됨
- 데이터 송수신을 위한 HTTP 프로토콜 사용
- 데이터를 표시하기 위해 HTML 형식 사용
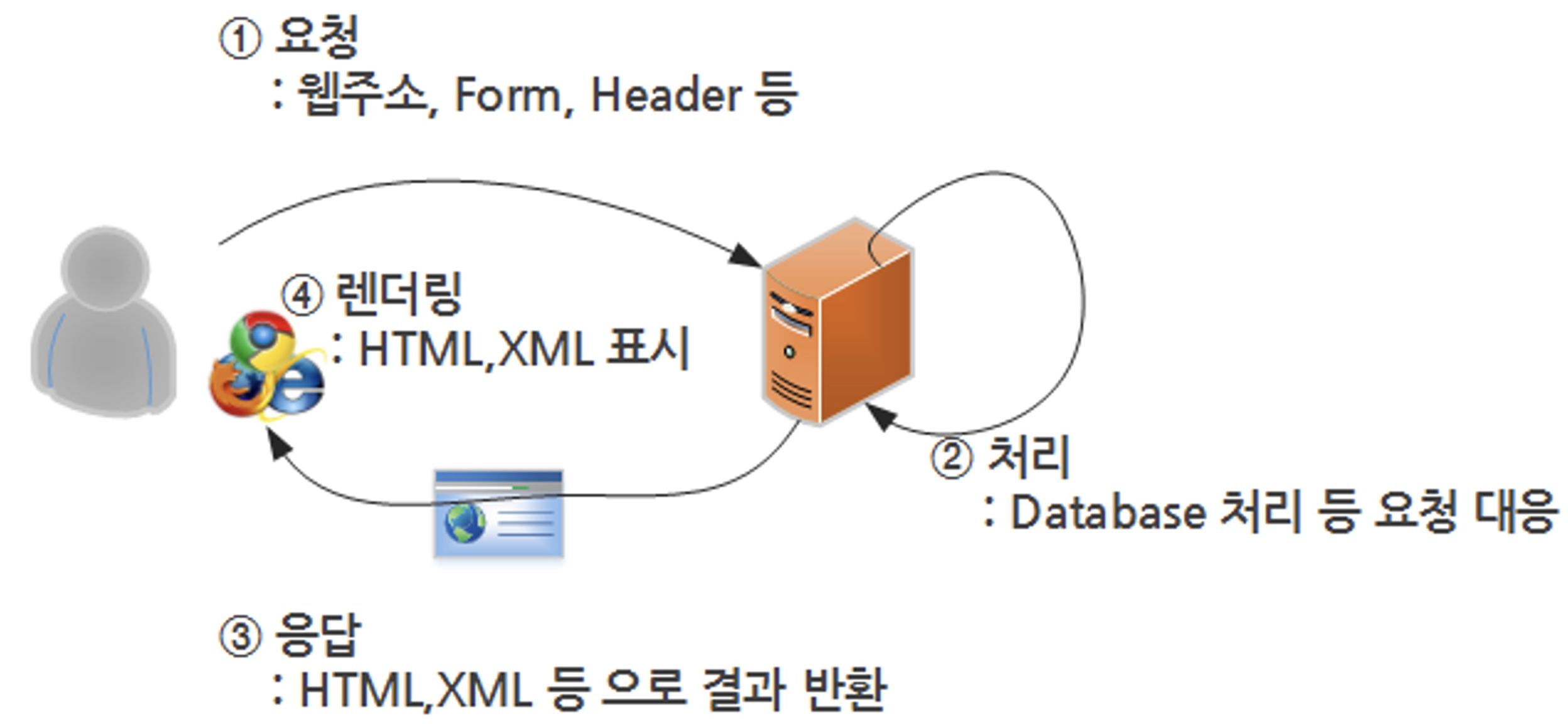
웹의 동작 방식
HTML (Hyper Text Markup Language)
- 웹 상의 정보를 구조적으로 표현하기 위한 언어
- 제목, 단락, 링크 등 요소의 표시를 위해 태그(tag)를 사용
- 모든 요소들은 꺾쇠 괄호 안에 둘러 쌓여 있음
<title> Hello, World </title>→ 제목 요소, 값은 Hello, World
- 모든 HTML은 트리 모양의 포함 관계에 있음
- 일반적으로 웹 페이지의 HTML 소스 파일은 컴퓨터가 다운로드 받은 후 웹 브라우저가 해석 및 표시
- 예시
<!doctype html> <html> <head> <title> Hello HTML </title> </head> <body> <p>Hello WOrld!</p> </body> </html>- HTML 구조
<html>-<head>-<title>-<body>-<p>
- Element와 attribute value로 이루어짐
<tag attribute1=”att_value1” attrigute2=”att_value1”> 보이는 내용(Value) </tag>
- HTML 구조
- 웹을 알아야 하는 이유
- 정보의 보고, 많은 데이터가 웹을 통해 공유됨
- HTML도 일종의 프로그램이며, 페이지 생성 규칙이 있음
- 규칙을 분석해 데이터 추출 가능
- 추출된 데이터를 바탕으로 다양한 분석이 가능
정규식 (regular expression)
- 정규 표현식
- regexp 또는 regex 등으로 불림
- 복잡한 문자열 패턴을 정의하는 문자 표현 공식
- 특정한 규칙을 가진 문자열 집합 추출
- 010-0000-0000 →
^\d{3}\-\d{4}\-\d{4}$ - 203.252.101.40 →
^\d{1, 3}\.\d{1, 3}\.\d{1, 3}\.\d{1, 3}$ - 이메일:
^[a-zA-Z0-9]+@[a-zA-Z0-9]+$또는^[_0-9a-zA-Z-]+@[0-9a-zA-Z-]+(.[_0-9a-zA-Z-]+)*$ - 휴대폰:
^01(?:0|1|[6-9])-(?:\d{3}|\d{4})-\d{4}$ - 주민번호:
\d{6} \- [1-4]\d{6} - IP주소:
([0-9]{1,3}) \. ([0-9]{1,3} \. ([0-9]{1,3}) \. ([0-9]{1,3})
- 010-0000-0000 →
HTML Parsing을 위한 정규식
정규표현식(Regular Expression)을 소개합니다.
- 주민번호, 전화번호, 도서 ISBN 등 형식이 있는 문자열을 원본 문자열로부터 추출
- HTML 역시 tag를 사용한 일정한 형식이 존재해 정규식으로 추출이 용이함
- 문법 자체가 매우 방대해 스스로 찾아서 하는 공부가 필요
- 필요한 것들은 인터넷 검색으로 충분히 탐색 가능
- 기본적인 것을 공부해서 넓게 적용하는 것이 중요
- 정규식 연습장 RegExr: Learn, Build, & Test RegEx
- 테스트하고 싶은 문서를 text란에 삽입
- 정규식을 사용해서 찾아보기
정규식 기본 문법
- 문자 클래스
[]:[와]사이의 문자들과 매치라는 의미- 예:
[abc]← 해당 글자에 a, b, c 중 하나가 있음- “a”, “before”, “deep”, “dud”, “sunset” 등 모두 들어갈 수 있음
- 예:
- “
-”를 이용해 범위를 지정할 수 있음- 예:
[a-zA-Z]→ 알파벳 전체,[0-9]→ 숫자 전체
- 예:
- 메타 문자
- 정규식의 핵심
- 정규식 표현을 위해 원래 의미와는 다른 용도로 사용되는 문자들
.^$*+?{}[]\|()
.: 줄바꿈 문자인\n을 제외한 모든 문자와 매치*: 앞에 있는 글자가 반복해서 나올 수 있음+: 앞에 있는 글자가 최소 1회 이상 반복{m.n}: 반복 횟수를 지정?: 반복 횟수가 1회|: or
정규식 추출 연습
- 정규식 연습장으로 이동
- 구글 USPTO Bulk Download 데이터페이지 소스 보기 클릭
- 소스 전체 복사 후 정규식 연습장 페이지에 붙여 넣기
- 상단 expression 부분 수정해가며 ‘zip’으로 끝나는 파일명만 추출
- 정답
- Expression에 (http)(.+)(zip)을 입력
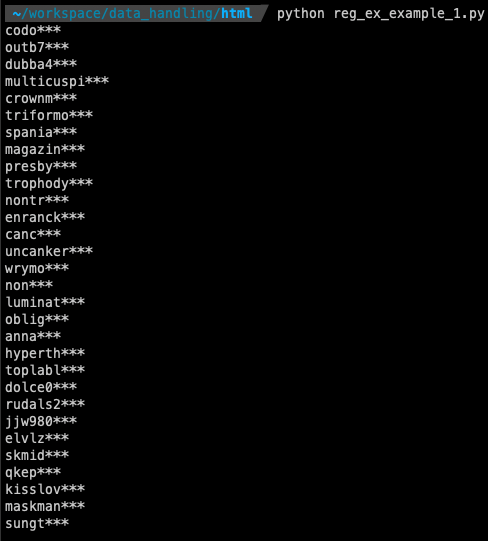
예제 1: 아이템 매니아 이벤트 당첨자 아이디 추출
import re
import urllib.request
url = "http://goo.gl/U7mSQl"
html = urllib.request.urlopen(url)
html_contents = str(html.read())
# print(html_contents)
id_results = re.findall(r"([A-Za-z0-9]+\*\*\*)", html_contents)
for result in id_results:
print(result)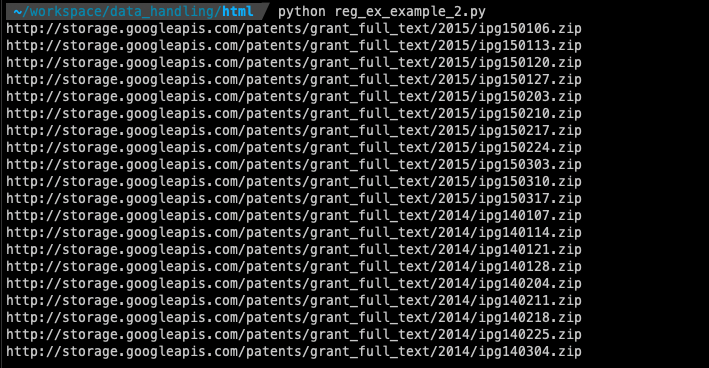
예제 2: 구글 USPTO-Patents-Grants-Text 페이지 URL 추출
import re
import urllib.request
url = "http://www.google.com/googlebooks/uspto-patents-grants-text.html"
html = urllib.request.urlopen(url)
html_contents = str(html.read().decode("utf8"))
url_list = re.findall(r"(http)(.+)(zip)", html_contents)
for url in url_list:
print("".join(url))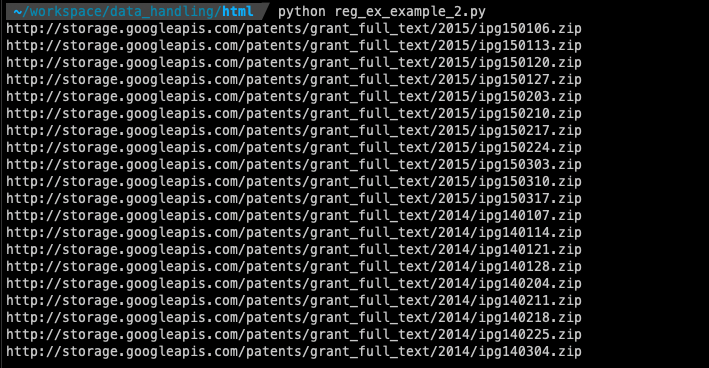
예제 3: 네이버 주식 삼성전자 주가 데이터 추출

<dl class=”blind”> ~~~~</dl>에 있는(\<dl class=\”blind\”\>)([\s\S]+?)(\<\/dl\>)→<dl class="blind">에서 시작해서 / 사이에 아무 글자나 있고 /</dl>로 끝내기
<dd> ~~~~ </dd>정보를 추출하면 됨(\<dd\>)([\s\S]+?)(\<\/dd\>)→<dd>에서 시작해서 / 사이에 아무 글자나 있고 /</dd>로 끝내기
import re
import urllib.request
url = "http://finance.naver.com/item/main.nhn?code=005930"
html = urllib.request.urlopen(url)
html_contents = str(html.read().decode("ms949"))
stock_results = re.findall("(\<dl class=\"blind\"\>)([\s\S]+?)(\<\/dl\>)", html_contents)
samsung_stock = stock_results[0] # 두 tuple 값 중 첫 번째 패턴
samsung_index = samsung_stock[1] # 세 tuple 값 중 두 번째 값
index_list = re.findall("(\<dd\>)([\s\S]+?)(\<\/dd\>)", samsung_index)
print(index_list)
for index in index_list:
print(index[1])XML (eXtensible Markup Language)
- 데이터 구조와 의미를 설명하는 tag(MarkUp)를 사용하여 표시하는 언어
- Tag와 Tag 사이 값이 표시되고, 구조적인 정보를 표현할 수 있음
- HTML과 문법이 거의 유사하며, 대표적인 데이터 저장 방식 중 하나
- 정보의 구조에 대한 정보인 스키마와 DTD 등으로 정보에 대한 정보(메타정보)가 표현되며, 용도에 따라 다양한 형태로 변경이 가능
- 컴퓨터(예: PC ↔ 스마트폰) 간 정보를 주고받기에 매우 유용한 저장 방식으로 사용되고 있음
- 예시
<?xml version="1.0"?> <고양이> <이름>나비</이름> <품종>샴</품종> <나이>6</나이> <중성화>예</중성화> <발톱 제거>아니요</발톱 제거> <등록 번호>Izz138bod</등록 번호> <소유자>이강주</소유자> </고양이>
XML 형태로 만들어보기
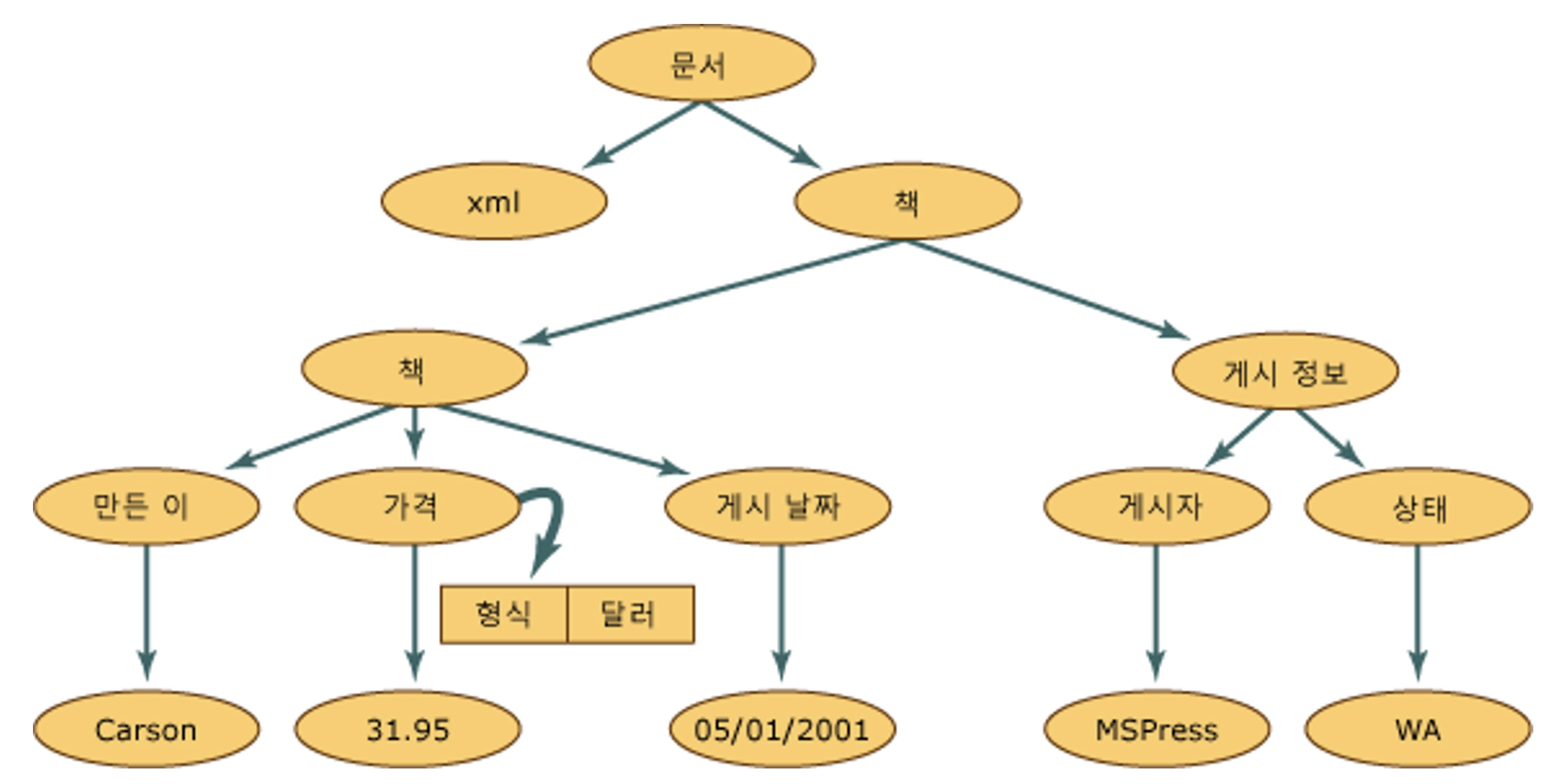
<?xml version="1.0"?>
<books>
<book>
<author>Carson</author>
<price format="dollar">31.95</price>
<pubdate>05/01/2001</pubdate>
</book>
<pubinfo>
<publisher>MSPress</publisher>
<state>WA</state>
</pubinfo>
</books>XML Parsing in Python
- XML도 HTML과 같이 구조적 MarkUp 언어
- 정규표현식으로 parsing 가능
- 그러나 좀 더 손쉬운 도구들이 개발되어 있음
- 가장 많이 쓰이는 parser가 바로
beautifulsoup
BeautifulSoup
- HTML, XML 등 MarkUp 언어 스크래핑(scraping)을 위한 대표적 도구: Beautiful Soup
lxml과html5lib과 같은 parser 사용- 속도는 상대적으로 느리지만 간편히 사용 가능
예제 1: 책 정보 추출
<?xml version="1.0"?>
<books>
<book>
<author>Carson</author>
<price format="dollar">31.95</price>
<pubdate>05/01/2001</pubdate>
</book>
<pubinfo>
<publisher>MSPress</publisher>
<state>WA</state>
</pubinfo>
<book>
<author>Sungchul</author>
<price format="dollar">29.95</price>
<pubdate>05/01/2012</pubdate>
</book>
<pubinfo>
<publisher>Gachon</publisher>
<state>SeoungNam</state>
</pubinfo>
</books>from bs4 import BeautifulSoup as bs
with open("books.xml", "r", encoding="utf8") as books_file:
books_xml = books_file.read() # file을 string으로 불러오기
# xml 모듈을 이용해 데이터 분석
soup = bs(books_xml, "lxml")
# author가 들어간 모든 element 추출
for book_info in soup.find_all("author"):
print(book_info)
print(book_info.get_text())예제 2: USPTO 특허 정보 추출
# invention-title에 대한 정보만 찾기
import urllib.request
from bs4 import BeautifulSoup as bs
with open("US08621662-20140107.xml", "r", encoding="utf8") as patent_xml:
xml = patent_xml.read() # file을 string으로 읽어오기
soup = bs(xml, "xml")
# print(soup)
# invention-title tag 찾기
invention_title_tag = soup.find("invention-title")
# print(invention_title_tag)
print(invention_title_tag.get_text())
# 출원번호, 출원일, 등록번호, 등록일, 상태, 특허명 추출
import urllib.request
from bs4 import BeautifulSoup as bs
with open("US08621662-20140107.xml", "r", encoding="utf8") as patent_xml:
xml = patent_xml.read() # file을 string으로 읽어오기
soup = bs(xml, "xml")
invention_title_tag = soup.find("invention-title")
# print(invention_title_tag)
publication_reference_tag = soup.find("publication-reference")
p_document_id_tag = publication_reference_tag.find("document-id")
p_country = p_document_id_tag.find("country").get_text()
p_doc_number = p_document_id_tag.find("doc-number").get_text()
p_kind = p_document_id_tag.find("kind").get_text()
p_date = p_document_id_tag.find("date").get_text()
print(publication_reference_tag)
print()
print(p_document_id_tag)
print()
print(p_doc_number, p_kind, p_date)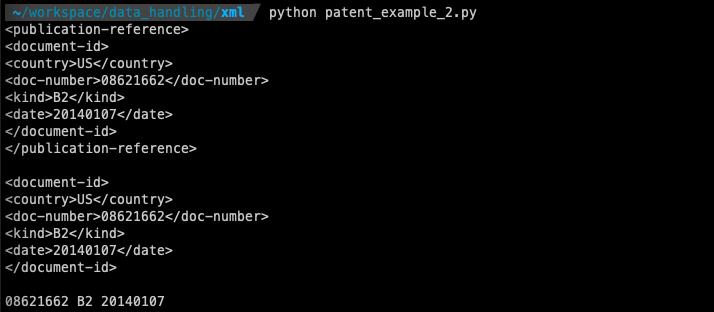
[연습] ipa110106.xml 분석
- 11년 첫째 주에 나온 출원 특허를 모은 파일
- 개별 특허 시작은
<?xml version=”1.0”으로 시작 - 분할된 특허 문서로부터 특허의
등록번호,등록일자,출원 번호,출원 일자,상태,특허 제목을 추출해 CSV 파일로 만들기
JavaScript Object Notation (JSON)

- 원래 웹 언어인 JavaScript의 데이터 객체 표현 방식
- 간결성으로 기계/인간이 모두 이해하기 편함
- 데이터 용량이 적고, 코드로의 전환이 매우 쉬움
- 이로 인해 XML의 대체재로 많이 활용되고 있음
- XML
<?xml version="1.0" encoding="UTF- 8" ?> <employees> <name>Shyam</name> <email>shyamjaiswal@gmail.com</email> </employees> <employees> <name>Bob</name> <email>bob32@gmail.com</email> </employees> <employees> <name>Jai</name> <email>jai87@gmail.com</email> </employees> - JSON
{ "employees":[ {"name":"Shyam", "email":"shyamjaiswal@gmail.com"}, {"name":"Bob", "email":"bob32@gmail.com"}, {"name":"Jai", "email":"jai87@gmail.com"} ] }
- XML
- 이로 인해 XML의 대체재로 많이 활용되고 있음
JSON in Python
json모듈을 사용해 쉽게 파싱 및 저장 가능- 데이터 저장 및 읽기는 dict type과 상호 호환 가능
- 웹에서 제공하는 API는 대부분 정보 교환시 JSON 활용
- 페이스북, 트위터, 깃허브 등 거의 모든 사이트
- 각 사이트마다 Developer API 활용법을 찾아 사용
JSON 읽기
import json
with open("json_example.json", "r", encoding="utf8") as f:
contents = f.read()
json_data = json.loads(contents)
print(json_data["employees"])- 읽기는
loads()
JSON 쓰기
import json
dict_data = {"Name": "Zara", "Age": 7, "Class": "First"}
with open("data.json", "w") as f:
json.dump(dict_data, f)- 쓰기는
dump()
Twitter API 가져오기(나중에)
- 수업에서 안 다뤘음
- 나중에 해보기

J의 틀에 몸을 녹여 맞추는 P