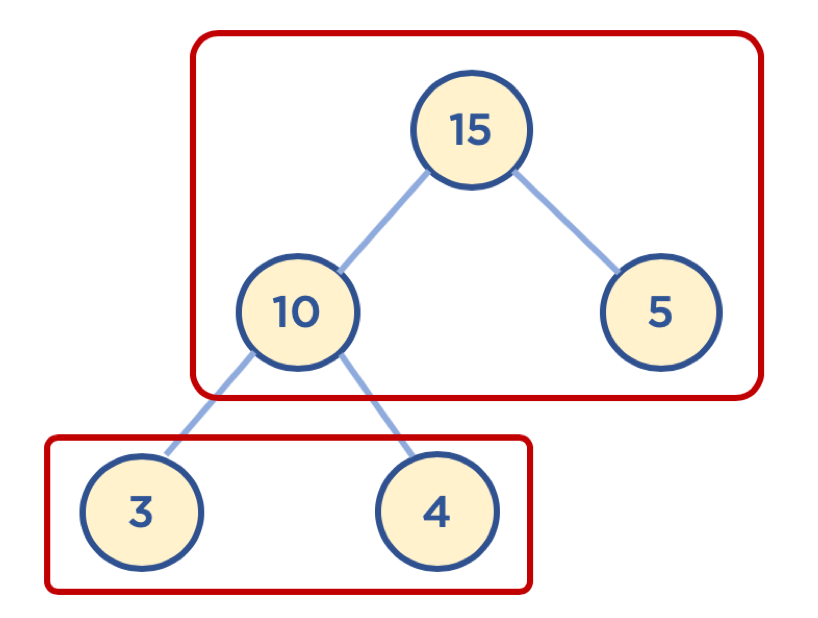
힙?
힙 이란, 데이터의 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree) 입니다. 완전 이진 트리는 새로운 노드를 추가할때 무조건 왼쪽 최하단에서 부터 순차적으로 노드를 추가하는 이진 트리입니다. (이진 트리는 부모 노드가 최대 2개의 자식만 가질수 있는 트리)
항상 왼쪽 하단에 새로운 데이터를 추가한 후, 부모 노드와 비교해서 새로 추가한 노드의 최종 위치를 찾아 줍니다.. Max Heap의 경우 부모 노드가 자신의 값보다 작으면 서로 위치를 바꿔줌으로써 root에는 항상 최대값이 유지 됩니다. Min Heap은 자신 보다 부모 노드가 크면 서로 바꿈으로써, root에 항상 최소값을 유지합니다.
이때, 완전 이진 트리는 무조건 노드를 최하단에 추가하기 때문에 데이터를 배열에 넣어도 부모와 자식간의 인덱스를 계산하기 편합니다.
(https://www.fun-coding.org/00_Images/completebinarytree.png)
힙 구현하기(파이썬)
class Heap:
def __init__(self, data):
self.heap_array = list()
self.heap_array.append(None)
self.heap_array.append(data)힙은 단순히 배열로 구현이 가능하기 때문에 배열로 선언해 줍니다. 선언 후, 첫번째 데이터를 넣을때, 나중에 부모와 자식 간의 인덱스 계산을 편하게 하기 위해 인덱스 0에는 None 값을 넣고, 인덱스 1부터 데이터를 넣기 시작합니다.
부모와 자식간의 인덱스 계산하기
- 1. 부모 노드 인덱스 == 자식 노드 인덱스 // 2
- 2. 왼쪽 자식 노드 인덱스 == 2 * 부모 노드 인덱스
- 3. 오른쪽 자식 노드 인덱스 == 2 * 부모 노드 인덱스 + 1
노드 추가하기
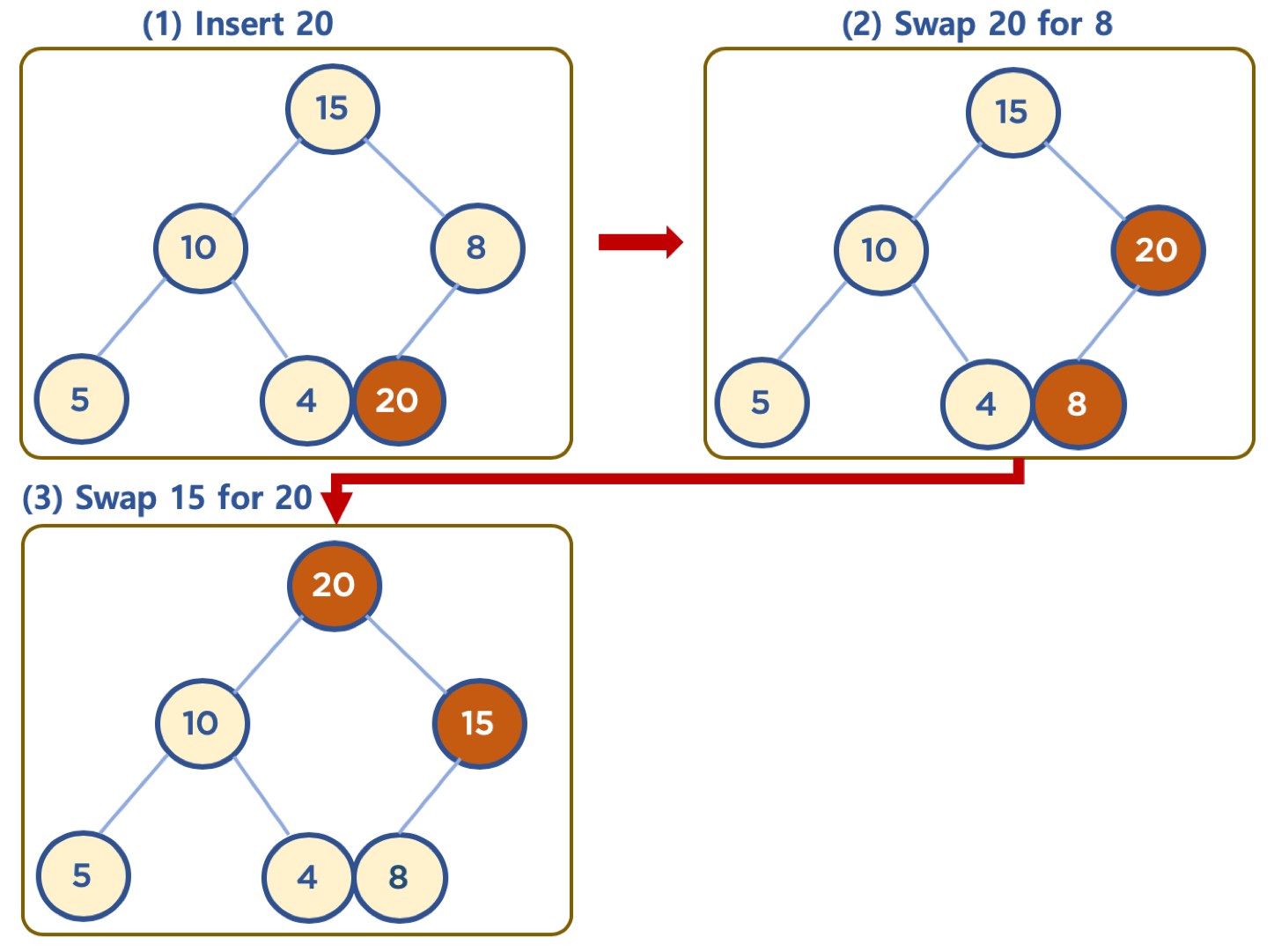
Max Heap 일때 새로운 노드를 추가하는 것을 보도록 하겠습니다.
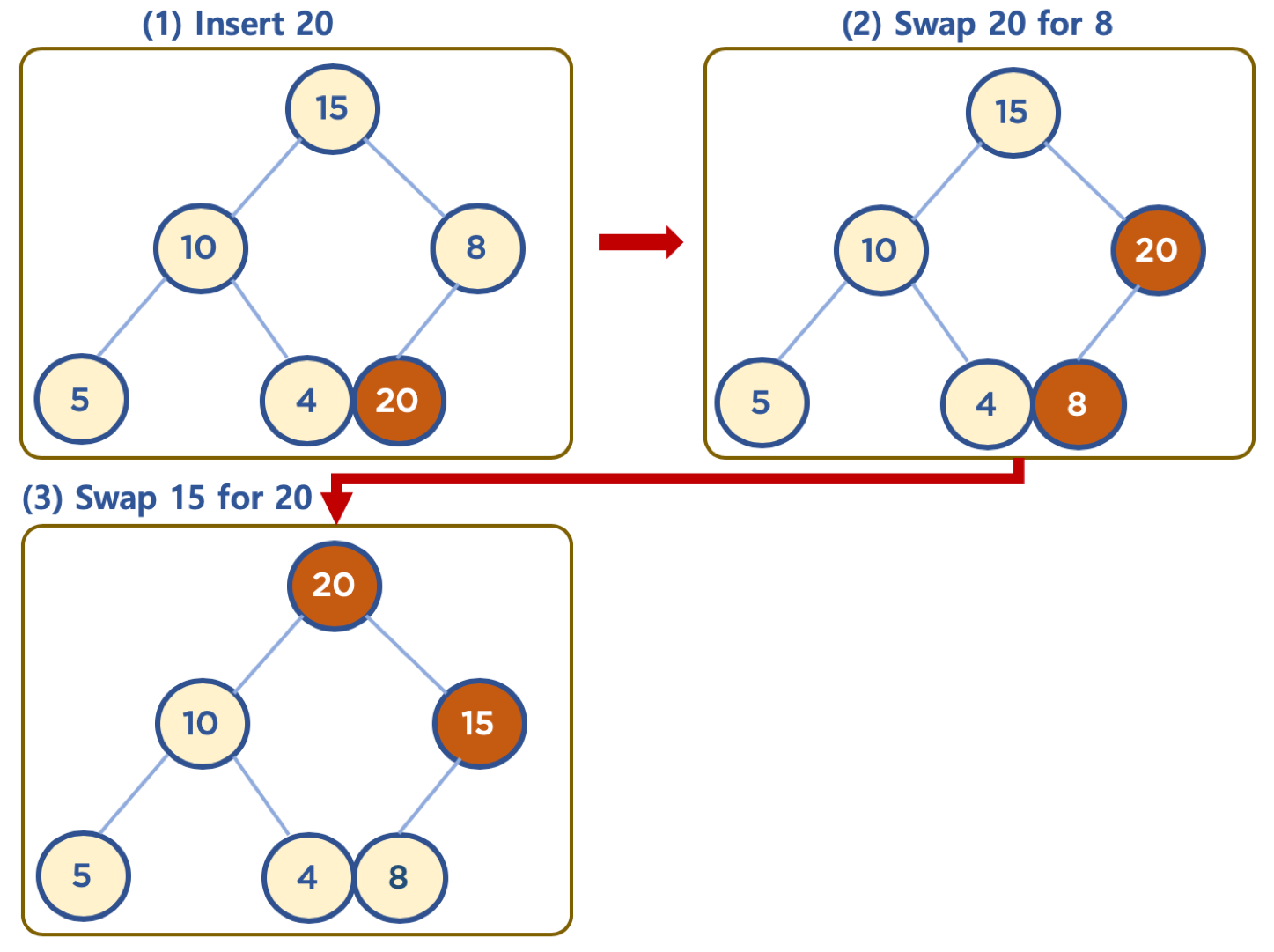
(https://www.fun-coding.org/00_Images/heap_insert.png)
사진에는 노드 20을 힙에 추가합니다. 이때, 노드 20은 먼저 맨 마지막 위치에 추가합니다. 추가한 후, 부모 노드와 비교해서, 부모 노드보가 값이 크면 부모 노드와 위치를 바꿔줍니다. 부모 노드가 자신보다 크거나, root 노드가 되었을 경우부터 비교를 멈추고, 새로 추가한 노드의 최종 위치가 정해집니다.
{kind=link}
{kind=link}
구현하기(파이썬)
def move_up(self, inserted_idx):
if inserted_idx <= 1: # 인덱스 값이 1이면 이미 root -> 부모 노드가 없으므로 메서드 탈출
return False
parent_idx = inserted_idx // 2
if self.heap_array[inserted_idx] > self.heap_array[parent_idx]: # 자신이 가진 값이 부모 노드의 값보다 클 경우
return True
else:
return False
def insert(self, data):
if len(self.heap_array) == 0:
self.heap_array.append(None)
self.heap_array.append(data)
return True
self.heap_array.append(data)
inserted_idx = len(self.heap_array) - 1 # 마지막 데이터의 인덱스 값 가져오기
while self.move_up(inserted_idx): # 추가된 데이터의 차리를 찾아주기
parent_idx = inserted_idx // 2 # 부모 노드의 인덱스 == 자신의 인덱스 // 2
self.heap_array[inserted_idx], self.heap_array[parent_idx] = self.heap_array[parent_idx], self.heap_array[inserted_idx] # SWAP
inserted_idx = parent_idx # 자신의 인덱스 값 갱신
return True새로운 노드를 추가할때, 먼저 배열의 마지막 인덱스에 추가를 합니다. 추가 후, 위에서 알아본 부모 노드와 자식 노드 간의 인덱스 계산 방식을 통해 부모 노드를 찾아서 값을 비교 합니다. 값 비교 후, 자신의 값이 부모 노드의 값이 더 크면 서로의 위치를 바꿔 줍니다(swap).
자기 자신이 root 노드가 되거나, 부모 노드보다 값이 작아질때까지 위치를 바꿔줍니다.
노드 삭제하기
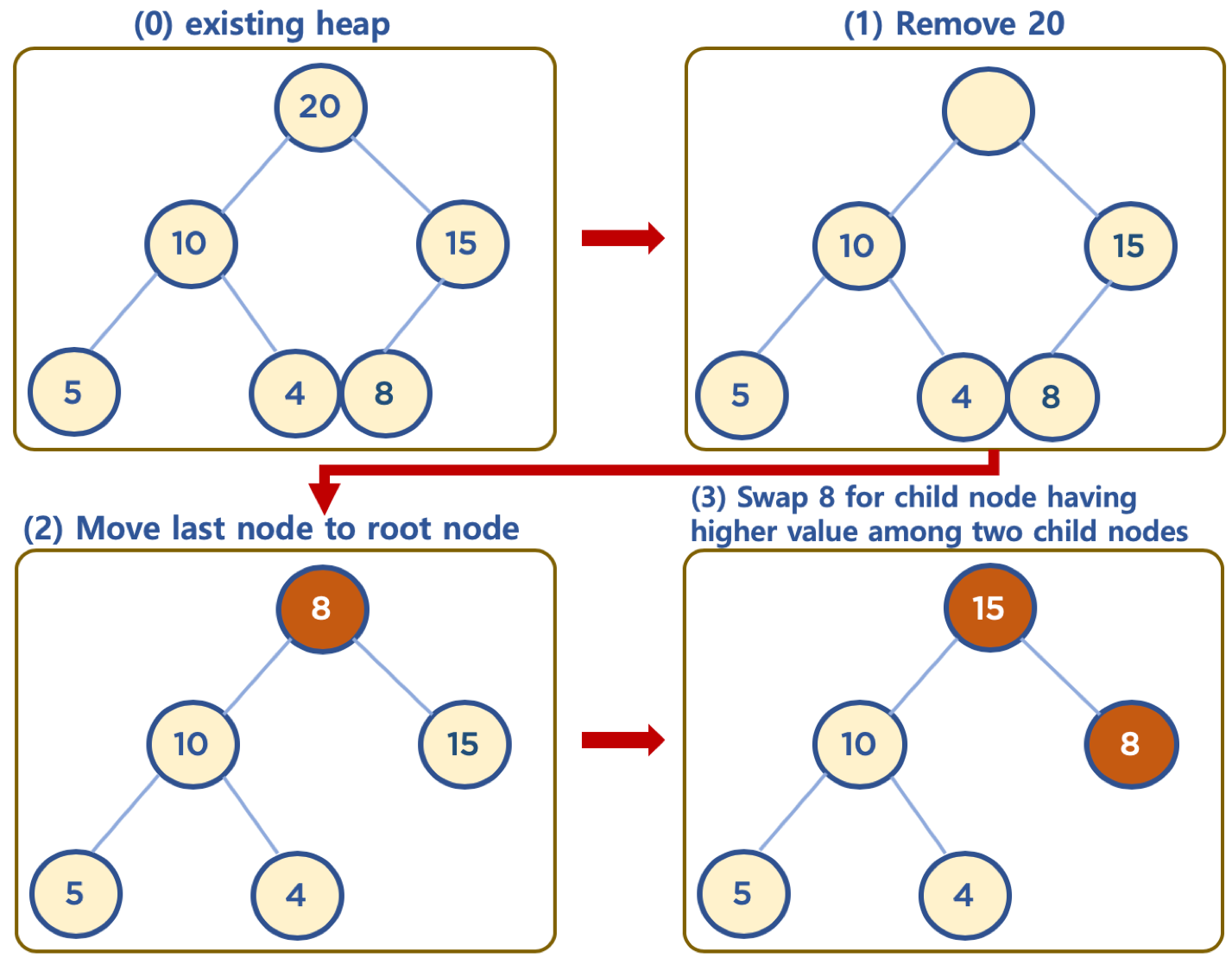
힙은 저장된 데이터들의 최대값 또는 최소값을 바로 접근 할 수 있도록 하는 데이터 구조임으로, 힙에서 데이터 삭제는 root 노드에서만 하도록 합니다. 그렇기 때문에, root 노드를 삭제 했을때, root 노드에는 항상 최대값 또는 최소값이 유지되도록 하는 것이 중요하며, 삭제된 root 노드를 대체할 노드가 최대값 또는 최소값이 되도록 해야 합니다.
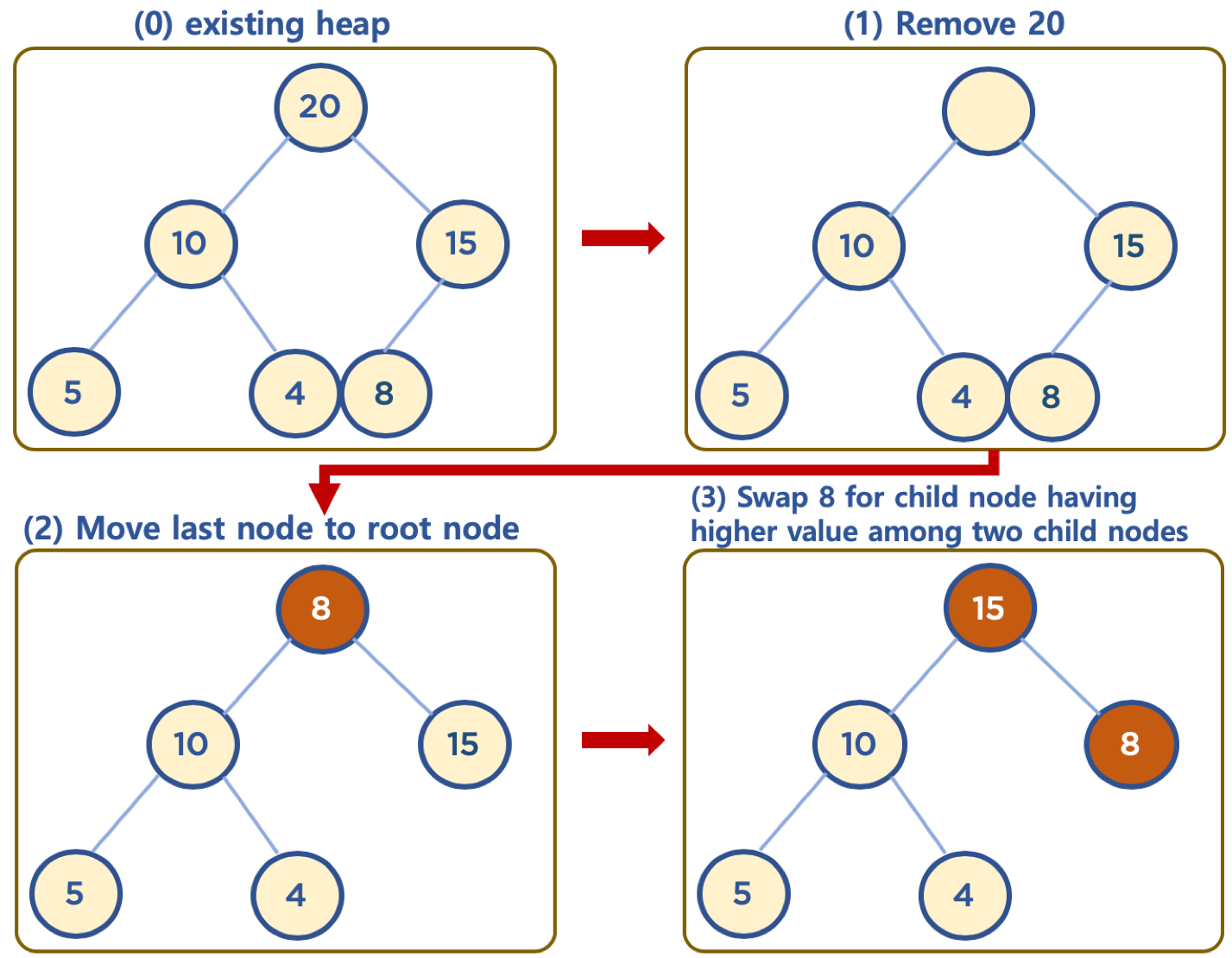
(https://www.fun-coding.org/00_Images/heap_remove.png)
Root 노드를 대체할 찾기 위해서 먼저 힙의 마지막 노드를 root로 이동시켜줍니다. 이동 시킨 후, 노드를 추가할때와 반대로 생각하면 됩니다. 이동 시킨 노드를 root에서 시작해서 아래로 내려가면서 위치를 찾아주는것 입니다. 이때, 자신의 값과 자식 노드들의 값들을 비교해서, Max Heap의 경우에는 자식 노드들 중 더 큰 값을 가진 노드를 찾고, 찾은 자식 노드가 자기 자신보다 값이 크면 서로 위치를 바꿔줍니다. 이렇게, 자기 자신이 Leaf Node가 될때까지, 또는 자식 노드들 모두 자기 자신보다 값이 작을때까지 반복해줍니다. Min Heap의 경우 자식 노드들 중 더 작은 값을 가진 노드와 비교하며, 자기 자신의 값이 자식 노드보다 더 작으면 위치를 바꿔줍니다.
{kind=link}
구현하기(파이썬)
def pop(self):
if len(self.heap_array) <= 1:
return None
# root(최대값) 반환
returned_data = self.heap_array[1]
# 마지막 노드를 root로 이동
self.heap_array[1] = self.heap_array[-1] # 가장 마지막 노드를 root로 옮기기 (-> 동시에 pop 된 데이터도 삭제됨)
del self.heap_array[-1] # 가장 마지막 노드를 root로 옮겼으므로, 마지막 노드가 있었던 위치에 있던 노드는 삭제
popped_idx = 1
# root로 옮긴 새로운 노드의 최종 자리를 찾아줌 -> 새로운 노드의 값이 자식 노드의 값보다 커질때까지 실행 || 자식이 없을때까지
# 자식 노드의 값이 더 크면 swap && 인덱스 값 갱신
while True:
left_child_popped_idx = popped_idx * 2
right_child_popped_idx = popped_idx * 2 + 1
# case1: 왼쪽 자식도 없을때(왼쪽 자식이 없으면 오른쪽 자식도 없음)
if left_child_popped_idx >= len(self.heap_array):
return returned_data
# case2: 오른쪽 자식 노드만 없을 때
elif right_child_popped_idx >= len(self.heap_array):
if self.heap_array[popped_idx] < self.heap_array[left_child_popped_idx]: # 부모 노드의 값보다 왼쪽 자식 값이 더 클때
self.heap_array[popped_idx], self.heap_array[left_child_popped_idx] = self.heap_array[left_child_popped_idx], self.heap_array[popped_idx]
popped_idx = left_child_popped_idx
continue
else: # 부모 노드의 값이 더 크므로 차리 찾기 완료
return returned_data
# case3: 왼쪽, 오른쪽 자식 노드 모두 있을 때
else:
if self.heap_array[left_child_popped_idx] > self.heap_array[right_child_popped_idx]: # 왼쪽 노드와 오른쪽 노드의 값 비교
if self.heap_array[popped_idx] < self.heap_array[left_child_popped_idx]: # 자식 노드의 값 > 부모 노드의 값
self.heap_array[popped_idx], self.heap_array[left_child_popped_idx] = self.heap_array[left_child_popped_idx], self.heap_array[popped_idx]
popped_idx = left_child_popped_idx
continue
else: # 부모 노드의 값이 더 크므로 차리 찾기 완료
return returned_data
else:
if self.heap_array[popped_idx] < self.heap_array[right_child_popped_idx]: # 자식 노드의 값 > 부모 노드의 값
self.heap_array[popped_idx], self.heap_array[right_child_popped_idx] = self.heap_array[right_child_popped_idx], self.heap_array[popped_idx]
popped_idx = right_child_popped_idx
continue
else: # 부모 노드의 값이 더 크므로 차리 찾기 완료
return returned_data
return returned_data
- 힙의 크기 1보다 작거나 같으면, root만 남아 있는 힙이로써, 위치를 더 찾을 필요가 없습니다
- Root(인덱스 1)의 값을 반환
- 힙에서 마지막 인덱스에 있는 값을 root(인덱스 1)로 이동
- 자식 노드가 있는지 없는지 확인:
- 3-1. 자식 노드가 없으면 최종 위치
- 3-2. 자식 노드가 하나만 있으면, 자식 노드와 값을 비교해서 위치를 바꿀지 말지 결정
- 3-3. 자식 노드가 두 개 있으면, 자식 노드 중 더 큰 값을 가진 노드를 먼저 찾음. 더 큰 값을 가진 자식 노드와 자기 자신을 비교해서 위치를 바꿀지 말지 결정
시간복잡도
힙의 경우, 배열로 저장하더라도 사실은 트리로 표현한 것이기 때문에, 높이 h에 대해서 시간 복잡도는 최악의 경우 O(h)입니다. 이때, n개의 노드에 대해서 h = log n 이므로, 시간 복잡도는 O(log n)이 됩니다. 데이터를 추가할때, 최악의 경우, leaf node부터 root node까지 탐색을 해야하기 때문입니다. 삭제를 할때도, root node를 삭제한 후 최악의 경우, 대체할 노드를 root node부터 leaf node까지 탐색을 해야합니다.
