5. 스케줄링
CPU 스케쥴링이란 다중 프로그래밍 운영체제의 기초이다.
"프로세스 스케줄링"과 "스레드 스케줄링"은 보통 같은 의미로 사용된다. 이 챕터에서는 프로세스 스케줄링을 일반적인 스케줄링 개념으로 칭하고, 스레드 스케줄링은 스레드에만 해당하는 내용으로 언급할 것이다.
챕터 1에서 코어가 어떻게 CPU의 기본 연산 단위가 되는지 얘기 했었는데 이 챕터에서는 "CPU를 돌릴" 프로세스를 스케줄링 한다고 할 때, 프로세스가 CPU의 코어에서 돈다는 것으로 정의할 것이다.
단원 목표
- 다양한 CPU 스케쥴링 알고리즘 이해하기
- 스케줄링 기준에 따라 CPU 스케줄링 알고리즘 평가하기
- 다중 프로세서 및 다중 코어 스케줄링과 관련된 문제 이해하기
- 다양한 real-time 스케줄링 알고리즘 이해하기
5.1 Basic Concepts
-
다중 프로그래밍의 목적
-> 어떤 프로세스들이 항상 실행되기 위해서
-> CPU 활용감을 극대화시키기 위해서 -
프로세스가 입출력 시간을 대기시 CPU는 아무것도 안하고 있다. -> 다중 프로그래밍 시 여러 프로세스를 메모리에 한 번에 올린 뒤 한 프로세스가 대기 중이면 CPU를 다른 프로세스에게 부여한다.
이런 스케줄링이 근본적인 운영체제 함수이다. 거의 모든 컴퓨터 자원은 사용되기 이전에 스케줄링이 되어있다. CPU도 마찬가지이다.
5.1.1 CPU-I/O 버스트 주기
CPU 스케줄링의 성공은 프로세스 속성에 달려있다: 이때 프로세스 실행은 CPU extension의 실행 주기 cycle와 입출력대기로 나뉜다. 프로세스는 CPU burst로 실행을 시작하며, 나중에 입출력 버스트가 되고, 다시 CPU 버스트가 되며 계속 반복된다. 마지막엔 CPU 버스트를 통해 시스템에게 실행 종료 요청을 보낸다.

CPU 버스트 소요시간은 확장적으로 측정된다. 프로세스에서 프로세스, 컴퓨터에서 컴퓨터로는 당연히 다른데 아래 그림과 유사한 곡선을 가진다. 보통 지수적 또는 하이퍼지수적인 그래프 형태를 띠어 자주 발생하는 짧은 CPU 버스트와 적게 발생하는 긴 CPU 버스트로 구성된다.
입출력 제약 장치 경우 짧은 CPU 버스트가 많다. CPU 제약 프로그램의 경우 약간의 긴 CPU 버스트가 있다. 이 분배가 CPU 스케줄링 알고리즘을 구현할 때 중요한 부분이다.

5.1.2 CPU 스케줄러
CPU가 보통 놀고 있을 때 CPU 스케줄러가 메모리에서 실행 가능한 프로세스를 골라서 CPU에 해당 프로세스를 할당해줘야된다.
이때 준비 큐가 fifo(first-in-first-out) 선입선출 큐가 아닐 수도 있다. priority 큐, 트리, 정렬이 안 된 링크드 리스트가 될 수도 있다. 개념적으로 CPU에 실행되도록 줄 서 있는 큐라고 보면 쉽다.
5.1.3 Preemptive and Nonpreemptive Scheduling
CPU 스케줄링할 때 내리는 결정들을 보통 다음과 같은 경우에 발생한다:
- 프로세스가 실행 상태에서 대기 상태로 바뀔 때(입출력 요청이나
wait()호출) - 프로세스가 실행 상태에서 준비 상태로 바뀔 때(인터럽트)
- 프로세스가 대기 상태에서 준비 상태로 바뀔 때(입출력 완료)
- 프로세스가 종료될 때
1,4의 경우에는 딱히 스케줄링이라 할 만한게 없다. 그냥 새 프로세스를 (준비 큐에 있으면) 실행하면 된다. 이를 비선점적 nonpreemptive 혹은 협력적 cooperative 스케줄링 계획이라고 부른다.
반대로 2,3과 같은 경우를 선점적 preemptive 스케줄링이라고 부른다. 비선점적 스케줄링에선 CPU가 프로세스에게 할당될 때, 프로세스가 종료되거나 대기 상태에서 교환되지 않는 이상 CPU를 붙잡고 있다. 그래서 현대 운영체제들(Windows, MacOs, Linux, Unix)은 선점적 스케줄링 알고리즘을 사용하고 있다.
선점적 알고리즘
선점적 알고리즘의 경우 프로세스 간 데이터를 공유할 때 경합 조건에 놓이게 된다. 예시로 만약에 A가 데이터를 수정 중에 선점당해 B가 실행됐다고 가정했을때 이것을 B가 수정 중인 상태의 데이터를 읽으려고 한다면? -> 이 이슈의 자세한 내용의 챕터 6에서 다룰 것이다.
선점은 운영체제 커널의 설계에서도 영향을 끼친다. 시스템 호출을 처리하면, 커널이 해당 호출을 처리하느라 바쁠 것이다. 이때 처리하는 것이 중요한 커널 데이터(입출력 큐 등)일 수도 있다. 근데 프로세스가 수정 중간에 선점 당했는데, 이후에 커널(혹은 장치 드라이버)이 똑같은 자료를 읽거나 수정할려고 한다면? 혼돈 그 자체이다. -> 이것들은 Section 6.2에서 운영체제 커널은 선점적 또는 비선점적으로 설계 된다는 내용을 다룰 것이다.
비선점적 알고리즘
비선점적 커널같은 경우 시스템 콜이 완료될 때까지, 혹은 프로세스가 입출력 완료될 때까지 프로세스가 막는 동안 대기한다. 이후에 문맥교환을 통해 커널구조를 단순화 해주는데 이것은 실시간 컴퓨팅 입장 쪽에선 좋지 않다. -> 작업이 주어진 시간 간격 내에 완료되어야 하기 때문이다. 선점적 커널은 Mutex 잠금과 같이 커널 데이터 구조에서의 공유 데이터에 대한 경합 조건 방지를 위해서 메커니즘이 필요하다. 대부분 현대 운영체제는 커널모드에서도 선점적이다.
왜냐하면 인터럽트는 이론상 언제라도 일어날 수도 있고, 커널이 무시할 수도 없기 때문이다. 인터럽트에 의해 영향 받는 코드들은 동시 사용에 대비해서 항상 보호해야된다. 그래서 여러 프로세스에 의한 동시 접근은 불가해야 된다. 이는 시작할 때 인터럽트를 비활성화하고, 끝나면 인터럽트를 재활성화 시켜준다.
5.1.4 Dispatcher
디스패처는 CPU 스케줄링 함수의 한 성분으로 CPU 스케줄러가 선택한 프로세스에 CPU의 코어에 대한 제어권을 준다:
- 프로세스간 문맥 교환
- 유저 모드로 교환
- 사용자 프로그램에 알맞은 위치로 도약하여 프로그램 재개
디스패쳐는 모든 문맥 교환마다 실행되므로 최대한 빨라야 한다. 프로세스를 하나 중단하고 다른 것을 실행 시키는데 걸리는 시간을 디스패치 지연 속도 dispatch latency라고 부른다:

여기서 의문점이 하나 발생한다. 그래서 문맥 교환은 얼마나 자주 일어날까? Linux 체제에서는 vmstat 명령어를 통해 시스템 간의 문맥 교환 정보를 얻을 수 있다:
vmstat 1 3이 명령어는 1초 간격으로 세줄을 출력한다는 뜻이다.:
------cpu-----
24
225
339첫 번째 줄의 시스템 부팅 후 1초 간 평균 문맥 교환 수이고, 다음 두 줄은 두 번의 1초 간격 간 몇 번의 문맥 교환이 일어났는지 보여준다.
또한 /proc 파일 시스템을 통해서 주어진 프로세스의 문맥교환 횟수를 알 수 있다. /proc/2166/status같은 경우 pid = 2166인 프로세스 에 대한 여러 통계를 보여 줄 수 있다.
voluntary_ctxt_switches 150
nonvoluntary_ctxt_switches 8프로세스의 문맥교환 횟수의 결과를 나타낸 것이다. 이때 자의적 voluntary과 타의적 nonvoluntary 문맥 교환이 구분되어있다. 이때 자의적 문맥 교환은 프로세스가 현재 사용 불가능한 자원을 요청해서 CPU 제어를 포기한 경우, 타의적 문맥 교환은 주어진 시간이 다 되었거나 더 우선 순위가 높은 프로세스에 의해 선점 당하는 것 처럼 CPU가 다른 프로세스에게 뺏긴 경우 발생한다.
5.2 Scheduling Criteria
CPU 스케줄링 알고리즘은 특징이 다 다르다. 그래서 상황마다 알고리즘을 잘 골라야 한다.
그래서 알고리즘 간 평가 기준이 필요하다:
- CPU utilization(효율) : CPU가 최대한 놀지 않게 한다. 일반 적으로 CPU 효율을 0에서 100%까지 나눌 수 있다. 실제로 40%(탑재량이 가벼운 시스템)에서 90%(탑재량이 무거운 시스템)(리눅스, MacOs, 유닉스)까지 쓰여진다.
- 처리율 Throughput : 작업에 대한 단위로, 시간 단위 당 완료된 프로세스 수를 의미한다.
- Turnaround time: 특정 프로세스 입장에서는 자기 프로세스가 얼마나 실행할 수 있냐가 중요하다. 이때 프로세스 제출 시간부터 완료시간까지의 간격을 턴어라운드 시간이라고 한다. (준비 큐에서 대기한 시간, CPU에서 실행된 시간, 입출력에서 처리한 시간 전부 포함한다.)
- 대기 시간 waiting queue: CPU스케줄링 알고리즘은 준비 큐에서 대기하는 시간에만 영향을 주는데 이때 준비 큐에서 대기한 시간의 합을 대기 시간이라고 한다.
- 반응 시간 response time: 보통 프로세스들은 결과값을 빠르게 만들어내고, 새로운 결과를 계산하는 동안 이전 결과값을 사용자들에게 보여준다. 이때 요청이 처음 들어왔을 때 이걸 처리하기 시작하는 데까지 걸린 시간이 반응 시간의 하나의 평가 기준이다.
결과적으로는 결과값에 대한 응답이 완료될 때까지 걸린 시간이 아니라, 요청에 대응하기 시작하는데 걸린 시간을 반응시간이라고 한다.
CPU효율과 처리율을 극대화하고, 턴어라운드 시간, 대기 시간, 반응시간을 최소화하는게 제일 베스트이지만 상황에 따라 한 쪽에 더 집중하는 최적화 전력을 할 수도 있다.
그래서 상호작용 시스템(pc desktop, laptop)에서는 평균적인 반응 시간을 줄이는 것보다 반응 시간의 변동성을 최소화하는 것이 더 중요하다고 한다. 보통 합리적이고 예측 가능한 변동시간 같은 경우가 오히려 더 빠르고 예측하기 어려운 것보다 더 나을 수 있다. (그러나 cpu 알고리즘 중 변동성을 줄이는 연구는 별로 안 되어있다고 한다.)
5.3 Scheduling Algorithms
CPU 스케줄링은 준비 큐에 어떤 프로세스를 CPU 코어에 할당하느냐의 문제를 다룬다. 현대 CPU 구조는 다중 프로세싱 코어구조지만, 여기서 다루는 스케줄링 알고리즘은 코어가 하나만 있을 경우에 대하여 다룰 예정이다.
5.3.1 First-Come, First-served Scheduling(선도착, 선처리 스케줄링)
CPU 스케줄링 알고리즘 중 가장 간단한 알고리즘이다.
장점
CPU에 먼저 할당 요청한 프로세스가 우선적으로 처리된다. 선입선출(FIFO) 큐로도 구현이 가능하다. 구현도 쉽고 이해하기도 매우 쉽다.
단점
평균 대기 시간이 긴 편이다. 다음 주어진 프로세스들이 시간 0에 도착한다고 가정하고, CPU 버스트의 길이 단위를 millisecond로 단위로 정했을 때:
| Process | Burst Time |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
위의 순서대로 도착하면 간트 차트로 나타나게 되면

이때 P1의 대기시간은 0ms, P2의 대기시간은 24ms, P3의 대기시간은 27ms이다. 그러면 평균 대기시간은 (0+24+27)/3 = 17ms이다.
만약 2,3,1 순서로 도착했다고 가정했을 때 간트 차트로 나타나게 된다면:

평균 대기 시간은 (0+3+6)/3 = 9ms가 된다. 순서가 달라졌을 뿐인데 평균 대기시간이 달라지는 것을 볼 수 있다. 그래서 FCFS 정책의 경우 평균 대기시간이 최적의 경우가 아닐 뿐더러 프로세스의 CPU 버스트 시간이 다를 수록 크게 차이 날수도 있다.
예시
만약 FCFS 스케줄링이 동적인 환경이라고 가정해보자. 우선 CPU 제약 프로세스는 CPU를 차지할 것이다. 이때 다른 프로세스가 입출력을 완료하고 준비 큐로 이동하여 CPU를 위해 대기하고 있을 것이다. 그동안 입출력 장치들은 놀고 있다. CPU 제약 프로세스는 완료되고 입출력 장치로 이동하게 되면 입출력 제약 프로세스는 CPU 버스트가 짧으므로 빠르게 처리된 뒤 다시 입출력 큐로 들어갈 것이다. 그러면 CPU가 놀게 된다. CPU 제약 프로세스는 다시 준비 큐로 이동하여 CPU에 할당될 것이고, 이때 또 입출력 장치는 놀게 된다. 이때 큰 프로세스 하나가 CPU를 냅둘 때 까지 대기하는 현상을 Convoy Effect라고 한다.
이는 비선점적이고 낮은 CPU와 장치 효율성을 나타내어 상호작용 체계 시스템에 적합하지 않다.
5.3.2 Shortest-Job-First Scheduling
최단 작업 우선(Shortest-Job-First-Scheduling)스케줄링 알고리즘은 각 프로세스의 다음 CPU 버스트의 길이를 바탕으로 작동한다. 앞으로 남은 CPU 버스트 중 제일 적은 프로세스를 우선적으로 실행한다. 만약 남은 두 프로세스의 CPU 버스트가 같을 때는 FCFS를 통해 처리된다. 이 알고리즘은 사실 더 적합한 이름이 있는데 shortest-next-CPU-burst라고도 불린다.
예시
SJF의 예시로 CPU burst의 기본 단위를 ms를 주고 나타내보면:
| Process | Burst Time |
|---|---|
| P1 | 6 |
| P2 | 8 |
| P3 | 7 |
| P4 | 3 |
이를 SJF 스케줄링 알고리즘을 적용하여 간트 차트를 표현해보았다.:

이때 간트 차트 순서대로 의 대기 시간은 각각 0ms, 3ms, 9ms, 16ms이다. 그러므로 평균 대기시간은 (0+3+9+16)/4 = 7ms이다. 만약 FCFS였으면 10.25ms였다.
장점
이를 통해서 주어진 프로세스에 대해 최소 시간을 얻을 수 있다는 점에서 제일 최적이다. 짧은 프로세스를 먼저 처리해서 짧은 프로세스를 먼저 처리해서 짧은 프로세스들의 대기시간을 줄이는게 큰 프로세스의 대기시간을 먼저 처리하는 것보다 평균 대기 시간이 더 줄어든다.
단점
CPU 스케줄링 단계에서 구현이 불가능하다. -> CPU 버스트가 얼마나 걸릴지 모르니까...
이를 해결하기 위해 고안한 것이 근사 SJF 스케줄링이다. 이는 정확히 값은 몰라도 예측은 가능하기 때문이다. 다음 CPU의 버스트를 이전 것과 유사할 것이라고 예측하고 근사치를 정하였다.
예시
다음 CPU 버스트는 기존 CPU 버스트 측정 값의 지수 평균(exponential average)로 예측했다.
tn이 n 번째 CPU 버스트 길이라고 하고, τn + 1이 다음 CPU 버스트 추정치라고 가정한다면, 0 ≤ α ≤ 1인 α에 대해:
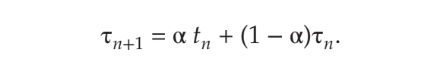
나타낼 수 있다.
tn이 제일 최근 정보, τn이 과거 정보를 나타낸다. 매개변수 α는 최근 기록과 과거 기록을 통해 상대적 가중치를 결정한다.
α=0이면 아무런 영향이 없고, α=1이면 오로지 최근 기록으로만 결정한다.
보통 α=1/2로 두고 처리한다. 아래 그림은 α=1/2과 τ0=10일 때 보여준 지수 평균 그래프이다: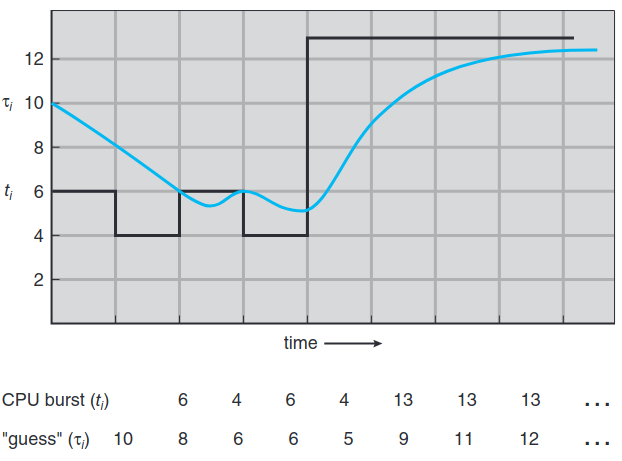
이때 지수 평균의 영향을 이해하려면 τn을 대체하여 τn + 1의 공식을 확장을 해야된다.
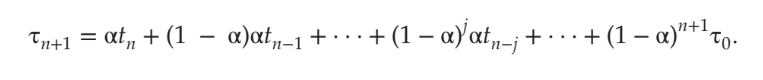
이때 α는 1보다 작다. 결과적으로 (1 - α)는 1보다 작고, 직전 계수보다 더 작은 값을 가지게 된다.
이를 통해 SJF는 비선점, 선점 둘 다 가능하다. 이 둘 중 선택은 여전히 이전 프로세스가 실행 중일때 새로운 프로세스가 대기 큐에 도착하게 되면 이벤트가 발생하게 된다. 이때 다음 CPU 버스트는 현재 실행되는 프로세스보다 짧을 경우 선점적 SJF 알고리즘은 현재 프로세스는 현재 실행 프로세스를 선점할 것이고 비선점적 SJF 알고리즘은 현재 CPU 버스트가 끝날 때까지 기다린다. 이때 선점적 알고리즘을 최단 잔여 시간 우선(shortest-remaining-time-first) 스케줄링이라고 한다.
선점적 SJF 스케줄링 예시2
| Process | Arrival Time | Burst Time |
|---|---|---|
| P1 | 0 | 8 |
| P2 | 1 | 4 |
| P3 | 2 | 9 |
| P4 | 3 | 5 |
간트 차트:

이때 P1이 유일한 프로세스이므로 먼저 실행한 뒤 arrival time 1에 P2가 오는데 P2의 버스트 시간이 P1의 남은 버스트 시간(7ms)보다 짧으므로 먼저 P2가 실행되고 그 이후 arrival time 2,3인 P3,P4와 P1을 비교했을때 P4의 버스트 시간이 제일 짧으므로 P4가 실행된 뒤 그다음에 P1의 남은 버스트 시간이 실행되고 나머지 P3가 실행되게 된다.
그렇게 되면 평균 대기 시간은 ((10-1)+(1-1)+(17-2)+(5-3))/4 = 6.5ms가 된다.
이때 비선점적 스케쥴링이라고 가정하게 되면 (0 + (8-1) + (17-2) + (12-3))/4 = 7.75ms가 나오게 된다.
5.3.3 Round-Robin Scheduling
라운드 로빈 Round-Robin(RR) 스케줄링 알고리즘은 선점이 추가된 FCFS알고리즘과 유사하다. 시간 단위를 time quantum 혹은 time slice이라는 짧은 시간 단위로 정의된다. time quantum은 보통 10ms에서 100ms 구간으로 나뉘고 준비 큐는 순환큐로 취급되고 CPU 스케줄러가 준비 큐를 돌면서 1시간 단위 정도씩 프로세스를 할당한다.
RR 스케줄링을 구현하기 위해서는 준비 큐를 선입선출 큐로 간주한다. CPU스케줄러는 준비 큐로 부터 첫 번째 프로세스를 뽑은 뒤, 1시간 단위 이후에 인터럽트하도록 타이머 설정한 뒤 프로세스를 디스패치한다.
그러면 둘 중 하나의 상황이 발생하게 되는데:
- 1시간 단위보다 짧은 프로세스가 자체적으로 CPU를 해제시켜준다. 그러면 스케줄러는 다음 프로세스를 실행하게 될 것이다.
- 1시간 단위보다 긴 프로세스를 가지게 된다면, 타이머가 인터럽트를 실행하게 되어 문맥교환이 되어 프로세스가 준비 큐의 꼬리 부분으로 들어간다.
예시
RR 정책의 평균 대기 시간은 긴 편이다:
| Process | Burst Time |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
위를 예시로 들어보자. 시간 단위가 4ms라고 가정했을 때 간트 차트로 표시하게 되면:

이때 대기 시간은 P1은 (10-4)ms이고, P2는 4ms이고, P3는 7ms를 기다리게 된다. 그래서 평균 대기시간은 17/3 = 5.66ms이다.
RR 스케줄링 알고리즘에서는 그 어떠한 프로세스도 1시간 단위를 초과해서 할당받지 않는다. 초과하면 바로 선점당하게 되고, 준비 큐 뒤로 돌아가야 한다. 즉 RR 알고리즘은 선점적이다.
준비 큐에 n개의 프로세스가 있고, 시간 단위가 q이면 각 프로세스는 1/n을 최대 q번의 시간 단위를 가지게 된다. 한 마디로 프로세스는 최대 (n-1) x q 시간 만큼 대기하게 된다. 만약 다섯 개의 프로세스가 20ms의 시간 단위로 돌게 된다면 각 프로세스는 최대 100ms마다 20ms를 얻게된다.
RR 알고리즘의 성능은 시간 단위의 크기가 결정된다. 다음 그림처럼 프로세스 시간 단위가 10일때 시간단위가 충분히 크면 CPU 버스트가 큰 것도 한 번에 처리 가능하다. 그러나 시간 단위가 6에 CPU 버스트 크기도 6이면 두 번째 처리하다가 10에서 문맥교환이 발생하게 된다. 시간 단위가 1이면 그만큼 문맥교환이 많이 일어난다.

그래서 문맥 교환 시간에 따라 시간 단위가 적당히 커야된다. 만약 문맥 교환 시간이 시간 단위의 10% 정도면 CPU 시간의 10%가 문맥 교환에 사용되고 있다는 것이다. 실무에서는 10에서 100ms 시간 단위를 사용하고 있는데 보통 문맥 교환에 걸리는 시간은 10ms보다 작으므로 문맥 교환은 시간 단위에 있어서 작은 부분에 속한다.
턴어라운드 시간도 시간 단위 크기에 의존한다. 아래 그림과 같이 시간 단위가 증가한다고 평균 턴 어라운드 시간이 개선되지는 않는다. 일반적으로 평균 턴어라운드 시간은 대부분의 프로세스가 하나의 시간 단위에 CPU 버스트를 전부 소진할 때 제일 좋다고 한다.

시간 단위는 결국 문맥 교환 시간 보다는 커야겠지만, 그렇다고 너무 커져서는 안된다. 만약 너무 커지게 된다면 FCFS 정책이랑 다를 바가 없어진다. 보통 CPU 버스트의 80%는 시간 단위보다 짧아야 한다.
5.3.4 Priority Scheduling
SJF 알고리즘은 우선 순위 스케줄링 priority-scheduling의 한 형태라고 볼 수 있다. 각 프로세스마다 우선순위를 가지며 CPU는 가장 우선순위가 높은 프로세스에게 할당한다. 우선 순위가 동일할 경우 FCFS 순으로 처리하게 된다. SJF의 경우 우선 순위(p)가 (예측된)다음 CPU 버스트의 역수이다. 말 그대로 CPU 버스트가 커질수록, 우선순위가 낮아진다.
여기서 우선 순위가 높다(high) 낮다(low)라는 표현을 사용한다. 우선 순위는 0에서 7, 0에서 4095등의 보통 고정된 범위 내에서 숫자를 사용하지만 0이 제일 낮은 건지 높은 건지에 대한 통일된 규격은 없다고 보면 된다.
예시
예시를 들자면:
| Process | Burst Time | Priority |
|---|---|---|
| P1 | 10 | 3 |
| P2 | 1 | 1 |
| P3 | 2 | 4 |
| P4 | 1 | 5 |
| P5 | 5 | 2 |
간트차트

여기서 평균 대기 시간은 8.2ms이다.
우선 순위는 내부적, 외부적으로 정의가 가능하다.
내부적으로 정의할 경우 프로세스의 우선순위를 결정할 정량적인 자료(시간 한계, 메모리 소요, 연 파일수, 평균 입출력 버스트 대 CPU 버스트율 등)을 사용한다. 외부적으로 정의할 경우 운영체제의 외적인 기준인(프로세스의 중요도, 컴퓨터 사용에 들어간 금액적 비용, 작업을 후원하는 부서, 다른 정치적 요소)등이 포함된다.
우선 순위 스케줄링도 선점적 / 비선점적으로 정의 가능하다. 프로세스가 준비 큐에 들어오게 되면 현재 실행 중인 프로세스와 우선 순위를 비교하게 되는데, 선점적이면 새 프로세스의 우선 순위가 더 높으면 원래 실행하던 것을 뺀다.
우선 순위 알고리즘의 문제점
우선 순위 알고리즘의 가장 큰 문제점은 무한 막기 indefinite blocking 혹은 기아 상태 starvation이다. 프로세스는 실행 준비가 되었는데 CPU를 위해 대기 중인 프로세스는 막힌 상태라고 한다. 우선 순위 스케줄링 알고리즘의 경우 우선 순위가 낮은 프로세스가 무한정으로 대기할 수 있다. 부하가 많을 경우 계속해서 우선 순위가 높은 프로세스가 끊임없이 흘러서 낮은 프로세스는 CPU 쪽에 접근을 못할 수 도 있다. 이럴때는 언젠가 실행되거나 컴퓨터가 뻗고 모든 우선 순위 작은 프로세스가 다 사라진다.
이를 해결하는 방법으로는 노화 aging가 있다. 기다린 만큼 우선 순위를 높여주는 것이다.
또는 라운드 로빈과 우선순위를 결합해서 우선 순위가 높은 프로세스를 실행하고, 같은 우선순위끼리 라운드 로빈 방식으로 스케줄링을 한다.
예시로:
| Process | Burst Time | Priority |
|---|---|---|
| P1 | 4 | 3 |
| P2 | 5 | 2 |
| P3 | 8 | 2 |
| P4 | 7 | 1 |
| P5 | 3 | 3 |
이를 시간 단위를 2ms로 두고 간트 차트를 그리면:

그렇게 되면 우선 P4는 전부 다 실행될 것이고, 우선 순위가 같은 P2와 P3는 시간단위에 맞춰 번갈아 가며 실행하게 된다. 이때 P2는 시간 16에 끝나게 되고, P3는 시간 20에 끝나게된다. 나머지 P1과 P5도 우선 순위가 같으므로 번갈아 가며 실행하게 된다.
5.3.5 Multilevel Queue Scheduling
우선 순위와 라운드 로빈 스케줄링 둘 다 프로세스를 하나의 큐에 놓는다. 그리고 스케줄러가 우선순위가 제일 높은 프로세스를 선택한다. 이 때 큐 관리법에 의해 우선 순위가 높은 프로세스를 탐색하는데 O(n)의 탐색 시간이 걸릴 수도 있다.
아래의 그림처럼 실무에서는 특정 우선 순위에 해당하는 큐를 따로 갖곤 한다. 그리고 우선순위 스케줄링은 가장 높은 우선 순위의 큐를 가진 프로세스를 스케줄링한다. 일반적으로 보면 우선 순위는 정적으로 각각 프로세스에 할당되고, 프로세스는 실행 중에는 같은 큐에 존재하게 된다.

다단계 큐 스케줄링은 프로세스 유형에 따라 큐를 구분해줄 수도 있다:
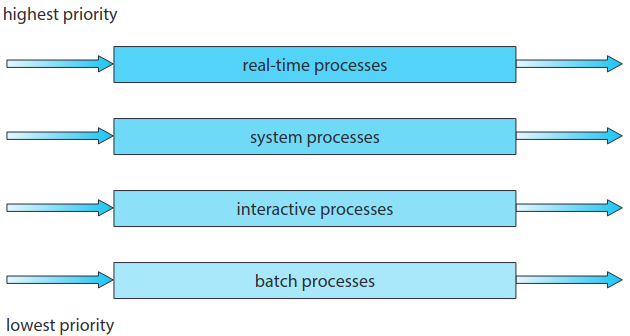
Foreground Process, Background Process
일반적으로 전면 foreground(상호작용) 프로세스와 배경 background(배치) 프로세스가 있다. 이 둘은 각각 반응 시간 소요가 다르고 서로 다른 스케줄링 방법으로 처리된다.
추가적으로 전면 프로세스가 배경 프로세스 보다 더 우선순위가 높은 경향을 보인다. 여기서 전면 큐는 RR알고리즘으로, 배경 큐는 FCFS 알고리즘으로 처리된다.
큐간에도 스케줄링이 필요한데 보통 고정 우선순위 선점적 알고리즘을 사용한다. 예를 들어 실시간 큐는 상호작용 큐보다 절대적으로 높은 순위를 가진다.
네 개의 큐를 갖는 다단계 큐 스케쥴링의 예시를 보자:
- 실시간 프로세스
- 시스템 프로세스
- 상호작용 프로세스
- 배치 프로세스
각 큐는 순위 별로 아래 큐보다 우선 순위가 높다. 1,2,3 번이 비지 않는 이상 배치를 실행하지 않는다.
또 다른 방법으로는 큐 간 시간 단위(time slice)를 부여하는 것이다. 이러면 각 큐 별로 CPU 시간 일부를 부여 받을 것이다. 예를 들어 전면 큐에는 CPU 시간의 80%를 받아 RR 스케줄링을 하고, 배경은 나머지 20%를 받아 FCFS로 처리한다.
5.3.6 Multilevel Feedback Queue Scheduling
보통 다단계 큐 스케줄링 알고리즘을 사용할 때, 프로세스가 들어갈 큐는 정해져있다. 예시로 전면과 배경 프로세스에 각각의 큐가 있다고 가정한다면, 이때 큐 간의 프로세스는 이동하지 않는다고 한다. 이게 스케줄링 부담이 없긴 하지만 유연성이 적다.
BUT 다단계 피드백 큐 스케줄링을 사용할 경우 큐 간 이동이 정해진다. 이 아이디어는 CPU 버스트에 따라 프로세스를 구분하자는 것이다. 만약 프로세스가 CPU를 너무 많이 사용하면 우선순위가 낮은 큐로 옮기고 입출력 제약 및 상호작용 프로세스 처럼 CPU 버스트가 짧은 애들이 우선 순위가 높아진다. 너무 오랜기간 낮은 우선 순위 큐에 있을 때 우선 순위 높은 큐로 옮겨주기도 하는 식으로 aging(노화)를 진행한다.
아래 그림처럼 프로세스가 첫 번째 큐에 들어갔을 때, 시간 단위 8내 못 끝내면 두 번째 큐의 끝에 넣어주고, 거기서 시간 단위 16내에 못 끝내면 마지막 FCFS 큐에 넣어준다.

일반적으로 다단계 피드백 큐 스케쥴러는 다음 매개변수를 가진다.:
- 큐의 개수
- 각 큐 별 스케줄링 알고리듬
- 프로세스를 더 높은 우선순위로 승격하는 방법
- 프로세스를 더 낮은 우선순위로 강등하는 방법
- 프로세스를 서비스해야할 때 어떤 큐에 배치할 지를 결정할 방법
다단계 피드백 큐 스케줄러는 가장 일반적인 CPU 스케줄링 알고리즘이다. 물론 가장 좋은 알고리즘을 만들려면 모든 매개변수에 대한 값을 선택해야한다는 점에서 가장 복잡한 알고리즘이긴하다.
5.4 Thread Scheduling
스레드는 사용자 스레드와 커널 스레드로 나뉜다. 대부분의 현대적인 운영체제는 프로세스가 아니라 커널스레드에 의해 스케줄링된다.
사용자 스레드는 스레드 라이브러리에서 관리하고, 커널은 여기에 관여하지 않는다. 사용자 스레드를 CPU에서 실행시킬려면, light weight process(LWP) 형태로 간접적이든 뭐든 커널 스레드와 손을 잡아야된다.
5.4.1 Contention Scope
다대일이나 다대다의 경우 스레드 라이브러리가 사용자 스레드를 LWP에 대해 스케줄링을 한다. 이것을 프로세스 경합 영역 Process-contention Scope(PCS) 라고한다. 즉 같은 프로세스의 스레드 간에 CPU 점유를 위해 경쟁한다.(여기서 알아야 될 점은 스레드 라이브러리가 사용자 스레드를 LWP에 스케줄링한다는 것은 스레드가 실제 CPU에서 돌게한다는 것과는 다르다.)
어떤 커널 스레드를 CPU에 할당할 지 스케줄링 할 때는 커널이 시스템 경합 영역 system-contention scope(SCS) 을 사용한다. SCS 스케줄링을 사용 시 모든 스레드 간에 CPU 경쟁을 하게 된다. 여기서 일대일 경우는 SCS 스케줄링만 사용한다.
보통 PCS는 우선 순위에 따라 처리된다. 사용자 스레드의 우선 순위는 프로그래머가 설정하고 스레드 라이브러리가 수정해줄 수는 없다. 그렇게 되면 PCS가 선점적으로 처리하게 되는데 스레드간 고르게 시간 분할한다는 보장이 없다.
5.5 Multi-Processor Scheduling
지금까지 코어가 하나일때만 다뤘었다. CPU 코어가 여러개가 된다면 부하 분담 load sharing을 통해 여러 스레드가 병렬적으로 돌 수 있게되고 복잡해진다.
보통 다중 프로세스라는 용어는 물리적인 프로세스가 여러 개인 경우를 칭했었는데, 현대적인 컴퓨터 체제에서는 다중 프로세서 를 이런 구조로 칭한다:
- 다중 코어 CPU
- 다중 스레드 코어
- NUMA 체제
- 비균일 다중 프로세싱
이 구조를 바탕으로 다중 프로세서 스케줄링을 다룰 것이다. 첫 번째와 세 번째 예시는 프로세서가 서로 기능면에서 동일한 면에서 다루는 것이고, 마지막 예시는 기능이 서로 같지 않은 경우에 대해서 다룰 것이다.
5.5.1 Approaches to Multiple-Processor Scheduling
비대칭 다중 프로세싱
다중 프로세서에 있어서의 CPU 스케줄링은 스케줄링 결정, 입출력 처리 등 모든 체제 활동을 하나의 프로세서, 즉 마스터 서버가 처리한다. 다른 프로세서는 사용자 코드만 실행하게 되는데 이를 비대칭 다중 프로세싱 asymmetric multiprocessing 이라고 한다. 이는 한 코어만 시스템 자료 구조에 접근하게 되어 자료 공유의 필요성도 줄어들어 단순하게 된다. 단점이라면 전체 성능이 낮아질 수 있다.
대칭 다중 프로세싱
일반적으로 다중 프로세서를 처리하는 법은 대칭 다중 프로세싱 symmetric multiprocessing(SMP) 이다. 이때 각 프로세서는 자기 스스로 스케줄링을 하고 각 스케줄러가 준비 큐를 확인하고 실행할 스레드를 선택한다. 이때 2가지의 전략이 나오게 되는데:
- 모든 스레드가 동일한 준비 큐를 사용한다.
- 각 프로세서마다 개인 스레드 큐를 가진다.
위의 전략들은 아래 그림에서 확인이 가능하다.

첫 번째의 경우에는 공유된 준비 큐에 대한 경합 조건이 설정되므로 두 프로세서가 동일한 스레드를 스케줄링하지 않도록, 그리고 스레드가 큐에서 사라지지 않도록 확인해야 한다.
두 번째의 경우에는 각 프로세서가 개인 실행 큐를 가지는 것이다. SMP에선 두번째 방법이 젤 일반적이다.
5.5.2 Multicore Proessors
보통 SMP 체제는 여러 개의 물리적인 프로세서들을 바탕으로 프로세스를 병렬 처리했다. 요즘 현대 컴퓨터 하드웨어는 다중 연산 코어를 하나의 칩에 넣고 다중 코어 프로세서 multicore processor 구조로 간다. 각 코어는 구조를 갖는 상태를 가지므로 운영체제 입장에선 분리된 논리 CPU로 인식된다. 다중 코어 프로세서를 사용하는 SMP 체제가 사실 CPU마다 물리적인 칩을 갖는 경우보다 더 빠르고 전력도 덜 먹는다.
다중 코어 프로세서 덕에 스케줄링이 조금 복잡해지기 시작했다. 예를 들어 프로세서가 메모리에 접근할 때, 해당 메모리의 자료를 사용할 수 있을 때까지 대기하는 시간이 생각보다 꽤 된다. 이럴 때 메모리 지연 memory stall 이 발생하게 된다. 이 이유는 요즘 프로세서가 메모리보다 더 빨라서 발생하게 된다. 근데 이 뿐만 아니라 캐시 미스(캐시 메모리에 없는 자료를 접근함.) 때문에 발생하기도 한다.
아래 그림이 메모리 지연인 경우이다. 이 경우 프로세서는 자료가 사용할 수 있을때까지 대기하는데 자기 시간의 50%를 사용한다고 한다
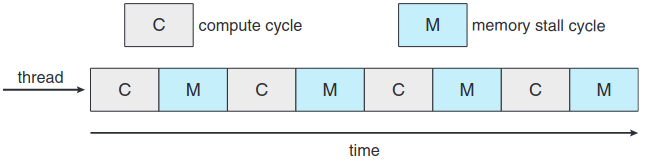
메모리 지연인 상태를 해결하기 위해 두개 이상의 하드웨어 스레드 hardware thread가 각 코어에 할당되는 다중 프로세싱 코어를 구현한다. 이러면 한 하드웨어 스레드가 메모리에 대기하느라 지연되면 다른 스레드로 교환할 수 있게 된다. 아래 그림이 이중 스레드 프로세싱 코어이다.
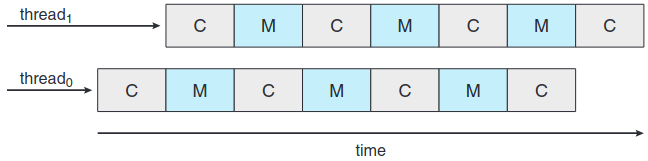
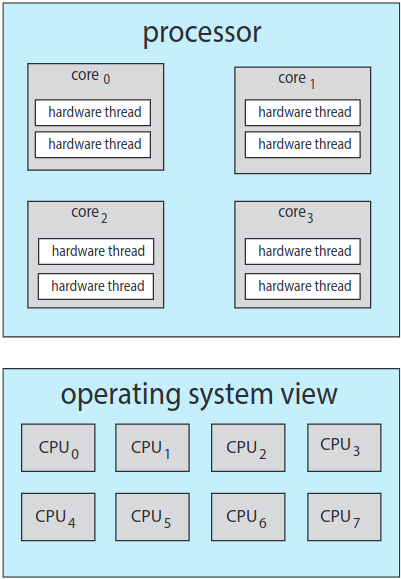
운영체제 입장에서는 각 하드웨어 스레드가 각자 구조적 상태(명령어 포인터, 레지스터 집합 등)을 유지하므로 마치 소프트웨어 스레드를 돌릴 수 있는 논리 CPU로 보인다. 이 기술을 칩 멀티스레딩 chip multithreading(CMT) 라고 부른다. 아래 그림 같은 경우 프로세서가 네 개의 연산 코어를 갖고, 각 코어마다 2 개의 하드웨어 스레드를 가지는데 이 때 운영체제의 입장에서는 논리 CPU가 8개인 것이다.
프로세싱코어를 멀티 스레딩하는 방법
- 조립 coarse-grained 멀티 스레딩
- 세립 fine-grained 멀티 스레딩
조립 멀티 스레딩
메모리 지연과 같이 지연 속도가 긴 이벤트 발생 전까지 스레드가 코어에서 실행된다. 이때 지연이 길기 때문에 코어는 반드시 다른 스레드로 교환해야 된다. 하지만 스레드 간 교환 시 기존 스레드가 사용하던 명령어 파이프 라인을 깨끗이 비워야 새 스레드가 사용할 수 있기 때문에 교환 비용이 높다.
세립 멀티 스레딩
조립 멀티 스레딩보다 더 세밀하게 교환이 이루어진다.
보통 명령어의 경계에서 일어나게 되는데 세립 체제에서 구조적 설계에서는 스레드 교환에 대한 로직도 포함되기 때문에 스레드 간의 교환 비용이 적다.
물리적인 코어 자원들(캐시, 파이프 라인 등)이 반드시 하드웨어 스레드 간 공유가 되어야한다. 그래서 프로세싱 코어는 한 순간 마다 한 스레드만 실행이 가능하다. 그러면 아래 그림처럼 사실상 멀티 스레드 다중 코어 프로세서는 두 가지 스케줄링 단계를 가진다.

첫 번째 단계는 운영체제가 어떤 소프트웨어 스레드를 어떤 하드웨어 스레드(논리 CPU)에 돌릴지를 결정하는 스케줄링을 결정한다. 여기서는 5.3 단원에 있었던 스케줄링 방법 중 아무거나 고르면 된다.
두 번째 단계는 코어가 어떤 하드웨어 스레드를 실행시킬지 결정하는 스케줄링이다.
여기서는 여러 전략이 있는데, 먼저 그냥 단순하게 라운드 로빈 알고리즘으로 하드웨어 스레드를 프로세싱 코어에 스케줄링하기가 있다. ULTRASPARC T3가 실제 이 방법을 사용한다. 또 다른 방법으로는 인텔 Itanium이라는 코어 당 하드웨어 스레드가 두 개인 듀얼 프로세서에서 사용한 방법이 있다. 이 방법의 경우 하드웨어 스레드마다 동적으로 0과 7 사이의 긴급도 urgency 값을 부여한다. 0에서 7순으로 긴급도가 올라간다.
여기서 두 단계의 스케줄링이 꼭 상호 배타적이지는 않다. 사실 운영체제 스케줄러는 프로세서 자원 공유에 대한 지식이 있기 때문에 더 효율적으로 스케줄링 결정을 내릴 수 있다. 예를 들어 프로세싱 코어가 2개 있는 CPU에 각 코어가하드웨어 스레드 2개 씩 있다고 가정해보자. 이때 소프트 웨어 스레드 2개가 지금 돌고 있으면 같은 코어에서 실행될 수도 별개의 코어에서 실행될 수도 있다. 둘 다 같은 코어에서 실행되도록 스케줄링 되면 프로세서 자원을 공유하니까 따로 하는 것보다는 느릴 것이다.
5.5.3 Load Balancing
SMP 체제에서는 부하 분산 load balancing을 통해 프로세스 간 작업을 고르게 분산해서 다중 프로세서의 이득을 최대한 봐야된다. 특히 프로세서가 각자 개인 준비 큐가 있는 체제에서 필요하다.
부하 분산에 접근할 수 있는 두가지 방법
Push Migration
특정 작업이 현재 각 프로세서의 부하를 확인하고, 불균형하다 싶으면 스레드 간 부하를 덜 바쁘거나 놀고 있는 프로세서로 옮겨준다.
Pull Migration
놀고 있는 프로세서가 바쁜 프로세서에서 대기 중인 작업을 갖고 오는 것이다.
이때 푸시와 풀 이동은 상호 배타적일 필요가 없고, 사실 부하 균형체제에서 병렬적으로 구현하는 편이다.
5.5.4 Processor Affinity(프로세서 친화도)
스레드는 프로세서에서 돌 때 스레드에서 자주 접한 자료가 프로세서의 캐시에 들어간다. 이때 캐시 메모리 안에 스레드에 의해 메모리 접근이 성공적으로 이루어진다.(이것을 "warm cache"라고 부른다.)
근데 만약 스레드가 부하 분산 등의 이유로 다른 프로세서로 가게 된다면? 그러면 새로운 프로세서의 캐시 메모리 내용이 다를 것이므로 다시 스레드가 사용할 내용으로 채워야 될 것이다. 이때 기존 캐시를 무효화하고 새 캐시로 채우는 과정의 비용이 비싼 편이라 대부분 SMP를 지원하는 운영체제들은 스레드를 프로세서 간 이동시키는 걸 좀 피하려고 한다. 한마디로 최대한 따뜻한 캐시 상태로 유지할려고 하는 것이다. 이를 프로세서 친화도 Processor affinity라고 한다
Soft Affinity
프로세서 친화도에는 여러가지 형태를 가진다.
운영체제가 최대한 프로세스를 같은 프로세서에게 돌게 정책을 짰더라도, 그걸 보장하지 않으면 약친화도 soft affinity 를 갖는다고 한다. 즉, 프로세스를 한 프로세서에 유지는 하겠다고는 하지만 부하 분산 때 프로세스가 다른 프로세서로 이동될 수 있다는 점이다.
Hard Affinity
반대의 경우, 강친화도 hard affinity로, 프로세스가 자기가 돌아갈 프로세서들을 명시해주는 것이다. 대부분 체제들을 둘 다 전부 가지고 있다.
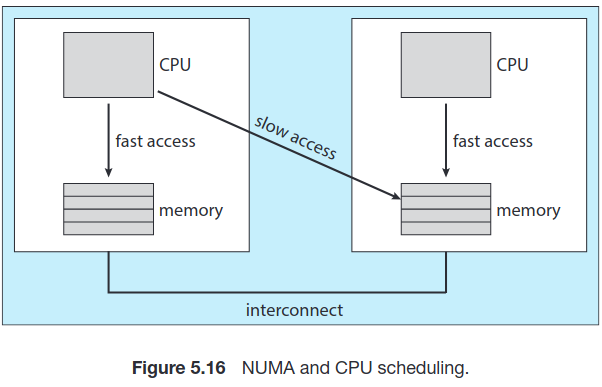
시스템의 주 메모리 구조도 프로세서 친화도에 영향을 준다. 아래 그림은 각자 CPU와 지역 메모리를 갖는 물리적인 프로세서 칩 두 개에서의 비균등 메모리 접근(NUMA)이다. NUMA 체제에서 CPU 간 상호연결해서 서로 같은 메모리 공간을 사용하더라도 당연히 남의 메모리보다는 자기 메모리 접근이 더 빠르다. 만약 운영체제의 CPU 스케줄러와 메모리 배정 알고리듬이 NUMA를 인식하고 있다면 특정 CPU에 스케줄링된 스레드는 해당 CPU와 제일 가까운 메모리에 할당이 될 것이다.
5.6 Real-Time Cpu Scheduling
5.6.1 Minimizing Latency
실시간 체제가 이벤트 기반인 것을 알아야한다. 시스템은 전형적으로 보통 이벤트가 발생할 때까지 대기하는데, 이벤트는 보통 타이머 종료같은 소프트웨어 이벤트랑 센서처럼 하드웨어 이벤트가 발생한다. 이때 이벤트가 발생 시 최대한 빠르게 대응해야되는데, 이때 발생 시간부터 서비스 된 시간 까지를 이벤트 지연속도 event latency라고 한다.

대개 이벤트 별로 지연속도가 다르다. 어떤 경우는 3에서 5ms 내로 처리할 수 있는 경우도 있고, 어떤 경우는 몇 초까지 봐주는 경우도 있다.
실시간 체제에 성능에 영향을 주는 지연 속도를:
- 인터럽트 지연속도
- 디스패치 지연속도
인터럽트 지연속도
인터럽트가 CPU에 도착하는 시점부터 이에 대응하는 서비스가 시작할 때 까지를 의미한다.
인터럽트가 발생하면 운영체제는 일단 자기가 실행 중이던 명령어를 끝내고 나서 무슨 인터럽트인지 확인한다. 그리고 현재 프로세스의 상태를 저장하고 특정 인터럽트 서비스 루틴(ISR)에 따라 서비스를 한다. 이때 걸린 총 시간이 인터럽트 지연속도이다.
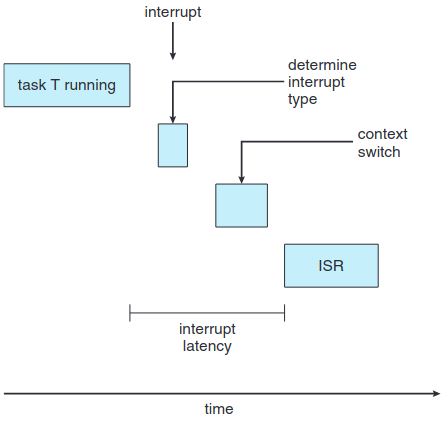
당연히 이 지연 속도를 줄이는 것이 좋다. 특히 강실 시간 체제면 지연속도를 단순히 하는 것 뿐만 아니라, 이 시스템의 필요요소까지도 맞춰야한다.
인터럽트 지연 속도에 기여하는 요소 중 하나는 커널 자료구조가 갱신 중에 얼마나 인터럽트가 비활성화되는 것이다. 실시간 운영체제는 이때 인터럽트를 정말 짧은 시간만 비활성화 해야된다.
디스패치 지연속도
여기서 한 프로세스를 멈추고 다른 걸 실행하기 위한 디스패처를 스케줄링하는데 걸린 시간이 디스패치 지연속도 dispatch latency이다. CPU에 즉시 접근해야되는 경우 이 지연속도도 줄여야한다. 가장 효과적인 방법은 선점적인 커널을 제공하는 것이다. 강실체제의 경우 디스패치 지연속도가 보통 몇 ms 수준이다.
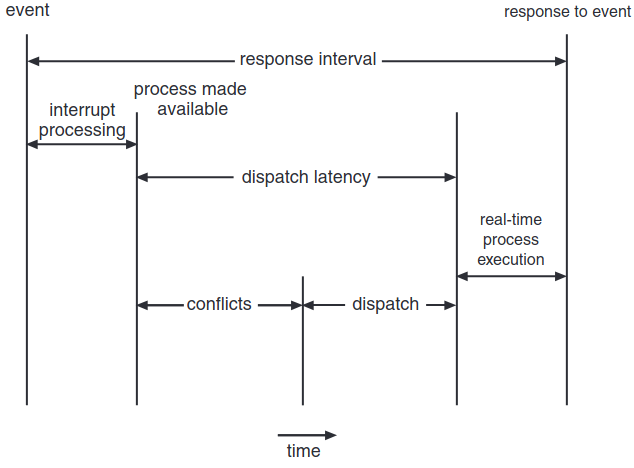
위의 그림에서 디스패치 지연속도의 conflict phase에서는 두 성분으로 구성된다:
- 커널에서 도는 임의의 프로세스를 선점한다.
- 고우선순위 프로세스가 필요로하는 자원을 저우선순위 프로세스에서 뺏기.
충돌 단계 이후에는 디스패치 단계가 고우선순위 프로세스를 CPU에 스케줄링한다.
5.6.2 Priority-Based Scheduling
실시간 운영체제에서 제일 중요한 기능은 실시간 프로세스가 CPU가 필요할 때 즉시 대응하는 것이다. 그러므로 실시간 운영체제는 반드시 선점적 우선순위 기반 알고리즘이 되어야 한다.
그러나 선점적 우선 순위 기반 스케줄러로는 약실시간 밖에 안된다. 강실시간까지 가려면 마감 시간 소요까지 적용해야하므로 추가적인 스케줄링 기능이 필요하다.
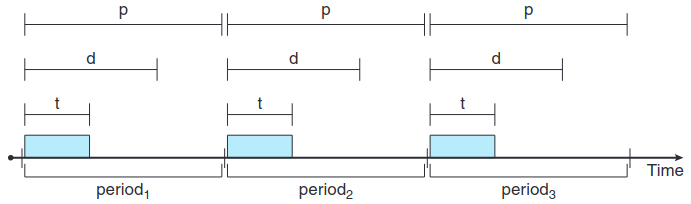
각 스케줄러 다루기 전 우선 스케줄링할 프로세스의 특징을 알아야 될 필요가 있다. 우선 프로세스는 주기적 periodic이다. 위의 그림은 시간에 대한 주기적 프로세스의 실행에 대한 그림이다.
프로세스가 주기적이라는 것은 상수 기간(주기)마다 CPU를 필요로 한다는 뜻인데 이때 CPU를 얻으면 고정된 처리 시간 t가 있고, 마감 기한 d 전에 처리해야된다. 또한 주기 p가 있다. 이 관계는 0 ≤ t ≤ d ≤ p 이다. 그래서 주기적 작업의 주기율 rate는 1/p이다.
5.6.3 Rate-Monotonic Scheduling
비율 단조 rate-monotonic 스케줄링 알고리즘이란 정적 우선순위 정책을 통해 주기적 작업을 선점적으로 스케줄링한다. 이때 주기적 작업은 시스템에 들어온 순간 자기 주기의 역수를 우선 순위로 가진다. 이때 정적 우선순위 정책을 쓰는 이유는 한마디로 CPU 자주 쓰는 애한테 우선 순위를 계속 주겠다는 뜻이다.
예시1
두 프로세스 P1 P2가 있다. 각각 주기는 p1 = 50, p2 = 100이고, 처리 시간은 t1 = 20, t2 = 35라고 가정하자. 이때 마감 기한의 경우 각 프로세스마다 다음 주기 시작전에는 CPU버스트를 다 써야한다.
우선 마감기한에 맞추어 스케줄링이 가능한지 봐야한다. 프로세스의 CPU 효율을 버스트/주기로 가정하면, P1은 0.4, P2는 35/100d으로, 총 75%이다. 그래서 마감기한을 시키면서 CPU 사이클에 여유분을 남길 수 있다.
이때 P2가 P1보다 우선순위가 높다고 가정하면 아래 그림처럼 될 것이다. P2가 우선 실행되고, 시간 35에서 끝나고, 이후 P1이 시작하고 자기 CPU 버스트를 55에 끝낸다. 그러나 이때 P1의 마감기한은 50이므로 스케줄러가 마감기한을 놓치게 된다.

그러나 이때 비율단조 스케줄링을 적용하면 P1이 우선순위가 더 높아질 것이다. 이 경우엔 아래 그림처럼 P1이 먼저 시작하고 자기 CPU 버스트를 20에 끝내서 마감 기한 지킨다. 다음 P2의 경우 50까지 돌고, 이 순간 5 ms가 남아있어도 P1에 의해 선점 당한다. P1이 70에 종료되면 P2가 75에 종료되어 마감 기한 지킨다. 100까지 가만히 있다가 다시 P1부터 재시작하게 된다.

예시2
비율 단조 알고리즘은 프로세스가 이 알고리즘에 의해 스케줄링이 안된다면, 정적 우선순위를 갖는 다른 모든 알고리즘에서도 스케줄링이 안된다는 점에서 최적이다.

P1의 주기 p1 = 50, CPU 버스트 t1 = 25이고 P2의 경우 p2 = 80, t2 = 35이다. 이때 총 CPU 효율은 (25/50) + (35/80) = 0.94로 충분하다. 하지만 아래 그림 보면 알겠지만 우선순위가 더 높은 P1이 처리되고, P2처리하다가 선점적으로 P1이 다시처리된다. P1이 끝나고 P2해봤자 85에서 끝나서 마감 기한인 80이 지나게된다.
이것이 제일 최적화한것이지만 한계점이 존재한다는 것을 할 수 있다:
->CPU 효율이 제한되고, 언제나 CPU 자원을 100%로 최대화하기 힘들다는 점이다.
5.6.4 Earliest-Deadline-First Scheduling
최단 마감 우선 earliest-deadline-first(EDF) 스케줄링은 마감기한에 따라 동적으로 우선순위를 부여한다. 마감 기한이 빠른 순으로 우선순위를 부여하는 것인데, 프로세스가 실행 가능할 때 반드시 시스템에 자기 마감 기한 소요를 알려줘서 우선순위를 갱신해야 한다.
아래 그림은 EDF 스케줄링의 예시를 나타낸 그림이다. 이때 p1 = 50, t1 = 25, p2 = 80, t2 = 35라고 하자. 이때 P1이 마감기한이 더 빠르니까 우선순위가 더 크다. P1이 끝나고나서 P2가 실행이 되는데, 비율 단조 스케줄링알고리즘과는 다르게 선점이 불가능하다. 그러므로 P2가 다 돌아갈 때 까지 P1은 기다려야한다. 그렇게 계속 진행하여 145부터 150까지 진행하게된다.

비율 단조 알고리즘과 달리 프로세스가 굳이 주기적이지 않아도 되고, 버스트 당 상수 CPU 시간을 필요로 하지도 않는다. 그냥 실행 가능할 때 마감 기한만 스케줄러한테 알려주면 된다. 이론적으론 최적이고, CPU 효율도 100%라는 점에서 매력적이다. 실무에서는 근데 프로세스 간 문맥 교환이랑 인터럽트 처리 때문에 그 수준의 CPU 효율은 불가능하다고 한다.
5.6.5 Proportional Share Scheduling
비례적 proportional share 스케줄러는 모든 어플리케이션에 T만큼의 지분을 할당해준다. 어플리케이션은 N 개의 시간 지분을 받을 수 있어 모든 어플리케이션이 총 프로세서 시간의 N/T를 가진다. 예를 들어 총 T = 100의 지분이 있고, 이걸 A, B, C에 각각 지분을 50, 15, 20으로 준다고 가정하자.
비례적 스케줄러는 승인 제어 정책과 같이 협력해서 어플리케이션이 자기 지분만큼의 시간을 받도록 보장해야 한다. 물론 충분한 지분이 남아있어야 클라이언트의 요청을 받아줄 수 있다. 이때 예시의 경우 50 + 15 + 20 = 85 지분이니 여유 있음. 만약 새 프로세스 D가 지분 30 요청하면 승인 제어가 D를 거부시킬 것이다.
