나는 object detect나 image segmentation 같은 경우 yolo보다 detectron으로 먼저 접해서...남들이 욜로 욜로 하는데 자신이 없었다.
근데 v5는 쓰기 쉽게 나와있더라... 좋았음.
문제는 프로젝트 하는 os에 v5가 안 올라가서 v4로 해야된다는 사실...?ㅎㅎㅎ;;; 어떻게든 되겠지. 장관상 타면 좋고...아니어도 이것저것 다뤄본거에 후회는 없을듯
yolo format 라벨링은 labelImg로 할 수 있다.
detectron은 labelme로 했었다.
둘의 차이점은 detectron은 직접 코드상에서 사용자 함수를 만들어서 json 데이터셋을 만드는... 그러고 register한 뒤에 쓸 수 있다. 난 이 과정이 재밌더라 ㅎㅎ 하나로 뭉쳐져 있어도 재밌고 나눠져있음 편하고~ yolo는 format이 대중적이라 좋다. 근데 안 맞으면 좌표계산해서 바꿔줘야함...
얘네가 킬 때 마다 라벨링 순서가 뒤바뀌는거 빼면 뭐....
미리 지정해서 한번에 몰아서 라벨링하면 되니까 괜찮다.
노동의 시간이...ㅎㅎ... ..ㅎㅎㅎ... 눈알 아프겠다.
~yolov5 사용법부터 opencv랑 matplotlib으로 결과 확인까지~
1. roboflow dataset download
%cd /content/drive/MyDrive/yolo_sample
!curl -L "https://app.roboflow.com/ds/XsDCLg5ive?key=XxwLZ3UeLe" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
작업경로로 이동해서 zip파일 삭제까지!
data 찾기 귀찮아서 roboflow에 있는 걸 예제로 썼다.
format만 잘 맞으면 귀찮은 일 없이 쭉 업로드 되어서 꿀임..
Universe 탭에서 데이터를 검색해서 찾을 수도 있고
Project > WorkSpace에서 데이터 올려서 위의 명령어 사용해도 된다.
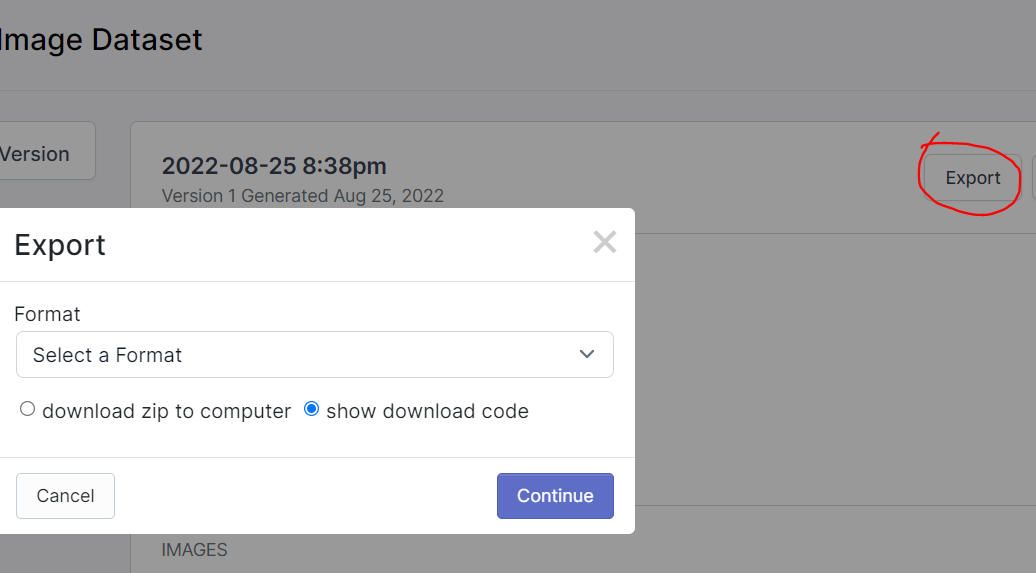
참고로 위의 명령어는 Export 누르고 Format 지정하고 download code 선택하면 복사할 수 있게 나옴. 세상 편하다~
2. yolov5 github repository clone & libary install
%cd /content/drive/MyDrive/yolo_sample
!git clone https://github.com/ultralytics/yolov5.git
%cd /content/drive/MyDrive/yolo_sample/yolov5
!pip install -r requirements.txt필요한거 install하고~ 사실 yaml 파일 만드는게 제일 중요한듯
3. data.yaml path set up
학습 데이터의 경로, 클래스 갯수,종류를 설정
학습데이터 경로
train: train/images
val: valid/images
test: test/images
클래스 수
nc: 2
클래스 이름
names: ["필요한","만큼ㅎㅎ"]
이건 그냥 솔직히 적당히...경로 맞춰서...glob 써서 경로 뽑아낸 다음 txt 파일에 write하고,
train_img_list = glob('/content/drive/MyDrive/yolo_sample/train/images/*.jpg') + glob('/content/drive/MyDrive/yolo_sample/train/images/*.jpeg')
with open('/content/drive/MyDrive/yolo_sample/train.txt', 'w') as f:
f.write('\n'.join(train_img_list) + '\n')이런식으로...train, valid, test 전부! valid는 없으면 생략~
import yaml
with open('/content/drive/MyDrive/yolo_sample/data.yaml', 'r') as f:
data = yaml.load(f, Loader=yaml.FullLoader)
data['train'] = '/content/drive/MyDrive/yolo_sample/train.txt'
with open('/content/drive/MyDrive/yolo_sample/data.yaml', 'w') as f:
yaml.dump(data, f)
yaml load해서 경로가 다 적힌 txt파일의 path를 dump까지
4. model train
%cd /content/drive/MyDrive/yolo_sample/yolov5
!python train.py --img 416 --batch 16 --epochs 100 --data /content/drive/MyDrive/yolo_sample/data.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt --name ocean_result3model train은 더 별거 없음
그냥 이동해서 설정하고 train~
--img : input image size
--batch : batch size
--epochs : epochs 훈련 횟수
--data : yaml 경로
--cfg : pretrained model (ex. yolov5m.yaml)
--weights : pretrained model weight (ex. yolov5m.pt)
--name : 학습정보 저장 폴더 이름 (yolov5/runs/train/이름)
이건 파라미터들 cfg 종류는 나노있고 스몰있고 미디움 있고 이런식..
5. result
%cd /content/drive/MyDrive/yolo_sample/yolov5
!python detect.py --weights /content/drive/MyDrive/yolo_sample/yolov5/runs/train/ocean_result/weights/best.pt --img 416 --conf 0.5 --source /content/drive/MyDrive/yolo_sample/test/images/CD_10494_jpg.rf.fbad05f9670bf5ab61678d86c6482ae4.jpg이동해서 --source 뒤에 결과 확인할 이미지나 영상 경로를 넣어준다.
--conf는 threshold의 개념! 0.5넣음 신뢰도 50이상인 객체만 detection 한다.
6. result + @
단순하게 5번처럼 확인만 하면 아까우니까~.~
import cv2
import torch
import matplotlib.pyplot as plt
%matplotlib inline
#model 로드
model_label = torch.hub.load('/content/drive/MyDrive/yolo_sample/yolov5', 'custom', path='/content/drive/MyDrive/yolo_sample/yolov5/runs/train/underwater_result/weights/best.pt', source='local')
video_file = "https://www.youtube.com/watch?v=CGP_sBC5oc4"#"/content/drive/MyDrive/yolov5/yolov5/mask_test.mp4" # 동영상 파일 경로
cap = cv2.VideoCapture(video_file) # 동영상 캡쳐 객체 생성
if cap.isOpened(): # 캡쳐 객체 초기화 확인
while True:
ret, img = cap.read() # 다음 프레임 읽기
if ret: # 프레임 읽기 정상
results = model_label(img)
results = results.pandas().xyxy[0][['name','xmin','ymin','xmax','ymax']]
for num, i in enumerate(results.values):
cv2.putText(img, i[0], ((int(i[1]), int(i[2]))), cv2.FONT_HERSHEY_SIMPLEX, 2,(0, 0, 255), 3)
cv2.rectangle(img, (int(i[1]), int(i[2])), (int(i[3]), int(i[4])), (0, 0, 255), 3)
# cv2.imread는 BGR로 불러오므로 plt를 이용하려면 RGB로 바꿔줘야 함
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(imgRGB)
plt.show()
#cv2.imshow(imgRGB)
else: # 다음 프레임 읽을 수 없음,
break # 재생 완료
else:
print("can't open video.") # 캡쳐 객체 초기화 실패
cap.release() # 캡쳐 자원 반납
cv2.destroyAllWindows()연속적으로 확인!

이런식으로 나온다. pafy써서 유튜브 영상 갖고와서 해도 되고 webcam 존재하면 cv2.VideoCapture를 0으로 설정해서 local에서도 써도 됨
!pip install pafy
!pip install youtube-dl==2020.12.2위의 두 명령어 필요~
class가 많으면 class마다 bounding box랑 text색을 dict로 미리 정의하고 바꿔놓는게 훨씬 눈에 잘 들어옴
(0,0,255) 부분을 color_dict[i[0]] 이런식으로
v4를 쓴다면...그것도 따로 정리하는 걸로 하겠다.
쓸 것 같음..... soda os ....정말 열받는군....
뭐 하나 버전 밀면 안 되고 뭐 다른거 건드려도 안 되고 라이브러리 패치도 안 되어 있고...하나하나 내가 찾아서 수정하다가 ㅎㅂㅈㅈ에서 내가 돈 받아야될 지경이길래 열받아서 때려침
v5 다른 프로젝트에 쓸 것 같아서 복습차 ㅎㅎ 데이터가 엉망이라 걱정이다...진짜..... 그래도 뭐라도 되겠지ㅋㅎ 10%만 잡아도 감지덕지한 수준의 데이터라고 본다...
