
이전에 정리한 내용들은 논문을 처음 읽기 시작하던 때라 정리가 미흡하고 설명이 부족한 것 같아 보충해서 재업로드한당 😊
Abstract & Introduction
- 기존 방법: 복잡한 RNN/CNN 기반의 모델을 사용
- 문제점
- Long term dependency (장기 의존성 문제)
- 긴 시퀀스에대해 병렬처리 불가
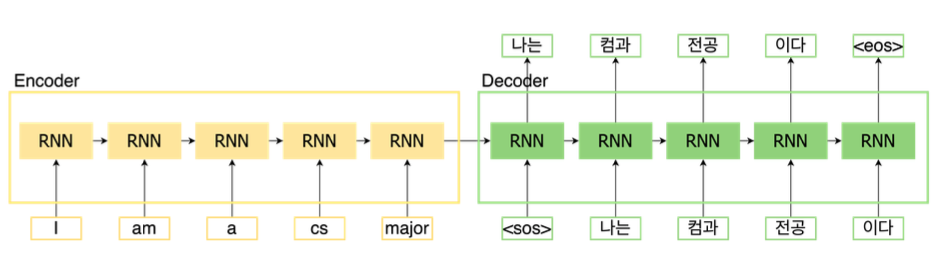
예시에서 볼 수 있 듯 문장의 단어가 하나 하나 처리되기 때문에 처리 속도에 문제가 생길 것이다.
또한, RNN의 구조를 생각해보면 바로 직전에대해서 더 많이 의존하기 때문에 문장이 길어진다면 장기 의존성문제가 발생할 수 있다!
그래서 논문에서는 어떻게 해결했을까?
그 유명한 Transformer를 제안한다.
오로지 attention 매커니즘을 사용하여 앞에서 설명한 단점 (병렬처리 불가 & 장기의존성)등의 문제를 해결할 수 있었다고 한다.
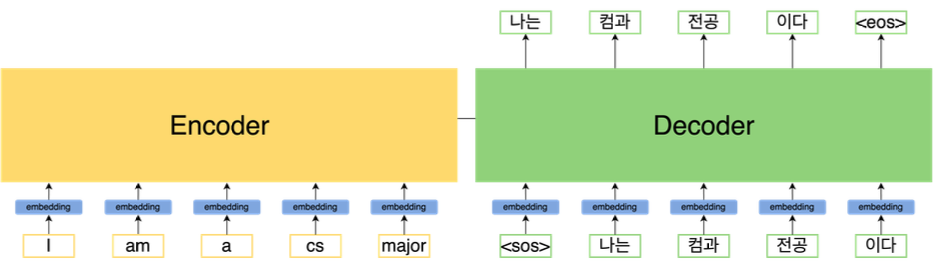
위의 구조와 다르게 문장 자체가 input으로 들어가 병렬화가 가능해진다.
Background
- Transformer에서 sequential computation이 multi-head attention으로 상수로 감소
- Self-attention은 특정 input이 있을대 그 input들 끼리 서로 attention 수행해 학습
ex ) I am a student → 4개의 단어가 서로 attention 수행
- End-to-end memory network는 recurrent attention에 기반 → simple-language question answering과 같은 task에서 좋은 성능
Model Architecture
a. Encoder and Decoder Stacks
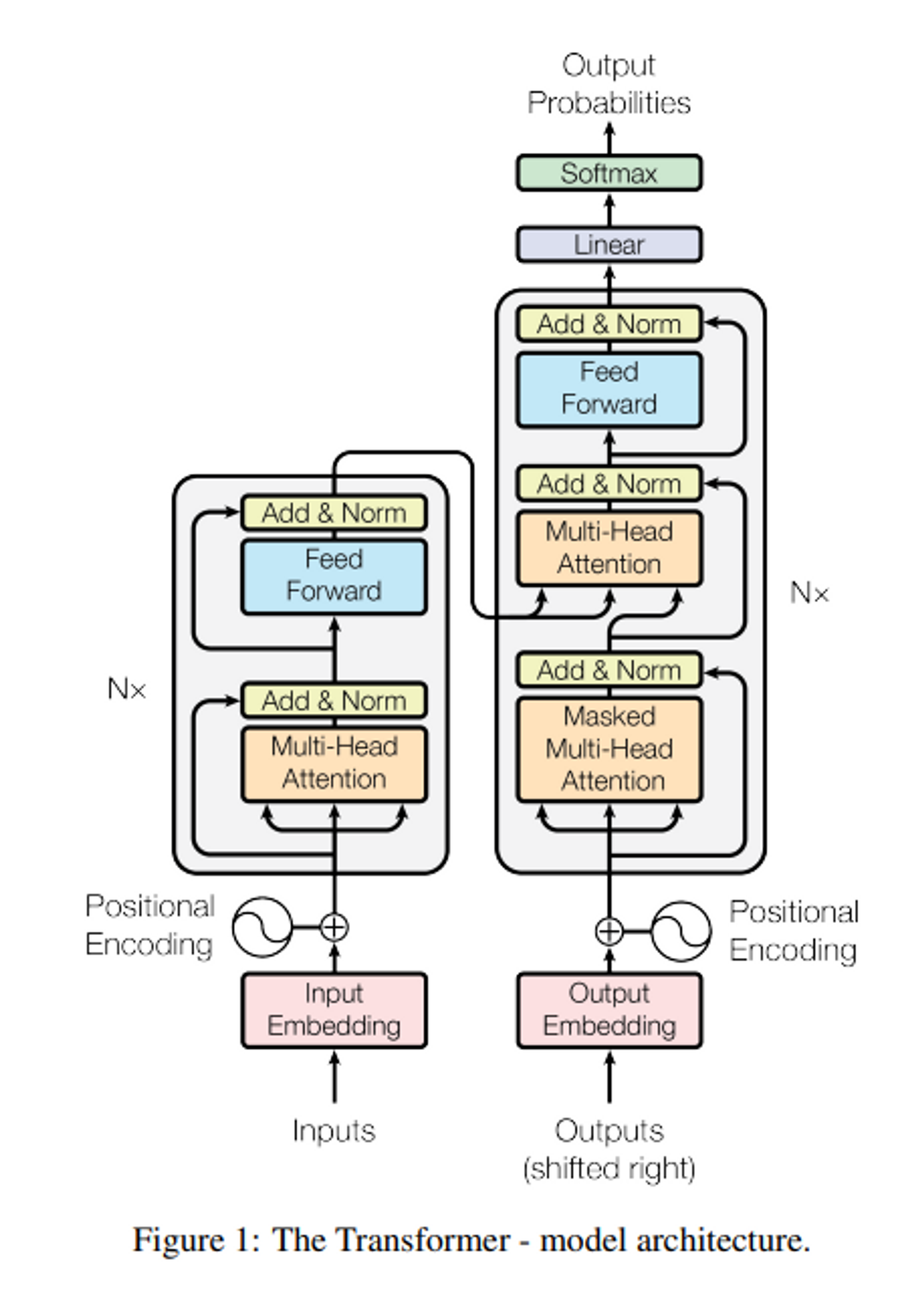
- Encoder
1 ) 6개의 identical layer로 구성 / 각 layer는 두 개의 sub-layer 존재
- 첫 번째 sub-layer : multi-head self-attention mechanism
- 두 번째 sub-layer : simple, position-wise fully connected feed-forward network
2 ) 두 개의 sub-layer에 layer normalization 후에 residual connection 사용
- sub-layer의 output 은
- Decoder
- Encoder와 마찬가지로 6개의 identical layer로 구성
- 각 layer는 두 개의 sub-layer 이외의 encoder 스택 출력을 통해 multi-head self-attention을 수행하는 3 번째 sub-layer 추가
- Encoder아 마찬가지로 residual connection & layer normalization
- Decoder는 순차적으로 결과를 형성해야함 → masking을 이용해 position i 보다 작은 (미리 알고 있는) output들에만 의존b. Attention
- query, key-value 쌍을 output에 mapping 하는 것이 attention function의 기능- Scaled Dot-Product Attention
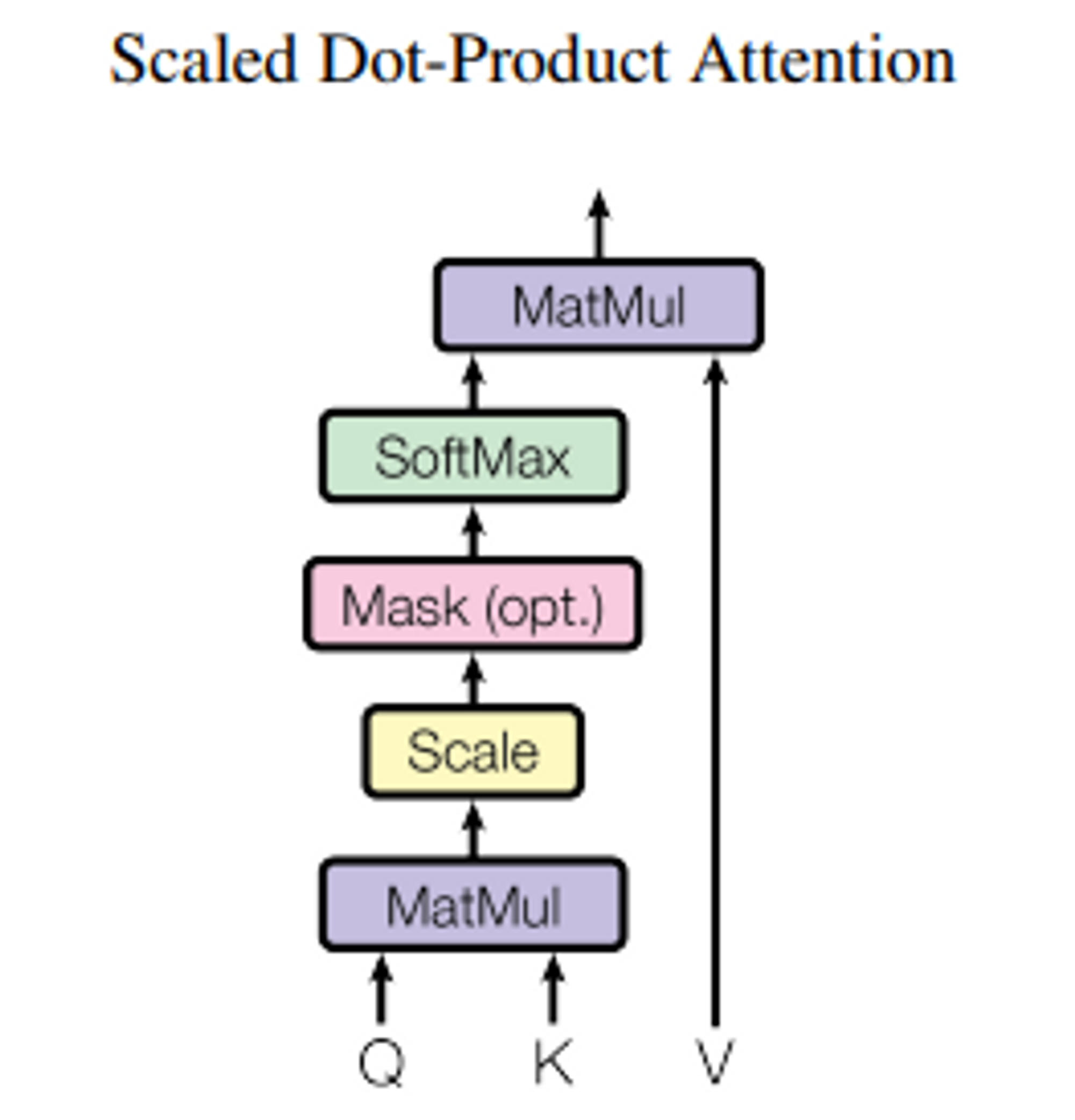
- Input : queries, key의 차원 , value의 차원 → Q, K, V
- 모든 Q와 K 내적 → 로 나누기 → V에 weight 적용하기 위해 softmax 적용
- Scaled Dot-Product Attention
📌 2가지 attention functions
1. Additive attention : single hidden layer로 feed-forward layer network 사용해 compatibility 계산
2. Dot-product attention : Scaling factor만 제외하면 이 논문의 attention과 동일
→ Dot-product attention이 더 빠르고 space-efficient함
-
Scaled Dot-Product Attention
-
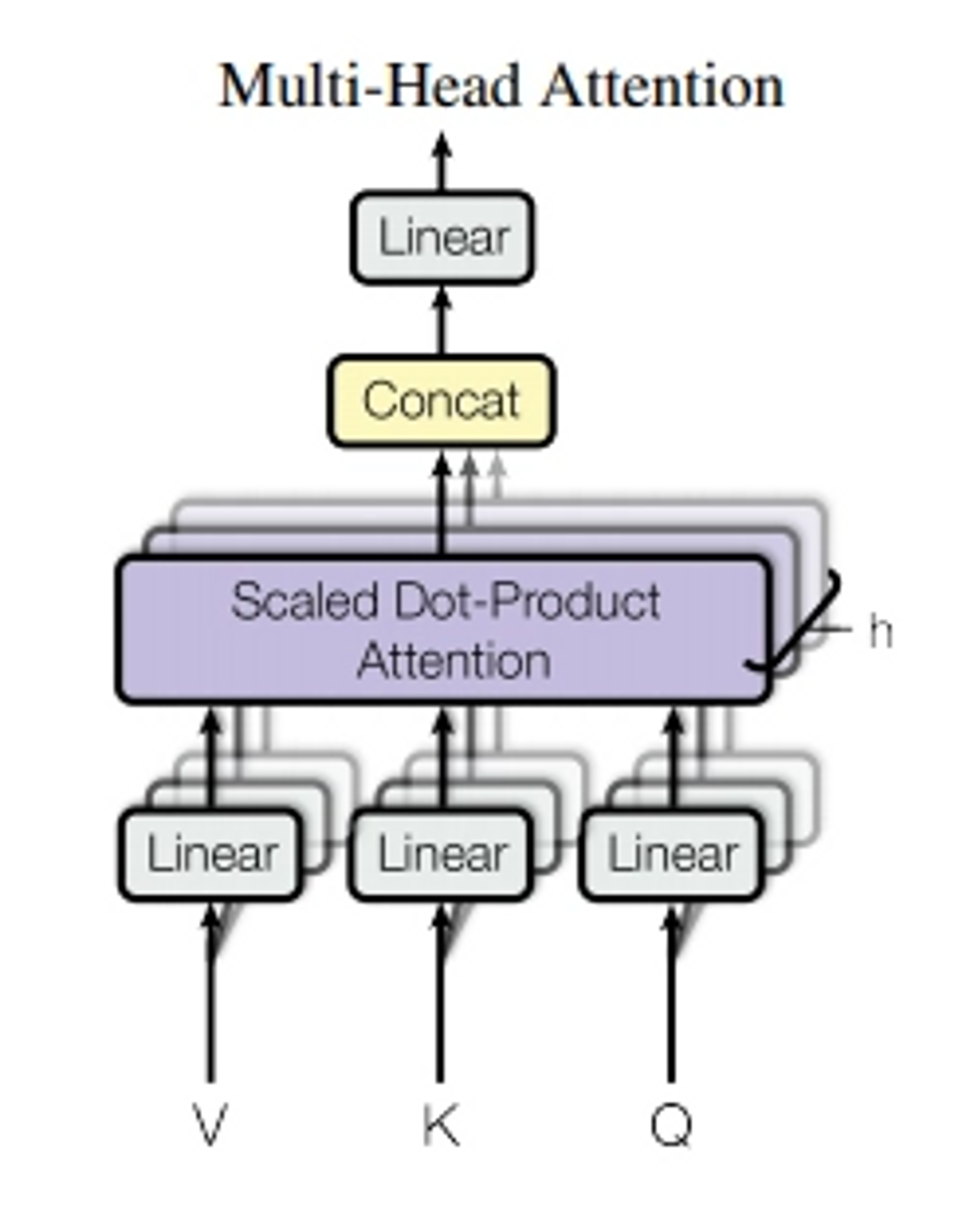
Multi-Head Attention
-
Q, K, V를 h번 서로 다른 학습된 linear projection으로 각 차원에 linear하게 project하는 것이 효과적임
-
project된 값들은 병렬적으로 attention function을 거쳐 output value 형성
-
즉, multi-head attention은 동시에 head 개수만큼의 attention을 수행 → 각 head들의 결과를 합쳐 결과 도출
-
multi-head attention을 3가지 다른 방향으로 transformer에서 사용
- encoder-decoder attention layers
- self-attention layer → encoder part
- self-attention layer → decoder part -
Position-wise Feed-Forward Networks
- Encoder/Decoder의 각 층마다 fully-connected feed-forward network 존재
- 이는 각 position 에 따로 따로 동일하게 적용
- ReLU activation을 포함한 2 개의 선형 변환 포함→ FFN은 각 position, 즉 각 단어마다 적용하게 됨
-
Embeddings and Softmax
- 다른 sequence 모델처럼 input/output 토큰들을 의 벡터로 변환하기 위해 사용
- 학습된 임베딩 사용
- decoder output을 다음 토큰 확률로 변환하기 위해 학습된 linear transformation과 softmax 사용 -
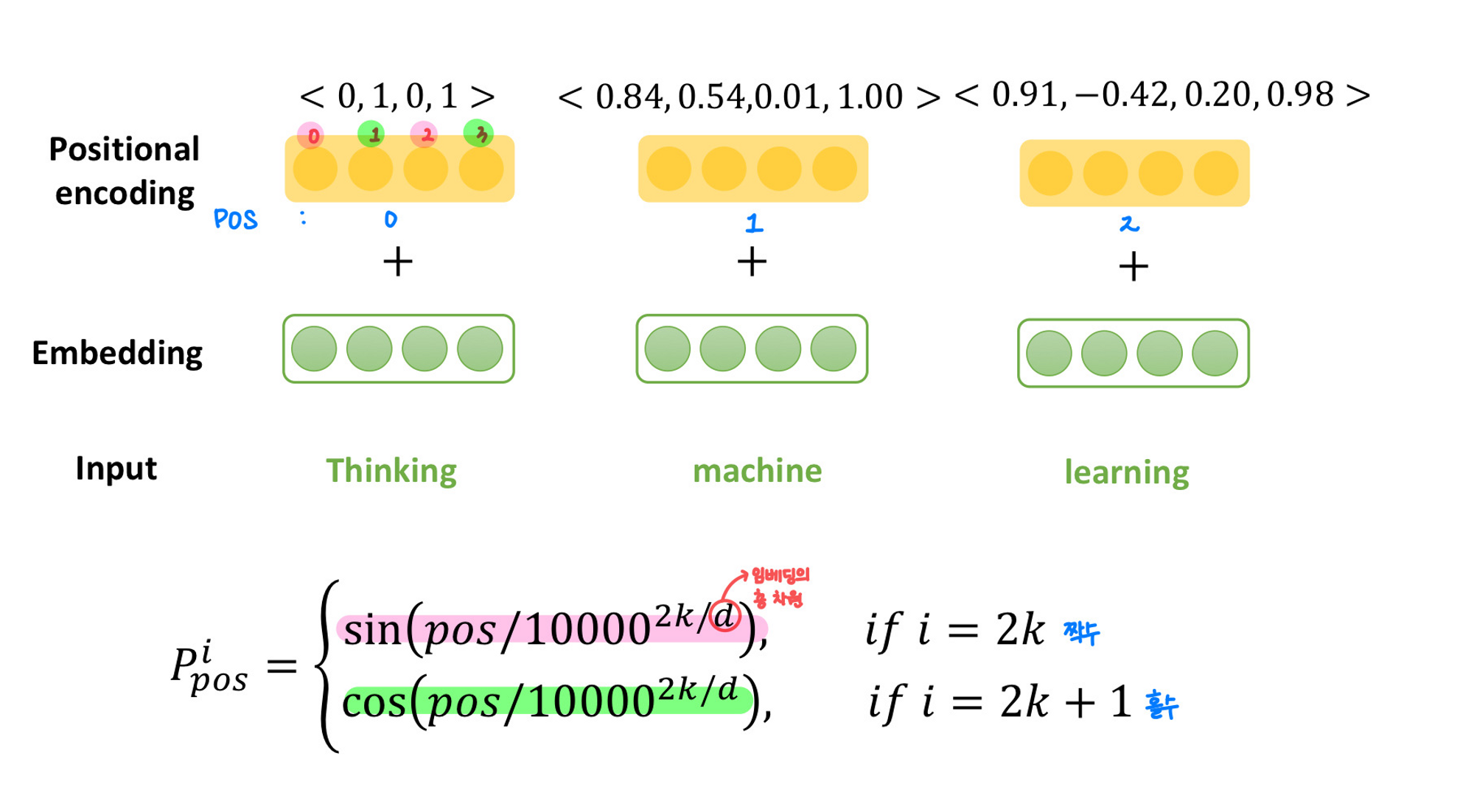
Positional Encoding
- sequence 정보를 처리하고자 하는 것
- encoder와 decoder stack 아래의 input 임베딩에 이를 추가
- sin 과 cos 함수를 이용함
-
-
- Why Self-Attention
- 각 layer마다 전체 계산 복잡도가 감소
- 병렬처리 가능한 계산 증가
- long-range dependency 간 거리 최소화

A TT E N T I ON