📌 우선순위 큐: 우선순위의 개념을 큐에 도입한 자료 구조
- 데이터들이 우선순위를 가지고 있고 우선순위가 높은 데이터가 먼저 나간다.


- 우선순위 큐의 이용 사례
- 시뮬레이션 시스템
- 네트워크 트래픽 제어
- 운영 체제에서의 작업 스케쥴링
- 수치 해석적인 계산 - 우선순위 큐는 배열, 연결리스트, 힙으로 구현이 가능한데 힙으로 구현하는 것이 가장 효율적이다.
📍 왜 우선순위 큐는 배열이나 연결리스트로 구현하지 않을까?
(1) 만일 배열로 구현한다고 가정합니다. 우선순위가 높은 순서대로 배열의 가장 앞부분부터 넣는다면, 우선순위가 높은 데이터를 반환하는 것은 맨 앞의 인덱스를 바로 이용하면 되므로 어렵지 않습니다.
하지만 우선순위가 중간인 것이 들어가야 하는 삽입 과정에서는 뒤의 데이터까지 인덱스를 모두 한 칸씩 뒤로 밀어야 하는 단점이 있습니다.
최악의 경우 삽입해야 하는 위치를 찾기 위해 모든 인덱스를 탐색해야 합니다. 즉 이 때의 시간 복잡도는 자료가 n개라고 할 때 O(n) 이 됩니다. → 배열로 구현 시 시간 복잡도 : 삭제는 O(1), 삽입은 O(n)
(2) 만일 연결리스트로 구현한다고 가정합니다. 이 또한 우선 순위가 높은 순서대로 연결을 시키면, 우선순위가 높은 데이터의 반환은 배열과 마찬가지로 쉽습니다.
하지만 연결리스트 또한 삽입의 과정 또한 배열과 마찬가지로 그 위치를 찾아야 합니다. 최악의 경우 맨 끝에까지 가게 됩니다. → 연결리스트로 구현 시 시간 복잡도 : 삭제는 O(1), 삽입은 O(n)
(3) 우선순위 큐를 힙으로 구현한다고 가정합니다. 힙의 경우 삭제나 삽입 과정에서 모두 부모와 자식 간의 비교만 계속 이루어집니다. (아래에서 다룰 것입니다)
즉, 이진 트리의 높이가 하나 증가할 때마다 저장 가능한 자료의 갯수는 2배 증가하며, 비교 연산 횟수는 1회 증가합니다. 즉 삭제나 삽입 모두 최악의 경우에는 O(log2n) 의 시간 복잡도를 가집니다. → 힙으로 구현 시 시간 복잡도 : 삭제는 O(log2n), 삽입은 O(log2n)
이처럼 배열이나 연결 리스트가 삭제에서는 시간 복잡도의 우위를 점할지라도, 삽입의 시간 복잡도가 힙 기반이 월등하기 때문에, 편차가 심한 배열과 연결리스트보다는 힙으로 구현하는 것입니다.
📌 힙
데이터에서 최댓값과 최솟값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree)
부모 노드의 인덱스는 1로, 왼쪽 자식 노드부터 2, 3 순서이다.
- (부모 노드의 인덱스) = (자식 노드 인덱스) // 2
- (왼쪽 자식 노드의 인덱스) = (부모 노드의 인덱스) * 2
- (오른쪽 자식 노드의 인덱스) = (부모 노드의 인덱스) * 2 + 1
배열로 구현할 때 인덱스 번호 1부터 시작하면 편함..
0부터 할거라면 계산할 때 -1하는 거 잊지 말기..
💡 힙은 왜 사용하나요?
최솟값이나 최댓값을 찾기 위해 배열을 사용하면 Ο(n)만큼 시간이 걸린다.
하지만 힙을 사용하면 O(logn)만큼 소요되므로, 배열을 사용할 때보다 빠르게 최솟값과 최댓값을 구할 수 있다.
우선순위 큐와 같이 최댓값 또는 최솟값을 빠르게 찾아야하는 알고리즘 등에 활용된다.
정리하자면, 힙은 다음 조건을 만족하는 자료구조이다.
- 힙은 최대힙(Max heap)과 최소힙(Min heap)으로 나뉘어진다. 최대힙은 자식 노드보다 부모 노드의 값이 크고, 최소힙은 자식 노드보다 부모 노드의 값이 작다.
- 노드가 왼쪽부터 채워지는 완전 이진 트리 형태를 가진다.
- 중복을 허용한다.
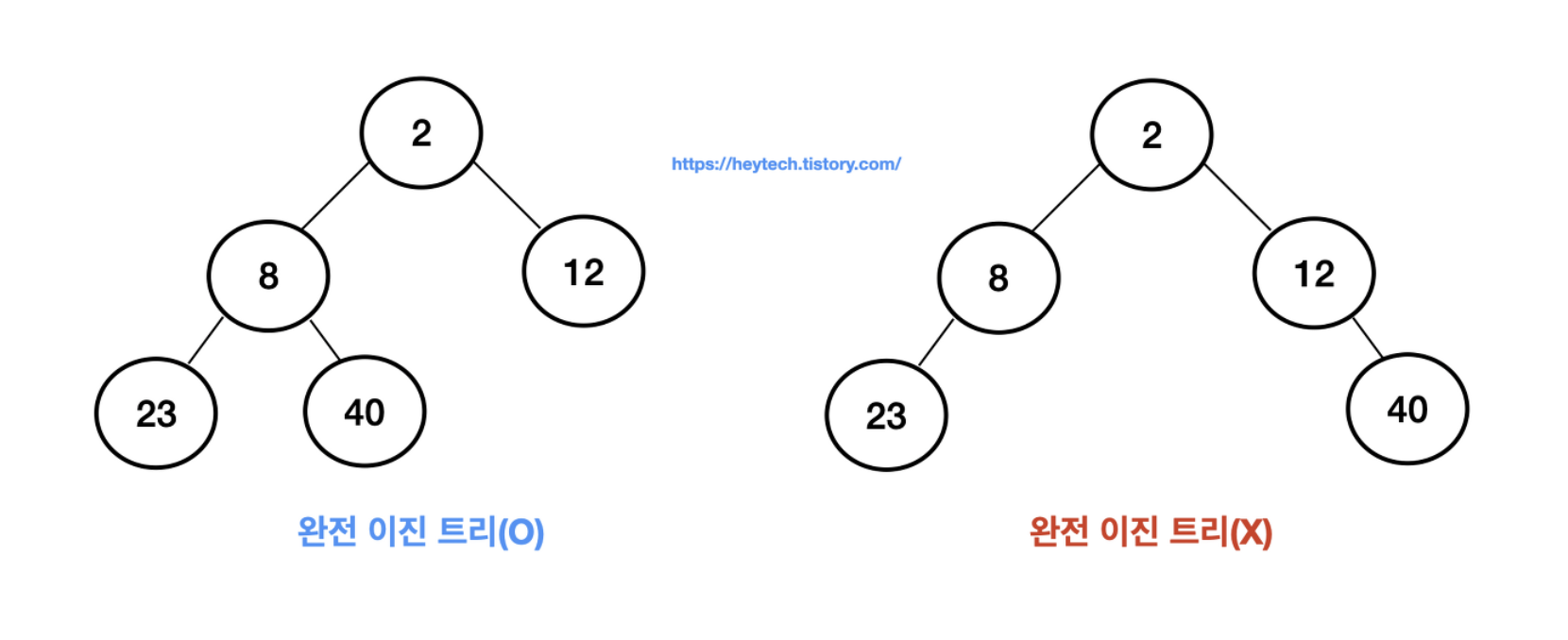
💡 완전 이진 트리(Complete Binary Tree)란?
이진 트리에 노드를 삽입할 때 왼쪽부터 차례대로 삽입하는 트리이다.
위 그림과 같이 나타내며, 왼쪽이 비어있고 오른쪽이 채워져 있는 형태는 완전 이진 트리라고 할 수 없다.
(출처: https://heytech.tistory.com/105)
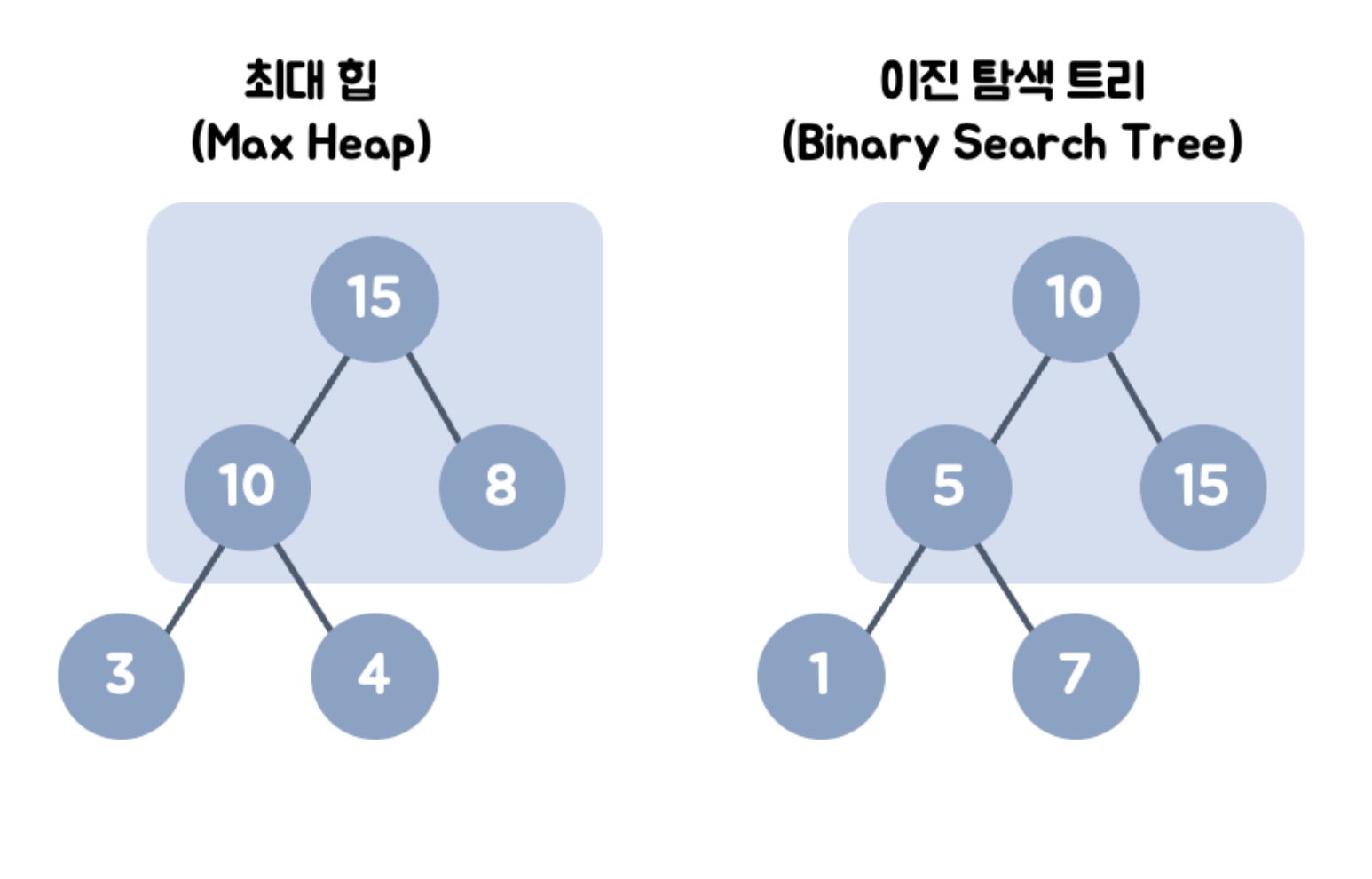
힙 vs 이진 탐색 트리
💡 이진 탐색 트리(Binary Search Tree)란?
이진 탐색과 연결리스트(linked-list)를 결합한 자료구조의 일종이다.
이진 탐색의 효율적인 탐색 능력을 유지하면서 빈번한 자료의 입력과 삭제를 가능하도록 한다.
각 노드에서 왼쪽의 자식 노드는 해당 노드보다 작은 값으로, 오른쪽의 자식 노드는 해당 노드보다 큰 값으로 이루어져 있다.
공통점
모두 완전 이진 트리이다.
차이점
(최대힙의 경우) 힙은 각 노드의 값이 자식 노드보다 크거나 같다.
이진 탐색 트리는 각 노드의 왼쪽 자식은 더 작은 값으로, 오른쪽 자식은 더 큰 값으로 이루어져있다.
왼쪽 자식 노드 < 부모 노드 < 오른쪽 자식 노드
힙은 왼쪽 노드의 값이 크든 오른쪽 노드의 값이 크든 상관 없다.
힙은 최대/최소 검색을, 이진 탐색 트리는 탐색을 위한 구조이다.
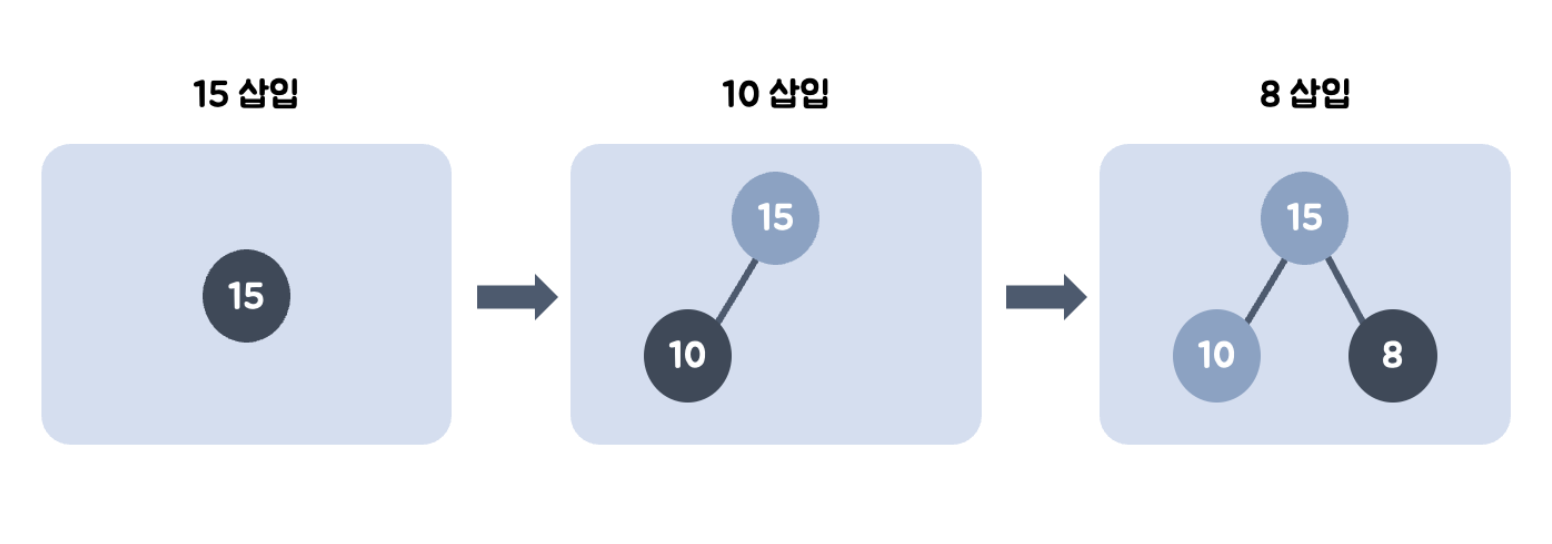
힙의 동작
최대 힙(Max heap)으로 예를 들어 힙의 삽입, 삭제 동작을 알아보자.
데이터 삽입
힙은 완전 이진 트리이기 때문에, 삽입할 노드는 기본적으로 왼쪽 최하단부 노드부터 채워진다.
- 15를 왼쪽 최하단 노드에 삽입한다.
- 10을 왼쪽 최하단 노드에 삽입한 뒤, 부모와 비교한다. 부모보다 작으므로 그 자리에 위치한다.
- 왼쪽 최하단 노드가 이미 있으므로 8을 오른쪽 최하단 노드에 삽입한 뒤, 부모와 비교한다. 부모보다 작으므로 그 자리에 위치한다.
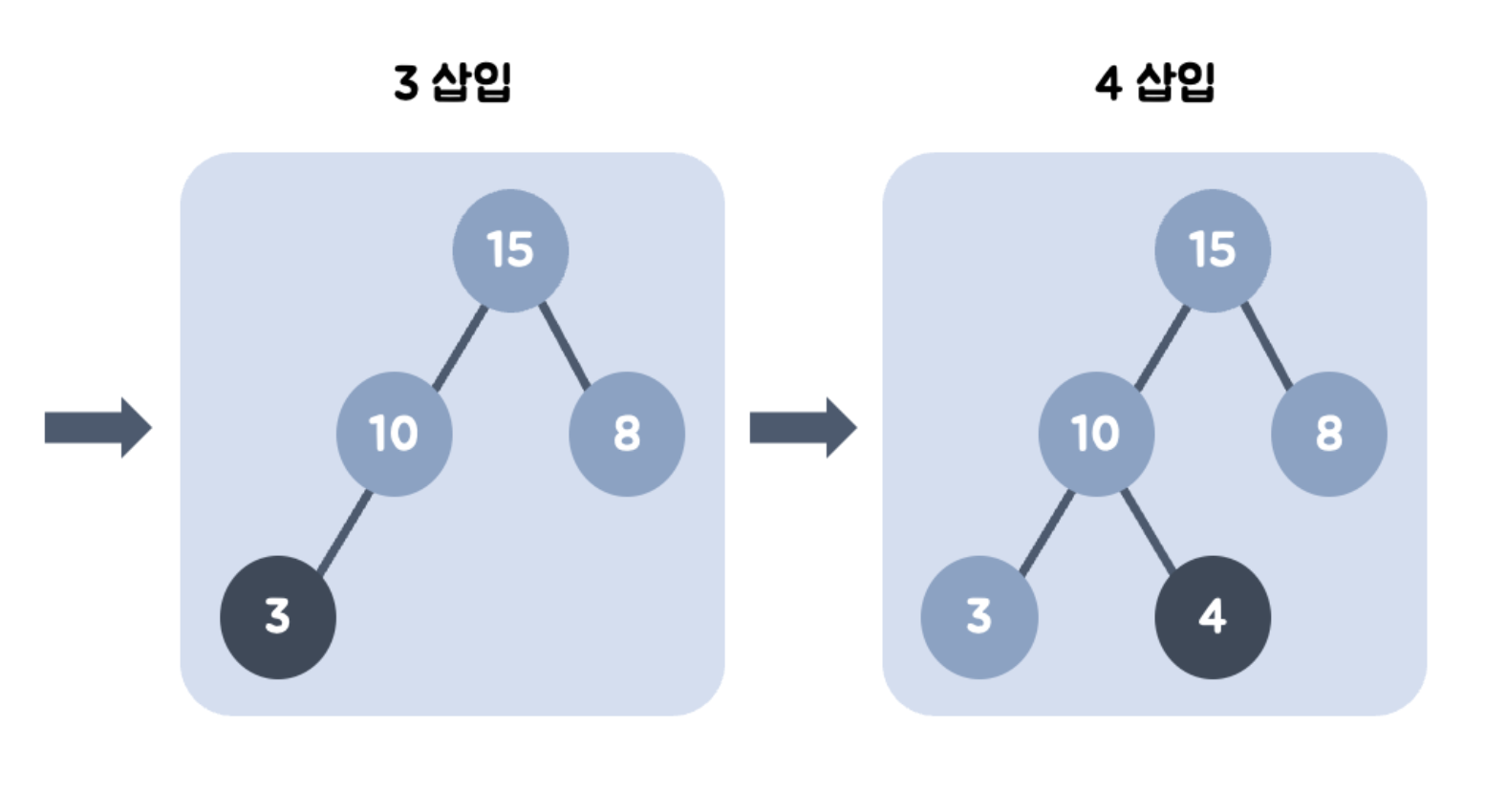
- 3을 왼쪽 최하단 노드에 삽입한 뒤, 부모와 비교한다. 부모보다 작으므로 그 자리에 위치한다.
- 왼쪽 최하단 노드가 이미 있으므로 4를 오른쪽 최하단 노드에 삽입한 뒤, 부모와 비교한다. 부모보다 작으므로 그 자리에 위치한다.
데이터 삽입 (힙의 데이터보다 클 경우)
기본적으로 앞에서 설명한대로, 완전 이진 트리의 구조에 맞춰 최하단부 노드부터 채워진다.
채워진 노드의 위치에서, 부모 노드의 값보다 클 경우에는 부모 노드와 위치를 바꾸며 이를 반복한다.
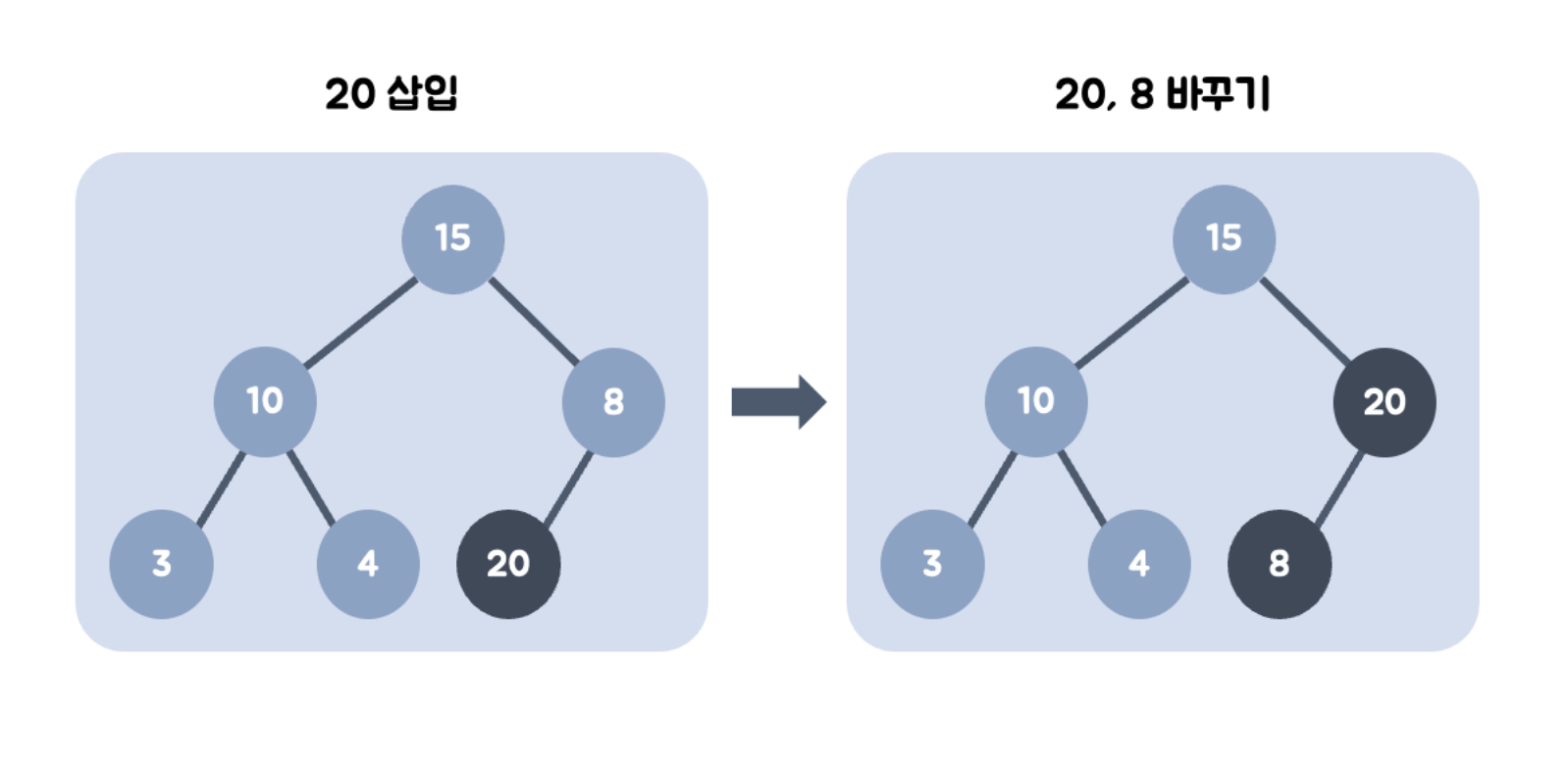
- 20을 왼쪽 최하단부 노드에 삽입한다.
- 20의 부모 노드인 8과 비교한다. 20이 더 크므로 8과 위치를 바꾼다. (swap)
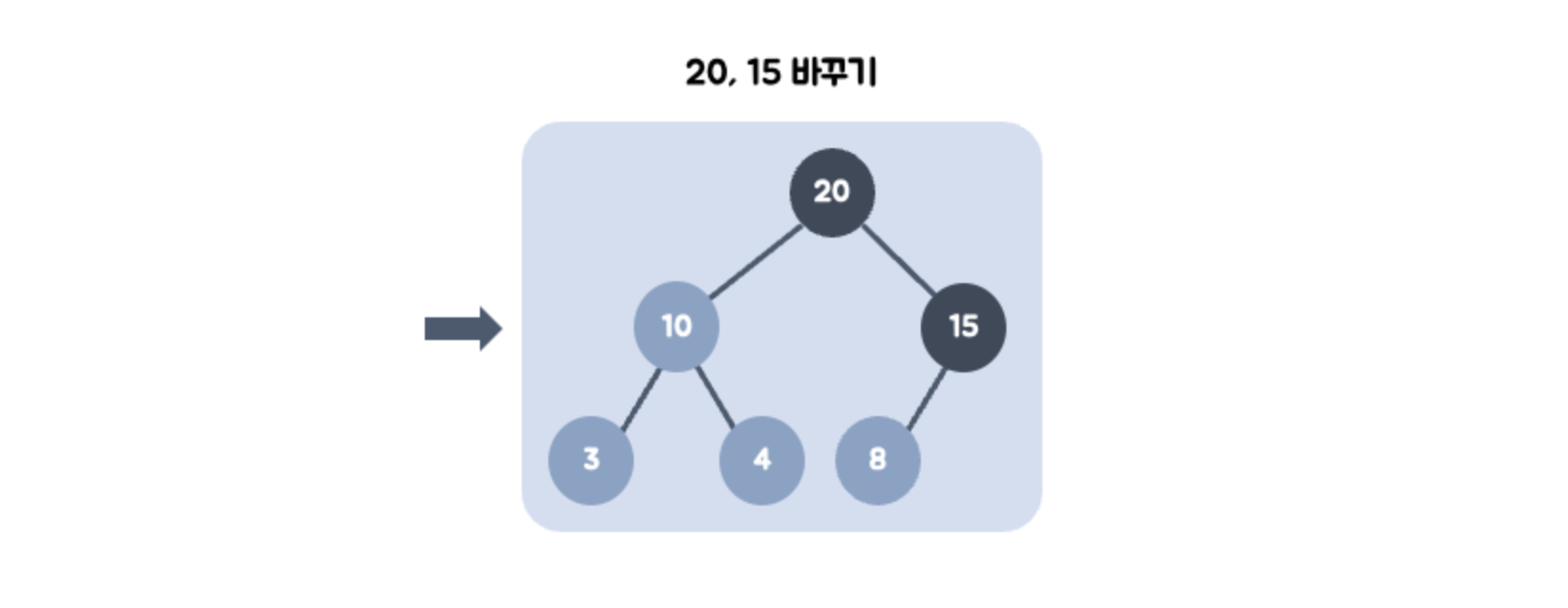
- 20의 부모 노드인 15와 비교한다. 20이 더 크므로 15와 위치를 바꾼다. (swap)
데이터 삭제
힙 자료구조의 목표는 바로 최대값이나 최소값을 알아내는 것이다.
때문에 데이터가 삭제 된다면 가장 큰 값인 부모 노드의 값이 삭제된다.
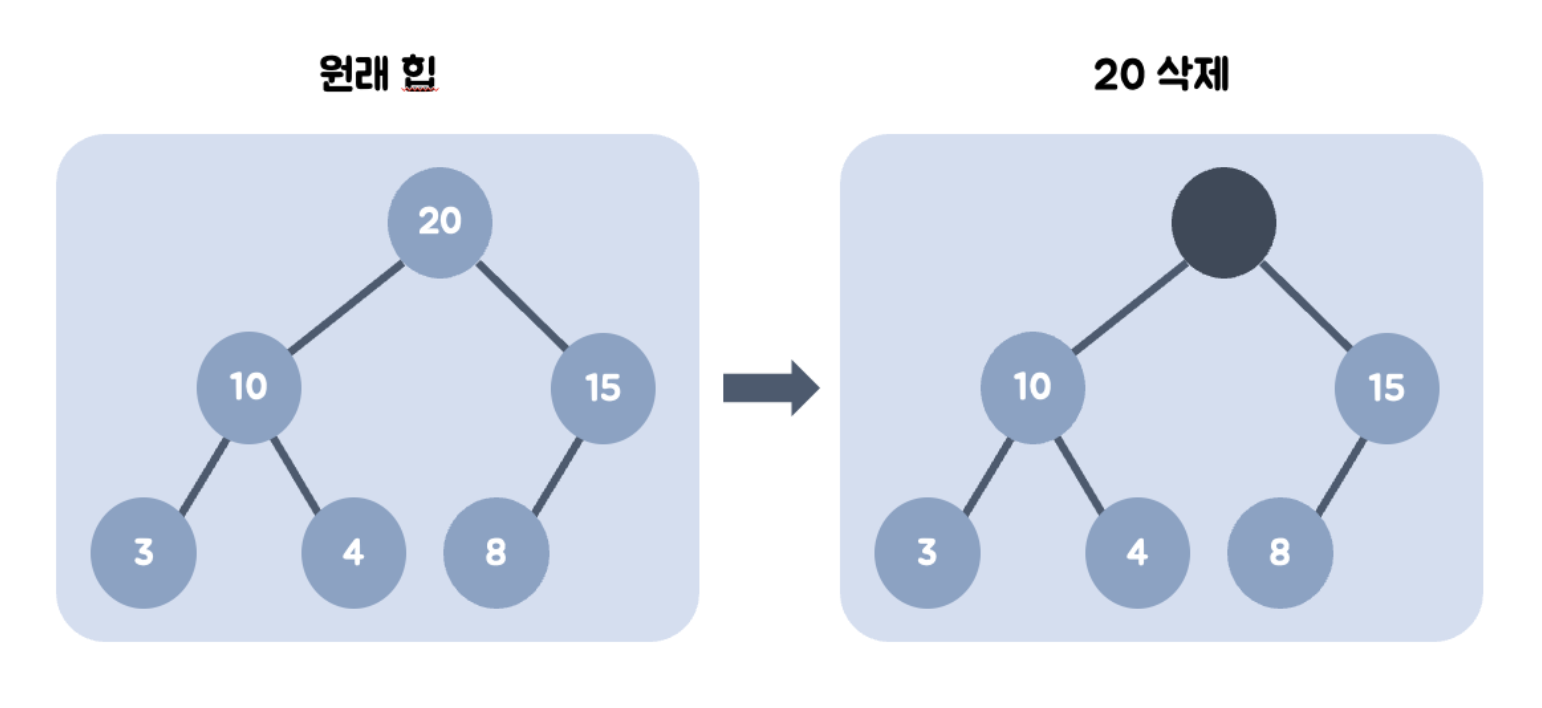
- 최대값을 갖는 부모 노드를 삭제한다.
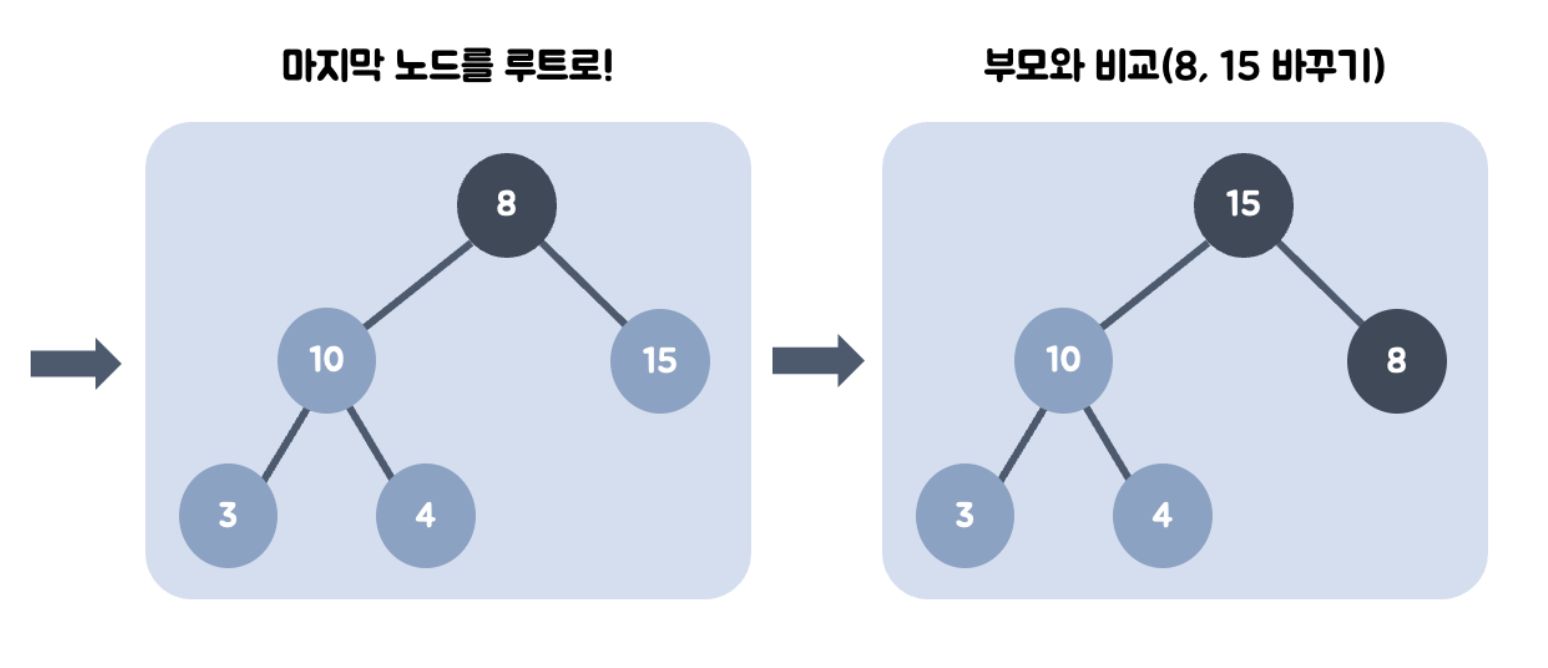
- 부모 노드가 비었으므로, 가장 최하단부 노드를 루트로 옮긴다.
- 부모 노드인 8보다 값이 큰 자식 노드가 있는지 비교한다.
1) 왼쪽, 오른쪽 자식 노드 모두 부모 노드보다 클 경우
- 왼쪽 자식 노드와 오른쪽 자식 노드를 비교하여, 더 큰 자식 노드와 부모 노드의 위치를 바꾼다. (swap)
2) 왼쪽, 오른쪽 자식 노드 중 하나만 부모 노드보다 클 경우
- 둘 중에 부모 노드보다 큰 자식 노드와 부모 노드의 위치를 바꾼다. (swap)
