📌 개요
이진 트리는 하나의 부모가 두 개의 자식밖에 가지질 못하고, 균형이 맞지 않으면 검색 효율이 선형검색 급으로 떨어진다.
B트리는 이진트리에서 발전되어 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동으로 벨런스를 맞추는 트리입니다. 또한 정렬된 순서를 보장하고, 멀티레벨 인덱싱을 통한 빠른 검색을 할 수 있기 때문에 DB에서 사용하는 자료구조 중 한 종류라고 합니다.
실제 DB에서는 B트리에서 발전한 B+트리를 실제로 사용한다고 합니다. 2번에 걸쳐 B트리와 B+트리에 대해 포스팅 해보겠습니다.
📌 B Tree
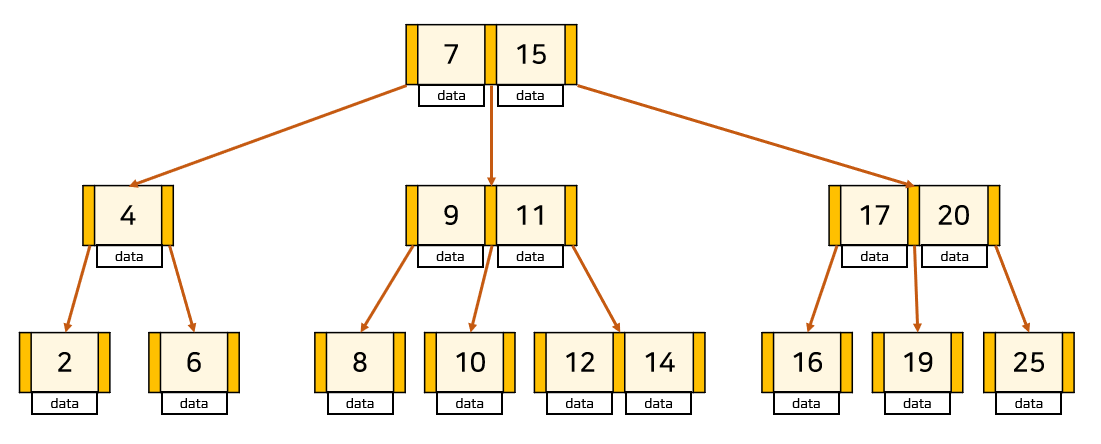
자식 수에 대한 일반화를 진행하면서, 하나의 레벨에 더 저장되는 것 뿐만 아니라 트리의 균형을 자동으로 맞춰주는 로직까지 갖추었다. 단순하고 효율적이며, 레벨로만 따지면 완전히 균형을 맞춘 트리다.
대량의 데이터를 처리해야 할 때, 검색 구조의 경우 하나의 노드에 많은 데이터를 가질 수 있다는 점은 상당히 큰 장점이다.
대량의 데이터는 메모리보다 블럭 단위로 입출력하는 하드디스크 or SSD에 저장해야하기 때문!
ex) 한 블럭이 1024 바이트면, 2바이트를 읽으나 1024바이트를 읽으나 똑같은 입출력 비용 발생. 따라서 하나의 노드를 모두 1024바이트로 꽉 채워서 조절할 수 있으면 입출력에 있어서 효율적인 구성을 갖출 수 있다.
→ B-Tree는 이러한 장점을 토대로 많은 데이터베이스 시스템의 인덱스 저장 방법으로 애용하고 있음
규칙
- 노드의 자료수가 N이면, 자식 수는 N+1이어야 함
- 각 노드의 자료는 정렬된 상태여야함
- 루트 노드는 적어도 2개 이상의 자식을 가져야함
- 루트 노드를 제외한 모든 노드는 적어도 M/2개의 자료를 가지고 있어야함
- 외부 노드로 가는 경로의 길이는 모두 같음.
- 입력 자료는 중복 될 수 없음
📌 B+ Tree
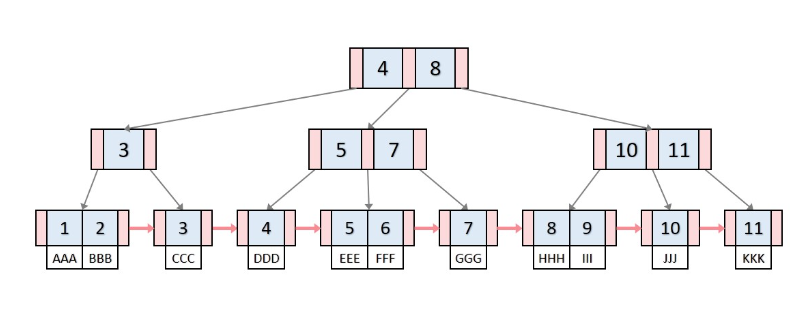
데이터의 빠른 접근을 위한 인덱스 역할만 하는 비단말 노드(not Leaf)가 추가로 있음
(기존의 B-Tree와 데이터의 연결리스트로 구현된 색인구조)
B-Tree의 변형 구조로, index 부분과 leaf 노드로 구성된 순차 데이터 부분으로 이루어진다. 인덱스 부분의 key 값은 leaf에 있는 key 값을 직접 찾아가는데 사용함.
장점
블럭 사이즈를 더 많이 이용할 수 있음 (key 값에 대한 하드디스크 액세스 주소가 없기 때문)
leaf 노드끼리 연결 리스트로 연결되어 있어서 범위 탐색에 매우 유리함
단점
B-tree의 경우 최상 케이스에서는 루트에서 끝날 수 있지만, B+tree는 무조건 leaf 노드까지 내려가봐야 함
📌 B-Tree & B+ Tree
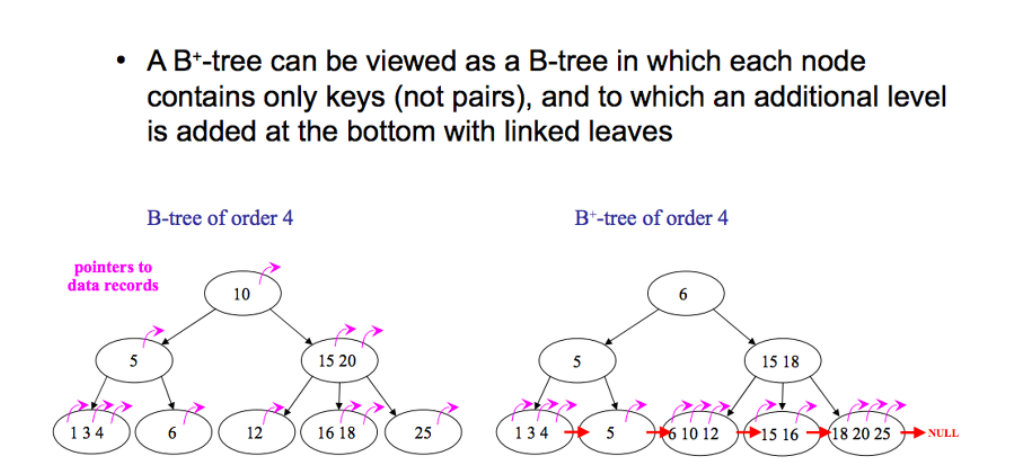
B-tree는 각 노드에 데이터가 저장됨
B+tree는 index 노드와 leaf 노드로 분리되어 저장됨
(또한, leaf 노드는 서로 연결되어 있어서 임의접근이나 순차접근 모두 성능이 우수함)
B-tree는 각 노드에서 key와 data 모두 들어갈 수 있고, data는 disk block으로 포인터가 될 수 있음
B+tree는 각 노드에서 key만 들어감. 따라서 data는 모두 leaf 노드에만 존재
B+tree는 add와 delete가 모두 leaf 노드에서만 이루어짐
