코딩테스트에서 주로 사용되는 자료구조들에 대해 배웠는데 그냥 어려웠다.. 너무 어려웠다..
저번 유닛까진 분명 할만했는데?.. 난이도가 3에서 10이 됐다..
기업 들어갈때 코딩테스트는 필수 인지라 포기 할수도 없는 판.. 이 악물고 버티긴 했는데 나한테 흡수 된건지 아닌지도 모르겠다..
문제가 이해가 되면 코드로 구현이 어느정도 되는데, 너무 이해가 안된다. 문제가 의도하는 바가 무엇인지 잘 모르겠다.. 해결 방법으론 어떤 것이 있을까?.. 비슷한 유형의 문제들을 많이 풀어보면 될려나..
어려워 하는 내 자신에 자괴감이 들어서 요 며칠간 수업 끝나고 잠들때까지 백준문제들을 엄청 많이 풀었다.
강사님도 실제로 난이도 있는 문제이며 따지자면 웬만한 기업 코딩테스트 수준이라며 지금 당장은 못풀어도 된다고 줌세션시간에 얘기 해주셨다. 그나마 위로가 됐다..
이번 주말부터 설연휴다, 휴일? 그딴건 나한테 없다 마음가짐 단단히 먹고 하루종일 책상 앞에 앉아있을 것이야.
자료구조
자료구조 - 자료의 사용 방법이나 성격에 따라 효율적으로 사용하기 위하여 조직하고 저장하는 방법
Stack
Stack - 데이터를 순서대로 쌓는 자료구조
특징
- LIFO - 가장 먼저 들어간 데이터가 가장 나중에 나온다
- 한번에 여러개의 데이터를 빼거나 넣을수 없고 하나씩만 처리 가능
- 입출력 방법이 하나
Stack<Integer> stack = new Stack<>(); // 스택 선언
stack.push(1); // 값 1 추가
stack.pop(); // 값 제거
stack.clear(); // 전체 값 제거
stack.peek(); // 가장 상단의 값 출력
stack.size(); // 크기 출력
stack.empty(); // 비어있는지 체크 (비어있다면 true)
stack.contains(1) // 1이 있는지 체크 (있다면 true)Queue
Queue - 데이터가 입력된 순서대로 처리할 때 주로 사용
특징
- FIFO - 가장 먼저 들어간 데이터가 제일 처음에 나온다
- 한번에 여러개의 데이터를 빼거나 넣을수 없고 하나씩만 처리 가능
- 두 개의 입출력 방향을 가지고 있다 ( 입력 출력 방향이 다름 )
Queue<Integer> queue = new LinkedList<>(); // 큐선언
queue.add(1); // 값 1 추가
queue.offer(2); // 값 2 추가
queue.poll(); // 첫번째 값을 반환하고 제거 비어있다면 null
queue.remove(); // 첫번째 값 제거
queue.clear(); // 전체 값 제거
queue.peek(); // 첫번째 값 출력Tree
Tree - 단방향 그래프의 한 구조
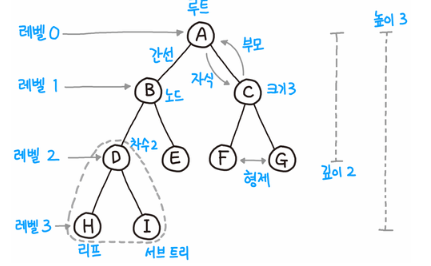
노드(node): 트리를 구성하는 기본 원소
루트 노드(root node/root): 트리에서 부모가 없는 최상위 노드, 트리의 시작점
부모 노드(parent node): 루트 노드 방향으로 직접 연결된 노드
자식 노드(child node): 루트 노드 반대방향으로 직접 연결된 노드
형제 노드(siblings node): 같은 부모 노드를 갖는 노드들
리프 노드(Leaf) : 트리 구조의 끝 지점이고, 자식 노드가 없는 노드
경로(path): 한 노드에서 다른 한 노드에 이르는 길 사이에 있는 노드들의 순서
길이(length): 출발 노드에서 도착 노드까지 거치는 간선의 개수
깊이(depth): 루트 경로의 길이
레벨(level): 루트 노드(level=0)부터 노드까지 연결된 간선 수의 합
높이(height): 가장 긴 루트 경로의 길이
차수(degree): 각 노드의 자식의 개수
크기(size): 노드의 개수
너비(width): 가장 많은 노드를 갖고 있는 레벨의 크기
Graph
Graph - 여러개의 점들이 서로 연결되어 있는 관계를 표현한 자료구조
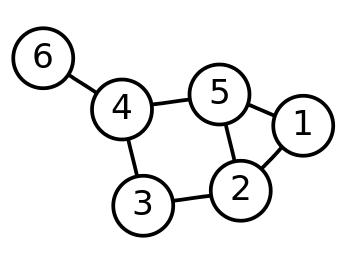
정점(vertex) - 하나의 점
간선(edge) - 하나의 선
인접 행렬
두 정점을 이어주는 간선이 있다면 이 두 정점은 인접하다고 표현한다.
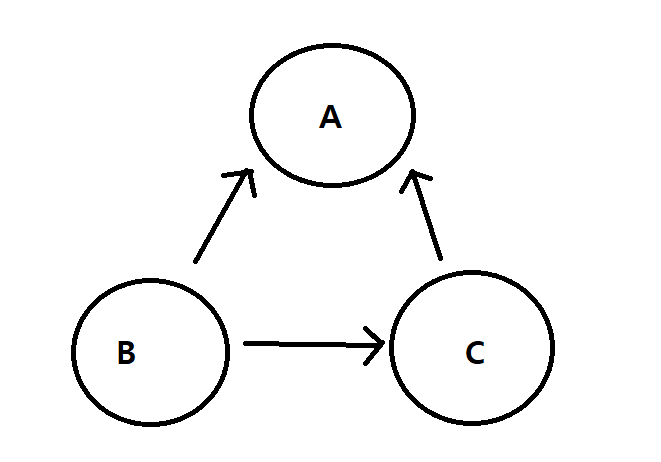
A의 진출차수 - 0개
B의 진출차수 - 2개 : B —> A, B —> C
C의 진출차수 - 1개 : C —> A
주로 두 정점 사이에 관계가 있는지, 없는지 확인하기에 사용하고 가장 빠른 경로를 찾을때 주로 사용
인접 리스트
각 정점이 어떤 정점과 인접하는지를 리스트의 형태로 표현
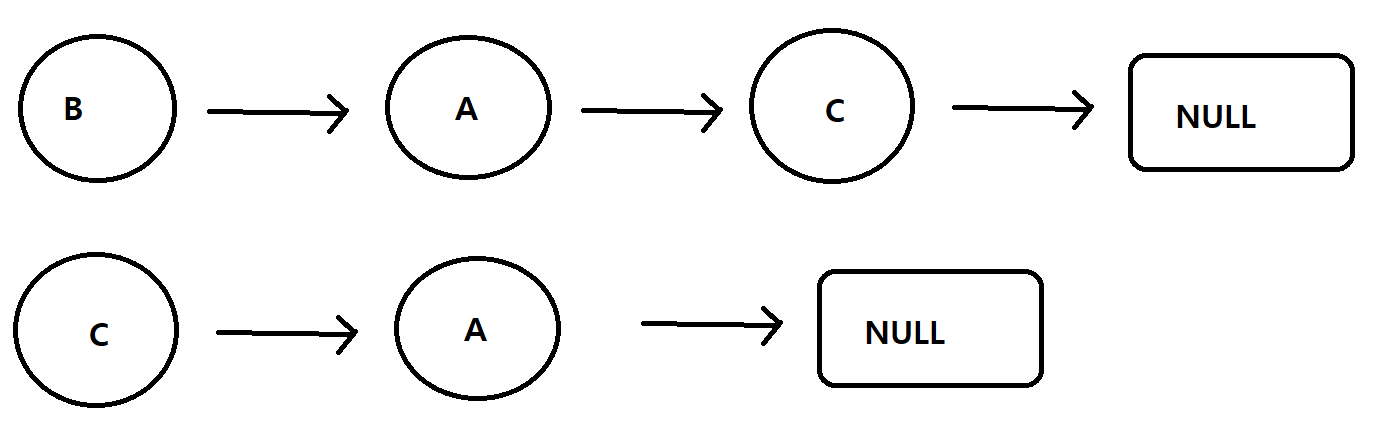
메모리를 효율적으로 사용하고 싶을 때 주로 사용
Binary Search Tree
이진 탐색 트리- 모든 왼쪽 자식의 값이 루트나 부모보다 작고, 모든 오른쪽 자식의 값이 루트나 부모보다 큰 값을 가지는 특징을 가지고 있다.
효율적인 탐색을 위해 사용
Tree traversal
전위 순회
- 부모 노드를 먼저 방문하는 순회 방식
- 우선순위: 부모 노드 > 왼쪽 노드 > 오른쪽 노드
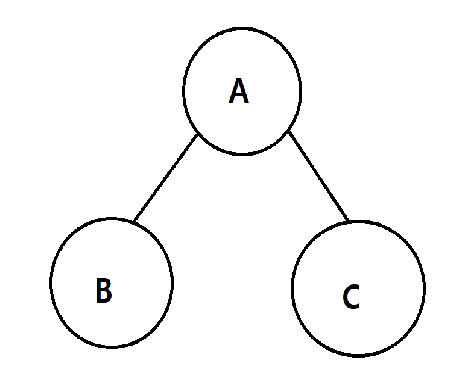
위 그림 1-2-3 순서로 방문
중위 순회
- 왼쪽 노드를 먼저 방문 후 부모 노드를 방문하는 순회 방식
- 우선순위: 왼쪽 노드 > 부모 노드 > 오른쪽 노드
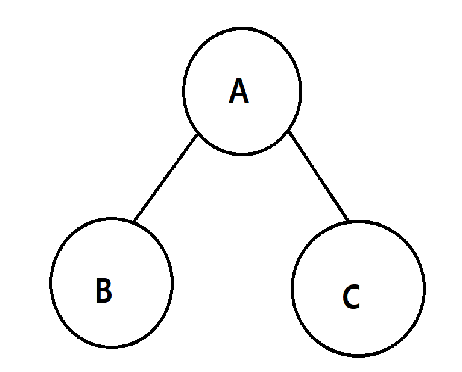
위 그림 2-1-3 순서로 방문
후위 순회
- 하위 노드를 먼저 방문 후 부모 노드를 방문하는 순회 방식
- 우선순위: 왼쪽 노드 > 오른쪽 노드 > 부모 노드
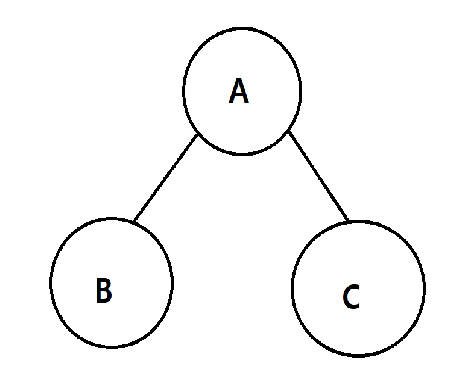
위 그림 2-3-1 순서로 방문
BFS / DFS
BFS - 너비를 우선적으로 탐색하는 방법, 최단 경로를 탐색할때 사용한다, 최악의 경우로는 모든 경로를 다 탐색해야 한다.
DFS - 깊이를 우선적으로 탐색하는 방법, 한 정점에서 시작해서 다음 경로로 넘어가기 전에 해당 경로를 완벽하게 탐색할 때 사용
Deque
Deque - 양방향으로 열려있는 구조
특징
- 스택과 큐를 모두 사용가능
- 양방향 끝에서 데이터 추가,삭제 용이
- 양방향 끝이 아닌 임의의 데이터만 추가하거나 삭제하는 건 불가능
Linked List
연결 리스트는 각 데이터들을 포인터로 연결하여 관리하는 구조
특징
- 노드의 추가와 삭제가 빠르다
- 노드의 값을 찾으려면 최대 전체를 순회해야 한다
Hash Table
해시 테이블이란 해시함수를 사용하여 변환한 해시를 색인으로 삼아 키와 데이터를 저장하는 자료구조
특징
- hash table에서 저장, 삭제, 검색 과정은 모두 평균적으로 O(1)의 시간복잡도를 가지고 있어 데이터를 다루는 작업이 매우 빠르다는 장점
- 해시 충돌이 발생할 수 있고 데이터가 저장되기 전에 저장공간을 미리 만들어놔야 하기 때문에 공간 효율성이 떨어진다. 또한 해시함수의 의존도가 높다.
Heap tree
heap tree는 트리 구조로 구현된 자료구조, 우선순위에 따라서 빠르게 자료를 검색할 수 있는 구조다
특징
- 완전 이진 트리
- 중복된 값 저장 가능
- 최대 힙과 최소 힙으로 구현
