
☕헤이동동 : 생협 음료 원격 주문 서비스
이번 포스팅에서는 직접 작성한 ERD를 바탕으로 헤이동동 테이블 구조를 설명하고, 이를 어떻게 Class로 매핑하였는지 설명한다.
Entity-Relation Diagram
아래는 헤이동동의 데이터베이스 구조를 표현한 전체 ERD다.
ERDCloud라는 무료 웹 편집기를 찾아 사용했는데, 여러 무료 편집기 중에서 UI와 결과물 디자인이 가장 마음에 들어 사용했다.

위 ERD는 서비스 구현을 마무리 한 상태에서의 ERD로, 앞 포스팅에서 작성한 주문 시나리오를 가장 기본으로 하여 테이블을 설계했다. 또한 가장 자주 발생할 주문 프로세스의 시나리오에 초점을 맞추어 효율을 높였다.
orders

주문에 필요한 기본적인 정보를 orders 테이블에 담았다.
주문에 들어 있는 음료는 여러 잔일 수 있기 때문에, orders의 id를 참조하는 별도의 테이블을 생성해서 조인으로 조회하도록 하였다.
menus
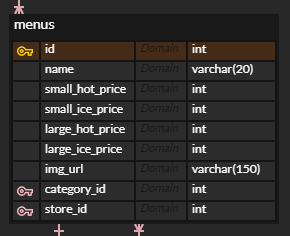
매장에서 제공하는 메뉴 정보를 menus 테이블에 담았다.
서비스를 발전시키면서 계속 테이블 안의 필드가 변경되었는데, 초기의 작성한 테이블과의 가장 큰 차이점은 각 매장별 메뉴를 별도의 테이블로 설계했던 것을 하나의 테이블로 합치게 된 것이다.
각 매장별로 판매하는 메뉴가 다르기 때문에 menus 테이블 하나로는 각각의 매장의 메뉴를 로드하거나, 각각의 주문을 처리할 수 없었다. 그래서 원래는 eng_menus, stu_menus 등으로 각 건물별로 테이블이 각각 지정되어 있고, menus의 id를 참조하도록 했었다.
그런데, 산학멘토님께서 그렇게 하는 것은 조인 비용이 크게 발생하여 비효율적이므로, menus 테이블 안에 모든 매장별 메뉴를 때려 넣고 순차적으로 id를 부여하라고 조언을 주셨다. 한 테이블 안에 너무 많은 레코드가 중복으로 들어가는 것에 거부감이 있었지만, 생각해보니 모든 작업마다 조인을 수행하는 것은 확실히 비효율적이라 멘토님의 조언대로 테이블을 수정했다.
menus_in_orders

주문한 메뉴들을 menus_in_orders 테이블에 담았다. order_id를 FK로 가져 주문별로 조회할 수 있으며, menu_id를 FK로 가져 메뉴의 정보를 가질 수 있다.
커스텀 옵션은 menus_in_orders 테이블 안의 custom_options 필드에 json string으로 담았다. 초기에는 커스텀 옵션의 모든 항목을 각각의 필드로 만들고 boolean으로 표시하도록 테이블을 작성했다.
하지만 json string으로 필요한 정보만 담는 것이 저장 공간을 줄이는 데에 아주 효율적이며, 파싱만 잘 구현하면 되기 때문에 json string으로 필드 타입을 지정하게 되었다. (물론 MySQL은 json인지 아닌지 모르고 그냥 varchar 타입으로 저장한다.)
나머지 is_hot, is_small, is_tumblr은 주문된 모든 음료에 대해 필수로 지정되어야 하는 옵션이기 때문에 별도의 필드로 두었다.
users

user_roles 테이블은 Spring security를 활용한 USER ROLE 인증 시 자동으로 생성되는 테이블이다.
users는 고객의 개인정보, No show 처리를 위한 정보, 그리고 회원관리를 위한 정보를 담는다.
email_check_token과 is_email_verified는 회원가입 시 이메일 중복인증을 할 때 사용되며, is_email_verified bit가 1인 회원만 서비스를 사용할 수 있다. device_token은 푸시 알림을 위해 로그인한 디바이스의 토큰을 저장하고, refresh_token_value는 JWT를 이용한 로그인 세션 유지 기능을 위해 사용된다. 관련 구현 포스팅은 여기서 확인할 수 있다.
Class Diagram
아래는 헤이동동 서버의 Class 구조를 설명한 Class Diagram이다.
Class Diagram은 Draw.io라는 웹 편집기를 사용했다. ERD와 마찬가지로 직관적이고 깔끔한 결과물 디자인이 마음에 들어서 사용했다.
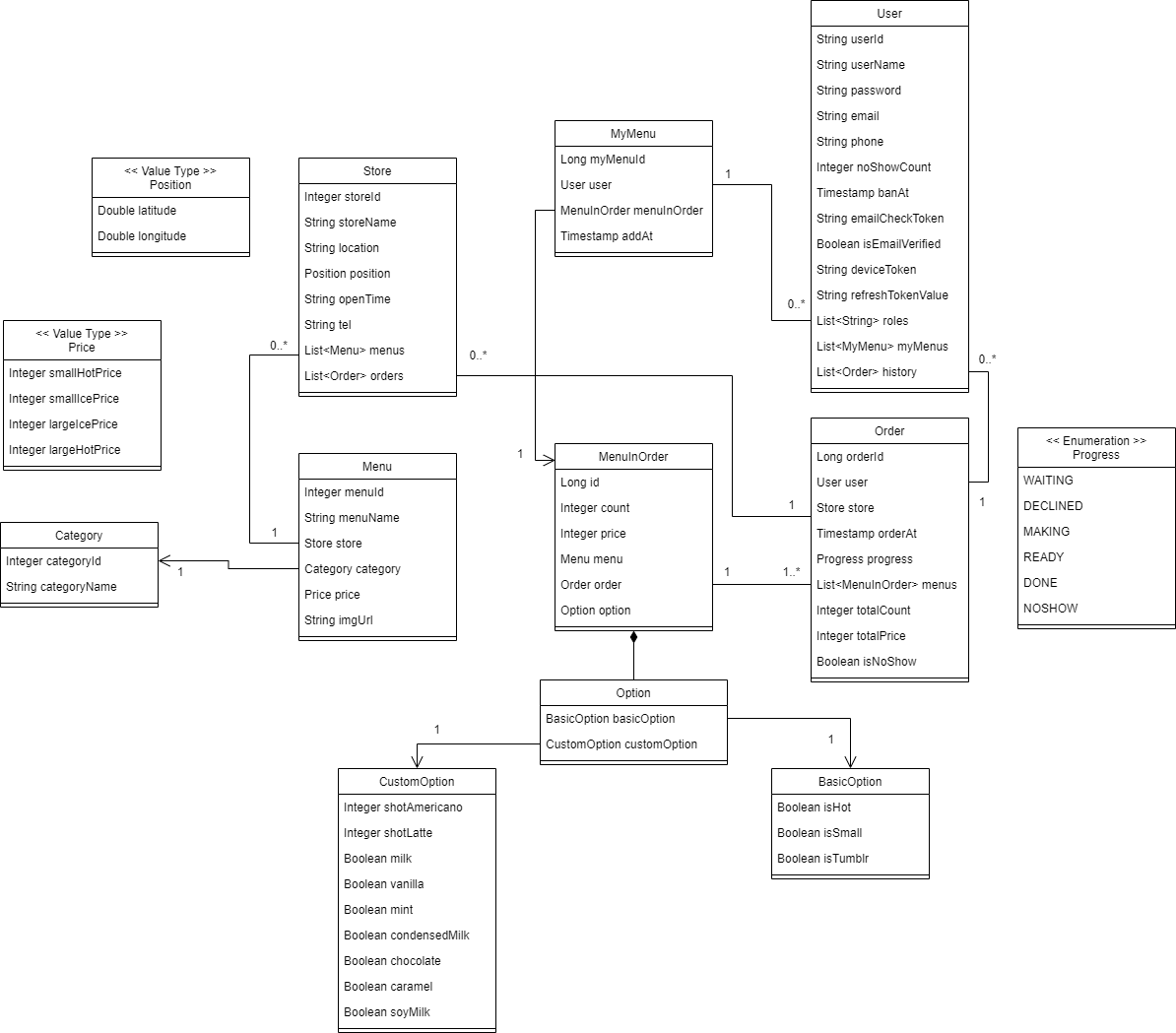
DB를 먼저 설계한 후, 클래스로 매핑할 때 특히 신경썼던 점은 다음과 같다.
- 엔티티 간 1:1, 1:N, N:1, N:N 매핑
- 매핑 시 참조 방향과 관계의 주인 설정
- 클래스 크기를 최소화를 위해 Value Type Class 생성
미리 설정을 해 놓은 뒤 JPA 매핑을 진행했더니 훨씬 수월하게 오류 없이 진행할 수 있었다. 매핑을 진행하는 과정은 다음 포스트에서 확인할 수 있다.
느낀점
초기 DB와 클래스 설계는 사실상 혼자 맡아서 했는데, 이렇게 설계를 하면서 서비스 흐름을 쭉 검토하고 어떻게 하는 것이 가장 효율적인지 고민하는 것이 재밌었다. 그러면서 또 동시에, 기획 단계에서 서비스 흐름과 로직을 꼼꼼하게 문서화하고 적어 놓지 않았던 점이 힘들기도 했다.
오로지 내 머릿속으로 사용자의 입장에서의 흐름과 유즈케이스를 상상해서 빼먹은 요소가 없는지 생각했어야 했기 때문에 아쉬운 점도 많았다. 물론 이러한 점은 구현하면서 계속 추가하고 수정하면 되는 것이지만, 처음 할 때 정리를 잘 해놓으면 작업의 효율성이 훨씬 높아질 것 같다는 생각이 계속 들었다.
헤이동동의 테이블을 설계하기 전까지는 완벽한 정규화와 테이블 최소화, 그리고 분리가 항상 올바른 정답인 줄 알았다. 하지만 실무에서는 정규화가 무조건 정답이 아니라 효율성을 위해 규칙을 살짝 깰 수도 있고 다양한 방법으로 구현을 할 수 있다는 것을 배울 수 있었다.
데이터베이스 과목을 수강했을 때는 올바른 데이터베이스를 설계하는 방법을 배웠다면, 이렇게 실무에 가까운 경험을 통해서는 효율적인 데이터베이스를 설계하는 방법에 대해 배울 수 있게 되는 것 같다. 개인 토이 프로젝트에서는 실무자로부터 피드백을 받기가 어려운데, 멘토링을 강제로라도 하게 되면서 도움을 받을 수 있어서 좋았다.
