이전 포스팅에서는 프로그램 실행 단위의 정의에 대해 간단하게 알아보았다. 이 포스팅은 아래 질문의 답을 명확하게 정리하는 글이다.
🙋 멀티프로세스와 멀티쓰레드는 뭐가 다른가요?
📝 다중 처리방식
우리는 컴퓨터를 쓸 때 한 번에 여러가지 작업을 동시에 수행한다. 이 포스팅을 쓰면서도 한 쪽에는 음악를 틀어 놓고 다른 한 쪽엔 참고 자료를 같이 띄워 놓고 있는 것처럼 말이다. 이렇게 여러 개의 프로그램을 동시에 띄워 놓고 사용할 수 있는 것은 컴퓨터가 프로세스와 쓰레드를 다중 처리방식으로 제어하기 때문이다.
📌 동시성
여기서 한 가지 짚고 넘어가야 할 점이 있다. 바로 동시성에 관한 것이다.
한 컴퓨터에 여러 프로그램을 띄워 놓으면 우리 눈에는 모든 프로그램이 다 동시에 수행되는 것처럼 보인다. 노래도 끊임없이 나오고, 키보드를 치면 바로 글자가 입력되는 것이 보이기 때문이다.
하지만 그렇다고 해서 프로그램이 정말 말 그대로 동시에 수행되는 것은 아니다. CPU는 한 시점에 오직 하나의 명령문만 수행할 수 있다. 그래서 우리는 CPU가 아주아주 짧은 간격으로 번갈아가며 여러가지 일을 수행하도록 만들었다. 매우 자주, 매우 빠르게 Context Switching이 일어나도록 해서 사람 눈에는 여러가지 일을 동시에 처리하는 것처럼 보이도록 만든 것이다.
그래서 사실 컴퓨터가 어떤 것을 동시에 수행한다는 것은 정말로 여러 일을 한 시점에 처리한다는 것이 아니고, 그 일들이 동시에 수행되는 것처럼 보이도록 CPU Scheduling을 수행한다는 것을 의미한다.
📌 Multi-Process
메모리에 여러 프로세스가 동시에 로드되어 수행되는 것
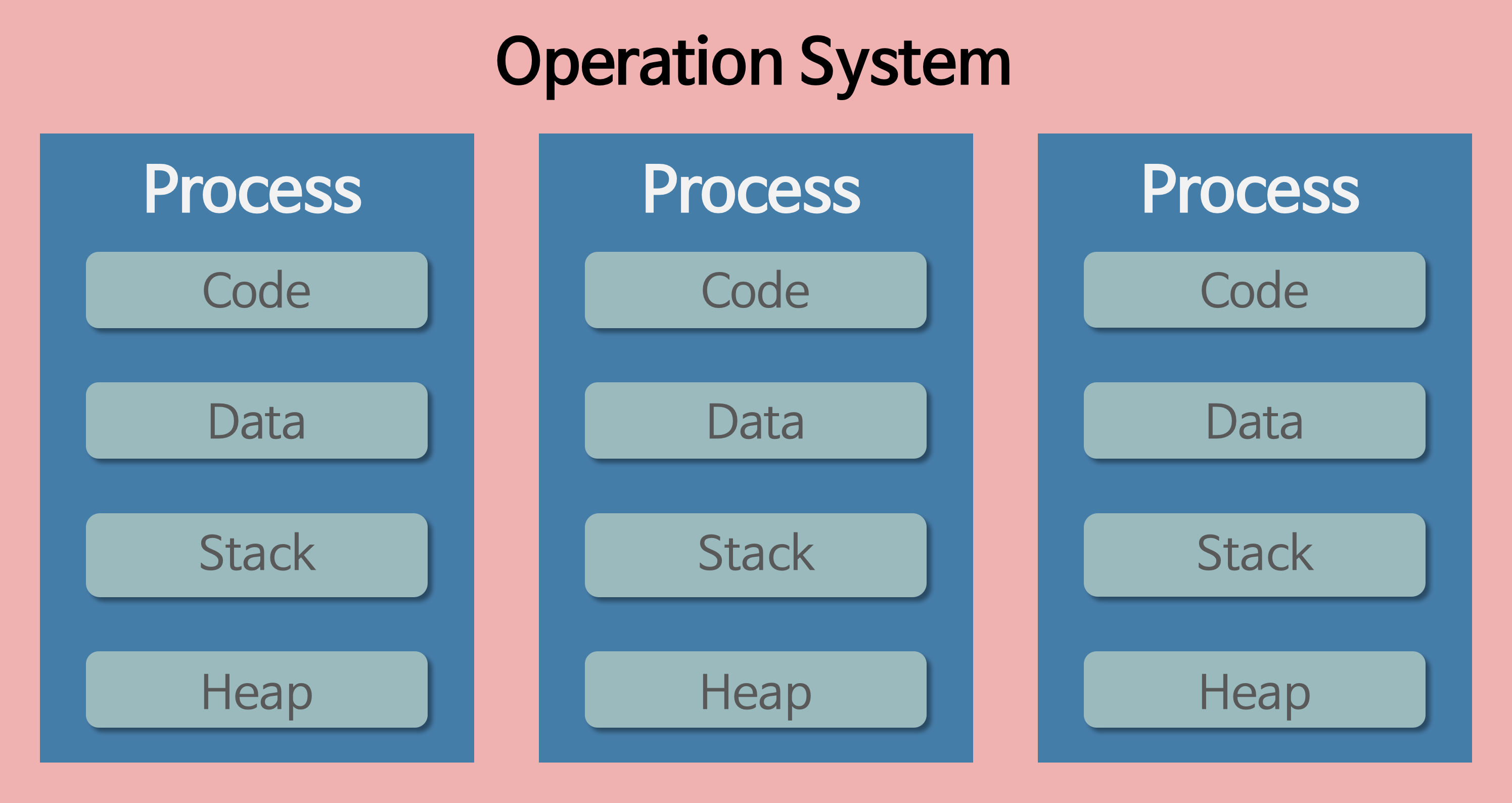
멀티프로세스의 예시로는 프로그램을 여러 개 띄워서 수행하는 것을 들 수 있다. 하나의 계산기에서 값을 입력해서 계산을 했다 하더라도 다른 계산기에 똑같이 그 값이 뜨지 않는다. 같은 프로그램이지만 별도의 메모리 영역에서 독립적으로 수행되고 있기 때문이다.

이전에 설명했듯이, 모든 프로세스는 각자 독자적인 주소공간과 PCB를 가진다.
하지만 그림에서도 볼 수 있듯이, 메모리에 동일한 프로세스가 여러개 올라가있으면 Code와 Data가 중복된다. Code와 Data Segment는 정적 Segment로, 프로그램 실행 내용에 관계 없이 항상 동일하기 때문에 멀티프로세스로 수행하면 메모리 공간이 낭비된다.
뿐만 아니라, 새로운 프로세스를 실행할 때는 주소공간과 PCB를 새로 다 만들어서 메모리에 올려야 한다. 이것은 컴퓨터 차원에서 꽤나 큰 수행 단위이기 때문에, 시간적, 공간적 비용 낭비가 될 수 있다.
그래서 보다 경량화된 단위로 여러 작업을 수행하도록 한 것이 아래의 멀티쓰레드 개념이다.
📌 Multi-Thread
하나의 프로세스 안에서 동시에 실행되는 흐름이 여러 개인 것
카카오톡에서 내가 메세지를 전송하는 동안 카카오톡은 중단되지 않고, 상대방 메세지가 도착하는 대로 바로 화면에 띄워준다. 내 메세지를 전송하는 기능, 새 메세지를 수신하는 기능, 화면에 메세지를 출력하는 기능이 모두 각각의 실행 흐름으로서 동시에 멀티쓰레드로 수행되고 있는 것이다.
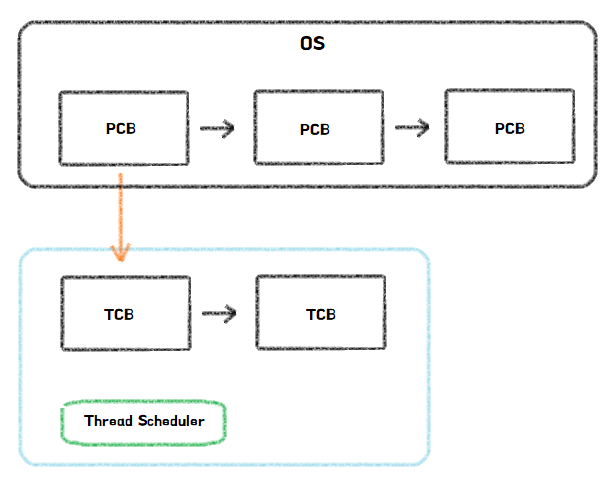
멀티쓰레드에서 각각의 쓰레드는 Stack만 별도의 주소공간에 관리하고, 나머지 주소공간은 프로세스 단위로 관리되어 서로 공유한다. 그렇기 때문에 새로운 프로세스를 생성할 때보다 적은 물리적, 시간적 비용으로 새로운 쓰레드를 생성할 수 있다.
또한, 위 그림에서 볼 수 있듯이, CPU는 쓰레드를 TCB(Thread Control Block)으로 제어한다. 프로세스가 PCB를 통해 관리되는 것처럼, TCB를 통해 실행상태를 제어하는 것이다. TCB는 PCB보다 작고 가볍기 때문에 OS 입장에서는 PCB보다 효율적으로 스케쥴링을 수행할 수 있다.
이러한 멀티쓰레드를 구현할 때는 동기화에 주의해야 한다. 공유되는 전역 변수, 데이터 등에 충돌이 없도록 관리해야 하는 것이다. 또한, 멀티쓰레드에 사용할 쓰레드 개수도 주의해서 구현해야 한다. 쓰레드 개수가 너무 많으면 사용되지 않고 낭비되는 쓰레드가 많아질 수도 있고, 한 쓰레드가 CPU를 점유할 수 있는 시간도 그만큼 줄어들기 때문이다.
Thread pool
쓰레드 자체가 프로세스보다는 작은 단위라 비용이 적게 들기는 하지만, 여전히 생성하는 비용을 최적화하는 것은 중요한 문제다. 생성 비용을 최소화하기 위해 생긴 개념이 바로 Thread pool이다.

쓰레드풀은 프로세스 실행 시에 필요한 만큼 미리 만들어 재사용하는 것을 의미한다. Queue에 Task가 새로 들어오면 쓰레드풀에서 쓰레드를 할당해주고 작업을 수행하도록 하는 것이다. 작업이 끝난 쓰레드는 다시 쓰레드풀에 반납되고, 쓰레드를 요청하는 Task가 있으면 그 쪽으로 가서 작업을 또 수행한다.
이렇게 쓰레드풀을 사용하면 쓰레드의 생성, 삭제 비용을 줄일 수 있다는 장점이 있다. 하지만 쓰레드 개수를 미리 지정하고 그만큼 미리 만들어 놓기 때문에, 모든 쓰레드를 다 사용하지 않으면 생성 비용과 메모리가 낭비될 가능성이 있다는 단점도 있다. 따라서 필요한 쓰레드 수를 정확하게 파악해서 최소 비용으로 최대 생산성을 뽑는 것이 중요하다.
참고
[OS] 멀티프로세스, 멀티스레드, 멀티 프로그래밍, 멀티프로세스 멀티스레드에서의 데이터 통신
[10분 테코톡] 🌷 코다의 Process vs Thread
Threadpool
