[5. 그룹 함수 (GROUP 함수)]
데이터 분석 개요
-
AGGREGATE FUNCTION: GROUP FUNCTION의 한 부분. COUNT, SUM, AVG, MAX, MIN 외 각종 집계 함수들이 포함됨
-
GROUP FUNCTION: GROUP FUNCTION으로는 집계 함수를 제외하고, 소그룹 간의 소계를 계산하는 ROLLUP 함수, GROUP BY 항목들 간 다차원적인 소계를 계산할 수 있는 CUBE 함수, 특정 항목에 대한 소계를 계산하는 GROUPING SETS 함수가 있다
-
WINDOW FUNCTION: 분석 함수나 순위 함수로도 알려져 있음
ROLLUP 함수
- Subtotal을 생성하기 위해 사용됨
- Grouping Columns의 수는 N이라고 했을 때 N+1 Level의 Subtotal이 생성됨
- 인수의 순서에 주의해야함
ROLLUP 함수 사용
- ex) 부서명과 업무명을 기준으로 집계한 일반적인 GROUP BY SQL 문장에 ROLLUP 함수 사용
SELECT DNAME, JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);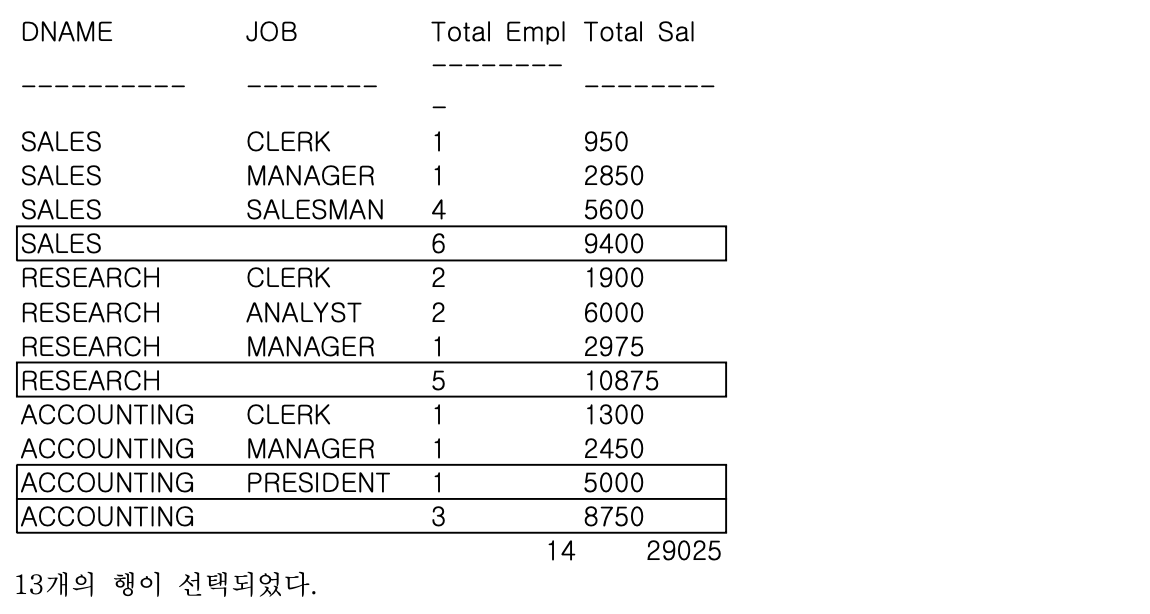
- 실행 결과에서 2개의 GROUPING COLUMNS (DNAME, JOB)에 대해 아래와 같은 추가 LEVEL의 집계가 생성됨
- L1 - GROUP BY 수행 시 생성되는 표준 집계 (9건)
- L2 - DNAME 별 모든 JOB의 SUBTOTAL (3건)
- L3 - GRAND TOTAL (마지막 행, 1건)
- ROLLUP은 LEVEL 별 순서는 정렬하지만, 계층 내 GROUP BY 수행시 생성되는 표준 집계에는 별도의 정렬을 하지 않는다 (L1, L2, L3 계층 내 정렬을 위해서는 별도의 ORDER BY 절을 사용해야함)
GROUPING 함수 사용
- ROLLUP, CUBE, GROUPING SETS 등 새로운 그룹 함수를 지원하기 위해 GROUPING 함수가 추가되었다
- ROLLUP이나 CUBE에 의한 소계가 계산된 결과에는 GROUPING(EXPR) = 1이 표시되고,
- 그 외의 결과에는 GROUPING(EXPR) = 0 이 표시된다
- ex) ROLLUP 함수를 추가한 집계 보고서에서 집계 레코트를 구분할 수 있는 GROUPING 함수가 추가된 SQL 문
SELECT DNAME, GROUPING(DNAME),
JOB, GROUPING(JOB),
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);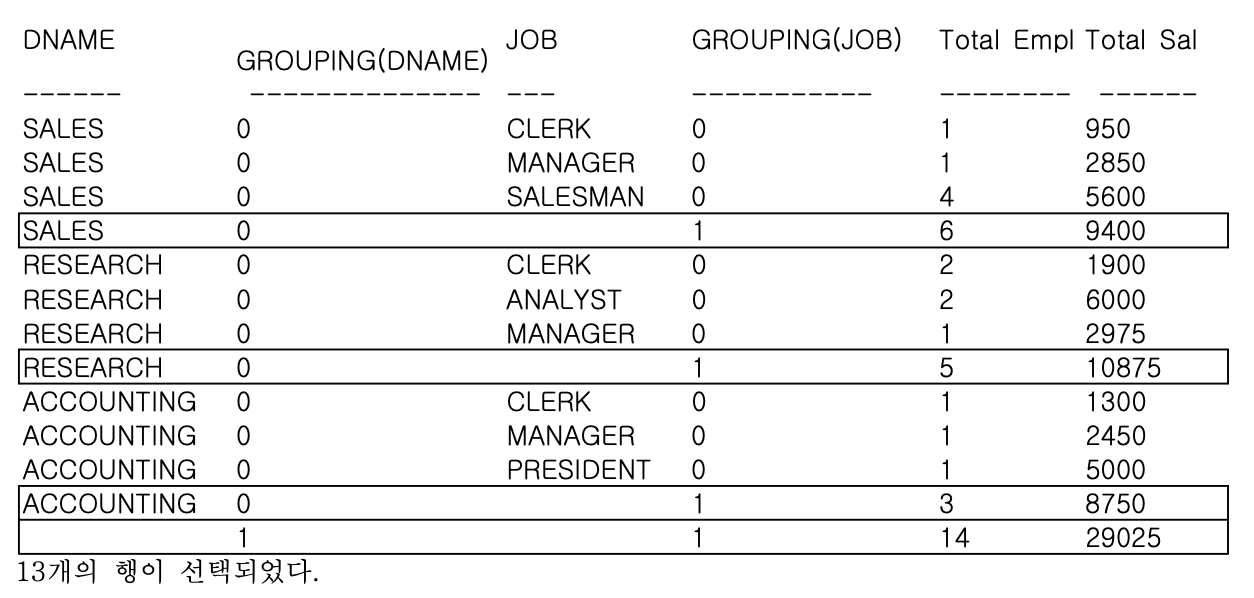
- 부서별, 업무별과 전체 집계를 표시한 레코드에서는 GROUPING 함수가 1을 리턴함
- 전체 합계를 나타내는 결과 라인에서는 부서별 GROUPING 함수와 업무별 GROUPING 함수가 둘 다 1임
ROLLUP 함수 결합 칼럼 사용
- ex) JOB과 MGR는 하나의 집합으로 간주하고, 부서별, JOB & MGR에 대한 ROLLUP 결과를 출력한다
SELECT DNAME, JOB, MGR, SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, (JOB, MGR));-> JOB, MGR을 소계 시 하나의 집합으로 간주하여 구분하지 않음
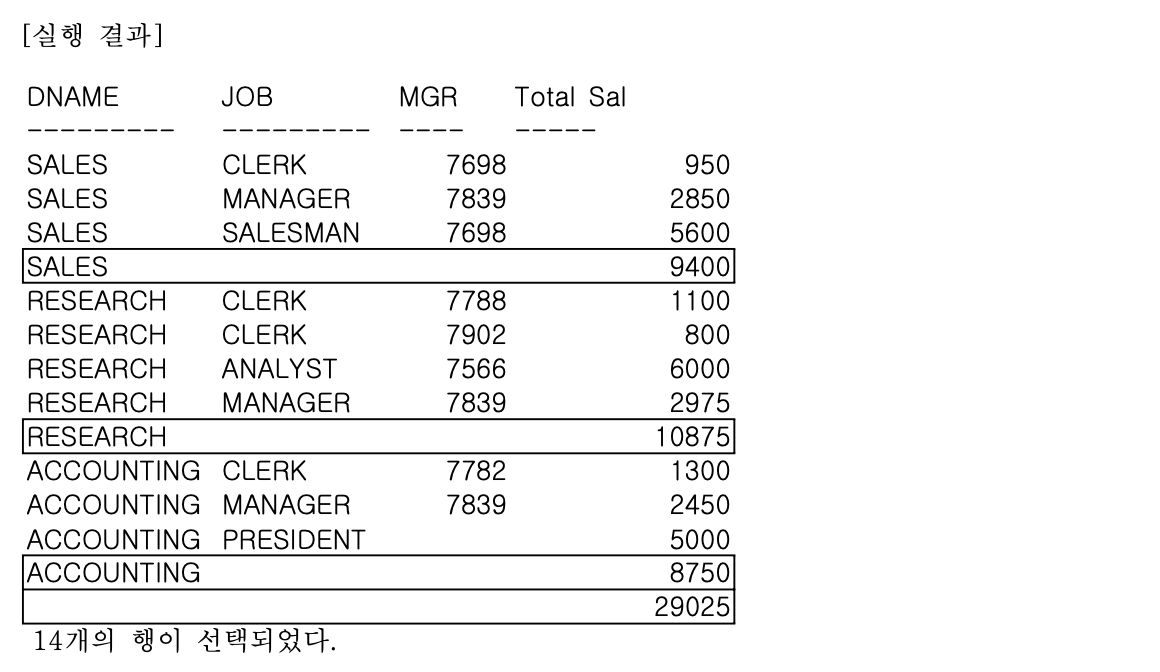
- ROLLUP 함수 사용 시 괄호로 묶은 JOB과 MGR의 경우 하나의 집합(JOB + MGR) 칼럼으로 간주하여 괄호 내 각 칼럼별 집계를 구하지 않음
CUBE 함수
- ROLLUP에서는 Subtotal만을 생성하였지만, CUBE는 결합 가능한 모든 값에 대하여 다차원 집계를 생성한다
- CUBE를 사용할 경우 내부적으로 Grouping Columns의 순서를 바꾸어서 도 한 번의 Query를 추가 수행한다
- Grouping Columns이 가질 수 있는 모든 경우에 대하여 Subtotal을 생성해야 하는 경우에는 CUBE를 사용하는 것이 바람직하나, ROLLUP에 비해 시스템에 많은 부담을 주므로 사용에 주의해야함
- CUBE 함수의 경우 표시된 인수들에 대한 계층별 집계를 구할 수 있으며, 이때 표시된 인수들 간에는 계층 구조인 ROLLUP과는 달리 평등한 관계이므로 인수의 순서가 바뀌는 경우 행간에 정렬 순서는 바뀔 수 있어도 데이터 결과는 같다
CUBE 함수 이용
- ex) GROUP BY ROLLUP (DNAME, JOB) 조건에서 GROUP BY CUBE (DNAME, JOB) 조건으로 변경해서 수행
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN "All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN "All Jobs" ELSE JOB END AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE (DNAME, JOB);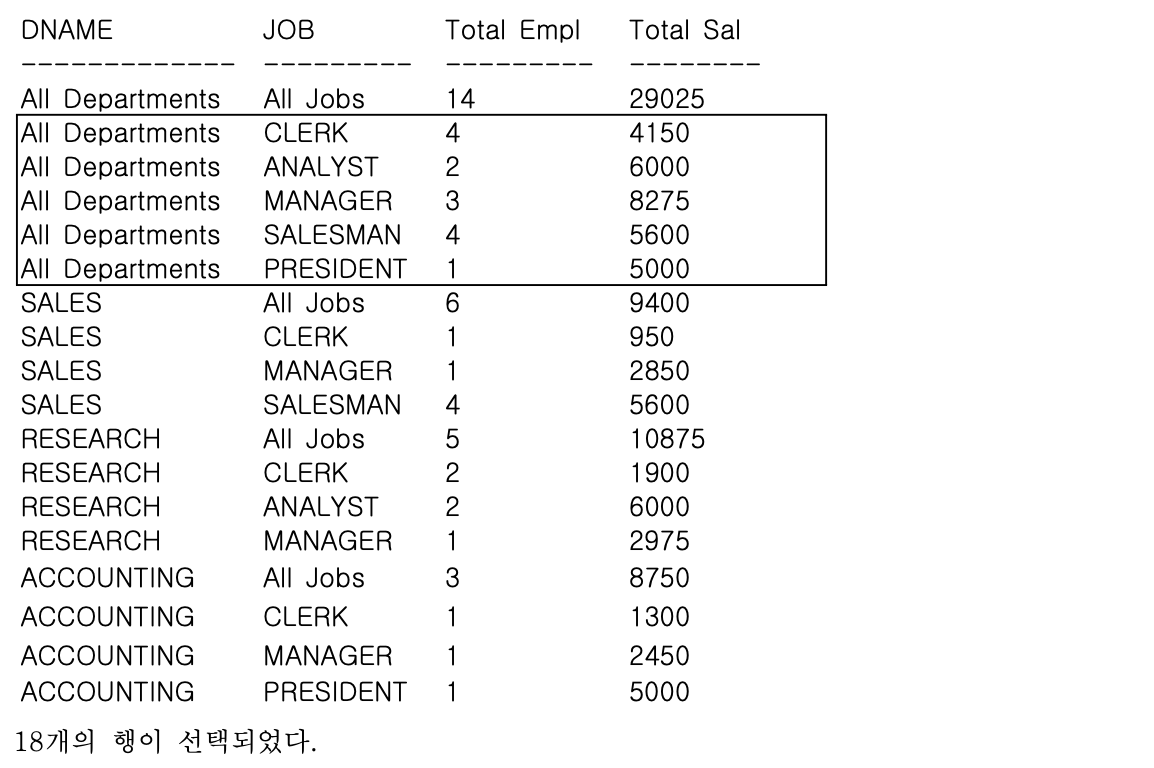
- CUBE는 GROUPING COLUMNS이 가질 수 있는 모든 경우의 수에 대하여 Subtotal을 생성하므로 GROUPING COLUMNS의 수가 N이라고 가정하면, 2의 N승 LEVEL의 Subtotal을 생성하게 된다
UNION ALL 사용 SQL
- UNION ALL은 Set Operation 내용으로, 여러 SQL 문장을 연결하는 역할을 할 수 있다
SELECT DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal" FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
UNION ALL
SELECT DNAME, 'All Jobs', COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'All Departments', JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal" FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY JOB
UNION ALL
SELECT 'All Departments', 'All Jobs', COUNT(*) "Total Empl", SUM(SAL) "Total Sal" FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO ;- CUBE 함수를 사용하면서 가장 크게 개선되는 부분은 CUBE 사용 전 SQL에서 EMP, DEPT 테이블을 네 번이나 반복 엑세스하는 부분을 CUBE 사용 SQL에서는 한 번으로 줄일 수 있는 부분이다.
GROUPING SETS 함수
- GROUPING SETS에 표시된 인수들에 대한 개별 집계를 구할 수 있으며, 이 때 표시된 인수들 간에는 계층 구조인 ROLLUP과는 달리 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같다
GROUPING SETS 사용 SQL
- 일반 그룹함수를 이용하여 부서별, JOB별 인원수와 급여 합을 구하라
SELECT DNAME, 'All Jobs' JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT "All Departments" DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY JOB;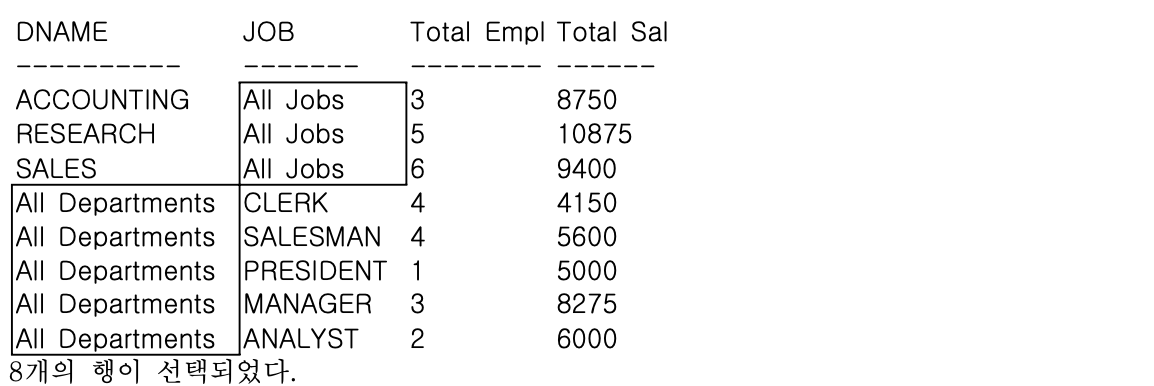
- 일반 그룹함수를 GROUPING SETS 함수로 변경하여 부서별, JOB별 인원수와 급여합을 구하라
SELECT DECODE(GROUPING(DNAME), 1, 'All Departments', DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1, 'All Jobs', JOB) AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB);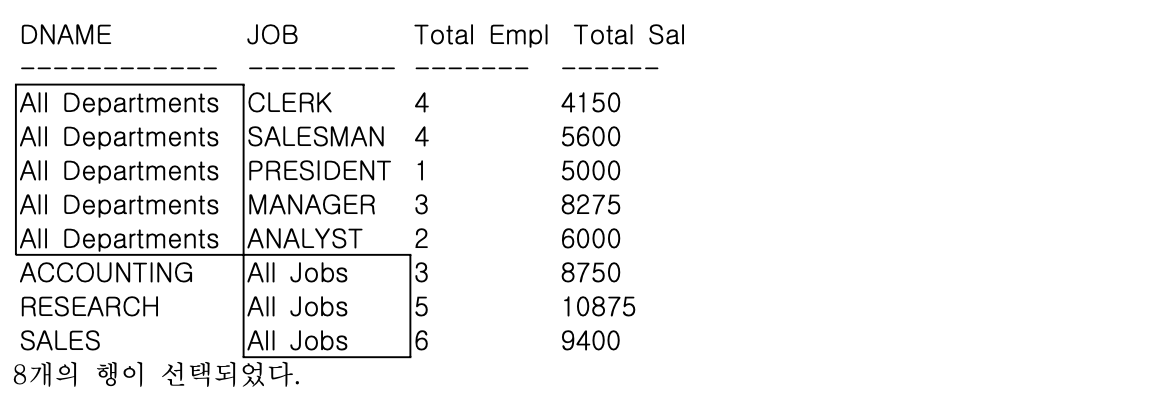
- GROUPING SETS 함수 사용 시 UNION ALL을 사용한 일반 그룹함수를 사용한 SQL과 같은 결과를 얻을 수 있으며, 괄호로 묶은 집합 별로(괄호 내는 계층 구조가 아닌 하나의 데이터로 간주함) 집계를 구할 수 있다
3개의 인수를 이용한 GROUPING SETS 이용
- ex) 부서-JOB-매니저 별 집계와, 부서-JOB 별 집계와, JOB-매니저 별 집계를 GROUPING SETS 함수를 이용해서 구해본다
SELECT DNAME, JOB, MGR, SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS
((DNAME, JOB, MGR), (DNAME, JOB), (JOB, MGR));- GROUPING SETS 함수 사용 시 괄호로 묶은 집합별로(괄호 내는 계층구조가 아닌 하나의 데이터로 간주함) 집계를 구할 수 있다
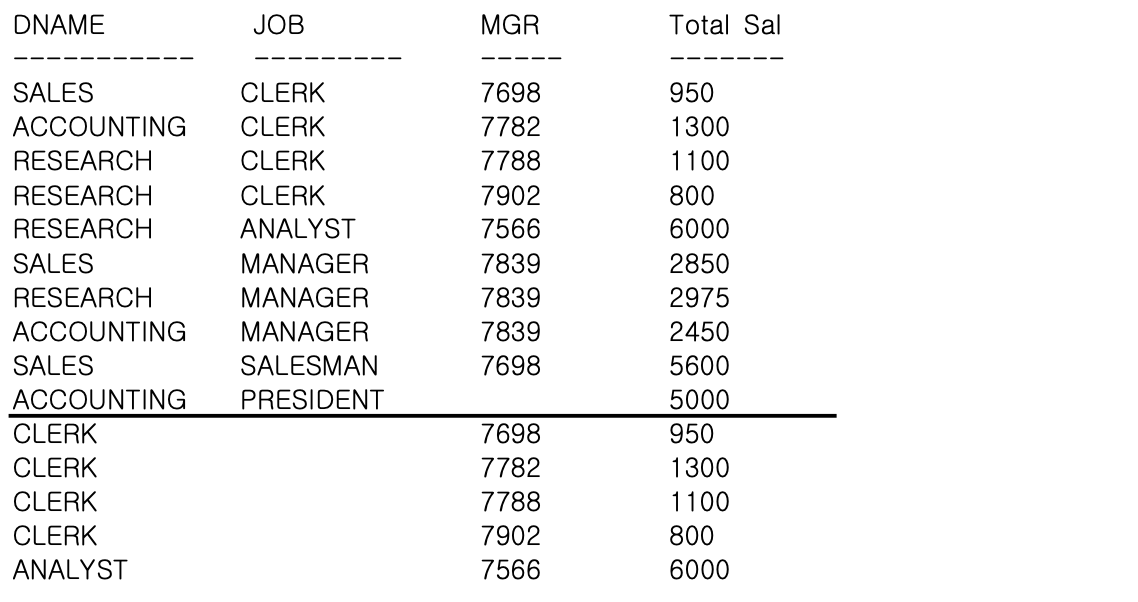
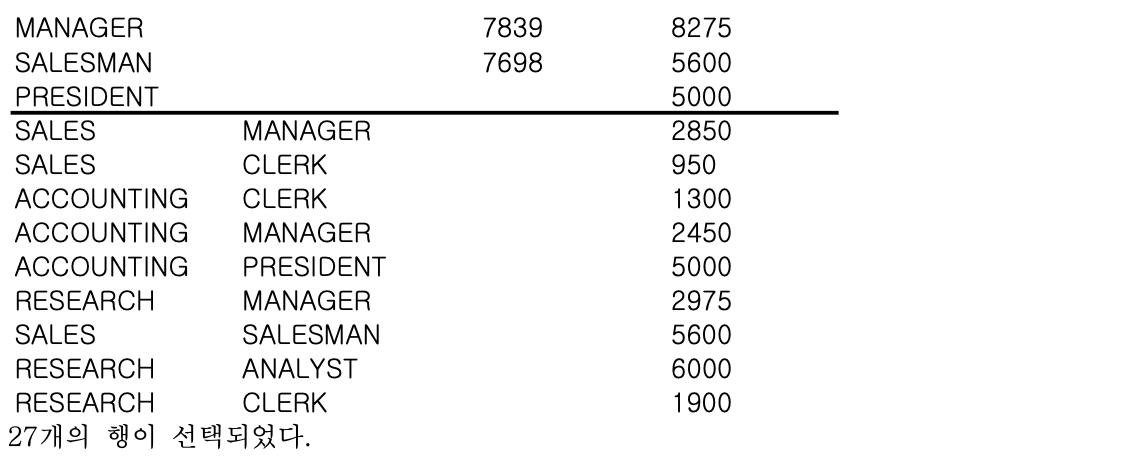
- 첫 번째 10건의 데이터는 (DNAME + JOB + MGR) 기준의 집계
- 두 번째 8건의 데이터는 (JOB + MGR) 기준의 집계
- 세 번째 9건의 데이터는 (DNAME + JOB) 기준의 집계
[6. 윈도우 함수 (WINDOW 함수)]
WINDOW FUNCTION 개요
- WINDOW FUNCTION: 행과 행간의 관계를 정의하거나 행과 행간을 비교, 연산하는 함수
- WINDOW FUNCTION의 종류는 크게 네 개의 그룹으로 분류 가능
- 그룹 내 순위(RANK) 관련 함수
- 그룹 내 집계(AGGRECATE) 관련 함수
- 그룹 내 행 순서 관련 함수
- 그룹 내 비율 관련 함수
SELECT WINDOW_FUNCTION (ARGUMENTS) OVER
( [PARTITION BY 칼럼] [ORDER BY 절] [WINDOWING 절] )
FROM 테이블 명;- WINDOW 함수에는 위와 같이 OVER 문구가 키워드로 필수 포함된다
- WINDOW_FUNCTION: 기존에 사용하던 함수도 있고, 새롭게 WINDOW 함수용으로 추가된 함수도 있다
- ARGUMENTS: 함수에 따라 0~N개의 인수가 지정될 수 있다
- PARTITION BY 절: 전체 집합을 기준에 의해 소그룹으로 나눌 수 있다
- ORDER BY 절: 어떤 항목에 대해 순휘를 지정할 지 ORDER BY 절을 기술한다
- WINDOWING 절: WINDOWING 절은 함수의 대상이 되는 행 기준의 범위를 강력하게 지정할 수 있다. ROWS는 물리적인 결과 행의 수를, RANGE는 논리적인 값에 의한 범위를 나타내는데, 둘 중의 하나를 선택해서 사용할 수 있다
그룹 내 순위 함수
RANK 함수
-
RANK 함수는 ORDER BY를 포함한 QUERY 문에서 특정 칼럼에 대한 순위를 구하는 함수이다
-
ex) 사원 데이터에서 급여가 높은 순서와 JOB 별로 급여가 높은 순서를 같이 출력
SELECT JOB, ENAME< SAL,
RANK() OVER (ORDER BY SAL DESC) ALL_RANK,
RANK() OVER (PARTITION BY JOB ORDER BY SAL DESC) JOB_RANK
FROM EMP;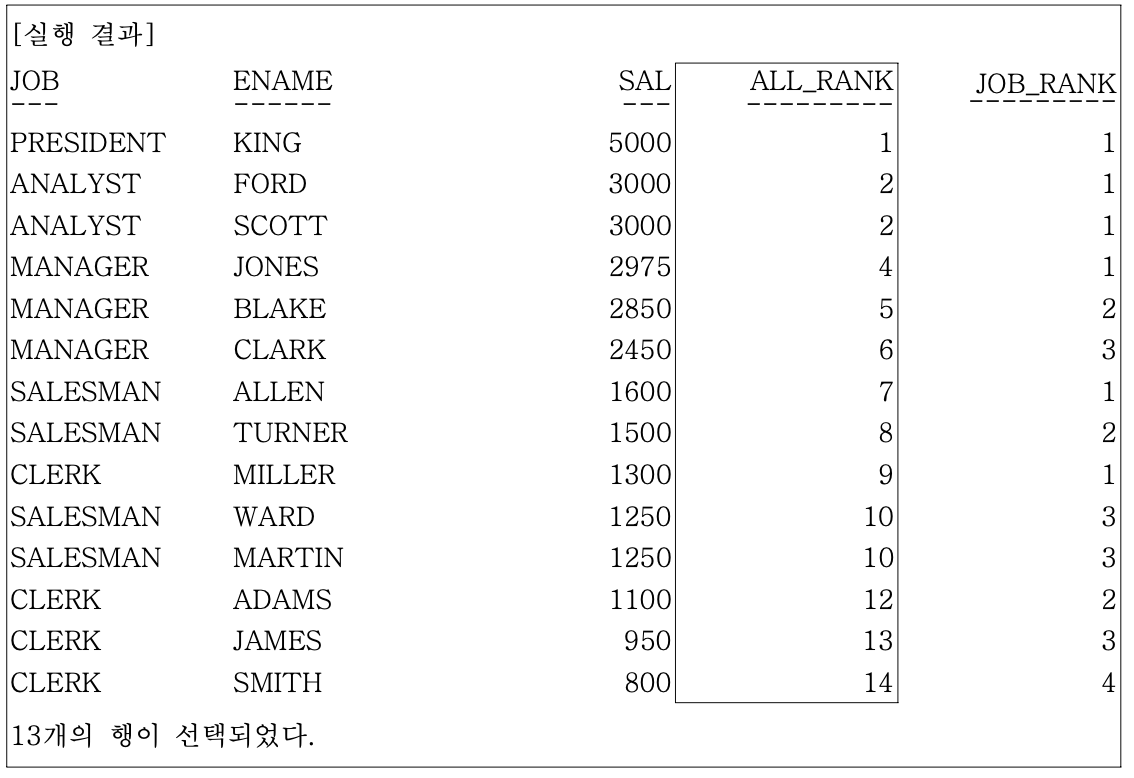
- ex) 앞의 SQL문의 결과는 JOB과 SALARY 기준으로 정렬이 되어있지 않다. 새로운 SQL에서는 전체 SALARY 순위를 구하는 ALL_RANK 칼럼은 제외하고, 업무별로 SALARY 순서를 구하는 JOB_RANK만 알아보도록
SELECT JOB, ENAME, SAL, RANK() OVER(PARTITION BY JOB ORDER BY SAL DESC) JOB_RANK
FROM EMP;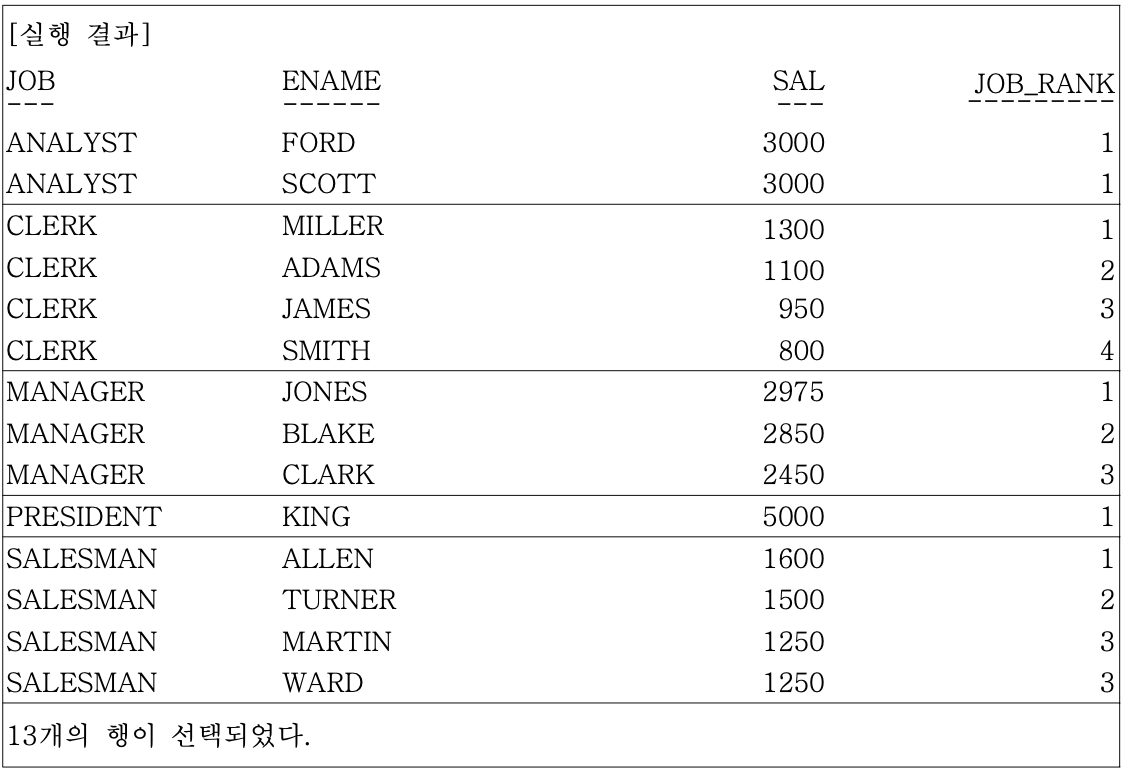
DENSE_RANK 함수
- DENSE_RANK 함수는 RANK 함수와 흡사하나, 동일한 순위를 하나의 건수로 취급하는 것이 차이점이다
- ex) 사원데이터에서 급여가 높은 순서와, 동일한 순위를 하나의 등수로 간주한 결과도 같이 출력
SELECT JOB, ENAME, SAL,
RANK() OVER (ORDER BY SAL DESC) RANK,
DENSE_RANK() OVER (ORDER BY SAL DESC) DENSE_RANK
FROM EMP;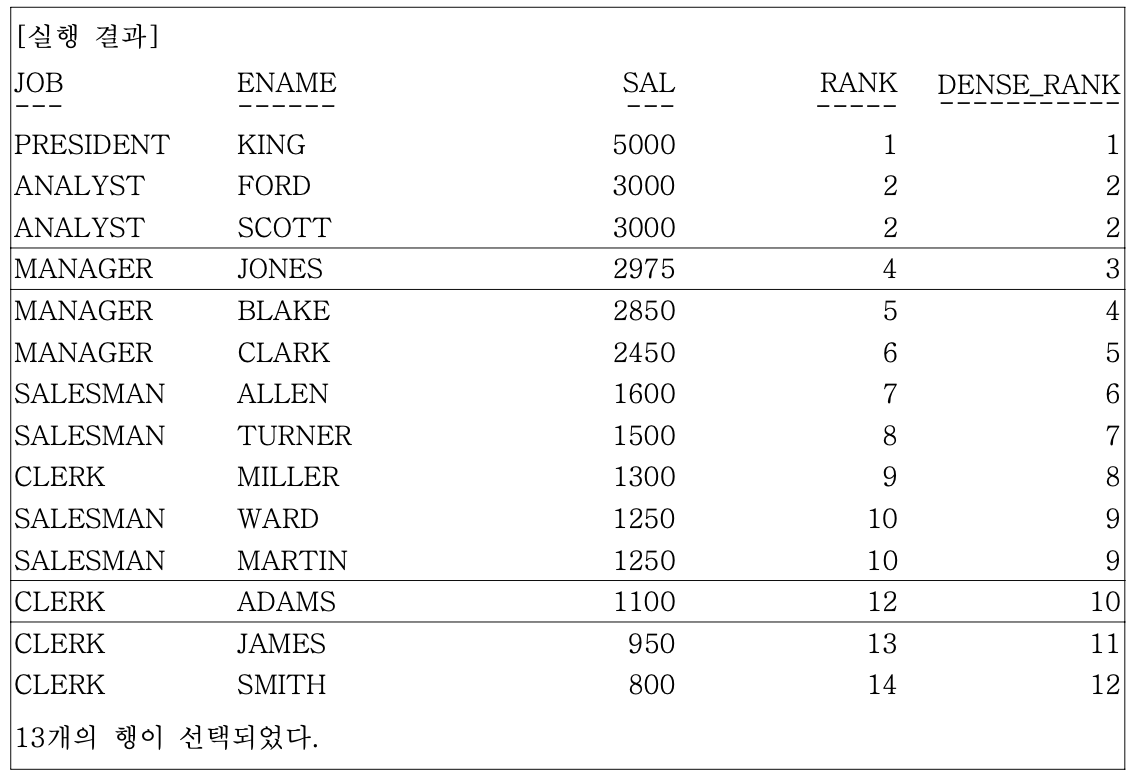
ROW_NUMBER 함수
- ROW_NUMBER 함수는 RANK나 DENSE_RANK 함수가 동일한 값에 대해서는 동일한 순위를 부여하는데 반해, 동일한 값이라도 고유한 순위를 부여한다
- ex) 사원데이터에서 급여가 높은 순서와, 동일한 순위를 인정하지 않는 등수도 같이 출력한다
SELECT JOB, ENAME, SAL,
RANK( ) OVER (ORDER BY SAL DESC) RANK,
ROW_NUMBER() OVER (ORDER BY SAL DESC) ROW_NUMBER
FROM EMP;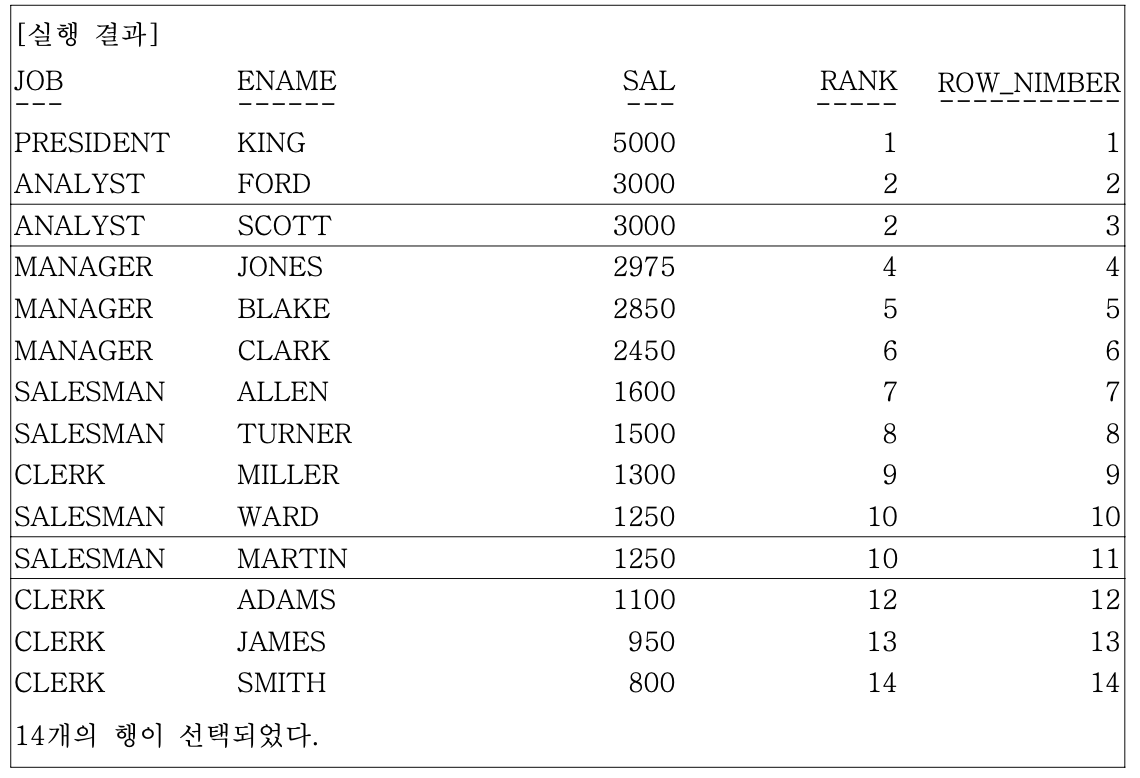
일반 집계 함수
SUM 함수
- SUM 함수를 이용해 파티션별 윈도우의 합을 구할 수 있다
- ex) 사원들의 급여와 같은 메니저를 두고 있는 사원들의 SALARY 합을 구한다
SELECT MGR, ENAME, SAL, SUM(SAL) OVER (PARTITION BY MGR) MGR_SUM
FROM EMP;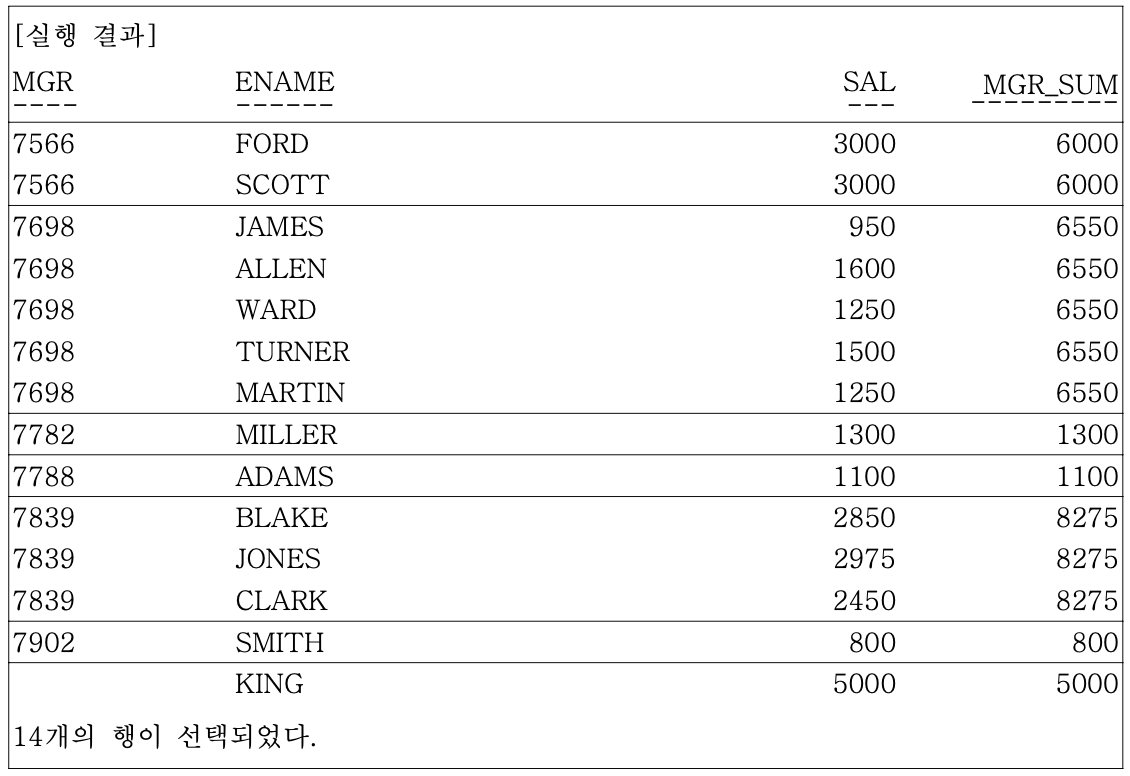
MAX 함수
- MAX 함수를 이용해 파티션별 윈도우의 최대값을 구할 수 있다
- ex) 사원들의 급여와 같은 매니저를 두고 있는 사원들의 SALARY 중 최대값을 같이 구한다
SELECT MGR, ENAME, SAL, MAX(SAL) OVER (PARTITION BY MGR) as MGR_MAX
FROM EMP;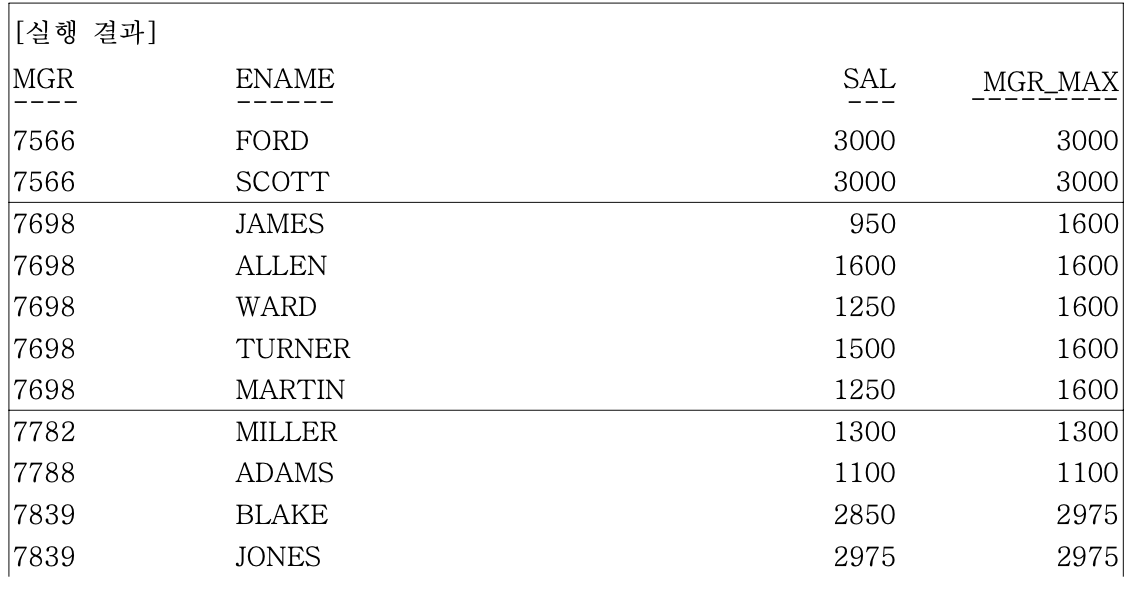

MIN 함수
- MIN 함수를 이용해 파티션별 윈도우의 최소값을 구할 수 있다
- ex) 사원들의 급여와 같은 매니저를 두고 있는 사원들을 입사일자를 기준으로 정렬하고, SALARY 최소값을 같이 구한다
SELECT MGR, ENAME, HIREDATE, SAL,
MIN(SAL) OVER(PARTITION BY MGR ORDER BY HIREDATE) as MGR_MIN FROM EMP;AVG 함수
- AVG 함수와 파티션별 ROWS 윈도우를 이용해 원하는 조건에 맞는 데이터에 대한 통계값을 구할 수 있다
COUNT 함수
- COUNT 함수와 파티션별 ROWS 윈도우를 이용해 원하는 조건에 맞는 데이터에 대한 통계 값을 구할 수 있다
그룹 내 행 순서 함수
FIRST_VALUE 함수
- FIRST_VALUE 함수를 이용해 파티셔별 윈도우에서 가장 먼저 나온 값을 구할 수 있다
- ex) 부서별 직원들을 연봉이 높은 순서부터 정렬하고, 파티션 내에서 가장 먼저 나온 값을 출력
SELECT DEPTNO, ENAME, SAL, FIRST_VALUE(ENAME)
OVER (PARTITION BY DEPTNO ORDER BY SAL DESC
ROWS UNBOUNDED PRECEDING) as DEPT_RICH
FROM EMP;
RANGE UNBOUNDED PRECEDING :LAST_VALUE 함수
- LAST_VALUE 함수를 이용해 파티션별 윈도우에서 가장 나중에 나온 값을 구할 수 있다
- ex) 부서별 직원들을 연봉이 높은 순서대로 정렬하고, 파티션 내에서 가장 마지막에 나온 값을 출력
SELECT DEPTNO, ENAME, SAL,
LAST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL DESC
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) as DEPT_POOR
FROM EMP;
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING:LAG 함수
- LAG 함수를 이용해 파티션별 윈도우에서 이전 몇 번째 행의 값을 가져올 수 있다
- ex) 직원들을 입사일자가 빠른 기준으로 정렬을 하고, 본인보다 입사일자가 한 명 앞선 사원의 급여를 본인의 급여와 함께 출력한다
SELECT ENAME, HIREDATE, SAL, LAG(SAL) OVER (ORDER BY HIREDATE) as PREV_SAL
FROM EMP
WHERE JOB = 'SALESMAN';LEAD 함수
- LEAD 함수를 이용해 파티션별 윈도우에서 이후 몇 번째 행의 값을 가져올 수 있다
- ex) 직원들을 입사일자가 빠른 기준으로 정렬을 하고, 바로 다음에 입사한 인력의 입사일자를 함께 출력한다
SELECT ENAME, HIREDATE,
LEAD (HIREDATE, 1) OVER (ORDER BY HIREDATE) as "NEXTHIRED"
FROM EMP;그룹 내 비율 함수
RATIO_TO_REPORT 함수
- RATIO_TO_REPORT 함수를 이용해 파티션 내 전체 SUM(캄럼)값에 대한 행별 칼럼 값의 백분율을 소수점으로 구할 수 있
- 결과 값은 > 0 & <= 1의 범위를 가진다
- 개별 RATIO의 합을 구하면 1
- ex) JOB이 SALESMAN인 사원들을 대상으로 전체 급여에서 본인이 차지하는 비율을 출력
SELECT ENAME, SAL, ROUND(RATIO_TO_REPORT(SAL) OVER (), 2) as R_R
FROM EMP
WHERE JOB = 'SALESMAN';PERCENT_RANK 함수
- PERCENT_RANK 함수를 이용해 파티션별 윈도우에서 제일 먼저 나오는 것을 0으로, 제일 늦게 나오는 것을 1로 하여, 값이 아닌 행의 순서별 백분율을 구한다
- 결과 값은 >= 0 & <= 1의 범위를 가진다
- ex) 같은 부서 소속 사원들의 집합에서 본인의 급여가 순서상 몇 번째 위치쯤에 있는지 0과 1 사이의 값으로 출력
SELECT DEPTNO, ENAME, SAL,
PERCENT_RANK() OVER (PARTITION BY DEPTNO ORDER BY SAL DESC) as P_R
FROM EMP;CUME_DIST 함수
- CUME_DIST 함수를 이용해 파티션별 윈도우의 전체건수에서 현재 행보다 작거나 같은 건수에 대한 누적백분율을 구한다
- 결과 값은 > 0 & <= 1의 범위를 가진다
- ex) 같은 부서 소속 사원들의 집합에서 본인의 급여가 누적 순서상 몇 번째 위치쯤에 있는 지 0과 1 사이의 값으로 출력
SELECT DEPTNO, ENAME, SAL,
CUME_DIST() OVER (PARTITION BY DEPTNO ORDER BY SAL DESC) as CUME_DIST
FROM EMP;NTILE 함수
- NTILE 함수를 이용해 파티션별 전체 건수를 ARGUMENT 값으로 N 등분한 결과를 구할 수 있다
- ex) 전체 사원을 급여가 높은 순서로 정렬하고, 급여를 기준으로 4개의 그룹으로 분류
SELECT ENAME, SAL, NTILE(4) OVER (ORDER BY SAL DESC) as QUAR_TILE
FROM EMP- NTILE(4)의 의미를 14명의 팀원을 4개의 조로 나눈다는 의미
- 전체 14명을 4개의 집합으로 나누면 몫이 3명, 나머지가 2명
-> 4명 + 4명 + 3명 + 3명
- 전체 14명을 4개의 집합으로 나누면 몫이 3명, 나머지가 2명
[7. DCL (data control language)]
- DCL: 유저를 생성하고 권한을 제어할 수 있는 명령어
Oracle과 SQL Server의 사용자 아키텍처 차이
- Oracle: 유저를 통해 DB에 접속을 하는 형태, ID와 PW 방식으로 인스턴스에 접속을 하고 그에 해당하는 스키마에 오브젝트 생성 등의 권한을 부여받게 됨
- SQL Server: 인스턴스에 접속하기 위해 로그인이라는 것을 생성하게 되며, 인스턴스 내에 존재하는 다수의 DB에 연결하여 작업하기 위해 유저를 생성한 후 로그인과 유저를 매핑해 주어야 한다. Windows 인증 방식과 혼합 모드 방식이 존재함
시스템 권한
- 시스템 권한 : 사용자가 SQL 문을 실행하기 위해 필요한 적절한 권한
- GRANT : 권한 부여
- REVOKE : 권한 취소
GRANT CREATE USER TO SCOTT;
CONN SCOTT/TIGER(ID/PW)
CREATE USER PJS IDENTIFIED BY KOREA7;
GRANT CREATE SESSION TO PJS;
GRANT CREATE TABLE TO PJS;
REVOKE CREATE TABLE FROM PJS;- 모든 유저는 각각 자신이 생성한 테이블 외에 다른 유저의 테이블에 접근하려면 해당 테이블에 대한 오브젝트 권한을 소유자로부터 부여받아야 한다
ROLE
- ROLE : 유저에게 알맞은 권한들을 한 번에 부여하기 위해 사용하는 것
CREATE ROLE LOGIN_TABLE;
GRANT CREATE TABLE TO LOGIN_TABLE;
DROP USER PJS CASCADE;
# (CASCADE : 하위 오브젝트까지 삭제)[8. 절차형 SQL]
- 절차형 SQL: SQL문의 연속적인 실행이나 조건에 따른 분기처리를 이용하여 특정 기능을 수행하는 저장 모듈을 생성할 수 있다
PL/SQL
- Oracle의 PL/SQL은 Block 구조로 되어있고 Block 내에는 DML 문장과 QUERY 문장, 그리고 절차형 언어(IF, LOOP) 등을 사용할 수 있으며, 절차적 프로그래밍을 가능하게 하는 트랜잭션 언어이다
- 이런 PL/SQL을 이용하여 다양한 저장 모듈(Stored Module)을 개발할 수 있다
- 저장 모듈이란 PL/SQL 문장을 데이터베이스 서버에 저장하여 사용자와 어플리케이션 사이에서 공유할 수 있도록 만든 일종의 SQL 컴포넌트 프로그램이며, 독립적으로 실행되거나 다른 프로그램으로부터 실행될 수 있는 완전한 실행 프로그램이다
- Procedure, User Defined Function, Trigger가 있다
PL/SQL의 특징
- PL/SQL은 Block 구조로 되어있어 각 기능별로 모듈화가 가능하다
- 변수, 상수 등을 선언하여 SQL 문장 간 값을 교환한다
- IF, LOOP 등의 절차형 언어를 사용하여 절차적인 프로그램이 가능하도록 한다
- DBMS 정의 에러나 사용자 정의 에러를 정의하여 사용할 수 있다
- PL/SQL은 Oracle에 내장되어 있으므로 Oracle과 PL/SQL을 지원하는 어떤 서버로도 프로그램을 옮길 수 있다
- PL/SQL은 응용 프로그램의 성능을 향상시킨다
- PL/SQL은 여러 SQL 문장을 Block으로 묶고 한 번에 Block 전부를 서버로 보내기 때문에 통신량을 줄일 수 있다
PL/SQL Architecture
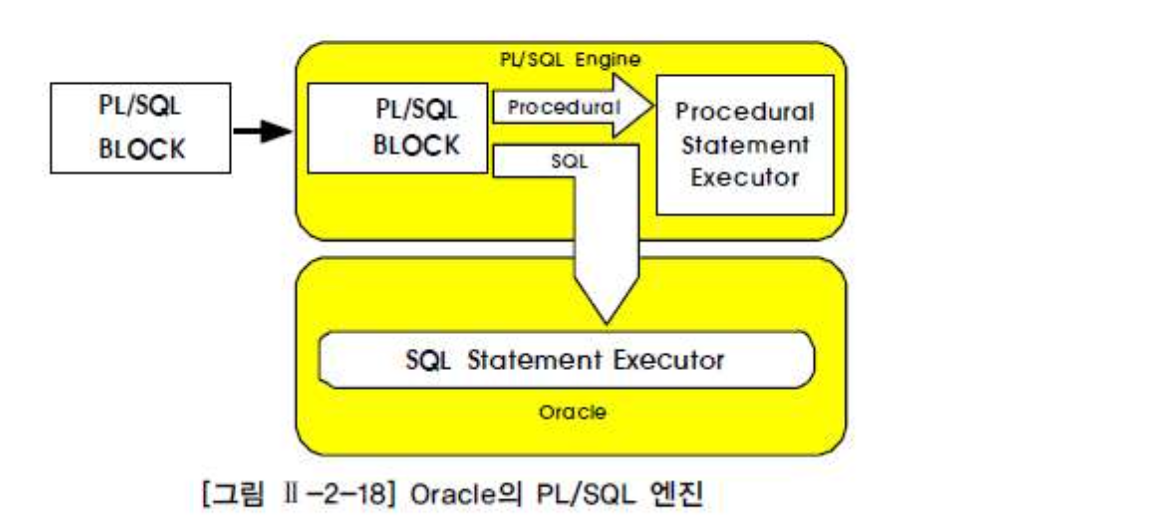
- PL/SQL Block 프로그램을 입력받으면 SQL 문장과 프로그램 문장을 구분하여 처리한다
- 프로그램 문장은 PL/SQL 엔진이 처리하고 SQL 문장은 Oracle 서버의 SQL Statement Executor가 실행하도록 작업을 분리하여 처리한다
PL/SQL Block 구조
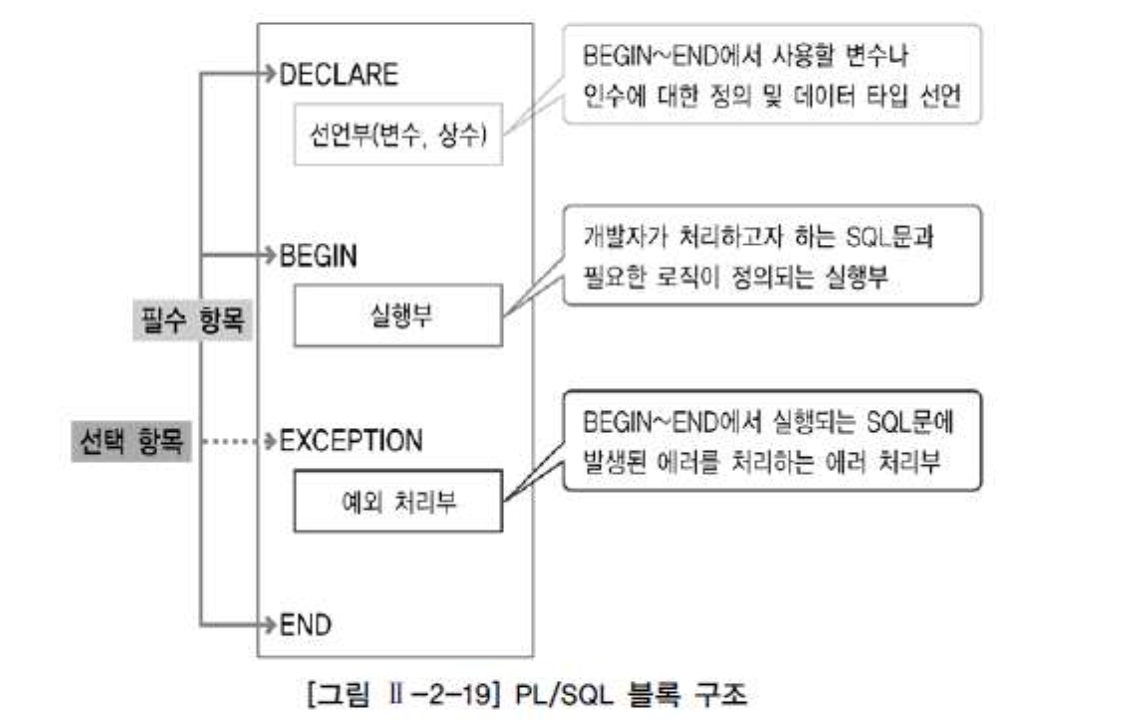
- DECLARE: BEGIN ~ END 절에서 사용될 변수와 인수에 대한 정의 및 데이터 타입을 선언하는 선언부
- BEGIN ~ END: 개발자가 처리하고자 하는 SQL문과 여러 가지 비교문, 제어문을 이용하여 필요한 로직을 처리하는 실행부
- EXCEPTION: BEGIN ~ END 절에서 실행되는 SQL문이 실행될 때 에러가 발생하면 그 에러를 어떻게 처리할 것인지를 정의하는 예외 처리부
T-SQL
- T-SQL: 근본적으로 SQL Server를 제어하는 언어이다. T-SQL을 이용하여 다양한 저장 모듈(Stored Module)을 개발할 수 있다
T-SQL Block 구조
- PL/SQL과 유사하다
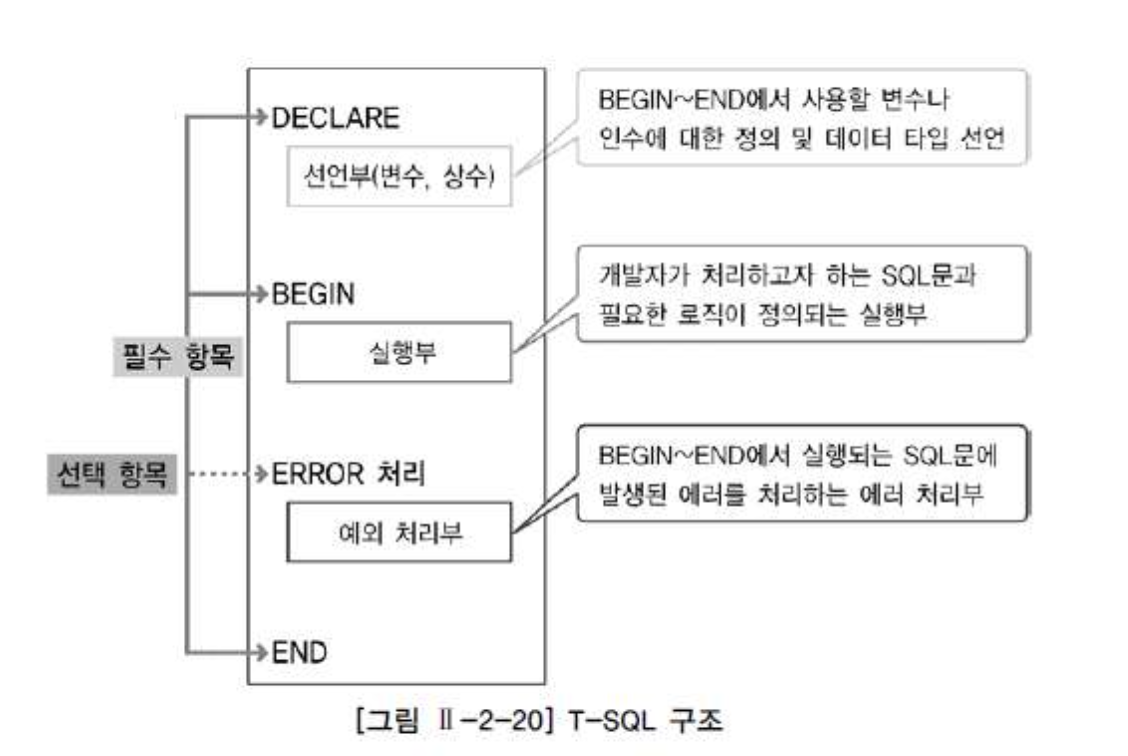
- DECLARE: BEGIN ~ END 절에서 사용될 변수와 인수에 대한 정의 및 데이터 타입을 선언하는 선언부
- BEGIN ~ END: 개발자가 처리하고자 하는 SQL문과 여러 가지 비교문, 제어문을 이용하여 필요한 로직을 처리하는 실행부/ T-SQL에서는 BEGIN, END 문을 반드시 사용해야하는 것은 아니지만 블록 단위로 처리하고자 할 때는 반드시 작성해야 한다
- ERROR 처리: BEGIN ~ END 절에서 실행되는 SQL문이 실행될 때 에러가 발생하면 그 에러를 어떻게 처리할 것인지를 정의하는 예외 처리부
Procedure
User Defined Function
- User Defined Function은 Procedure처럼 절차형 SQL을 로직과 함께 데이터베이스 내에 저장해 놓은 명령문의 집합을 의미한다
- 앞에서 학습한 SUM, SUBSTR, NVL 등의 함수는 벤더에서 미리 만들어둔 내장 함수이고, 사용자가 별도의 함수를 만들 수도 있다
- Function이 Procedure와 다른 점은 RETURN을 사용해서 하나의 값을 반드시 되돌려 줘야 한다는 것이다. 즉, Function은 Procedure와는 달리 SQL 문장에서 특정 작업을 수행하고 반드시 수행 결과 값을 리턴한다
Trigger
- Trigger란 특정한 테이블에 INSERT, UPDATE, DELETE와 같은 DML문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 프로그램이다. 즉, 사용자가 직접 호출하여 사용하는 것이 아니고 데이터베이스에서 자동적으로 수행하게 된다.
Procedure와 Trigger의 차이점
- Procedure는 BEGIN ~ END 절 내에 COMMIT, ROLLBACK 과 같은 트랜잭션 종료 명령어를 사용할 수 있지만, 데이터베이스 Trigger는 BEGIN ~ END 절 내에 사용할 수 없다


💼 Software Engineer @ LG Electronics | 🎓 SungKyunKwan Univ. CSE