[6. 함수 (FUNCTION)]
내장 함수 (BUILT-IN FUNCTION) 개요
- 내장 함수는 함수의 입력 값이 단일행 값이 입력되는 단일행 함수(Single-Row Function)와 여러 행의 값이 입력되는 다중행 함수(Multi-Row Function)로 나눌 수 있다.
-> 단일행 함수는 처리하는 데이터의 형식에 따라서 문자형, 숫자형, 날짜형, 변환형, NULL관련 함수로 나눌 수 있다.
-> 다중행 함수는 다시 집계 함수(Aggregate Function), 그룹 함수(Group Function), 윈도우 함수(Window Function)로 나눌 수 있다.
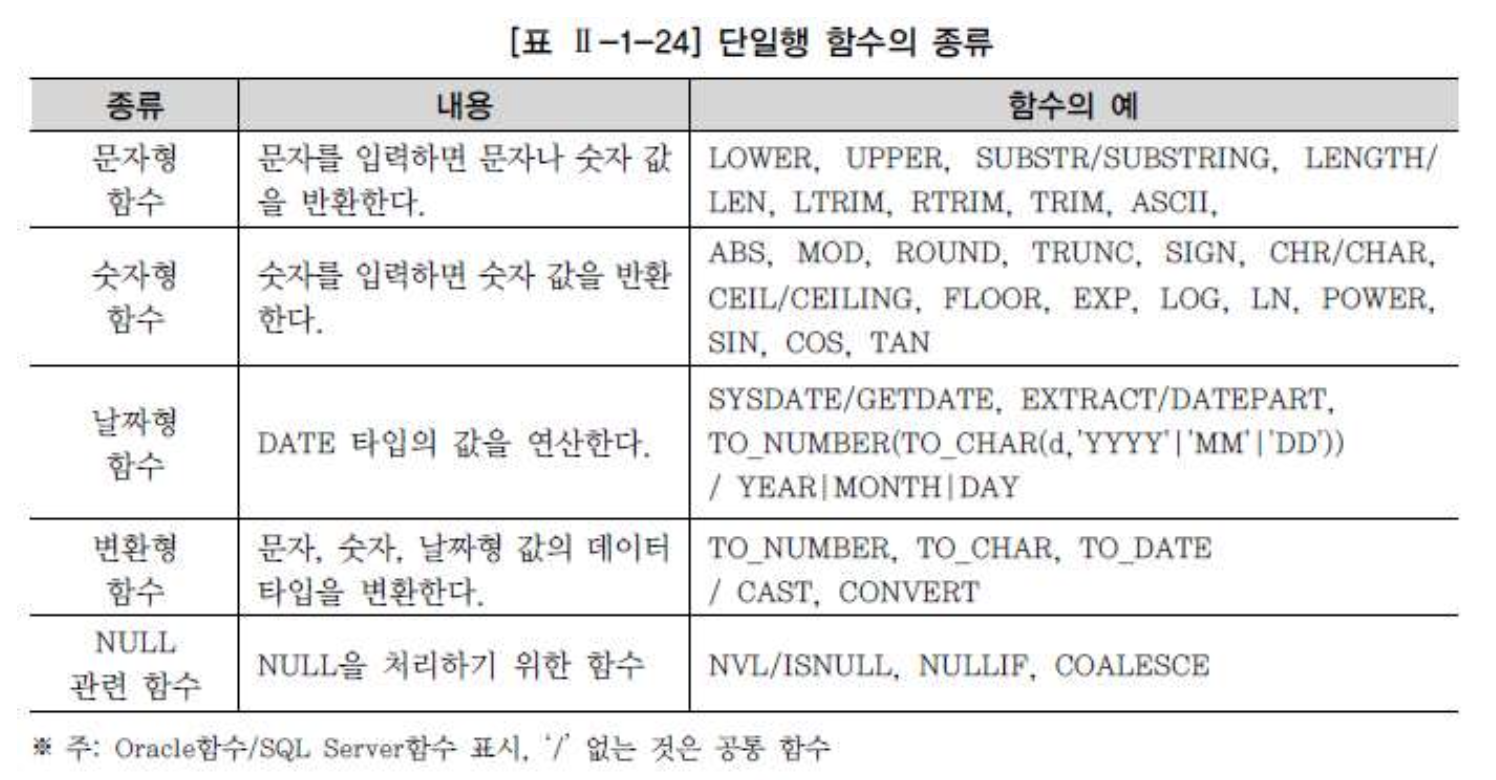
- 단일행 함수의 중요한 특징은 아래와 같다
- SELECT, WHERE, ORDER BY 절에 사용 가능하다
- 각 행(Row)들에 대해 개별적으로 작용하여 데이터 값들을 조작하고, 각각의 행에 대한 조작 결과를 리턴한다.
- 여러 인자(Argument)를 입력해도 단 하나의 결과만 리턴한다.
- 함수의 인자(Arguments)로 상수, 변수, 표현식이 사용 가능하고, 하나의 인수를 가지는 경우도 있지만 여러 개의 인수를 가질 수도 있다.
- 특별한 경우가 아니면 함수의 인자(Arguments)로 함수는 사용하는 함수의 중첩이 가능하다.
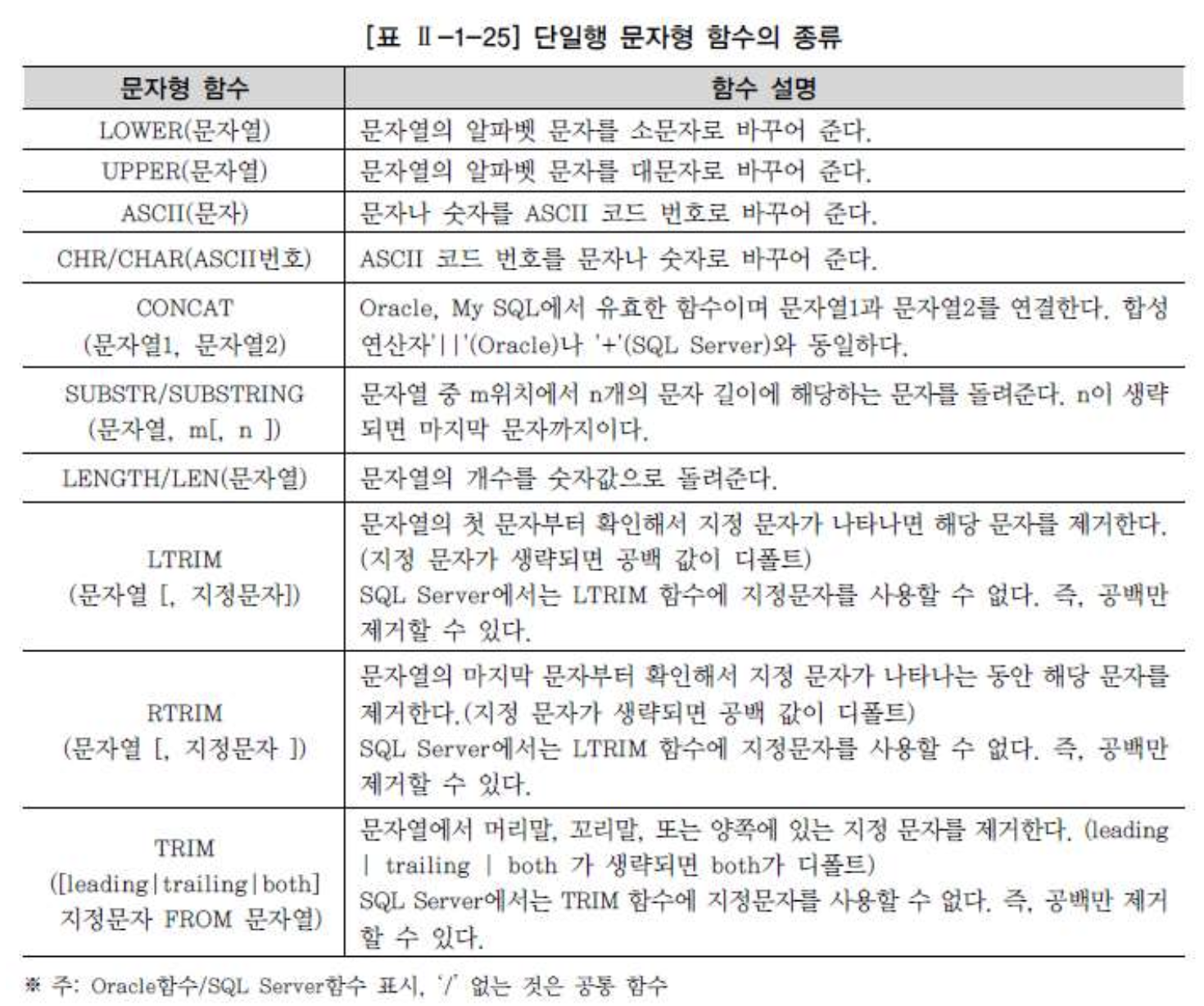
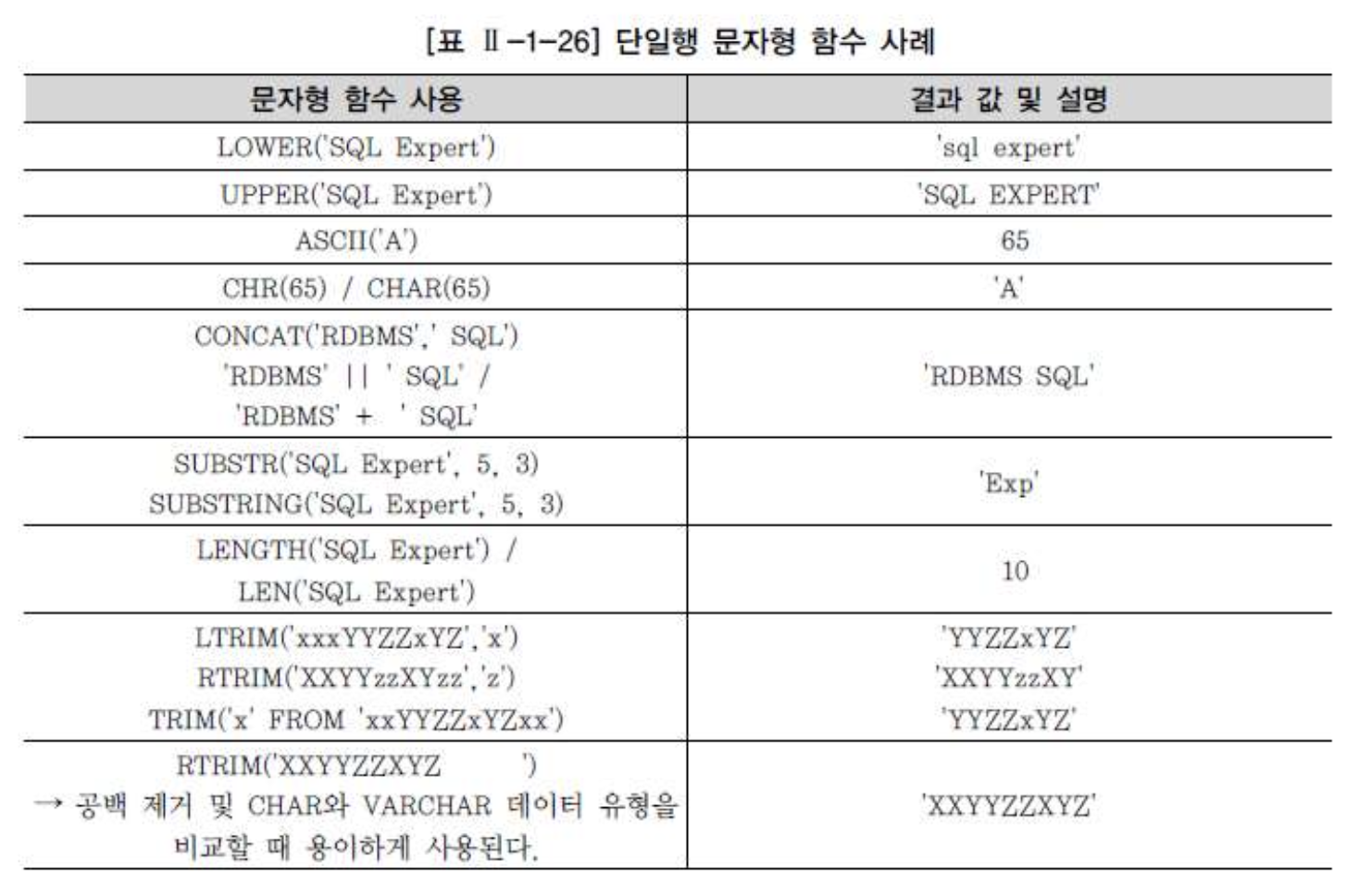
문자형 함수
- 문자형 함수는 문자 데이터를 매개 변수로 받아들여서 문자나 숫자 값의 결과를 돌려주는 함수
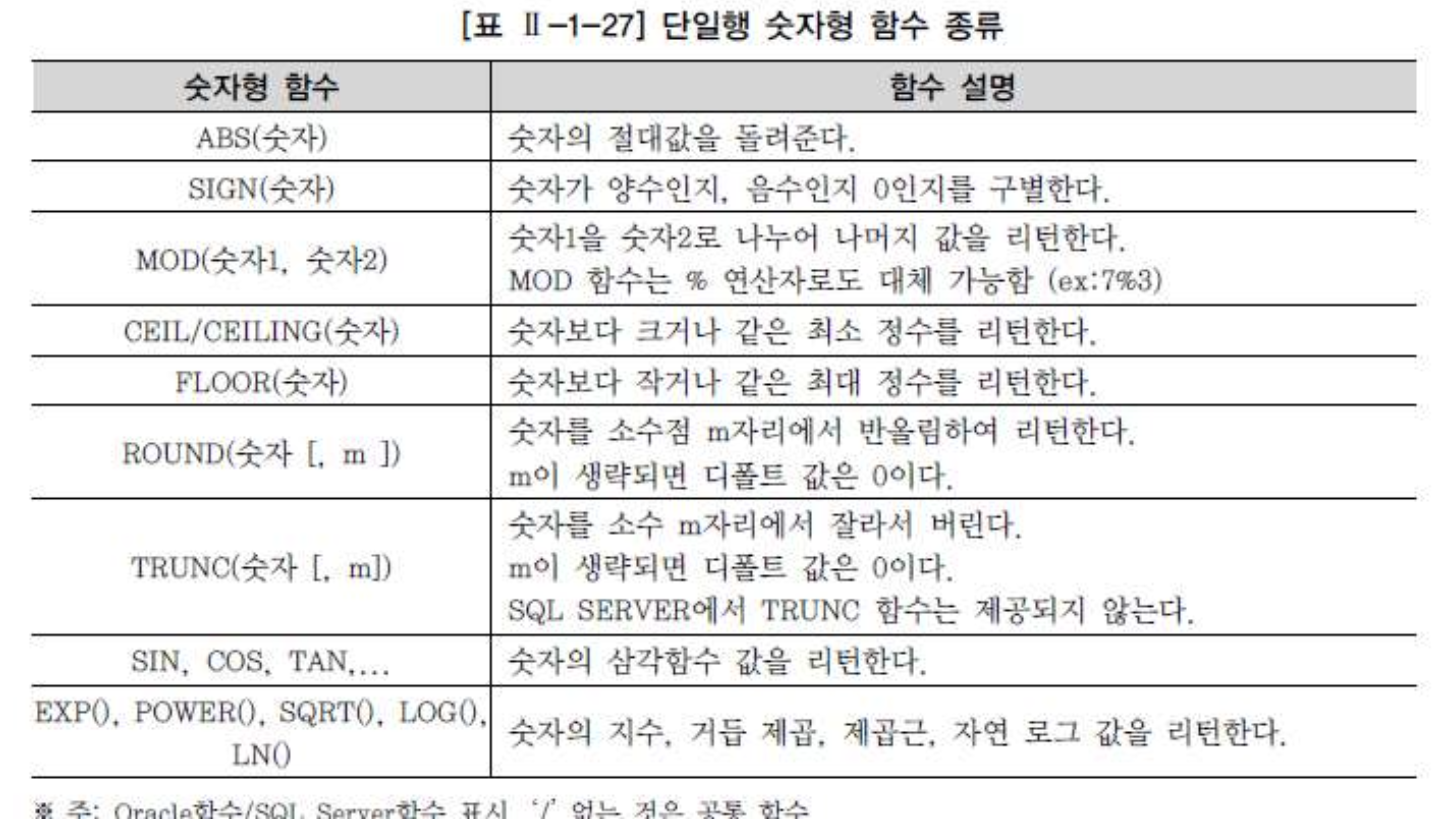
숫자형 함수
- 숫자형 함수는 숫자 데이터를 입력받아 처리하고 숫자를 리턴하는 함수
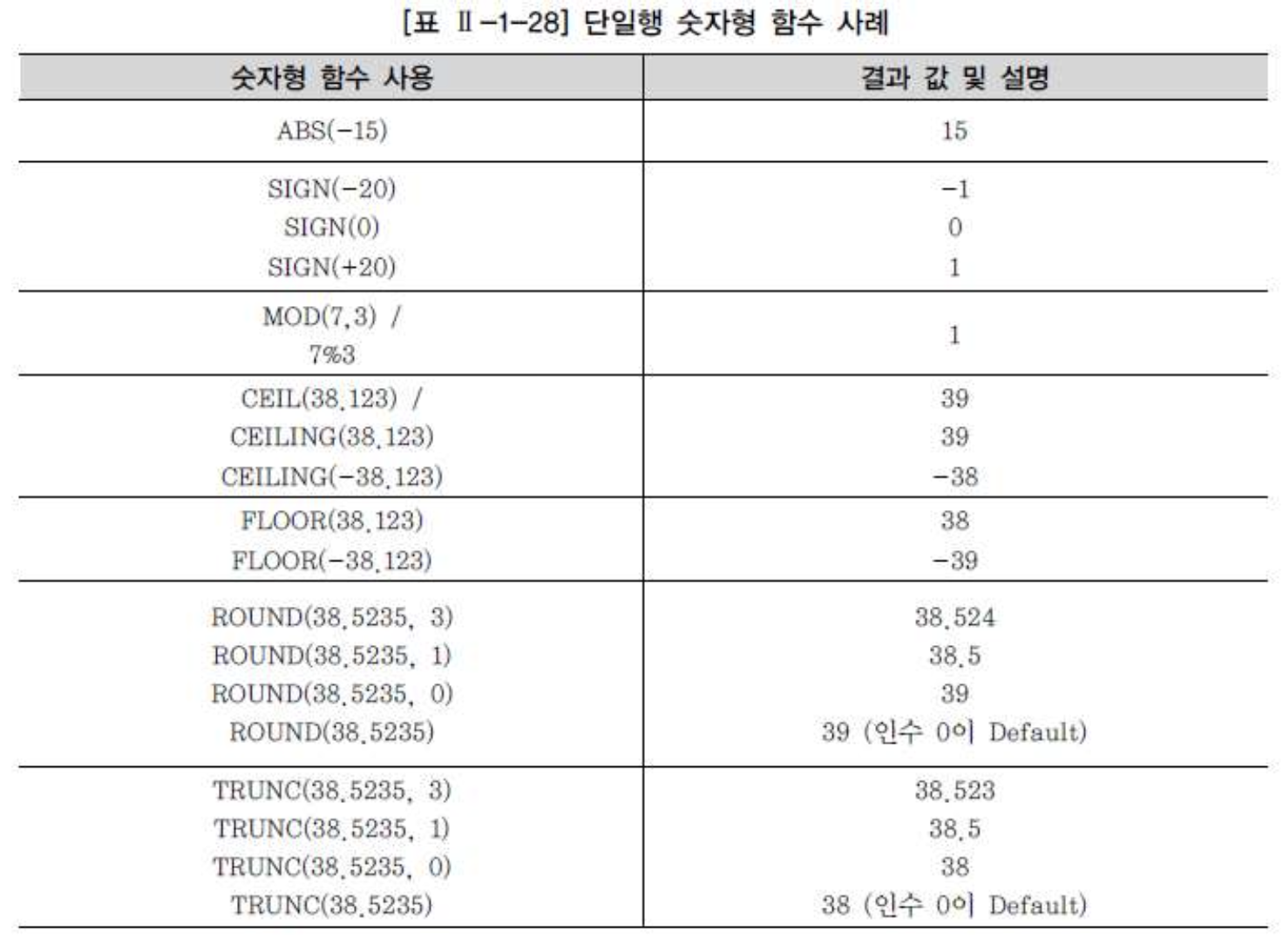
날짜형 함수
- 날짜형 함수는 DATE 타입의 값을 연산하는 함수
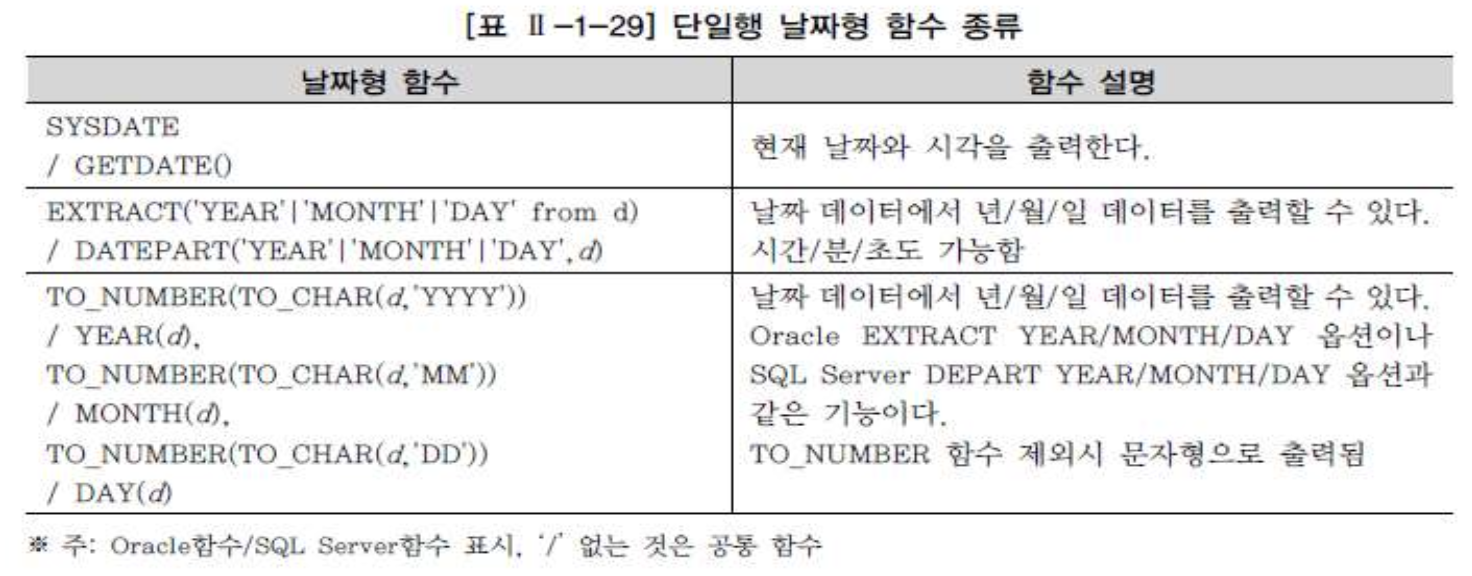

변환형 함수
-
변환형 함수는 특정 데이터 타입을 다양한 형식으로 출력하고 싶을 경우에 사용되는 함수
- 명시적(Explicit) 데이터 유형 변환: 데이터 변환형 함수로 데이터 유형을 변환하도록 명시해 주는 경우
- 암시적(Implicit) 데이터 유형 변환: 데이터베이스가 자동으로 데이터 유형을 변환하여 계산하는 경우
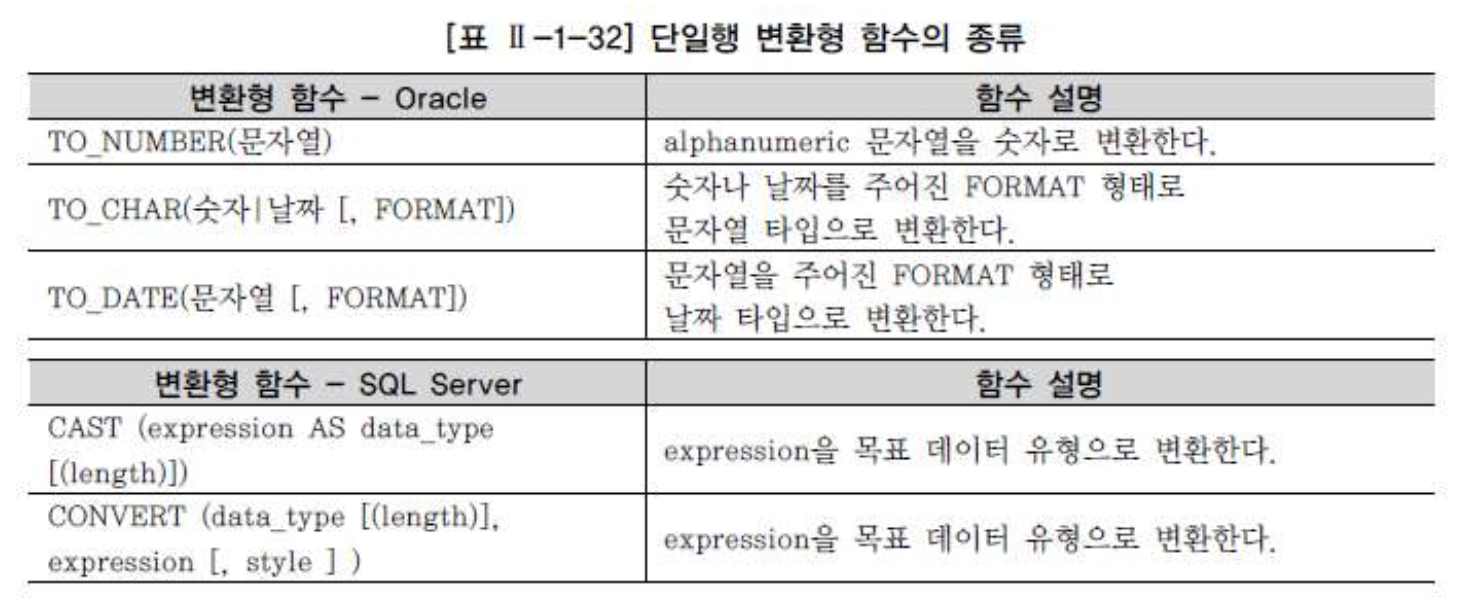
CASE 표현
- CASE 표현은 IF-THEN-ELSE 논리와 유사한 방식으로 표현식을 작성해서 SQL의 비교 연산 기능을 보완하는 역할을 한다.
NULL 관련 함수
-
NULL에 대한 특성
- 널 값은 아직 정의되지 않은 값으로 0 또는 공백과 다르다.
0은 숫자이고, 공백은 하나의 문자이다. - 테이블을 생성할 때 NOT NULL 또는 PRIMARY KEY로 정의되지 않은 모든 데이터 유형은 널 값을 포함할 수 있다.
- 널 값을 포함하는 연산의 경우 결과 값도 널 값이다.
모르는 데이터에 숫자를 더하거나 빼도 결과는 마찬가지로 모르는 데이터인 것과 같다. - 결과값을 NULL이 아닌 다른 값을 얻고자 할 때 NVL/ISNULL 함수를 사용한다.
- 널 값은 아직 정의되지 않은 값으로 0 또는 공백과 다르다.
-
NVL/ISNULL 함수를 유용하게 사용하는 예는 산술적인 계산에서 데이터 값이 NULL일 경우이다. 칼럼 간 계산을 수행하는 경우 NULL 값이 존재하면 해당 연산 결과가 NULL 값이 되므로 원하는 결과를 얻을 수 없는 경우가 발생한다. 이런 경우는 NVL 함수를 사용하여 숫자인 0으로 변환을 시킨 후 계산을 해서 원하는 데이터를 얻는다.

[7. GROUP BY, HAVING 절]
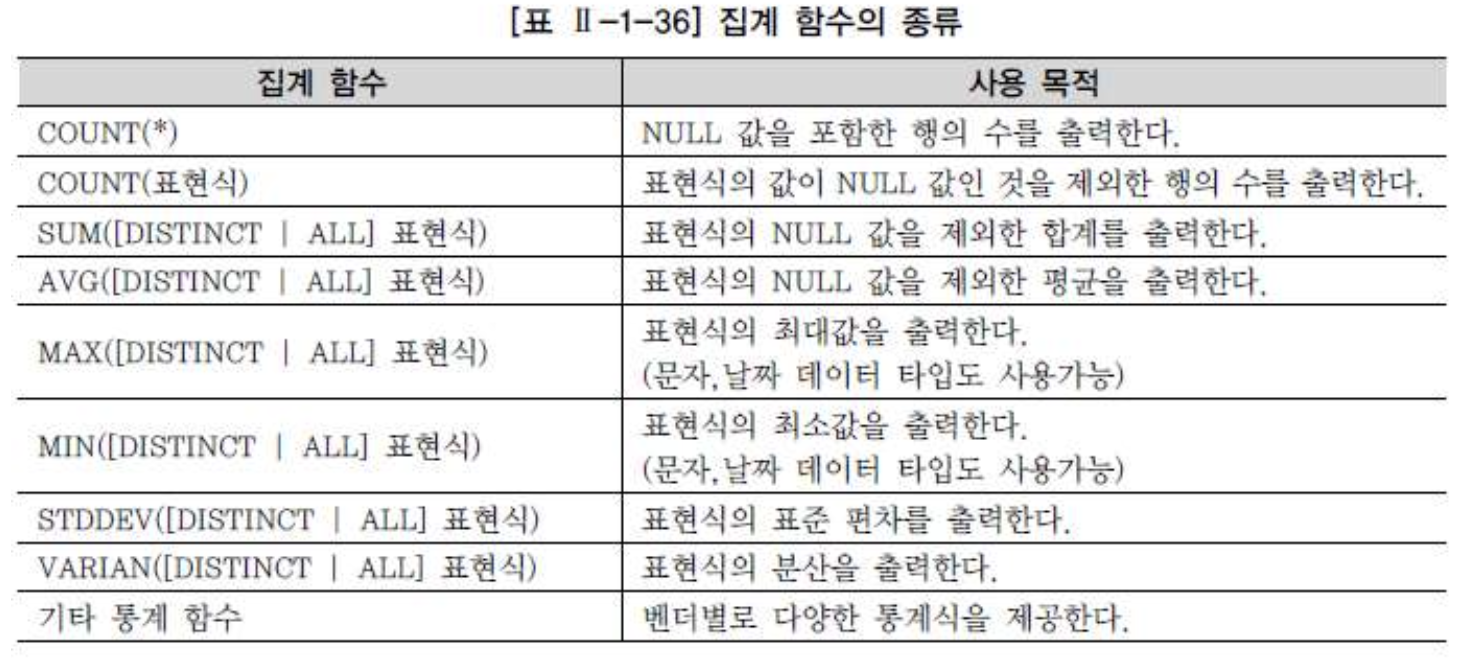
집계 함수 (Aggregate Function)
-
여러 행들의 그룹이 모여서 그룹당 단 하나의 결과를 돌려주는 다중행 함수 중 집계 함수의 특성은 아래와 같다.
- 여러 행들의 그룹이 모여서 그룹당 단 하나의 결과를 돌려주는 함수이다.
- GROUP BY 절은 행들을 소그룹화 한다.
- SELECT 절, HAVING 절, ORDER BY 절에 사용할 수 있다.
GROUP BY 절, HAVING 절
- GROUP BY 절은 SQL 문에서 FROM 절과 WHERE 절 뒤에 오며, 데이터들을 작은 그룹으로 분류하여 소그룹에 대한 항목별로 통계 정보를 얻을 때 추가로 사용된다.
SELECT [DISTINCT] 칼럼명 [ALIAS명]
FROM 테이블명
[WHERE 조건식]
[GROUP BY 칼럼(Column)이나 표현식]
[HAVING 그룹조건식] ;- GROUP BY 절과 HAVING 절은 다음과 같은 특성을 가진다.
- GROUP BY 절을 통해 소그룹별 기준을 정한 후, SELECT 절에 집계 함수를 사용한다.
- 집계 함수의 통계 정보는 NULL 값을 가진 행을 제외하고 수행한다.
- GROUP BY 절에서는 SELECT 절과는 달리 ALIAS 명을 사용할 수 없다.
- 집계 함수는 WHERE 절에는 올 수 없다.
(집계 함수를 사용할 수 있는 GROUP BY 절보다 WHERE 절이 먼저 수행된다) - WHERE 절은 전체 데이터를 GROUP으로 나누기 전에 행들을 미리 제거시킨다.
- HAVING 절은 GROUP BY 절의 기준 항목이나 소그룹의 집계 함수를 이용한 조건을 표시할 수 있다.
- GROUP BY 절에 의한 소그룹별로 만들어진 집계 데이터 중, HAVING 절에서 제한 조건을 두어 조건을 만족하는 내용만 출력한다.
- HAVING 절은 일반적으로 GROUP BY 절 뒤에 위치한다.
CASE 표현을 활용한 월별 데이터 집계
- "집계 함수(CASE( )) ~ GROUP BY" 기능은, 모델링의 제1정규화로 인해 반복되는 칼럼의 경우 구분 칼럼을 두고 여러 개의 레코드로 만들어진 집합을, 정해진 칼럼 수만큼 확장해서 집계 보고서를 만드는 유용한 기법이다.
[8. ORDER BY 절]
ORDER BY 정렬
- ORDER BY 절은 SQL 문장으로 조회된 데이터들을 다양한 목적에 맞게 특정 칼럼을 기준으로 정렬하여 출력하는데 사용한다.
- ORDER BY 절에 칼럼명 대신에 SELECT 절에서 사용한 ALIAS 명이나 칼럼 순서를 나타내는 정수도 사용 가능하다.
- 별도로 정렬 방식을 지정하지 않으면 기본적으로 오름차순이 적용되며, SQL 문장의 제일 마지막에 위치한다.
SELECT 칼럼명 [ALIAS명]
FROM 테이블명
[WHERE 조건식]
[GROUP BY 칼럼(Column)이나 표현식]
[HAVING 그룹조건식]
[ORDER BY 칼럼(Column)이나 표현식 [ASC 또는 DESC]] ;
ASC(Ascending) : 조회한 데이터를 오름차순으로 정렬한다.(기본 값이므로 생략 가능)
DESC(Descending) : 조회한 데이터를 내림차순으로 정렬한다.SELECT 문장 실행 순서
- GROUP BY 절과 ORDER BY가 같이 사용될 때 SELECT 문장은 6개의 절로 구성이 되고, SELECT 문장의 수행 단계는 아래와 같다.
- SELECT 칼럼명
- FROM 테이블명
- WHERE 조건식
- GROUP BY 칼럼이나 표현식
- HAVING 그룹조건식
- ORDER BY 칼럼이나 표현식;
- 발췌 대상 테이블을 참조한다. (FROM)
- 발췌 대상 데이터가 아닌 것은 제거한다. (WHERE)
- 행들을 소그룹화 한다. (GROUP BY)
- 그룹핑된 값의 조건에 맞는 것만을 출력한다. (HAVING)
- 데이터 값을 출력/계산한다. (SELECT)
- 데이터를 정렬한다. (ORDER BY)
[9. 조인 (JOIN)]
JOIN 개요
- JOIN : 두 개 이상의 테이블들을 연결 또는 결합하여 데이터를 출력하는 것
일반적으로 행들은 PK나 FK 값의 연관에 의해 JOIN이 성립된다. 어떤 경우에는 PK, FK 관계가 없어도 논리적인 값들의 연관만으로 JOIN이 성립가능하다.
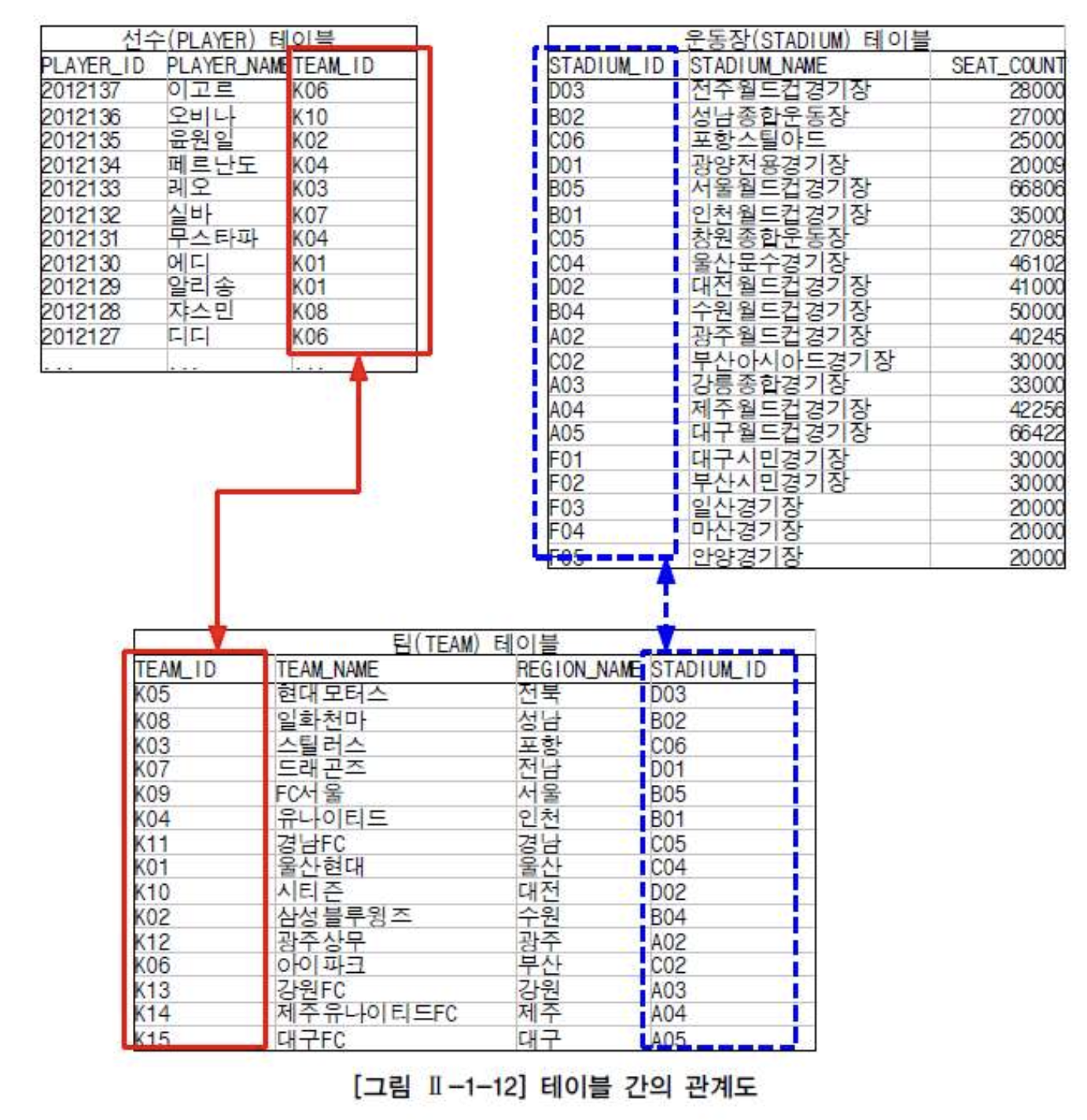
EQUI JOIN
- EQUI JOIN은 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하는 경우에 사용되는 방법으로 대부분 PK - FK의 관계를 기반으로 한다. (반드시는 아님)

- JOIN 조건에 맞는 데이터만 출력하는 INNVER JOIN에 참여하는 대상 테이블이 N개라고 했을 때, N개의 테이블로부터 필요한 데이터를 조회하기 위해 필요한 JOIN 조건은 대상 테이블의 개수에서 하나를 뺀 N-1개 이상이 필요하다.
Non EQUI JOIN
- Non EQUI JOIN은 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하지 않는 경우에 사용된다. Non EQUI JOIN의 경우에는 "=" 연산자가 아닌 다른(Between, >, >=, <, <=) 연산자들을 사용하여 JOIN을 수행하는 것이다.

💼 Software Engineer @ LG Electronics | 🎓 SungKyunKwan Univ. CSE