데이터 전처리
-
데이터 레이크: 목적을 가지고 있지 않은 모든 데이터가 자유롭게 저장된 저장소
데이터 웨어하우스: 형식을 갖고 데이터가 저장됨
데이터 마트: 여러 곳에 흩어진 데이터를 수집한 뒤 기업의 의사결정을 위해 공통의 형식으로 변환된 데이터의 집합으로써 특정 목적을 달성하기 위해 추출된 작은 데이터 집합 -
데이터프레임을 하나 이상의 특정 변수를 기준으로 나누는 함수와 나누어진 데이터를 원하는 구성으로 재결합하는 함수를 제공하며, 유연한 데이터 재구성 및 통계 처리가 가능하도록 도와주는 패키지. 대표적인 함수로는 melt와 cast가 있다 -> reshape
-
데이터 분석 전 이해.. 데이터 기초통계량 값 확인 및 다양한 관점에서 데이터를 바라보기 위해 시각화 등을 수행하는 작업 -> 탐색적 데이터 분석(EDA)
-
결측값도 의미를 띌 수 있다. / 결측값 처리를 위한 다중 대치법은 대치, 분석, 결합의 단계로 구성 / Amelia 패키지의 missmap 함수를 통해 결측값을 시각화할 수 있음
-
단순 대치법: 완벽하지 못한 False값에 대해 결측값 제거를 수행 / 조건부 평균 대치법: 회귀분석을 통해 결측값을 대치 / 단순 확률 대치법: 평균 대치법의 표준 오차에 대한 과소 추정을 보완하기 위해 고려된 방법 / 다중 대치법: n번의 대치를 통해 가상의 자료속에서 결측값을 대치하는 방법
-
데이터 입력 시점에 사람의 실수로 인해 발생할 수 있는 값도 이상값의 한 종류 / ESD는 이상값을 판단하는 기준으로 평균으로부터 표준편차의 3배를 넘어서는 데이터를 이상값으로 판단 / 사분위수를 이용한 이상값 판단 기준으로는 IQR(Q3-Q1)의 1.5배를 사용
-
평균으로부터 표준편차의 3배 이상 떨어져 있는 값을 이상치로 판단할 수 있다 / 군집분석을 이용해 다른 데이터들과 거리상 멀리 떨어진 데이터를 이상치로 판단할 수 있다 / Q1 - 1.5*IQR < data < Q3 + 1.5*IQR 벗어나는 경우 이상치로 판단 / 회귀분석에서는 동일수준의 설명변수에 대해 종속변수의 상이한 값을 이상치로 판단
-
파생변수는 사용자가 특정 조건을 만족하거나 특정 함수에 의해 값을 만들어 의미를 부여한 변수. 파생변수는 매우 주관적인 변수일 수 있으므로 논리적 타당성을 갖춰야함. / 많은 모델에서 공통적으로 사용x, 재활용성 낮음, 다양한 모델을 개발해야 하는 경우 비효율적
-
관측치가 기록된 값을 결측치로 처리하여 분석하는 것은 옳지 않다. default 값이 기록된 경우라도 의미가 있기 때문에 결측치로 처리하면 분석에 큰 오류로 작용할 수 있다.
-
complete analysis는 불완전 자료를 모두 삭제하고 완전한 관측치만으로 자료를 분석하는 방법. 그러나 부분적 관측자료를 사용하므로 통계적 추론의 타당성 문제가 있음 / 평균 대치법은 자료의 평균값으로 결측값을 대치 / 단순확률대치법은 평균대치법에서 추정량 표준오차의 과소 추정 문제를 보완하고자 고안된 방법 / 다중대치법은 추정량의 표준오차의 과소추정 또는 계산의 난해성 문제가 보완된 방법
-
평균으로부터 3*표준편차 벗어나는 것들을 비정상이라고 규정하고 제거한다 -> 틀림! (이상치는 분석에서 제외할 수 있지만 무조건적으로 제거할 수 는 없다) / 이상치는 변수의 분포에서 벗어난 값으로 상자 그림을 통해 확인할 수 있다
-
이상값 검색을 활용한 응용시스템 -> ex) 부정사용방지 시스템
-
군집분석을 이용하여 다른 데이터들과 거리상 멀리 떨어진 데이터를 이상치로 판정한다 / 데이터를 측정과정이나 입력하는 과정에서 잘못 포함된 이상치는 삭제 후 분석 한다 -> 틀림! 이상치는 분석에 의미가 있을 수 있으므로 제거하면 안된다 / 설명변수의 관측치에 비해 종속변수의 값이 상이한 값을 이상치라 한다 / 통상 평균으로부터 표준편차의 3배가 되는 점을 기준으로 이상치를 정의한다
-
이상값의 처리에 있어서 극단값 절단 방법과 조정 방법이 있으며, 조정의 경우 제거에 비해 데이터 손실율이 낮아지기 때문에 설명력이 높아지는 장점이 있다
-
R에서 multi-core를 사용하여 반복문을 사용하지 않고 간단하고 빠르게 처리할 수 있는 데이터 처리 함수를 포함하는 패키지 -> plyr
-
데이터 전처리 단계에서 데이터의 이상치에 대한 설명으로 틀린 것은? -> 최대값과 최소값. / 데이터 입력 시 오타, 분석 목적에 부합되지 않아 제거해야하는 경우, 부정사용방지 시스템에서 의도된 이상 값은 이상치 맞음
-
평균으로부터 t stadard deviation (표준편차) 이상 떨어진 값을 이상값으로 판단하고 t는 3으로 설정하는 이상값 검색 알고리즘은? ESD
통계분석 (개요)
-
두 개의 사건에 대해 두 사건이 서로 공통 부분이 존재하지 않는 경우를 "배반"관계라 하며, 두 개의 사건이 공통인 부분이 존재한다 하더라도 서로가 서로에게 영향을 주지 않는 경우를 "독립" 관계에 있다고 한다.
-
모집단의 구성비율을 반영한 표본집단을 생성하기 위해 모집단을 여러 개의 이질적인 집단으로 나눈 뒤 모집단의 비율과 같은 비율로 각 군집으로부터 표본을 추출하는 방법 -> 비례 층화 추출법
-
명목 척도: 어느 집단에 속하는 지 / 순서 척도: 서열 관계가 있을 때 / 구간 척도: 속성의 양을 측정하는 것으로 구간이나 구간 사이의 간격이 의미가 있는 자료. 절대적 원점은 없다. / 비율 척도: 절대적 기준인 0이 존재하고 사칙연산이 가능 // 구간 척도는 절대적 기준 0이 존재하지 않음. 비율 척도가 절대적 기준 0이 존재
-
상관계수는 두 변수에 대해 서로의 선형관계를 나타내는 척도 / 공분산은 최대, 최소값이 존재하지 않음 / 상관계수 값 0은 두 변수의 선형관계가 존재하지 않음을 의미 / 공분산은 두 개의 변수에 대한 선형 관계를 나타내는 측도임
-
왜도 < 0 -> 평균<중앙값<최빈값 / 왜도 = 0 -> 평균=중앙값=최빈값 / 왜도 > 0 -> 최빈값<중앙값<평균
-
기댓값: "X P(X)"의 합계
분산: "X제곱 P(X)"의 합계 -
이산형 확률변수: 베르누이, 이항, 기하, 다항, 포아송
연속형 확률변수: 균일분포, 정규분포, 지수분포, t-분포(평균이 동일한지 알고자할 때 사용), 카이제곱 분포(모분산에 대한 가설 검정에 사용), F-분포(분산의 동일성 검정에 사용) -
발생할 수 있는 사건이 0과 1인 두 개의 확률분포로 n번 시행할 때 처음으로 성공인 시행이 나올 때까지 n번 시행할 확률을 나타내는 분포 -> 기하분포 (처음으로 라는 단어가 나온다면 기하분포가 정답)
-
"추정과 가설검정"에 대한 설명
-> 모든 데이터를 조사하는 전수조사는 불가능하여 표본조사로부터 모집단을 파악하는 것이 목적
-> 점 추정이란 모집단이 어느 특정한 값일 것이라 여기는 값을 예측하는 것
-> 귀무가설이란 대립가설에 반하는 가설로 흔히 모집단이 어떤 값일 것이라 특정하는 가설
-> 더 위험하다 생각되는 1종 오류를 조정 -
모집단에서 표본을 추출하는 방법 -> 단순랜덤 추출법, 계통추출법(번호를 랜덤하게 부여한 후 특정한 간격별로 추출), 집락추출법(군집을 나눈 후 군집별로 단순랜덤 추출), 층화추출법(계층을 고루 대표할 수 있도록 표본 추출)
-
데이터의 한 부분으로 특정 사용자가 관심을 갖고 있는 데이터를 담은 비교적 작은 규모의 데이터웨어하우스 -> 데이터마트
-
확률이란 특정사건이 일어날 가능성의 척도 / 통게적 실험을 실시할 때 나타날 수 있는 모든 결과들의 집합을 표본 공간/ 사건이란 표본 공간의 부분 집합 / 서로 배반인 사건들의 합집합의 확률 = 각 사건들의 확률의 합 / 두 가선 A, B가 독립이면, 사건 B의 확률 = A가 일어난다는 가정하에서의 B의 조건부확률 / 확률변수 X가 구간 또는 구간들의 모임인 숫자 값을 갖는 확률분포함수를 연속형 밀도함수라 한다
-
데이터의 정규성을 확인하기 위한 방법 -> 히스토그램, Q-Q Plot, Shapiro Wilk test / Durbin Watson test는 회귀모형 오차항의 자기 상관이 있는 지에 대한 검점
-
이산형 확률분포 중 주어진 시간 또는 영역에서 어떤 사건의 발생 횟수를 나타내는 확률 분포 -> 포아송 분포
-
성공 확률 0.3인 경우 -> 기댓값도 0.3
-
상당히 이질적인 원소들로 구성된 모집단에서 각 계층을 고루 대표할 수 있도록 표본을 추출하는 방법. 이질적인 모집단의 원소들로 서로 유사한 것끼리 몇 개의 층을 나눈 후 각 게층에서 포본을 랜덤하게 추출 -> 층화추출법
-
만족도 5점 척도 조사 -> 순서 척도 (서열 관계가 있을 때)
-
확률변수 X와 Y의 공분산?
공분산은 최대 최소가 없다
X, Y 방향의 선형성
cov(X, Y) = E[(X-u)*(Y-u)]
X, Y가 독립이면 cov(X, Y) = 0 -
두 종류의 수면 유도제를 복용 전과 후의 평균 체중 비교에 사용할 수 있는 분석 -> 쌍체 t검정
통계분석 (회귀분석)
회귀분석이란 하나 또는 그 이상의 독립변수들이 종속변수에 미치는 영향을 추정하는 통계법 (함수의 개념과 비슷) (Regression)
-
선형회귀분석의 가정: 선형성(입력변수와 출력변수의 관계가 선형), 등분산성(오차의 분산이 입력변수와 무관하게 일정), 독립성(입력변수와 오차는 관련 없다), 비상관성(오차들끼리 상관이 없다), 정상성(오차의 분포가 정규분포를 따른다/ Q-Q plot, 히스토그램, Shapiro-Wilks test로 확인)
-
회귀분석에서 각 독립변수에 대한 회귀계수를 추정하기 위한 방법으로 잔차의 제곱합이 최소가 되는 회귀식을 찾는 방법 -> 최소제곱법
-
결정계수 -> 회귀제곱합/전체
-
여러 개의 독립변수 후보들 중 가장 최적인 회귀방정식을 찾는 방법으로 상수항만 있는 모형에서 출발하여 벌점에 따라 변수를 추가하는 반복 작업을 통해 최적 회귀방정식을 찾아내는 방법 -> 전진 선택법
전진선택법: 절편만 있는 상수모형으로부터 시작해 중요하다 생각되는 변수를 차례로 추가
후진제거법: 모든 변수를 포함한 모형에서 출발해 가작 적은 영향을 주는 변수부터 하나씩 제거
단계선택법: 전진선택법으로 변수를 추가하는데 기존 변수가 영향을 받아 중요도가 약화되면 변수를 다시 제거하는 등 단계별로 추가, 제거 여부를 검토하는 방법
최적회귀방정식: 모든 후보 모형들에 대해 AIC, BIC를 계산하고 그 값이 최소가 되는 모형 선택 -
최적 회귀방정식을 추정하는 데 있어, 벌점의 지표 중 하나에 대한 설명.. -> 자료의 수가 많아질수록 부정확해지는 문제를 해결하기 위해 도입된 변수 선택 지표. 또한 다른 벌점들보다 높은 패널티를 갖기 때문에 변수의 개수가 적은 경우에 활용이 권장됨. -> BIC
-
로지스틱회귀분석은 독립변수의 선형 결합을 이용해 사건의 발생 가능성을 예측하는 데 사용되는 통계기법. 이 중 로지스틱 회귀모형의 검정방법은? -> 카이제곱 검정
-
회귀분석에서 다중공선성은 모형의 일부 설명변수가 다른 설명변수와 상관되어 있을 때 발생하는 현상. (안조은거 가틈)
-> 다중공선성은 회귀계수의 분산을 증가시켜 불안정하고 해석하기 어렵게 만듬
-> 모형의 일부 예측 변수가 다른 예측 변수와 상관되어 있을 때 발생하는 문제
-> 높은 상관관계에 있는 설명변수에 대한 계수는 표본의 크기에 따라 달라질 수 있으므로 높은 상관관계가 있는 설명변수는 변환을 한 다음 모형에서 사용해야 함
-> R에서 다중공선성을 확인하는 함수로 vif가 있으며, 보통 vif값이 10이상이면 다중공선성을 의심함 -
추정된 다중회귀모형이 통계적으로 유의미한지 확인하는 방법 -> F통계량
-
회귀분석에서 가장 적합한 회귀모형을 찾기 위한 과정의 설명
-> 독립변수의 수가 많아지면 모델의 설명력이 증가 but 모형이 복잡해지고 독립변수들 간에 서로 영향을 미치는 다중공선성의 문제가 발생하므로 상대적인 조정이 필요
-> 회귀식에 대한 검정은 독립변수의 기울기가 0이라는 가정을 귀무가설, 기울기가 0이 아니라는 가정을 대립가설로 놓음
-> 잔차의 독립성, 등분산성, 정규성을 만족하는 지 확인 해야함
-> 회귀분석의 가설검정에서 p값이 0.05보다 작은 값이 나와야 통계적으로 유의미한 결과로 받아들일 수 있음 -
회귀분석에서 결정계수(R2)에 대한 설명
-> 결정계수는 총 변동 중에서 회귀모형에 의해 설명되는 변동이 차지하는 비율
-> 회귀모형에서 입력변수 증가 -> 결정계수 증가
-> 다중 회귀분석에서는 최적 모형의 선정 기준으로 결졍계수 값보단 수정된 결정계수 값을 사용하는 것이 적절
-> 수정된 결정계수는 유의하지 않은 독립변수들이 회귀식에 포함되었을 때 그 값이 감소함 -
최적회귀방정식을 선택하기 위한 방법
-> 가능한 범위 내에서 적은 수의 설명변수를 포함 -
AIC나 BIC의 값이 가장 작은 모형을 선택하는 방법으로 모든 가능한 조합의 회귀분석을 실시
-> 전진선택법은 설명변수를 추가했을 때 제곱합의 기준으로 가장 설며을 잘하는 변수를 고려하여 그 변수가 유의하면 추가 -
단계적 방법은 기존의 모형에서 예측 변수를 추가, 제거를 반복하여 최적의 모형을 찾는 방법이므로 전진선택법과 후진선택법과 동일한 최적의 모형을 가지는 것은 아니다.
통계분석 (기타분석)
-
양적척도에 대한 상관분석을 수행하기 위해서는 피어슨 상관계수를 사용해야 한다 / 상관분석의 귀무가설은 '두 변수 간 상관관계는 존재하지 않는다' 이다 / 상관분석을 통해 두 변수의 선형관계 여부를 파악할 수 있다 / 서열척도에 대해 상관게수를 구할 때 동일 석차가 존재해도 분석을 수행할 수 있다
-
다차원 척도법
-> 데이터를 저차원 공간에 배열하는 시각화 기법 중 하나
-> STRESS 값이 0인 경우 적합이 매우 잘 된 것
-> 데이터의 변수는 연속형 변수 또는 서열척도여야 한다
-> 좌표 평면에 나타냈을 때, x축 y축이 데이터 해석에 도움을 주지 않는다 (아마 그 거리? 뭐 이런거로 해석해야하는듯?) -
주성분 분석
-> 변수 요약 기법 중 하나로 기존 데이터의 선형결합으로 주성분을 생성
-> 기존 데이터의 분산이 가작 작은 축을 첫번째 주성분으로 하지 않음
-> 누적 기여율이 70~90%가 되도록 주성분의 개수를 선택
-> n개의 변수를 n개의 주성분으로 요약할 때 누적 기여율은 100% -
주성분 분석
-> scale. = T는 평균을 1로, center = T는 분산을 1로 조절하기 위함
-> 첫 번째 주성분은 분산이 가장 큰 새로운 축을 갖음 -
시계열 분석의 정상성
-> 모든 시점 t에 대해 일정한 평균을 갖는다
-> 모든 시점 t에 대해 일정한 분산을 갖는다
-> 평균이 일정하지 못한 경우 변환을 통해 정상 시계열로 만들 수 없다
-> 공분산은 특정 시점이 아닌 시차에 의존한다 -
시계열 분석을 수행하기 앞서 시계열 모형 선택은 중요한 과제 중 하나이다. 특정 시점에서의 시계열 자료의 값은 이전 시점 n개에 의해 결정 지을 수 있는 모델은? -> AR모형
-
시계열 자료를 설명하기 위한 분해 시계열 요소가 아닌 것은?
-> 회귀 요인
분해 시계열 요소는?
-> 순환 요인, 계절 요인, 불규칙 요인 -
한 변수를 단조 증가 함수로 변환하여 다른 변수를 나타낼 수 있는 정도를 나타내며 두 변수의 선형 관계의 크기 뿐만 아니라 비선형적인 관계도 나타낼 수 있는 상관계수는? -> 스피어만 상관계수
스피어만 상관계수는 서열 척도인 변수, 순서형 변수, 비모수적 방법, 비선형 관게'도' 측정 가능 -
시계열의 요소분해법은 시계열 자료가 몇 가지 변동들의 결합으로 이루어져 있다고 보고 변동요소별로 분해하여 쉽게 분석하기 위한 것이다.
-> 추세변동은 장기적으로 변해가는 큰 흐름을 나타내는 것으로 자료가 장기적으로 커지거나 작아지는 변화를 나타내는 요소이다
-> 계절변동은 일정한 주기를 가지고 반복적으로 같은 패턴을 보이는 변화를 나타내는 요소이다
-> 순환변동은 계절변동과 혼동할 수 있지만, 계절변동으로 설명되지 않는 '장기적'인 변동, 계절과 관련 없는 변동으로 주기변동을 뜻한다
-> 불규칙변동은 불규칙하게 변동하는 급격한 환경변화, 천재지변 같은 것으로 발생하는 변동을 말한다. -
주성분분석은 p개의 변수들을 중요한 m(p)개의 주성분으로 표현하여 전체 변동을 설명하는 방법을 사용한다.
-> 전체 변이 공헌도 방법은 전체 변이의 70-90% 정도가 되도록 주성분의 수를 결정한다
-> 평균 교유값 방법은 고유값들의 평균을 구한 후 고유값이 평균값 이상이 되는 주성분을 유지하는 방법이다
-> Scree graph를 이용하는 방법은 고유값의 크기순으로 산점도를 그린 그래프에서 감소하는 추세가 원만해지는 지점에서 1을 뺀 개수를 주성분의 개수로 선택한다
-> 주성분은 주성분을 구성하는 변수들의 계수 구조를 파악하여 적절하게 해석되어야 하며, 명확하게 정의된 해석 방법이 있는 것은 아니다 -
시계열 분석을 위해서는 정상성을 만족해야 한다. 따라서 주어진 자료가 정상성을 만족하는 지 판단하는 과정이 필요하다. 자료가 추세를 보이는 경우에는 현 시점의 자료 값에서 전 시점의 자료를 빼는 방법을 통해 비정상시계열을 바꾸어 준다. 이 방법은 무엇인가? -> 차분
-
주성분분석에서 변수의 중요도 기준이 되는 값은?
-> 고유값 (고유벡터! 어떤 특징을 갖는 벡터) -
시계열 데이터의 분석 절차 순서는?
1) 시간 그래프 그리기
2) 추세와 계절성을 제거하기
3) 잔차를 예측하기
4) 잔차에 대한 모델 적합하기
5) 예측된 잔차에 추세와 계절성을 더하여 미래 예측하기 -
시계열 데이터에 대한 설명
-> 시계열 데이터의 모델링은 다른 분석모형과 같이 탐색 목적과 예측 목적으로 나눌 수 있다
-> 짧은 기간 동안의 주기적인 패턴을 계절변동이라 한다
-> 잡음은 무작위적 변동이고, 일반적으로 원인은 알려져 있지 않다
-> 시계열 분석의 주목적은 외부인자와 관련해 계절적인 패턴, 추세와 같은 요소를 설명할 수 있는 모델을 결정하는 것이다 -
다차원 척도법
-> 다차원 척도법은 여러 대상들 간의 관계를 개체들 사이의 유사성/비유사성을 상대적 거리로 측정하여 개체들을 2차원 또는 3차원 공간상에 점으로 표현하는 분석 방법이다.
-> 다차원 척도법의 목적은 데이터 속에 잠재한 패턴을 찾기 위해 복잡한 구조를 소수 차원의 공간에 기하학적으로 표현하는 것이다.
-> 계량적 다차원척도법은 비율척도, 구간척도 데이터를 활용하고, 비계량적 다차원척도법은 순서척도의 데이터를 활용한다.
-> 스트레스 값이 0.05이하이면 적합 정도가 아주 좋은 것으로 해석하고 반복 분석과정을 중단해도 된다.
정형데이터마이닝 (개요)
-
대용량 데이터 속에서 숨겨진 지식 또는 새로운 규칙을 추출해 내는 과정 -> 데이터마이닝
-
지도학습 -> 인공신경망, 의사결정나무, 회귀분석, 로지스틱회귀분석, 사례기반추론
비지도학습 -> OLAP, 연관성 규칙발견, 군집분석(k-means clustering가 예시 중 하나), SOM(self organizing map -> 차원축소와 군집화를 동시에 수행하는 기법.) -
군집분석 예 -> k-means clustering, single linkage method, DBSCAN
군집분석은 주성분분석과 다름! -
비지도학습 예시
-> 고객의 과거 거래 구매 패턴을 분석하여 고객이 구매하지 않은 상품을 추천
-> 상품을 구매할 때 그와 유사한 상품을 구매한 고객들의 구매 데이터를 분석하여 쿠폰을 발행 -
데이터 마이닝의 대표적인 기능 중 이질적인 모집단을 세분화하는 기능 -> 군집분석
-
데이터 마이닝 단계 중 모델링 목적에 따라 목적변수를 정리하고 필요한 데이터를 데이터마이닝 소프트웨어에 적용할 수 있도록 준비하는 단계는? -> 데이터 가정! 준비 아님
-
과대적합
-> 생성된 모델이 훈련 데이터에 너무 최적화되어 학습하여 테스트 데이터의 작은 변화에 민감하게 반응한다 (안좋게)
-> 학습데이터가 모집단의 특성을 충분히 설명하지 못할 때 자주 발생
-> 변수가 너무 많아 모형이 복잡할 때 생김
-> 과대적합이 발생할 것으로 예상되면 학습을 종료하고 업데이트를 하는 과정을 반복해 과대적합을 방지할 수 있다 -
로지스틱 회귀: 독립변수의 선형 결합을 이용해 사건의 발생 가능성을 예측하는 데 사용되는 통계 기법/ 0~1을 반환
-> 오즈란 이진 분류에서 실패할 확률 대비 성공할 확률을 의미 -> 오즈=p/(1-p). 성공할 확률이 실패할 확률의 몇 배인지를 나타냄
-> 로지스틱 회귀분석의 종속변수는 범주형이다
-> x의 회귀계수를 5라 가정하면, x값이 1 증가할 때 성공할 확률은 e^5만큼 증가한다
-> 성공 횟수가 10이고 실패횟수가 1이면 오즈값은 10 = (10/11)/(1/11) -
의사결정나무
-> 분류분석의 일종으로 여러 개의 분리 기준에 의해 최종 분류 값을 찾는 방법
-> 지니 지수, 엔트로피 지수 등을 분리 기준의 지표로 활용
-> 시각화했을 경우 누구나 쉽게 알아볼 수 있다는 장점이 있음
-> 종속변수가 범주형인 경우에는 지니지수를, 연속형인 경우 이진분리 사용 -
의사결정나무 수행에서, 너무 많은 분리기준을 보유한 의사결정나무는 일반화의 어려움이 있을 수 있는 과적합 문제가 발생할 수 있다. 이러한 문제를 해결하기 위해 특정 조건에 도달했을 경우 나무의 성자을 멈추도록 하는 규칙이 있다. 그것은 바로 '정지규칙'
-
지니지수 = 1 - 각 확률의 제곱 값의 합 = 1 - {(3/5)^2 + (2/5)^2} = 12/25
-
앙상블 분석
-> 배깅은 원본 데이터의 붓스트랩을 활용하여 여러 개의 모형을 만들고 보팅에 의해 최종 결과를 도출한다
-> 붓스트랩이란 기존 데이터와 같은 크기만큼 표본을 복원추출하여 만들어낸 새로운 데이터집단이다
-> 의사결정나무와 랜덤 포레스트는 이상값에 만감하지 않지만, 부스팅은 이상값에 민감하다
-> 앙상블 분석의 주 목적은 여러 개의 분류기를 제작하여 하나의 분류기에서 오는 낮은 신뢰서을 높이는 것이다
배깅: 여러개의 부스트랩 자료를 생성한 후 각 자료에 예측 모형을 만든 후 결합. 가지치기를 하지 않고 최대로 성장한 의사결정나무 활용
부스팅: 배깅과 다른 점은 각 자료에 동일한 가중치를 주는 것이 아닌 분류가 잘못된 데이터에 더 큰 가중을 준다.
랜덤포레스트: 배깅에 랜던 과정을 추가한 방법 -
앙상블 분석에서, 한번에 여러 개의 붓스트랩을 만들지 않고 다음 분류기를 제작하기 위한 붓스트랩을 구성할 때 이전 분류기에 의해 잘못 분류된 데이터에 더 큰 가중치를 주어 새로운 붓스트랩을 구성하여 최종모형을 만드는 방법 -> 부스팅
-
인공신경망
-> 다층신경망에서 은닉층의 수와 은닉노드의 수는 많을 수록 좋다는 아님!
-> 발생한 오차를 줄이기 위해 역전파 알고리즘을 사용하여 가중치를 수정한다
-> 역전파에 의한 가중치 수정 작업 중 가중치의 절대값이 커져 과소적합(overfitting의 반대. underfitting)이 발생하는 것을 포화문제(기울기 소실? -> 학습 능력 제한 -> 이를 신경망에 포화 상태가 발생했다 함)라 한다
-> 다수의 은닉층을 보유한 경우 시그모이드 함수를 사용하면 기울기 소실 문제가 발생할 수 있다. -
x축은 1-특이도 값을 나타내며, y축은 민감도의 값을 나타내어 모형의 이진분류에 대한 성과를 평가하기 위한 그래프이다. 그래프의 아래 면적값이 클수록 (1에 가까울 수록) 모형의 성능이 우수하다고 말할 수 있다
-> ROC 커브에 대한 설명임 -
성과 분석
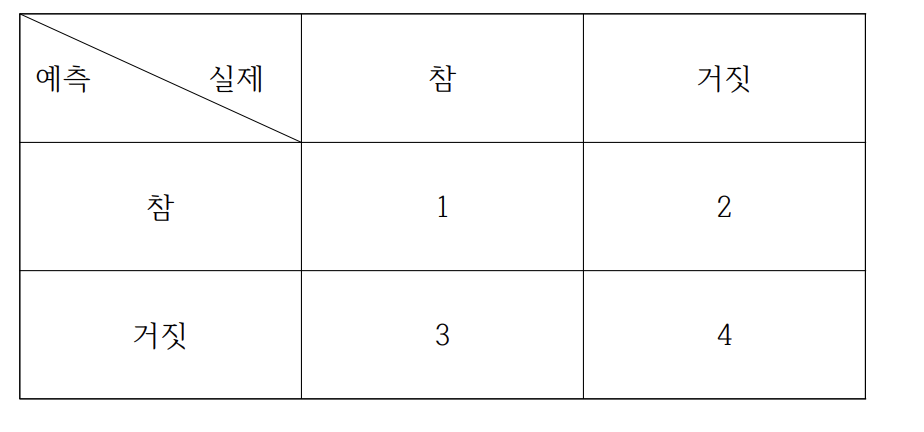
Accuracy = (1+4)/(1+2+3+4)
특이도(Specificity) = 4/(2+4)
정밀도(Precision) = 1/(1+2)
재현율(Recall) = 1/(1+3)
F1-score = 2*(precision*recall)/(precision+recall) -
의사결정 나무 모형의 학습 방법
-> 이익도표 또는 검정용 자료에 의한 교차 타당성 등을 이용해 의사결정나무를 평가한다
-> 분리 변수의 P차원 공간에 대한 현재 분할은 이전 분할에 영향을 받는다
-> 각 마디에서의 최적 분리규칙은 분리변수의 선택과 분리기준에 의해 결정된다
-> 가지치기는 분류오류를 크게할 위험이 높거나 부적절한 규칙을 가지고 있는 가지를 제거하는 작업이다 -
원 데이터 집합으로부터 크기가 같은 표본을 여러번 단순 임의 복원추출하여 각 표본에 대해 분류기를 생성한 후 그 결과를 앙상블하는 방법 -> 배깅
-
앙상블 모형은 여러 모형의 결과를 결합함으로써 단일 모형으로 분석했을 때보다 신뢰성 높은 예측값을 얻을 수 있다.
앙상블 모형의 특징
-> 이상값에 대한 대응력이 높아진다
-> 전체적인 예측값의 분산을 감소시켜 정확도를 높일 수 있다
-> 모형의 투명성이 떨어져 원인 분석에는 적합하지 않다
-> 각 모형의 상호 연관성이 높을 수록 정확도는 떨어진다 -
다수 모델의 예측을 관리하고 조합하는 기술을 메타학습이라 한다. 여러 분류기들의 예측을 조합함으로써 분류 정확성을 향상시키는 기법은? -> 앙상블 기법
-
의사결정나무와 같이 선형성, 정규성, 등분산성 등의 가정을 필요로 하지 않는 모형은? -> 비모수모형
-
의사결정 나무에서 더 이상 분기가 되지 않고 현재의 마디가 끝마디가 되도록 하는 규칙을 나타내는 용어는? -> 정지규칙
-
신경망 모형은 자신이 가진 데이터로부터 반복적인 학습과정을 거쳐 패턴을 찾아내고 이를 일반화하는 예측방법이다.
신경망 모형에 대한 설명
-> 피드포워드 신경망은 정보가 전방으로 전달되는 것으로 생물학적 신경계에서 나타나는 형태이며 딥러닝에서 가장 핵심적인 구조 개념이다
-> 은닉층의 뉴런수와와 개수는 신경망 모형에서 자동으로 설정되지 않고 직접 설정해야 한다
-> 일반적으로 인공신경망은 다층퍼셉트론을 의미한다. 다층 퍼셉트론에서 정보의 흐름은 입력층에서 시작하여 은닉층을 거쳐 출력층으로 진행된다
-> 역전파 알고리즘은 연결강도를 갱신하기 위해 예측된 결과와 실제값의 차이인 에러의 역전파를 통해 가중치를 구하는데서 시작되었다 -
SOM은 비지도 신경망으로 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬하여 지도 형태로 형성화하는 방법이다.
정형데이터마이닝 (군집/연관)
-
군집분석을 실시하기 위한 여러 거리 측도 중 범주형 데이터 거리를 계산하기 위한 측도는 무엇인가? -> 자카드 거리
연속형 변수 거리: 유클라디안 거리(흔히 아는 거리), 표준화 거리(표준화하게 되면 척도, 분산의 차이로 인한 왜곡을 피할 수 있다), 마할라노비스 거리(통계적 개념 포함. 변수의 표준화와 상관성을 동시에 고려, 맨하탄 거리, 민코우스키 거리
범주형 변수 거리: 자카드 유사도(Boolean 속성으로 이루어진 두 객체간의 유사도 측정에 사용), 코사인 유사도(두 단위 백터의 내적을 이용. 내각의 크기로 유사도를 측정) -
맨하튼 거리 -> 차이 값들의 합
체비셰프 거리 -> 차이 값의 최대값 -
계층적 군집 분석
-> 범주형 데이터에서도 거리 측정이 가능하므로 분석 기법을 적용할 수 있다
-> R에서 최장연결법을 수행하기 위해서는 complete를 사용한다
-> 군집분석의 기본은 가장 가까운 데이터를 우선적으로 묶는 방법이며, 최장연결법은 묶고 난 다음에 군집과 기존 데이터를 어떻게 연결한 것인지 정의
-> 와드연결법은 군집 내 편차 제곱합이 최소가 되도록 연결하는 방법
-> 최단연결법: 최단거리를 이용해 군집형성. 고립된 군집을 찾는 데 중점. 사슬모양의 군집이 생길 수 있음
-> 최장연결법: 최장거리를 이용해 군집형성. 내부 응집성에 중점을 둠
-> 중심연결법: 중심간의 거리를 이용해 군집형성
-> 평균연결법: 계산량이 많지만 모든 데이터를 포함하는 하나의 군집 형성
-> 와드연결법: 군집내의 오차제곱합에 기초하여 군집 형성 -
K 평균 군집
-> 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작
-> 군집의 seed가 이동함에 따라 데이터(군집)이 할당되었다 풀리게 됨
-> 제곱합 그래프를 보고 초기 K값 결정에 도움받을 수 있다
-> seed의 변경이 없거나 n번의 반복이 끝날때까지 군집작업을 반복 수행한다 -
K 평균 군집
-> 탐욕적 알고리즘으로 매 순간순간 최적의 군집을 찾기 위해 반복적으로 수행해서 안정적. 초기 seed 값을 결정하기 어려워 최적의 군집을 보장하지는 못함. 비지도 학습
-> 이상값에 민감하기 때문에 새로운 seed를 결정할 때 평균 대신 중앙값을 사용하기도
-> 목적이 없이 분석 수행이 가능하나 결과의 해석이 어렵다 -
EM 알고리즘의 E 단계에서, 임의로 설정된 파라미터 값을 활용하여 주어진 확률분포로부터 표본이 추출된 기댓값을 게산한다
-
자기 조직화 지도 (SOM)
-> 완전연결의 형태로 입력층의 각 데이터를 경쟁층의 뉴련에 모두 연결된다
-> 경쟁층에 한번 표시된 데이터는 iteration이 반복되는 동안 다른 노드로 이동할 수 있다!
-> 은닉층이 없으며 순전파 방식만 사용하기 때문에 알고리즘 수행 속도가 매우 빠르다
-> 초기 학습률 및 초기 가중치의 결정이 결과에 큰 영향을 끼친다 -
k-means clustering은 비계층적 군집방법! -> 이상값에 민감하여 군집 경계의 설정이 어렵다는 단점이 있음. 이를 극복하기 위해 등장한 비계층적 군집 방법은? -> k-medoids clustering
-
계층적 군집방법은 두 개체 간의 거리에 기반하여 군집을 형성해 나가므로 거리에 대한 정의가 필요함. 이 때 변수의 표준화와 변수 간의 상관성을 동시에 고려한 통계적 거리는? -> 마할라노비스 거리
-
계층적 군집분석 수행 시 두 군집을 병합하는 방법 가운데 병합된 군집의 오차제곱합이 병항 이전 군집의 오차제곱합의 합에 비해 증가한 정도가 작아지는 방향으로 군집을 형성하는 방법은? -> 와드연결법(군집 내 오차제곱이 최소가 되도록 연결)
-
실루엣: 군집분석의 품질을 정량적으로 평가하는 대표적인 지표. 군집 내 데이터간 거리가 짧을 수록 군집 간 거리가 멀수록 값이 커짐. 완벽한 분리일 경우 1의 값.
-
연관분석
-> 품목 수가 증가할 수록 계산량은 기하급수적으로 증가
-> 최소 지지도 이상의 품목에 대해 분석을 진행하는 apriori 알고리즘이 있다
-> 품목 세분화가 많이 된다 해서 더 좋은 결과를 얻는건 아님
-> 결과의 해석이 IF~ THEN~ 으로 매우 쉽고 단순하다 -
연관 분석에 시간 개념을 추가한 것으로 'A를 구매한 고객은 추후에 B를 구매할 것이다'와 같은 두 품목과 시간에 대한 규칙을 찾는 분석 기법. 어떤 고객이 무엇을 구매했는 지 과거와 현재를 비교하기 위해 고객의 정보가 필요 -> 순차패턴
-
연관분석 측도
두 품목에 대한 서로의 조건부 확률로 A가 구매될 때 B가 구매될 확률 또는 B가 구매될 때 A가 구매될 확률로 표현이 가능 -> 신뢰도
A->B일 때, (커피사는 사람은 A, 탄산음로도 산다 B)
지지도: P(A교B)
신뢰도: P(A교B)/P(A)
향상도: P(A교B)/(P(A)*P(B))/향상도가 1보다 크면 해당 규칙이 결과를 예측하는데 있어 우수하다는 것을 의미
