처음 v1(Angularjs) 프로젝트에서 정적페이지로만 이루어진 부분 먼저 v2(React)로 마이그레이션을 진행하던 중 상태관리 및 query fetching에 대한 효율적인 부분을 고민하던 중 ReactQuery가 좋은 대안이 될 수 있겠다고 판단했고 관련된 내용을 찾아보던 중 배민 주문팀 프로젝트에 성공적인 ReactQuery 도입과정을 세미나로 풀어낸 내용이 있어 해당 내용을 정리하였다.
당시 바쁘던 팀원들의 상태를 위해 그나마 빠르게 정리할 수 있도록 내용을 정리하고 공유했다.
유튜브 배민 세미나 영상 출처
https://www.youtube.com/watch?v=MArE6Hy371c
1. FE 상태관리는 무엇일까?
상태란??
- 주어진 시간에 대해 시스템을 나타내는 것으로 언제든지 변경 가능
- 즉, 문자, 배열, 객체 등으로 저장된 데이터
프론트 개발자로서 오너쉽을 가지고 관리를 해야하는 데이터들이다.
UI/UX 의 중요성과 함께 프로덕트 규모가 커짐에 따라 FE가 해야할 일들이 많아짐. → 관리할 상태가 많아짐
상태관리는?
상태관리가 프로덕트 커짐에 따라 어려움도 커짐
상태는 시간에 따라 변화함 → 유저 반응
리액트의 단방향 특성으로 Props Drilling 문제도 존재
Redux와 MobX 등의 라이브러리로 해결하기도 함
왜 그럼 React Query? 주문 FE 프로덕트를 보며 가진 고민이 무엇인지?
배민 앱위에서 메인 프로덕트들이 돌아가고 있음.
FE프로덕트가 어디에서 돌아가고 있는지 궁금할 수 있음.
→ 장바구니부터 주문쪽, 결제 등등에서 많은 부분에서 웹뷰를 활용 중
적은 인원으로 많은 FE레포들(제이쿼리, 우아한js, 리액트 등) 을 관리하는 과정에서 하나의 아키텍쳐(리액트)로 관리하기로 함
이에 따라 자연스럽게 상태관리에 대한 고민을 함 → 우리와 비슷한 과정
리덕스(RTK 나오기 전) 사용을 했는데 전역 Store가 상태를 관리한다기보단 대부분이 API 통신코드와 같은 느낌을 많이 받았음.
Store에 수많은 API통신 코드, isFetching, isError 등 API 관련 상태, 반복되는 구조의 API 통신 코드 → 리덕스의 전형적인 단점. 수많은 코드량
지금에와서 생각해봐도 상태관리를 위한 적정한 기술인가? 에 대한 의문은 있음.
서버에서 받아야하는 상태들의 특성
- Client에서 제어하거나 소유되지 않은 원격의 공간에서 관리되고 유지됨
- Fetching이나 Updating에 비동기 API가 필요함
- 다른 사람들과 공유되는 것으로 사용자가 모르는 사이에 변경될 수 있음
- 신경쓰지 않는다면 잠재적으로 “out of date”가 될 가능성을 지님
위의 내용을 예시로 정리해보자면
만약 배민앱으로 주문이 들어온 상태
- 이미 유저의 주문이 완료된 상태라면 해당 주문된 데이터는 Client가 갖고 있는 상태가 아닌 DB에 저장된 원격 공간의 데이터임.
- 해당 주문 데이터를 Client가 받아오기 위한 통신 API가 필요함.
- 주문이 완료된 상태에서 사장님이 주문을 접수한 후에 해당 건수의 상태가 메뉴접수 중 → 메뉴접수 완료로 변경될 수 있음. 해당 타이밍은 랜덤(사장이 주문 접수를 받는 순간)
- Client가 위의 상태를 신경쓰지 않는다면 유저는 접수가 완료되었는지 모르고 계속 메뉴접수 중인 상태로 인지할 수 있음.
사실상 FE에서 이 값들이 저장되어 있는 state들은 일종의 캐시.
그래서 결국 React Query 가 뭔데?
기능도 좋고, 파워풀하다. 뭔가 자신감 개쩜;
리액트에서 데이터들을 페치하고 캐싱하고 다 해준다. 전역 상태 하나~도 안건드리고.
써본 입장에서 생각해보니까 어느정도 동의하는 바.
지가 알아서 백그라운드에서 잘해주고 훅기반의 심플하게 사용 가능하고 꽤 강력하고 괜찮은 옵션이 많다.
하나하나 살펴보자
React Query는 zero-config로 즉시 사용가능, But 원하면 언제든 config도 커스텀 가능!
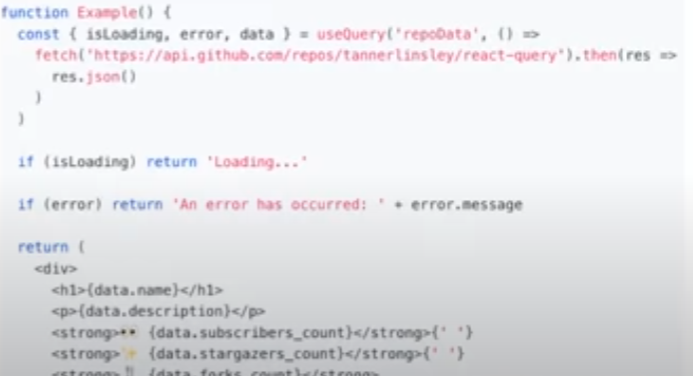
첫인상은 뭔가 간당해보이기는 함. 딱히 config도 없고 코드도 훅스 같고??
본격적으로 알아보기 전에
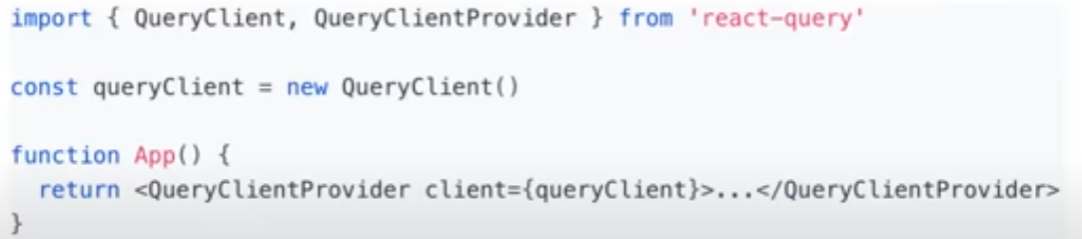
React에서 쓰려면 QueryClientProvider 필수!
React Query의 세가지 핵심 컨셉을 살펴보자.
공식 문서에서 짚은 3가지 핵심 개념
- Queries
- Mutations
- Query Invalidation
추후 공식문서 참고하여 자세하게 더 공부해보자!
1. Queries
CRUD 중 Reading만 사용할거입니다.
Queries는 데이터 Fetching용!
예제.
import { useQuery } from 'react-query'
function App() {
const info = useQuery('todos', fetchTodoList)
}
// 'todos' => Query Key
// fetchTodoList => Query FunctionQuery Key?
Key, Value 맵핑구조를 생각하면 된다.
- React Query는 Query Key에 따라 query caching을 관리한다.
Key가 관리되는 형태는 두가지 String, Array
1. String 형태
// A list of todos
useQuery('todos', ...) // queryKey === ['todos']
// Something else, Whatever!
useQuery('somethingSpecial', ...) // queryKey === ['somethingSpecial']2. Array 형태
// An individual todo
useQuery(['todo'], 5], ...)
// queryKey === ['todo', 5]
//An individual todo in a "preview" format
useQuery(['todo'], 5, { preview: true }], ...)
// queryKey === ['todo', 5, { preview: true }]
// A list of todos that are "done"
useQuery(['todo'], { type: 'done' }], ...)
// queryKey === ['todo', { type: 'done' }]실무에서 쓰게된다면 확실히 Array형태로 많이 쓰이게될 수 있을 듯.
Query Function?
이 녀석은 쉽게 얘기해서 우리도 현재 data fetching 할 때 Promise 함수로 만들어서 쓰죠?? 그런 녀석입니다.
Promise를 반환! → 데이터 resolve하거나 error를 throw
useQuery('fetchOrder', () => fetchOrder(orderNo), options)
export const fetchOrder = (orderNo: string): Promise<...> =>
orderHistoryApiRequester
.get(`url`)
.then(res => res.data);우리 흔히 쓰는 fetch, axios, etc… 등 생각하면 됨.
다시, Queries
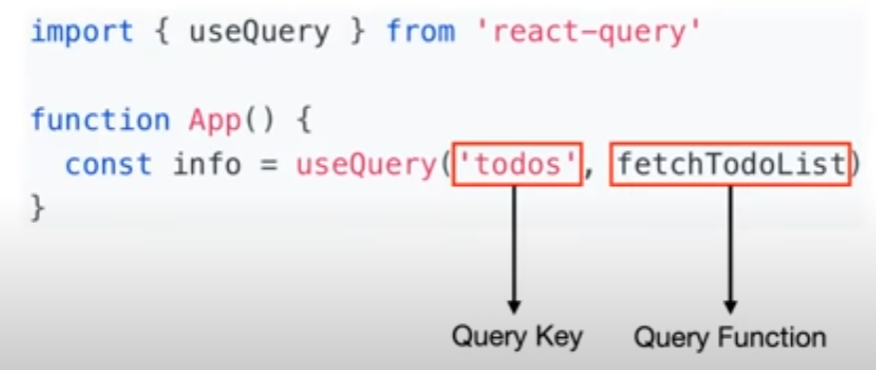
정리하면 useQuery 함수 사용법은 첫번째 인자로 캐싱을 관리할 키값을 넣어주고 두번째 인자로 우리가 실제로 api 통신을 통해 data를 fetching하려는 Promise 함수를 넣어준다.
자 이제 그럼 어떻게 쓰는지는 알겠고,
useQuery함수는 뭘 반환하느냐?
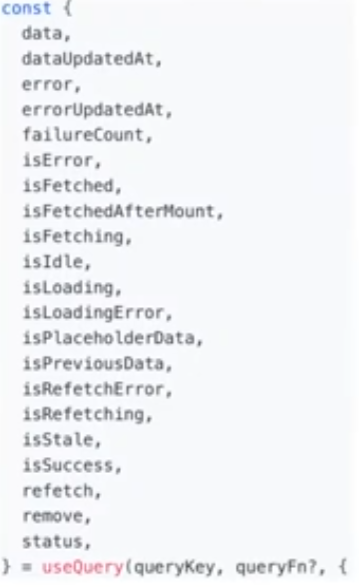
너무 많다. 우리가 쓸만한 것들만 정리하자면
data: 마지막으로 성공한 resoloved된 데이터 (response)
error: 에러가 발생했을 때 반환되는 객체
isFetching: Request기 in-flight 중일 때 true
status, isLoading, isSuccess, isError 등등 : 모두 현재 query의 상태
→ 이거 redux 써봤으면 얼마나 중간중간 액션 상태로 만들어주는게 극혐인지 알고 있을 것…ㅠ
refetch: 해당 query refetch 하는 함수 제공
→ ex) 뭐 이미 리액트 쿼리가 잘 알아서 가져와주겠지만 특정 버튼을 눌렀을 때 새로운 쿼리를 가져왔으면 할 때? 사용하면 됨. 현재 이모밥줘 사이트에 메뉴를 제출하면 refetch 해주고 있음.
remove: 해당 query cache에서 지우는 함수 제공
결국 우리가 다 구현해야될 상태에 관련된 함수들 다 제공해준다~넘나 편한것;
자 그래서 이제 뭐가 편한지도 알겠고 뭐 반환하는지도 알겠고 어느정도 뭔지 알겠다.
근데 아까 config 커스텀 된다면서??
useQuery Option
아까 슬쩍 지나간 코드
useQuery('fetchOrder', () => fetchOrder(orderNo), **options**)options에 들어가는 녀석들
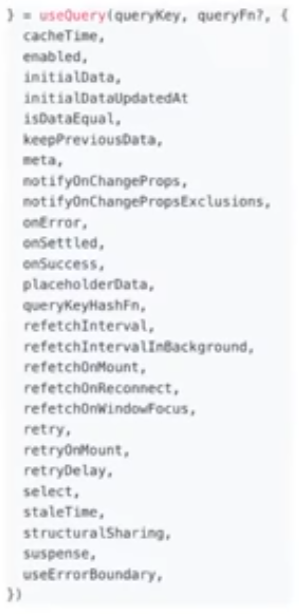
역시 많다.
쓸만한 것들을 정리해보자.
onSuccess, onError, onSettled: query fetching 성공/실패/완료 시 실행할 Side Effect 정의
enabled: 자동으로 query를 실행시킬지 말지 여부 → false 시 컴포넌트 마운트단계에서 실행x
retry: query 동작 실패 시, 자동으로 retry할지 결정하는 옵션 → 기본값 3번을 자동으로 실행
select: 성공 시 가져온 data를 가공해서 전달 가능 → data.data.name 등을 방지
keepPreviousData: 새롭게 fetching 시 이전 데이터 유지 여부
refetchInterval: 주기적으로 refetch 할지 결정하는 옵션 → polling 구현 시 엄청 스무스하게 자동으로 처리됨.
개인적으로 queries 파일을 분리하는 것도 추천함.
react-query 공식문서의 내용은 아니지만 배민에서 직접 사용하다보니 해당 부분 처리를 별도의 파일로 관리하는 것이 컴포넌트의 사용성이 더 좋았다고 생각하고 있어 해당 부분을 현재 분리하여 관리 중이라고 함.
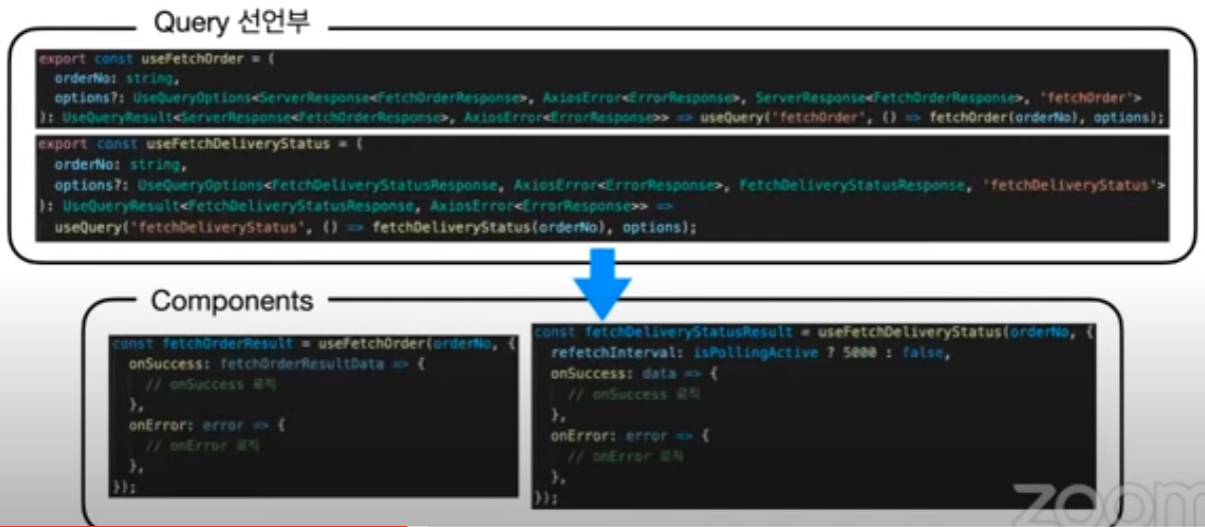
그럼 query가 여러 개일 땐 어떻게 하는게 좋을까?
알아서 잘 된다! (동적으로 하려면 다른 방법이 있음.)
function App () {
// 아래의 쿼리들을 병렬적으로 알아서 잘 처리될 것이다! 걱정 ㄴㄴ
const usersQuery = useQuery('users', fetchUsers)
const teamsQuery = useQuery('teams', fetchTeams)
const projectQuery = useQuery('projects', fetchProjects)
...
}그럼 질문!
기술 블로그에 달렸던 질문들중에 답변을 해보려고 함.

답변: 위의 경우 1번을 먼저 해보고 1번이 불가능한 경우 2번으로 처리할 것이다.
1번의 경우 매우 간단한 내용이고 2번으로 처리하는 경우 코드의 복잡도가 너무 많이 올라가게되고 이 부분을 최대한 지양하려고 함.
그래서 간단한 부분이라면 1번으로 처리.
조금 복잡한 컨디션의 조건을 갖고 있는 경우에서의 처리는 2번으로 추천. → 다만 해당 부분으로 처리 시 부가적인 상태들을 관리해야한다는 것은 좋은 부분은 아닌 듯함.
2번 질문은 리덕스에서 혼용하여 사용 시에 대한 질문이였기에 생략.
2. Mutations
const mutation = useMutation(newTodo => {
return axios.post('/todos', newTodo)
})useQuery 보다 더 심플하게 Promise 반환 함수만 있어도 된다!
→ 단, Query Key 를 넣어주면 devtools에서 볼 수 있기 때문에 실무에선 키값을 넣어주는 것을 개인적으로 추천함.
useMutation의 반환값
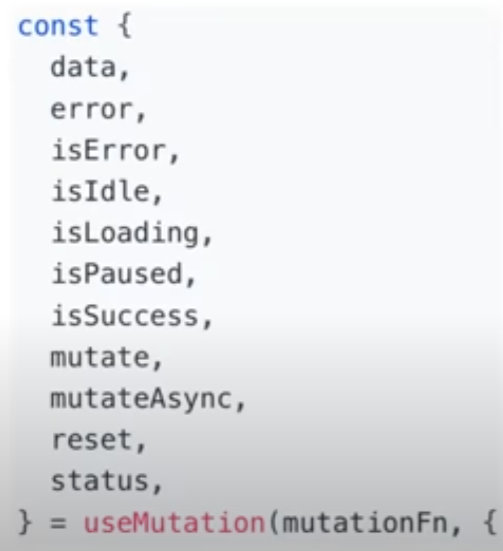
mutate: mutation을 실행하는 함수
mutateAsync: mutate와 비슷. But Promise를 반환
reset: mutation 내부 상태를 clean 하게 만듦
나머진 특별히 설명 필요x useQuery랑 비슷하게 동작하고 오히려 반환하는 객체 안의 내용은 더 적음.
useMutation Option
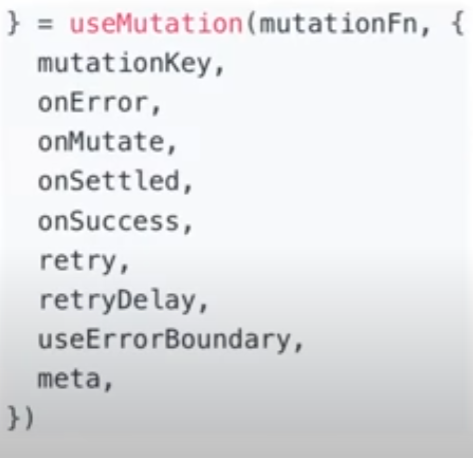
onMutate: 본격적인 Mutation 동작 전에 먼저 동작하는 함수, Optimistic update 적용할 때 유용
❓ Optimistic update?페이스북의 좋아요 기능을 사용한다 했을 때, 유저가 좋아요 버튼을 눌렀을 때 client는 해당 글의 좋아요 api가 성공했을 것이라고 예상하고 미리 파란색으로 좋아요 버튼에 대한 UI를 업데이트함.
다음과 같은 작업을 말하고 이후 api가 성공적으로 동작했다면 UI를 유지하고 실패한 경우에 한해 UI를 롤백함. 이 또한 기능으로 처리가 가능하다.
3. Query Invalidation
간단히 queryClient를 통해 invalidate 메소드를 호출하면 끝!
// Invalidate every query in the cache
queryClient.invalidateQueries()
// Invalidate every query with a key that starts with 'todos'
queryClient.invalidateQueries('todos')이러면 해당 Key를 가진 query는 stale 취급되고, 현재 rendering 되고 있는 query 들은 백그라운드에서 refetch 된다.
그래서 OK. Data Fetching하고 updating은 알겠어. 그럼
Caching하고 Synchronization은 어떻게 리액트쿼리에서 알아서 하는데요? 에 대한 질문은 2부에서.
2부 시작.
살펴보기 전에 잠깐,
우리들 모르는 사이에 등장한 옵션들
사실 아까 예제에서 잠깐 등장한 Option에 cacheTime, staleTime도 있었고,
refetchOnWindowFocus, refetchOnMount 같은 것도 있었음.
얘네들을 리액트쿼리가 어떻게 처리하고 있을까? 아래와 같은 아이디어를 차용했다고 생각하면 좋겠다.
RFC 5861
HTTP Cache-Control Extensions for Stale Content
-
stale-while-revalidate
-
백그라운드에서 stale response를 revalidate 하는 동안 캐시가 가진 stale response 를 반환
❓ Cache-Control 옵션의 max-age 속성은 해당 캐시값의 생애주기를 결정함. 위의 예제에서는 600초 동안 캐시가 유효하다. 여기서 stale-while-revalidate 속성은 해당 캐시가 수명을 다 한 뒤에 새로운 값을 요청하는 동안 로딩스피너가 돌게될텐데 그 간 30초동안의 요청에 대한 응답으로는 서버의 응답이 오기전이라면 우선적으로 전에 캐싱되어있던 값을 보여주고 이후 revalidate된 값이 있다면 해당 값으로 다시 캐싱처리되게 된다.

-
위와 같은 아이디어대로 동작하게 된다면 서버요청응답으로 인한 Latency가 숨겨질 것!
그럼 위와 같은 컨셉을 메모리 캐시에도 적용해보자!
이렇게하여 나온 것이 react-query, swr, etc 등등…
cacheTime: 메모리에 얼마만큼 있을건지 결정하는 요소(해당 시간 이후 GC에 의해 처리, default 5분)
staleTime: 얼마의 시간이 흐른 후에 데이터를 stale 취급할 것인지(default 0)
refetchOnMount / refetchOnWindowFocus / refetchOnReconnect → true 이면 Mount / window focus / reconnect 시점에 data 가 stale 이라고 판단되면 모두 refetch (모두 default true)
- 예로 윈도우 탭을 이동했다가 다시 돌아온 경우 refetchOnWindowFocus 이벤트가 발생할 것이고 해당 이벤트 전 fetching된 data가 있었다면 이미 regacy쿼리로 취급 후 다시 refetch 이벤트가 발생됨. 여타 이벤트에도 마찬가지. staleTime이 0이 default 이기 때문.
Query 상태흐름
화면에 있다가 사라지는 query
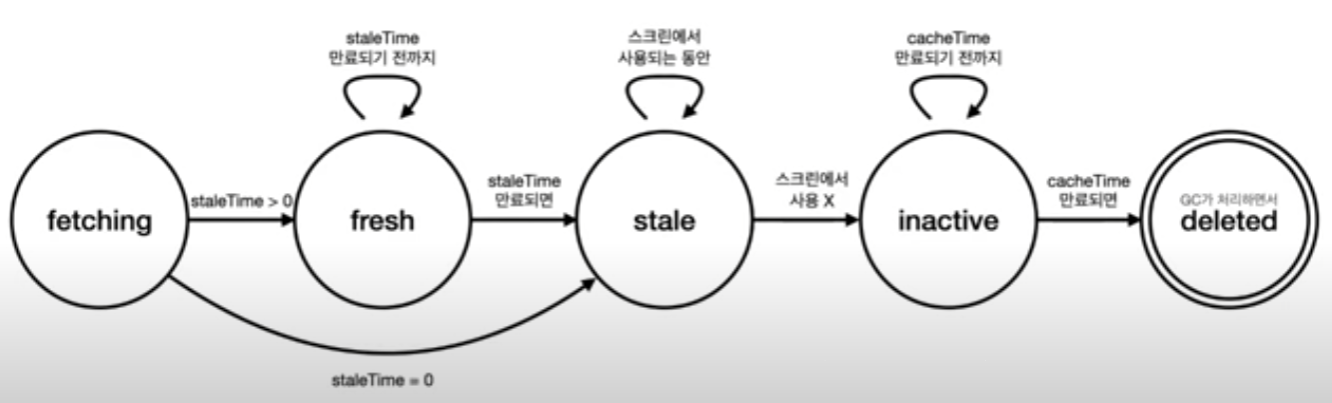
zero-config 에서도 이런 역할을 한다.
알아서 하는 것들이 있어서 좋지만 주의도 해야함.
- staleTime → default값 0
- refetchOnMount / refetchOnWindowFocus / refetchOnReconnect → default값 true
- cacheTime → default값 60 5 1000
- retry → default값 3, retryDelay → default값 exponential backoff function? (요건 이해 못함)
그래서 React Query 는 어디에서 값들을 관리할까??(회의때도 나왔던 내용인 듯)
마치 전역상태처럼 관리되는 데이터들
어떻게 Server State들을 전역상태처럼 관리할까??

해답은 Context API에 있음. 민구님이 말씀하신 그대로인듯.
QueryClient 내부적으로 Context를 사용하고 있음. 깃허브 코드 확인.

React Query etc.
- useInfiniteQuery
- Prefetching
- TypeScript 지원
- GraphQL도 대응
- SSR & Next.js에서도 사용 가능
- devtools
- etc.
React Query 이후 주문 FE프로덕트의 변화
느껴진 바뀐 점으로.

그래서 좋은 점으로 정리하자면,
- 서버상태 관리 용이하며 (Redux, MobX 사용할 때보다) 직관적인 API호출 코드
- API처리에 관한 각종 인터페이스 및 옵션제공
- Client Store 가 FE에서 정말로 필요한 전역상태만 남아 Store 답게 사용됨 (Boilerplate 코드 매우 감소)
- devtool 제공으로 원활한 디버깅 → 요거 개인적으로 추천함. 되게 좋은듯
- Cache 전략 필요할 때 아주 좋음
좀 더 고민이 필요할 것 같은 부분
- Component가 상대적으로 비대해지는 문제 (Component 설계/분리에 대한 고민 필요)
- 좀 더 난이도가 높아진 프로젝트 설계 (Component 유착 최소화 및 사용처 파악 필요)
- React Query의 장점을 더 잘 활용할 방법 찾기 (단순히 API 통신 이상의 가능성)
그래서 우리도 써야하나? (일단은 우리는 쓰기로 함ㅎ)
최신 npm 동향
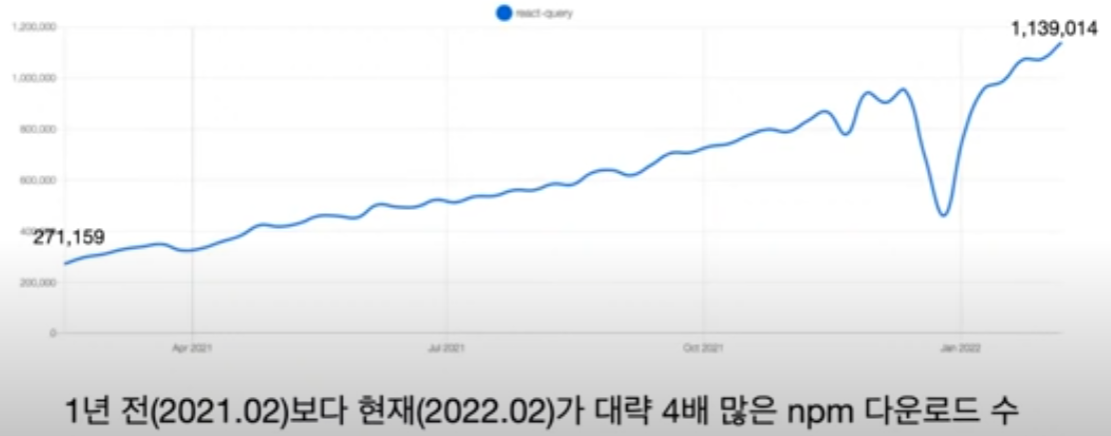
트렌드는 나쁘지 않아보임.
하지만 중요한건 트렌드보단 WHY!
이런분들에게 추천합니다.
- 수많은 전역상태가 API통신과 엮여있어 비대해진 Store를 고민하시는 분
- API 통신관련 코드를 보다 간단히 구현하고 싶으신 분
- FE에서 데이터 Caching 전략에 대해 고민하시는 분
- (공부가 목적이라면) 모든 FE 개발자 분들께!
끗.
