문제 발생. 정적 페이지가 맞나?!
네이버 쇼핑 '식빵' 검색 시 순위목록
Get 방식, 개발자 도구 이용, BeautifulSoup 사용
정적 페이지, 어떻게 수집하지?
정적 페이지: HTML 형식
- 동적 페이지는 JSON형식(str)로 받으며, 이를 list나 dict로 변환하는게 쉬웠음.
- 그러나 정적 페이지는 HTML 형식으로 받으며, 이를 list나 dict로 변환하는건 쉽지 않음.
BeautifulSoup과 CSS Selector
- 그래서, BeautifulSoup과 CSS Selector을 이용하여 html을 list나 dict로 바꿔야함. 그리고 최종적으로 DataFrame으로 변환하자.
- BeautifulSoup은 python의 대표적인 HTML 파싱 라이브러리.
절차
import
import pandas as pd
import requests
from bs4 import BeautifulSoup1. 개발자 도구로 url 가져오기
정적 페이지 확인하기
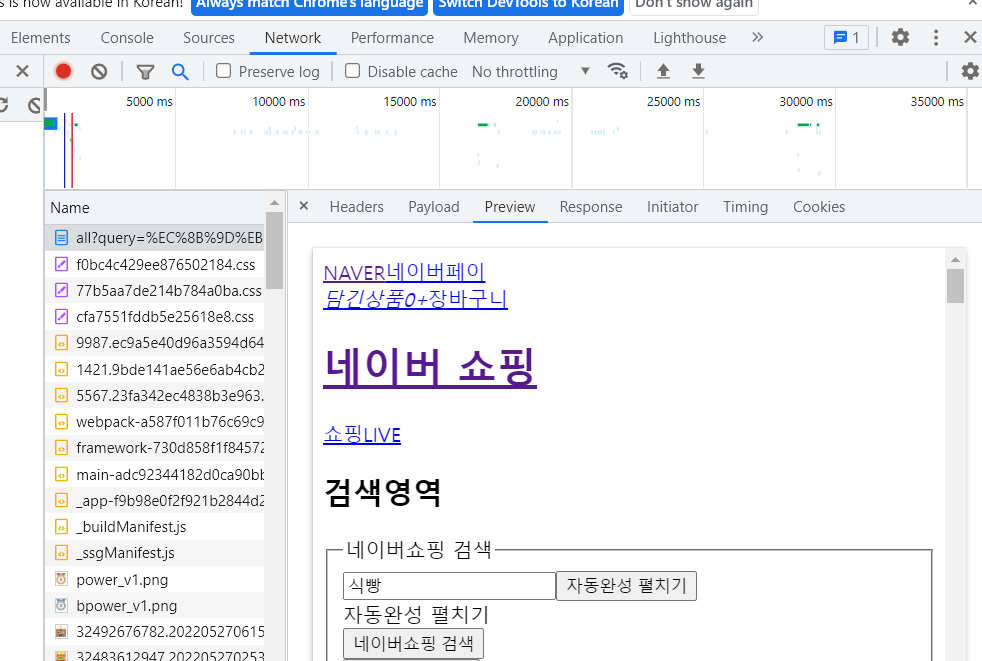
- HTML 형식으로 보이는 것을 알 수 있음
url 디코딩
"https://search.shopping.naver.com/search/all?query=%EC%8B%9D%EB%B9%B5&frm=NVSHATC&prevQuery=%EC%8B%9D%EB%B9%B5"을
"https://search.shopping.naver.com/search/all?query=식빵&frm=NVSHATC&prevQuery=식빵" 으로 디코딩
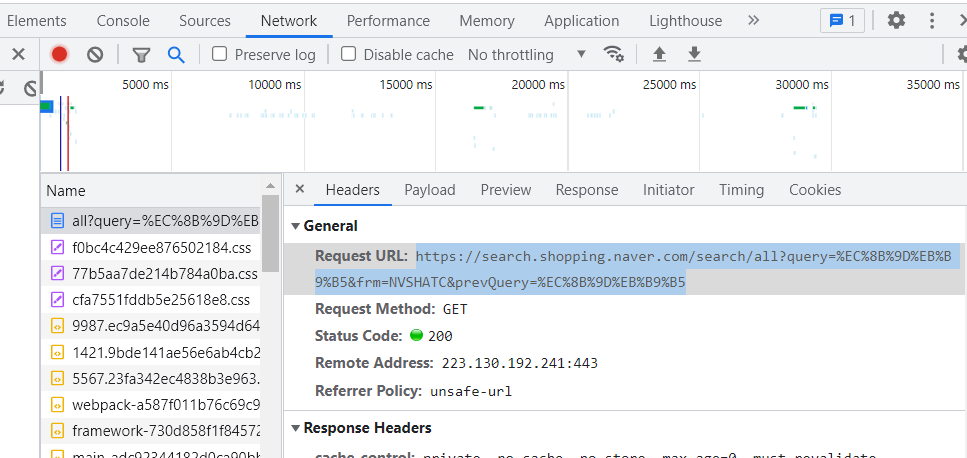
keyword 설정, f-string
keyword = "식빵"
url = f"https://search.shopping.naver.com/search/all?query={keyword}&frm=NVSHATC&prevQuery={keyword}"2. get 방식으로 request
response = requests.get(url)3. HTML 형식을 BeautifulSoup 타입으로 변환
dom = BeautifulSoup(response.text, "html.parser")
type(dom) # 출력: bs4.BeautifulSoup- dom 객체에는 파싱된 HTML 데이터가 담기게됨
4. CSS Selector를 이용하여 element 선택
select(): 엘리먼트 여러개 선택select_one(): 엘리먼트 한개 선택- select 함수는 CSS Selector를 이용해 HTML 내의 구성요소에 접근
- 여기서 우리는 엘리먼트 여러개를 먼저 선택한 다음에, 그 안에서 텍스트 하나하나 가져오는 방식으로 데이터를 수집
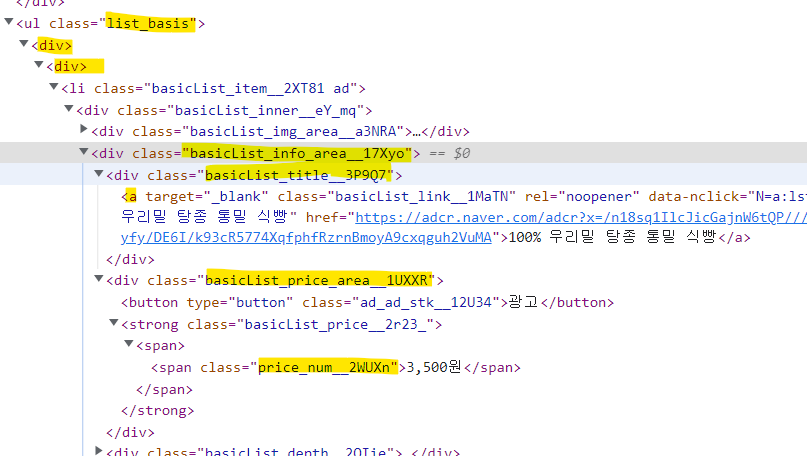
elements = dom.select(".list_basis > div > div .basicList_info_area__17Xyo")
len(elements) # 5
items = []
for element in elements:
data = {
"product" : element.select_one(".basicList_title__3P9Q7 > a").text,
"price" : element.select_one(".basicList_price_area__1UXXR .price_num__2WUXn").text,
}
items.append(data)5. DataFrame으로 변환하기
bread_search = pd.DataFrame(items)
bread_search
함수로 만들기
- 이번에는 link도 추가함
- 만약 url linkt 시작 부분이 '//' 라면?
: http를 가변적으로 작성 가능하게끔. 그럴땐 앞에 http or https를 추가하면 됨(그 사이트가 사용하는 거에 따라) - 태그가 여러개라면?
: 가장 위에 있는 태그 데이터를 가져옴 - 구성요소의 속성값을 가져올땐 get 함수를 씀
import pandas as pd
import requests
from bs4 import BeautifulSoup
def bread_search(keyword):
url = f"https://search.shopping.naver.com/search/all?query={keyword}&\
frm=NVSHATC&prevQuery={keyword}"
response = requests.get(url)
dom = BeautifulSoup(response.text, "html.parser")
elements = dom.select(".list_basis > div > div .basicList_info_area__17Xyo")
items = []
for element in elements:
data = {
"product" : element.select_one(".basicList_title__3P9Q7 > a").text,
"price" : element.select_one(".basicList_price_area__1UXXR .price_num__2WUXn").text,
"link" : element.select_one(".basicList_title__3P9Q7 > a").get("href"),
}
items.append(data)
return pd.DataFrame(items)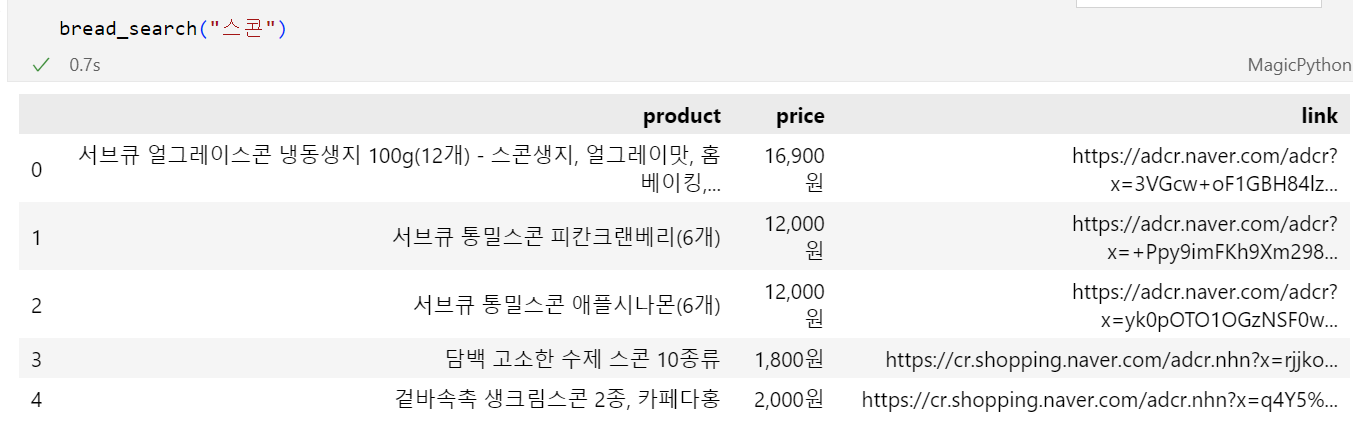
한계점
- 동적 페이지
- 웹브라우저 상에서 보이는 정보를 html에서 정보를 찾을 수 없다.
- 특정한 행동 이후 정보가 보여진다.
- 보여지는 창이 바뀌었는데 url이 변하지 않는다.
- 분명 화면상에는 40개가 뜨는데, html에는 5개만 뜬다. 그런데 BeautifulSoup으로는 스크롤하면서 데이터 수집 안되어서..슬픔... 그게 아쉽다..
- 썸네일을 표현하는 a > img 이미지 태그가 개발자 도구에서는 보였으나, 실제 앞에서 추출한 items에서는 보이지 않음.
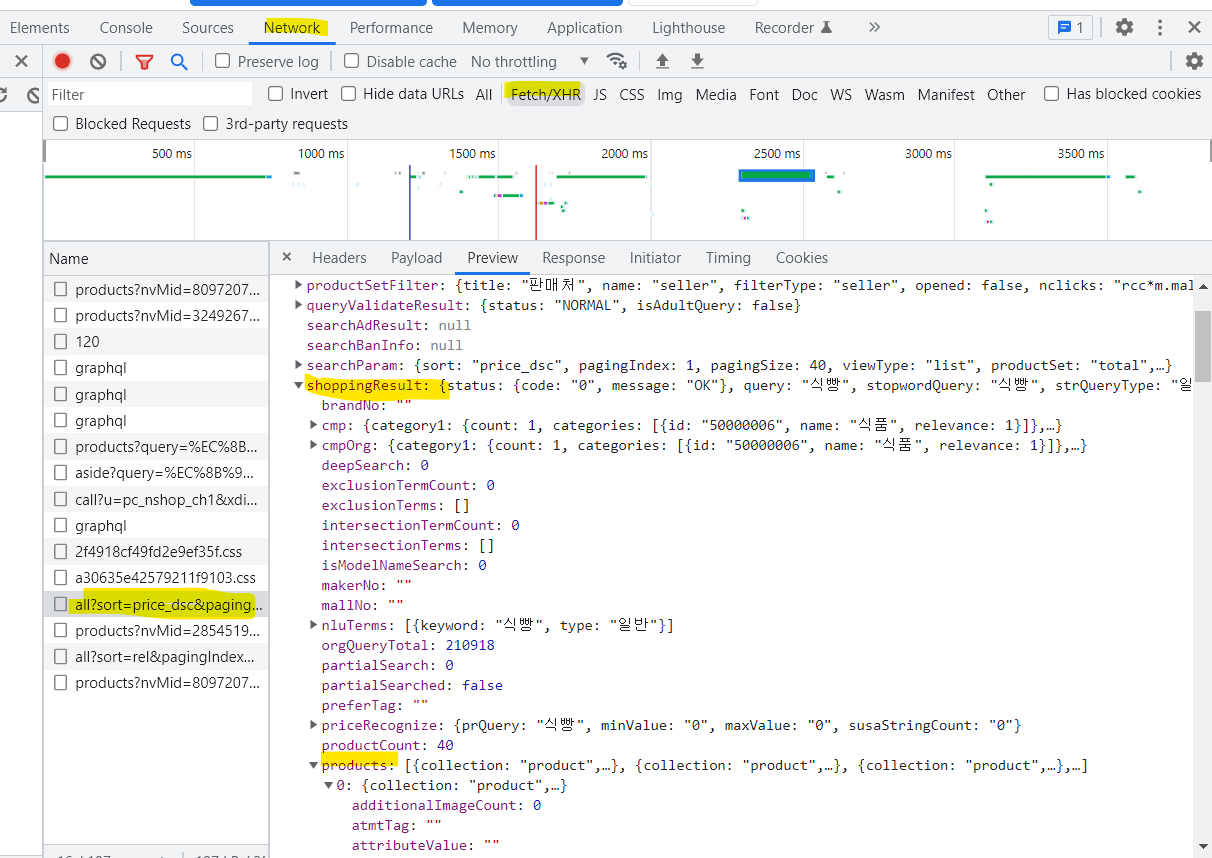
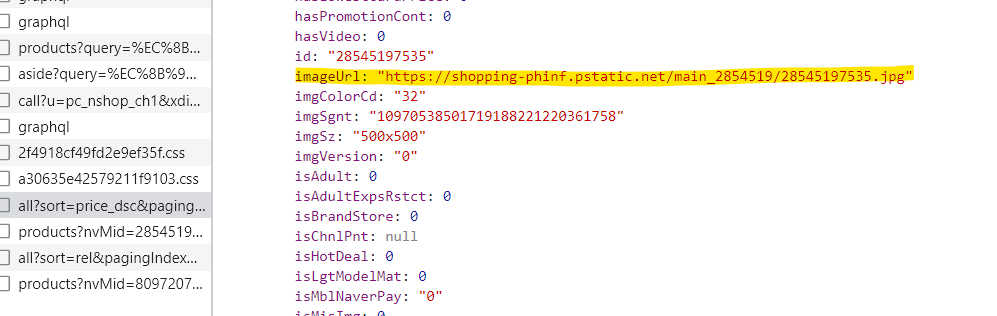
네이버 랭킹순/낮은 가격순/높은 가격순 탭을 클릭 했을 때 크롬 개발자도구 Fetch/XHR 탭에서 all?sort로 뜨는 곳에서 img url 찾을 수 있었습니다.
preview의 json파일에서 'shoppingResult' 'products'에서 imageUrl' 키 value로 get하였더니 이미지 정상적으로 저장되는걸 확인할 수 있었어요확인해보니 진짜로 있다!

내 인생의 주연