- 출처: HackerRank: Basic Select-Easy
- MYSQL 사용
정리
*: allWHERE: 조건에 부합하는 데이터 조회- 여러개의 조건은 논리연산자(and, or)와 같이 사용하자.
- select로 열을 여러개 가져올 때,
열1 and 열2가 아니라,열1, 열2로 가져오자 MOD(X, Y): X에서 Y를 나눈 나머지값을 반환하는 함수- 중복 제거하려면,
DISTINCT또는GROUP BY COUNT({컬럼명})- 정규표현식: 자세히
- 시작 철자 '^[AEIOU]', 끝 철자 '[AEIOU]$'
- not을 의미하는 기호
^ SUBSTRING(문자열, 시작할 자리위치, 가져올개수)
궁금증
- Weather Observation Station 4 문제에서
COUNT(city)이 아닌
SELECT COUNT(*)-COUNT(DISTINCT(city)) FROM station;로 하면, city 컬럼에 결측치가 존재하는 경우에 답이 COUNT(city) 에서 뺀 값과 값이 달라지지 않을까? 혹은 상관이 없으려나?
- 답:
COUNT(*): 결측치를 포함한 총 행의 수
COUNT(column): 결측치를 제외한 행의 수 - 따라서,
DISTINCT(city)를 할 경우 null을 포함하지만COUNT(DISTINCT(city))을 할 경우 null을 제외한 수를 셈
- Weather Observation Station 5: limit 수에 따라 출력값의 순서가 변한다..?
SELECT CITY, LENGTH(CITY)
FROM STATION
ORDER BY LENGTH(CITY)
# limit 1; 일때
Roy 3
# limit 2; 일때
Roy 3
Amo 3
# limit 3;일 때
Amo 3
Lee 3
Roy 3- Weather Observation Station 6
- 정규표현식에서, 소문자와 대문자는 구분이 없는걸까요? 둘다 정답으로 처리되네요.
- sql 자체는 소문자 대문자 구분이 없이 찾아짐
- 소문자,대문자를 구분하기 위해서는 LIKE BINARY '%a%'이런식으로 검색해야지만 가능
REGEXP와REGEXP_LIKE의 차이점도 궁금합니다. 우선 찾아보겠습니다.- REGEXP and RLIKE are synonyms for REGEXP_LIKE(). 즉 동음이의어
- Select By ID
- ID 컬럼의 타입이 숫자인데, 왜 WHERE에서 문자열로 조건을 걸어도 올바르게 출력되는걸까?
1. Revising the Select Query I (Easy)
Query all columns for all American cities in the CITY table with populations larger than 100000. The CountryCode for America is USA.
CITY table
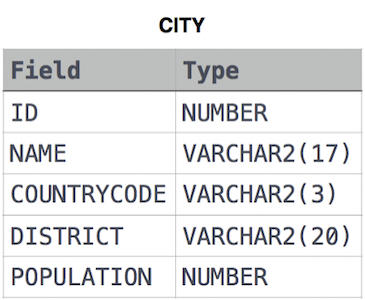
풀이
- 모든 열을 가져올 것
- 조건: 미국인, 인구수 100000 이상
SELECT * FROM CITY WHERE POPULATION > 100000 AND COUNTRYCODE = 'USA';2. Revising the Select Query II (Easy)
Query the NAME field for all American cities in the CITY table with populations larger than 120000. The CountryCode for America is USA.
CITY table
풀이
- 가져올 것: 이름
- 조건: 모든 미국인(CountryCode 코드: USA), 인구가 120000 이상
SELECT NAME FROM CITY WHERE POPULATION > 120000 AND COUNTRYCODE = 'USA';출력
Scottsdale
Corona
Concord
Cedar Rapids3. Select All (Easy)
Query all columns (attributes) for every row in the CITY table.
CITY table
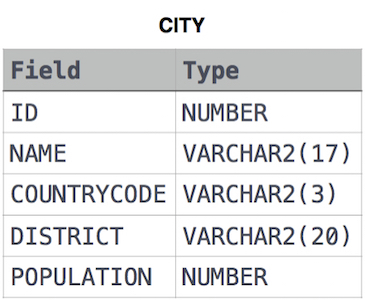
풀이
- 모든 열을 가져올 것
SELECT * FROM CITY;4. Select By ID (Easy)
Query all columns for a city in CITY with the ID 1661.
CITY table
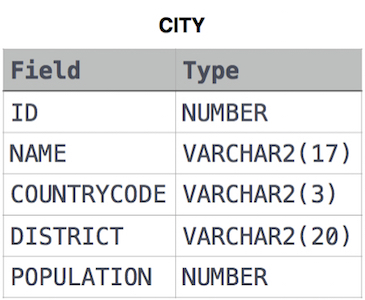
풀이
- 모든 열을 가져올 것
- 조건: ID = 1661
SELECT * FROM CITY WHERE ID = '1661';다시풀기
SELECT *
FROM CITY
WHERE ID = 1661;- ID 컬럼의 타입이 숫자(number)여서 1661로 조건을 걸었는데, 전에는 ID를 문자열('1661')로 조건을 걸어서 통과했다. 컬럼 타입이 숫자인데도 왜 문자열로도 통과가 되는걸까?
5. Japanese Cities' Attributes (Easy)
Query all attributes of every Japanese city in the CITY table. The COUNTRYCODE for Japan is JPN.
The CITY table
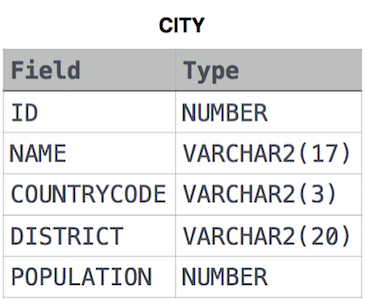
풀이
SELECT * FROM CITY WHERE COUNTRYCODE = 'JPN'6. Japanese Cities' Names (Easy)
Query the names of all the Japanese cities in the CITY table. The COUNTRYCODE for Japan is JPN.
CITY table
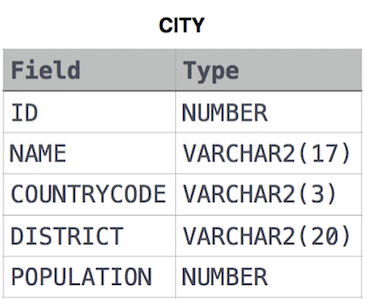
풀이
SELECT NAME FROM CITY WHERE COUNTRYCODE = 'JPN';
7. Weather Observation Station 1 (Easy)
Query a list of CITY and STATE from the STATION table.
STATION table
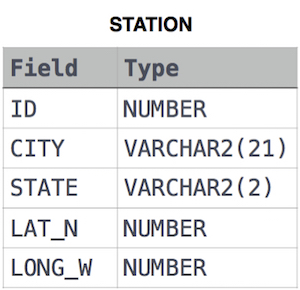
풀이
SELECT CITY, STATE FROM STATION;SELECT CITY AND STATE FROM STATION;하면 틀린다!
8. Weather Observation Station 3 (Easy)
Query a list of CITY names from STATION for cities that have an even ID number. Print the results in any order, but exclude duplicates from the answer.
STATION table
풀이
- MOD(X, Y) : X에서 Y를 나눈 나머지값을 반환하는 함수
- 중복 제거:
- SELECT DISTINCT {컬럼명} FROM {테이블명} {조건절}
: 중복만 제거 - SELECT {컬럼명} FROM {테이블명} {조건절} GROUP BY {테이블명}
: 중복 제거 후 정렬
- SELECT DISTINCT {컬럼명} FROM {테이블명} {조건절}
SELECT DISTINCT CITY FROM STATION WHERE MOD(ID, 2) = 0;다시풀기
- 처음 풀었을 때와 동일한 실수를 했다. 바로
'^[AEIOU]$으로 작성했던것. 그런데 쿼리에 오류가 떠서 문자열 시작과 끝을 각각 and로 나누니, 성공! - 문자열 시작과 끝을 조건으로 걸 때는, and를 사용하자
9. Weather Observation Station 4 (Easy)
Find the difference between the total number of CITY entries in the table and the number of distinct CITY entries in the table.
STATION table
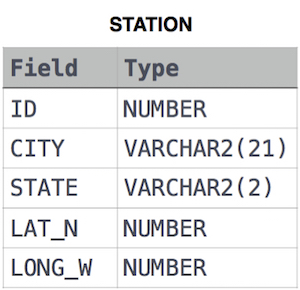
example
if there are three records in the table with CITY values 'New York', 'New York', 'Bengalaru', there are 2 different city names: 'New York' and 'Bengalaru'. The query returns.
풀이
- COUNT({컬럼명})
SELECT COUNT(CITY) - COUNT(DISTINCT(CITY)) FROM STATION;다시 풀기
SELECT COUNT(CITY) - COUNT(DISTINCT CITY)
FROM STATION;- DISTINCT 다음에 괄호 없이 컬럼명을 씀
- 근데 괄호 써도 되는거 같긴 하지만, 괄호 없이 쓰는게 정석인 것 같다.
10. Weather Observation Station 5 (Easy) ⭐
Query the two cities in STATION with the shortest and longest CITY names, as well as their respective lengths (i.e.: number of characters in the name). If there is more than one smallest or largest city, choose the one that comes first when ordered alphabetically.
STATION table
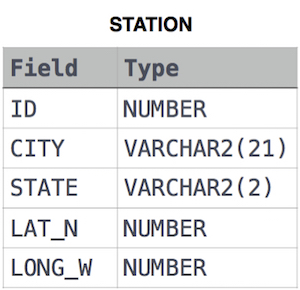
Sample Input
CITY has four entries: DEF, ABC, PQRS and WXY.
Sample Output
ABC 3
PQRS 4Note
You can write two separate queries to get the desired output. It need not be a single query.
풀이
SELECT CITY, LENGTH(CITY)
FROM STATION
ORDER BY LENGTH(CITY), CITY
limit 1;
SELECT CITY, LENGTH(CITY)
FROM STATION
ORDER BY LENGTH(CITY) DESC, CITY
limit 1;다시풀기
- 쿼리문을 여러개 작성 시, 구분을 위해 ;(쌍반점)을 꼭 쓰자!
11. Weather Observation Station 6 (Easy) ⭐
Query the list of CITY names starting with vowels (i.e., a, e, i, o, or u) from STATION. Your result cannot contain duplicates.
STATION table
풀이
SELECT DISTINCT CITY
FROM STATION
WHERE CITY LIKE 'a%' or CITY LIKE 'e%' or CITY LIKE 'i%' or CITY LIKE 'o%' or CITY LIKE 'u%';SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP '^[aeiou]';SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP '^[AEIOU]';SELECT DISTINCT CITY
FROM STATION
WHERE REGEXP_LIKE (CITY, '^[aeiou]');'^[aeiou]'
[]: [] 안에 나열된 패턴에 해당하는 문자열을 찾음.^: 시작하는 문자열을 찾음.
다시풀기
SELECT DISTINCT CITY
FROM STATION
WHERE LEFT(CITY, 1) IN ('a', 'e', 'i', 'o', 'u');- 이번에는 LEFT를 썼지만, 사실 문자열은 정규식을 쓰는게 더 정확할 것 같다.
- 정규식을 다 외우기는 힘드니까, 기본적인 특정 문자열로 시작~ 끝나는~ 이런것만 외우자!
12. Weather Observation Station 7 (Easy)
Query the list of CITY names ending with vowels (a, e, i, o, u) from STATION. Your result cannot contain duplicates.
The STATION table
풀이
- 더 다양한 시도는 6번 문제로 일축. 어짜피 6번이랑 시작과 끝만 다름.
SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP '[AEIOU]$';다시풀기
SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP ('[aeiou]$');- 정규표현식
$: 끝나는 문자열을 찾음
13. Weather Observation Station 8 (Easy)
Query the list of CITY names from STATION which have vowels (i.e., a, e, i, o, and u) as both their first and last characters. Your result cannot contain duplicates.
STATION table
풀이
- 더 다양한 시도는 6번 문제로 일축. 어짜피 6번이랑 시작과 끝만 다름.
- 실패
SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP '^[AEIOU]$';- 성공
SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP '^[AEIOU]' AND CITY REGEXP '[AEIOU]$';다시풀기
SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP ('^[aeiou].*[aeiou]$');- AND를 써도 되지만,
.*로 연결가능하다..*: 아무런 문자든(.)가 0번 이상(*) 반복되는 패턴 찾기.
- 즉,
^[aeiou].*[aeiou]$- aeiou중 하나(
[aeiou])로 시작하고(^) - 그 뒤에 어떤 문자든 0번 이상 오고(
.*) - 마지막으로 aeiou중 하나(
[aeiou])로 끝나는($) 문자열을 찾는것.
- aeiou중 하나(
.*때문에 문자열의 길이가 2 이상이어야만 해당이 되는데, 여기서는 도시명이니까 괜찮았다.
14. Weather Observation Station 9 (Easy)
Query the list of CITY names from STATION that do not start with vowels. Your result cannot contain duplicates.
The STATION table
풀이
- 더 다양한 시도는 6번 문제로 일축. 어짜피 6번이랑 시작과 끝만 다름.
SELECT DISTINCT CITY
FROM STATION
WHERE NOT CITY REGEXP '^[AIEOU]';다시풀기
SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP ('^[^aeiou]');^가 두번 들어가서 헷갈리지만.. 자세히 살펴보면,- X가 찾는 문자열이라고 할 때
^X: 시작하는 문자열을 찾고,[]: 괄호 안의 문자열 중 포함하는 문자열을 찾고,[^X]: 괄호 안의 문자를 포함하지 않는 문자열을 찾는다.
- 즉 aeiou로 '시작'하지 '않는' 문자열을 찾아야하니까 괄호안에
^를 넣고, 괄호 밖에^를 쓴다. - 그런데 그냥 NOT을 쓰는게 더 의미가 직관적인거 아닌가..?
15. Weather Observation Station 10 (Easy)
Query the list of CITY names from STATION that do not end with vowels. Your result cannot contain duplicates.
STATION table
풀이
not을 사용
SELECT DISTINCT CITY
FROM STATION
WHERE NOT CITY REGEXP '[AIEOU]$';- 'not'의 의미인
^을 사용
SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP '[^AIEOU]$';16. Weather Observation Station 11 (Easy)
Query the list of CITY names from STATION that either do not start with vowels or do not end with vowels. Your result cannot contain duplicates.
STATION table
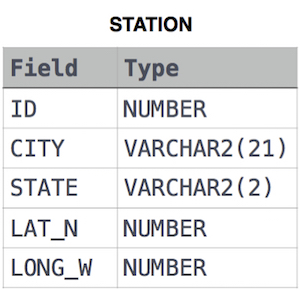
풀이
문제에서 요구하는건, "do not start with vowels or do not end with vowels". 즉 모음으로 시작하지 않거나, 모음으로 끝나지 않아야 한다.
정규표현식
^[aeiou]: aeiou(모음)으로 시작하는 단어 찾기[aeiou]$: aeiou(모음)으로 끝나는 단어 찾기- 대괄호 안에
^을 넣으면, not의 의미
SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP '^[^AEIOU]' OR CITY REGEXP '[^AEIOU]$';^ 대신에 NOT을 사용
NOT을 CITY 앞에 써도 실행되긴 하는데, CITY NOT REGEXP 순서로 쓰는게 맞는 것 같다!
SELECT DISTINCT CITY
FROM STATION
WHERE CITY NOT REGEXP ('^[aeiou]') OR CITY NOT REGEXP ('[aeiou]$');만약 left와 right를 사용한다면, 모음 문자열 나열이 길어서 WHERE절이 조금 길어진다.
SELECT DISTINCT CITY
FROM STATION
WHERE LEFT(CITY, 1) NOT IN ('a', 'e', 'i', 'o', 'u')
OR RIGHT(CITY, 1) NOT IN ('a', 'e', 'i', 'o', 'u');만약 like를 사용한다면 이렇게나 길고 가독성이 좋지 않은 쿼리문이 되므로, 정규표현식이나 left, right를 쓰자!
SELECT DISTINCT CITY
FROM STATION
WHERE
(CITY NOT LIKE 'a%' AND CITY NOT LIKE 'e%' AND CITY NOT LIKE 'i%' AND CITY NOT LIKE 'o%' AND CITY NOT LIKE 'u%') OR
(CITY NOT LIKE '%a' AND CITY NOT LIKE '%e' AND CITY NOT LIKE '%i' AND CITY NOT LIKE '%o' AND CITY NOT LIKE '%u');궁금증
- 생각해보니, MySQL이라서 aeiou의 대소문자를 구분하지 않은 것 같다. 다른 DB라면 구분하려나?
데이터리안 풀이
정규표현식
17. Weather Observation Station 12 (Easy)
Query the list of CITY names from STATION that do not start with vowels and do not end with vowels. Your result cannot contain duplicates.
STATION table
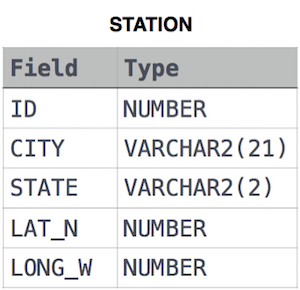
풀이
.*로 전체 표시
SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP '^[^AEIOU].*[^AEIOU]$';AND로 and 표시
SELECT DISTINCT CITY
FROM STATION
WHERE CITY REGEXP '^[^AEIOU]' AND CITY REGEXP '[^AEIOU]$';18. Higher Than 75 Marks (Easy) ⭐
Query the Name of any student in STUDENTS who scored higher than Marks. Order your output by the last three characters of each name. If two or more students both have names ending in the same last three characters (i.e.: Bobby, Robby, etc.), secondary sort them by ascending ID.
STUDENTS table
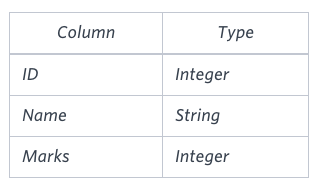
The Name column only contains uppercase (A-Z) and lowercase (a-z) letters.
Sample Input

Sample Output
Ashley
Julia
Belvetthe last three characters of each of their names, there are no duplicates and 'ley' < 'lia' < 'vet'.
풀이
SUBSTRING활용
SELECT Name
FROM STUDENTS
WHERE Marks > 75
ORDER BY SUBSTRING(Name, -3, 3), ID;다시 풀기
SELECT NAME
FROM STUDENTS
WHERE Marks > 75
ORDER BY RIGHT(NAME, 3), ID;- 저번에 문자열에서 left, right를 쓴것처럼 이번에는 정렬에서 right를 사용해봤다. 핵심은 문자열의 뒤에서 세 문자를 기준으로 정렬하고, 그 다음에는 id를 정렬하는 것이었다.
19. Employee Names (Easy)
Write a query that prints a list of employee names (i.e.: the name attribute) from the Employee table in alphabetical order.
테이블
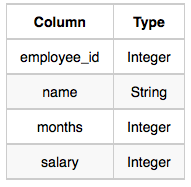
Sample Input
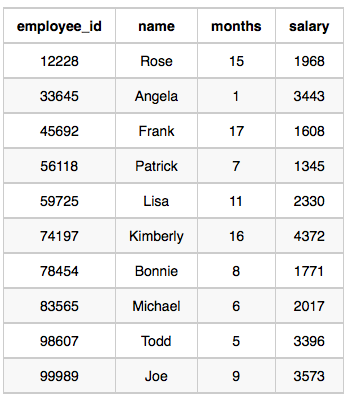
Sample Output
Angela
Bonnie
Frank
Joe
Kimberly
Lisa
Michael
Patrick
Rose
Todd풀이
SELECT name
FROM Employee
ORDER BY name;20. Employee Salaries
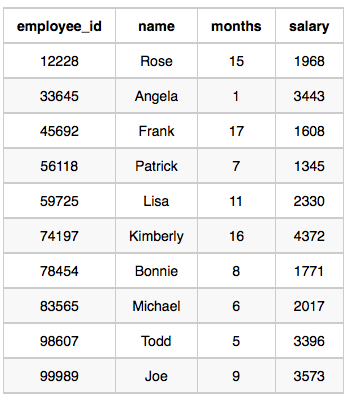
Write a query that prints a list of employee names (i.e.: the name attribute) for employees in Employee having a salary greater than $2000 per month who have been employees for less than 10 months. Sort your result by ascending employee_id.
테이블
Sample Input
Sample Output
Angela
Michael
Todd
Joe풀이
SELECT name
FROM Employee
WHERE salary > 2000 AND months < 10;