궁금증
1. permutation feature importance
1-1. 트리 기반 모델의 변수 중요도는 음수값이 나오지 않지만, pfi를 이용한 변수 중요도는 음수값도 나옵니다. 이에 음수값이 도출된 변수는 제거했을 때 성능이 올라가리라 생각되어, svm에서 변수중요도가 음수값인 변수를 제거하여 모델을 돌려보았으나, 오히려 성능이 떨어졌습니다. 왜 이런 결과가 나온 것일까요..?
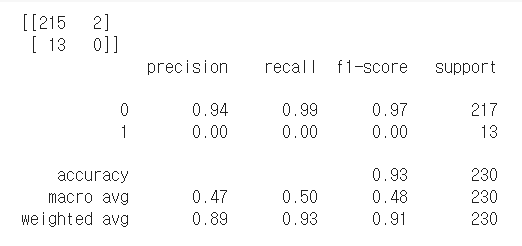
- 모든 변수를 넣었을 때
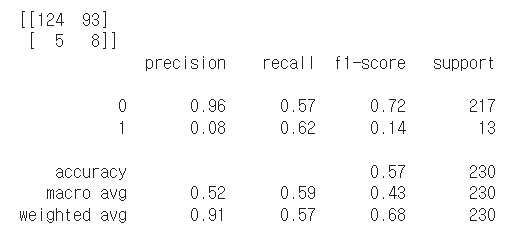
- 변수 중요도가 음수값인 변수를 제거하였을 때
답변
1) 디시전트리나 랜덤포레스트에 있는 feature importance는 노이즈에 취약하므로 Permutation importance를 쓰는게 좋다
2) Permutation importance에서 음수가 나왔다면 이는 그 변수가 오히려 성능을 저해하는 것으로 해석할 수 있다. 그렇지만 음수가 나온 모든 피처를 한꺼번에 삭제하기 보다는 하나씩 삭제하며 성능 추이를 보는 것이 좋다. 그 이유는 선형회귀처럼 독립적인 항이라면 피처를 하나 지워도 다른 항에 영향이 없겠지만, 예를 들어 트리모델만 해도 분기점의 위치마다 미치는 영향력이 달라서 Permutation importance 를 봤을때 상쇄될 수도 있다. 즉 피처들간의 관계가 존재하기 때문에, Permutation importance 를 통한 feature selection는 신중히 해야한다.
3) 근데 Permutation importance에서 음수값이 나온 피처를 제거하기 전에 먼저 표준편차도 보는 것이 좋다. 왜냐하면 어떤 피처는 평균보다 표준편차가 크기도 하기 때문이다.
2. Shapley additive explanations
2-2. 특정 관점으로 Data point이 Shap Value 정렬
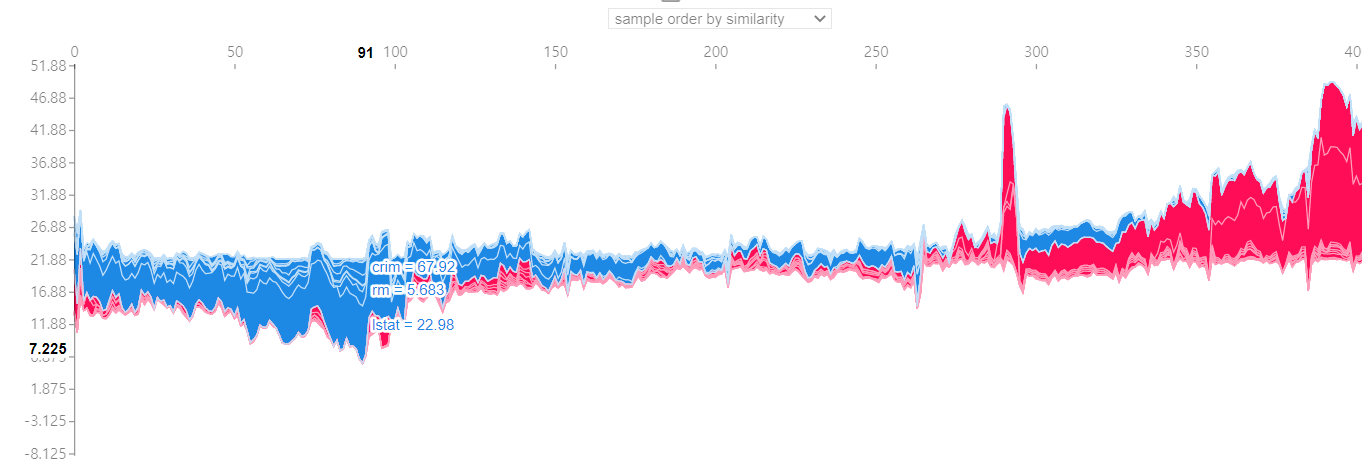
- 위와 같이 관점별 전체 shapley value를 시각화 하였을 때, 이를 어떻게 해석해야하는걸까요? 가로축은 행의 인덱스를 나타내고, 그 행의 예측값(y축)과 피처별 기여도를 나타내는 건가요?
- 그렇다면, 이 그림에서는 앞 행은 상승요인이 주로 나타나고 뒷 행은 하락요인이 주로 나타난다고 봐야할까요?
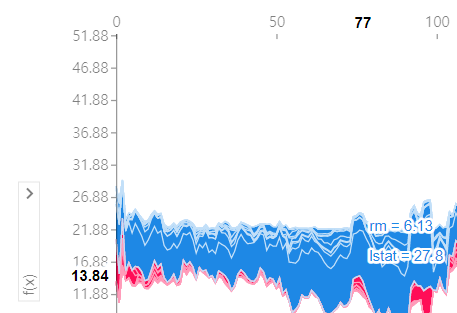
- 예를 들어 similarity에 대해 정렬했을 때, rm, lstat이 다음과 같고 예측값이 13.84이며 위에 숫자가 77이라는건, 77번째 행의 예측값은 13.84이고 rm과 lstat는 각각 상승요인이라는 뜻인가요?
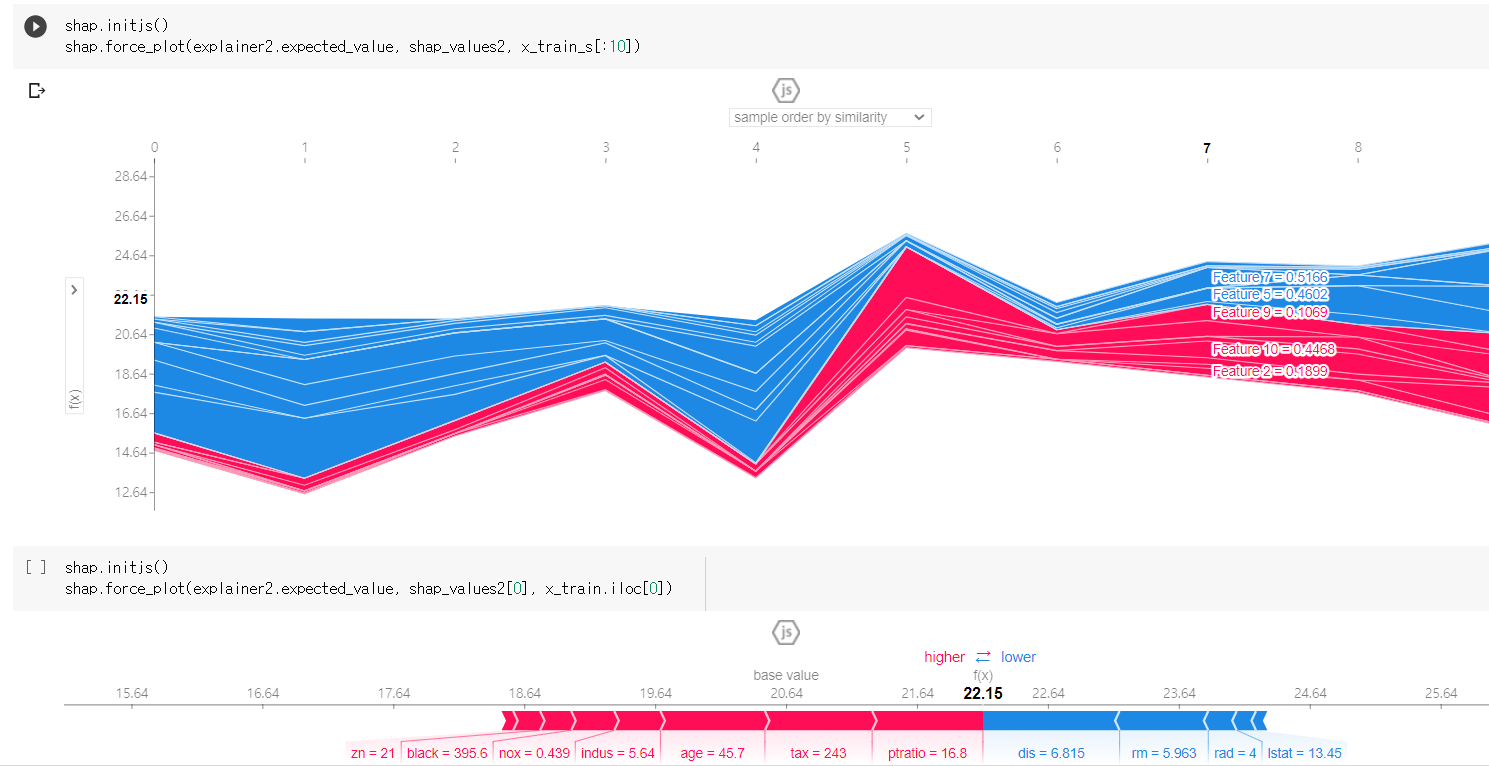
- 가로축의 숫자가 행의 인덱스를 나타내는게 맞다면, svm의 shapley value 그래프에서 위 사진은 7번째 인덱스를 나타내지만 아래에 0번째 인덱스만 추출한 결과값과 같게 나타납니다. 왜이러는걸까요..?

내 인생의 주연