abstract
pretrained model은 downstream tasks에서 우수한 성능 향상을 보였지만 모델의 커진 사이즈로 GPU,TPU 메모리가 제한적이고 training 시간이 길어졌다.
이 문제를 해결하기 위해 파라미터를 줄이는 두 개의 기술을 제시한다. 또한 SOP도 제시!
related work
1. Scaling up Representation Learning for Natural Language
Devlin et al은 더 큰 hidden size, hidden layer, attention head를 사용하면 더 나은 성능을 보여줄 수 있음을 확인할 수 있었다. 그러나 1024 hidden size에서 멈췄다. 아마 모델 사이즈와 계산 비용이 비쌌기 때문이다.
또한 GPU / TPU의 메모리는 제한적이고 최신 모델들은 수억 또는 수십억 개의 parameter를 가지므로 memory limitation problem이 쉽게 발생한다.
Chen et al. (2016)은 gradient checkpointing이라는 방법을 제안하였고 Gomez et al. (2017)은 각 layer의 activation을 재구성하여 intermediate activation을 저장할 필요가 없도록 하는 방법을 제안하였다. 두 방법 모두 속도비용으로 메모리 메모리 소비를 줄인다. 반대로, parameter reduction techniques는 메모리 소비를 줄이고 학습 속도를 높인다.
2 Cross-Layer Parameter Sharing
Hao et al., (2019)는 parameter-sharing transformer를 standard transformer와 결합하여 standard transformer보다 더 높은 성능을 달성하였다.
3 Sentence Ordering Objectives
BERT에서 사용하는 NSP는 SOP와 비교하여 더 쉬운 task로 ALBERT는 두 개의 text segment의 순서를 예측하여 pre-train loss로 사용한다.
NSP loss는 single task에서 topic prediction과 coherence prediction을 수행하는데 topic prediction은 coherence prediction에 비해 쉬운 task이고 MLM loss를 사용하여 학습한 내용과 겹치게 된다.
SOP는 특정 downstream task에서 더 효과적임을 알아냈다.
새롭게 제안한 방법
1. factorized embedding parameterization
- 기존 bert : input token embedding size(E)와 hidden size(H)가 동일함
- albert : input token embedding size(E)를 hidden size(H)보다 작게 설정한다.
input token embedding size(E) : 각 토큰의 정보만 담고있는 벡터
hidden size(H) : transformer의 output size로 해당 토큰과 주변 토큰의 관계까지 반영한 contextualized representation이다. 그러므로 히든 사이즈가 더욱 많은 정보를 담고있기에 사이즈 차이를 두는 것이 타당하다고 생각한다.
--> 기존 모델과 TRANSFORMER의 input size가 달라질 수 있으므로 레이어 하나 추가해서(E*H matrix 사용) 사이즈 바꿈
기존엔 V x H albert는 VxE+ExH로 바꾸어 파라미터 값을 줄인다. (E, H가 V보다 상대적으로 작아서 가능)
2. cross-layer parameter sharing
albert는 layer의 모든 파라미터를 공유한다. 기존 bert는 not shared
즉, 기존의 bert transformer block이 1~12까지 거쳤으면 알버트는 이와 같은 효과를 누리기 위해 하나의 transformer block을 12번 거친다. 이렇게 함으로 하나의 레이어가 여러층의 레이어 기능을 모두 하여 학습할 수 있도록 한다.
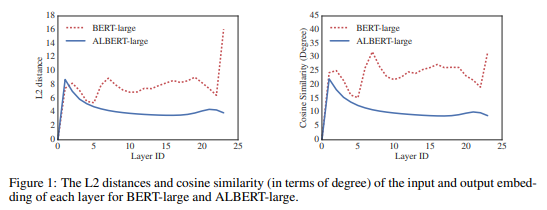
parameter sharing이 network의 parameter 안정화에 영향을 주는것을 알 수 있다.
3. sentence-order prediction
bert는 문장이 서로 연속된 문장인지 맞추는 (NSP)를 사용했지만 알버트는 문장 순서를 바꾸고 올바른지 예측하는 SOP를 사용했고, 더 효율적이라는 것을 table5-실험을 통해 증명함
Experimental Setup
- Pre-train corpora: BookCorpus, Wikipedia (약 16GB)
- BERT와 동일한 input format
- maximum input length:512 10% 확률로 512보다 짧은 input sequence를 random하게 생성.
- Wordpiece vocab size: 30,000 (BERT, XLNet)
- n-gram masking을 사용하며 각 n-gram masking의 길이를 random하게 선택.
- n-gram 최대 길이: 3
- batch size: 4096
- optimizer: Lamb(You et al., 2019)
- learning rate: 0.00176
- Cloud TPU v3에서 진행하였으며 사용된 TPU의 수는 model size에 따라 64~1024이다.
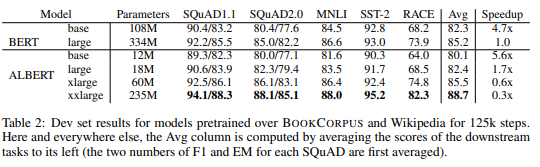
훨씬 적은 파라미터를 사용하면서도 ALBERT xlarge 성능이 높음을 알 수있다. 같은 large모델을 비교해봤을 때 성능은 좀 더 낮지만 속도는 더 빠르게 train할 수 있었다.
Discussion
ALBERT-xxlarge는 BERT-large보다 parameter가 적고 훨씬 더 좋은 성능을 보여줌. 그러나 large structure로 인해 계산비용이 더 비싸다.
따라서 중요한 다음 단계는 sparse attention(link) 및 block attention(link)과 같은 방법을 통해 ALBERT의 train 및 inference속도를 높이는 것이다.
논문에 환경을 같게 한 뒤, 기존의 버트와 비교하는 table이 많은데, 결론은 시간대비 성능이 좋다라는 의미로 따로 더 길게 옮겨 적진 않겠다.
