deeplearning optimizer 중 adadelta와 adam을 비교해보고자 한다.
아래 글과 코드는 "실전! 파이토치 딥러닝" 책을 참고하였다.
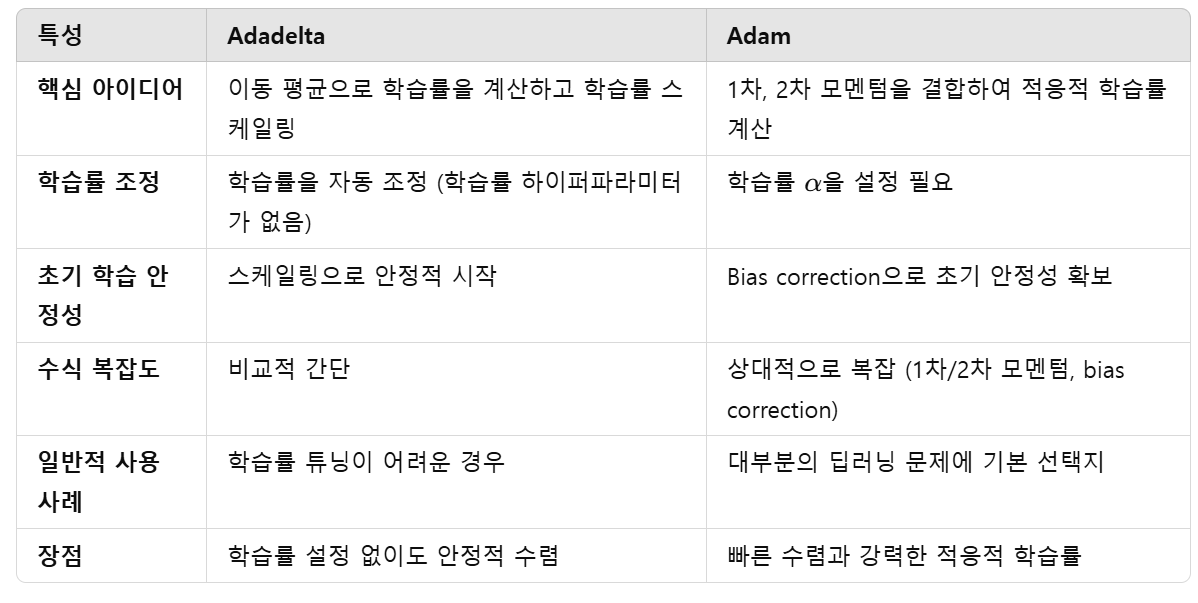
1. Adadelta & Adam 수식
두 알고리즘 모두 적응적 학습률(adaptive learning rate)을 사용
-> 매개 변수의 변화률이 많을 수록 이후에는 낮은 속도의 학습률을 가짐
1.1 Adadelta
- 학습율 람다에 대한 정의가 필요 없음
- 이전 경사의 제곱 값을 활용함
1.2 Adam
- 이전 경사의 제곱 값 뿐만 아니라 감소 크기도 활용함
-> 벡터의 방향과 크기 모두 고려. - 대체로 Adam 사용
1.3 요약
2. 비교 실험
MNIST 학습 및 평가 실험을 통해서 두 Optimizer의 차이를 확인하자
epoch = 5
batch size = 32
learning rate for adam = 0.001
2.1. 모델 훈련 시간, 궤적(수렴)
- one epoch 학습 시 소요된 시간 (1875개의 데이터 셋)
- adadelta: 약 49.46s
- adam: 약 41.29s
- 수렴 (train loss 확인)
- adadelta
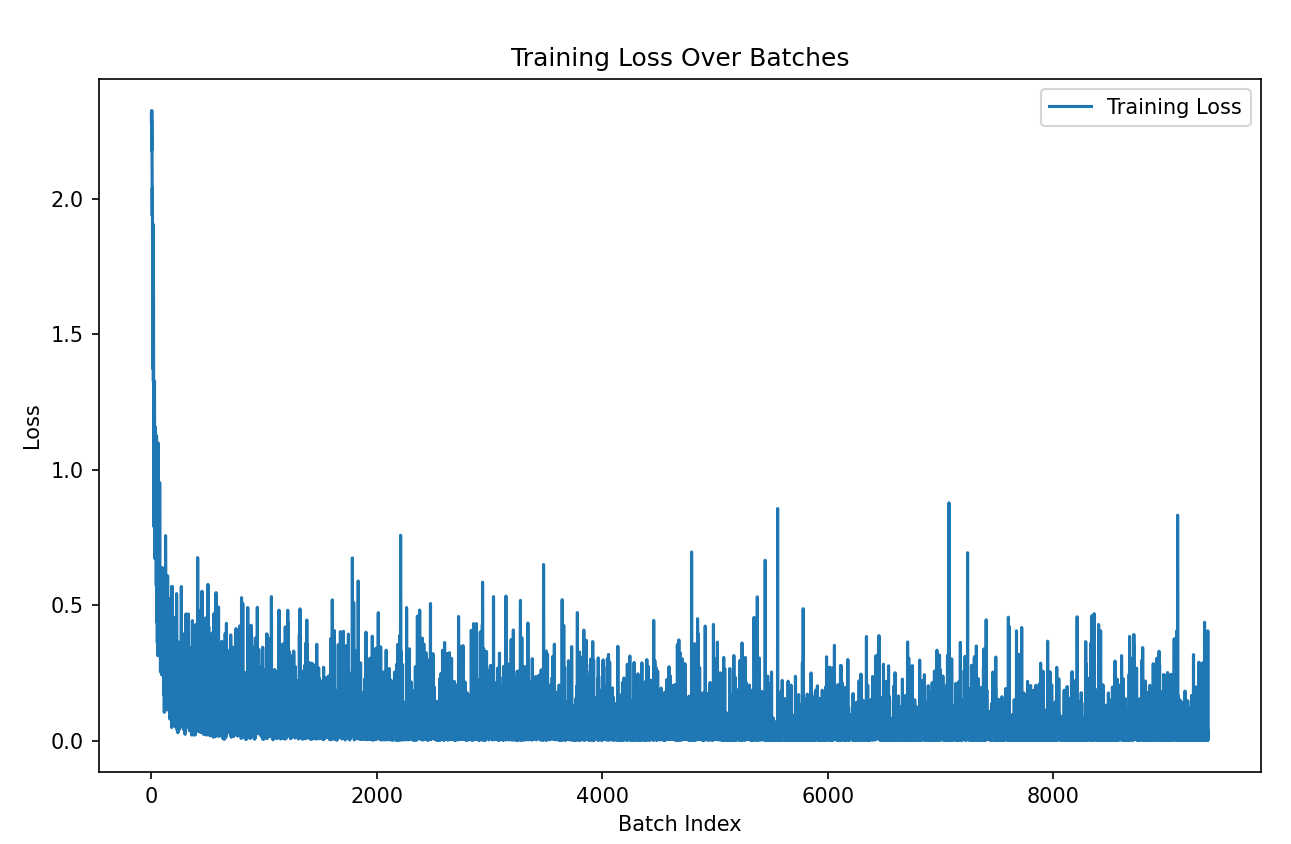
- 약 batch 1000 이후로 수렴함
- adam
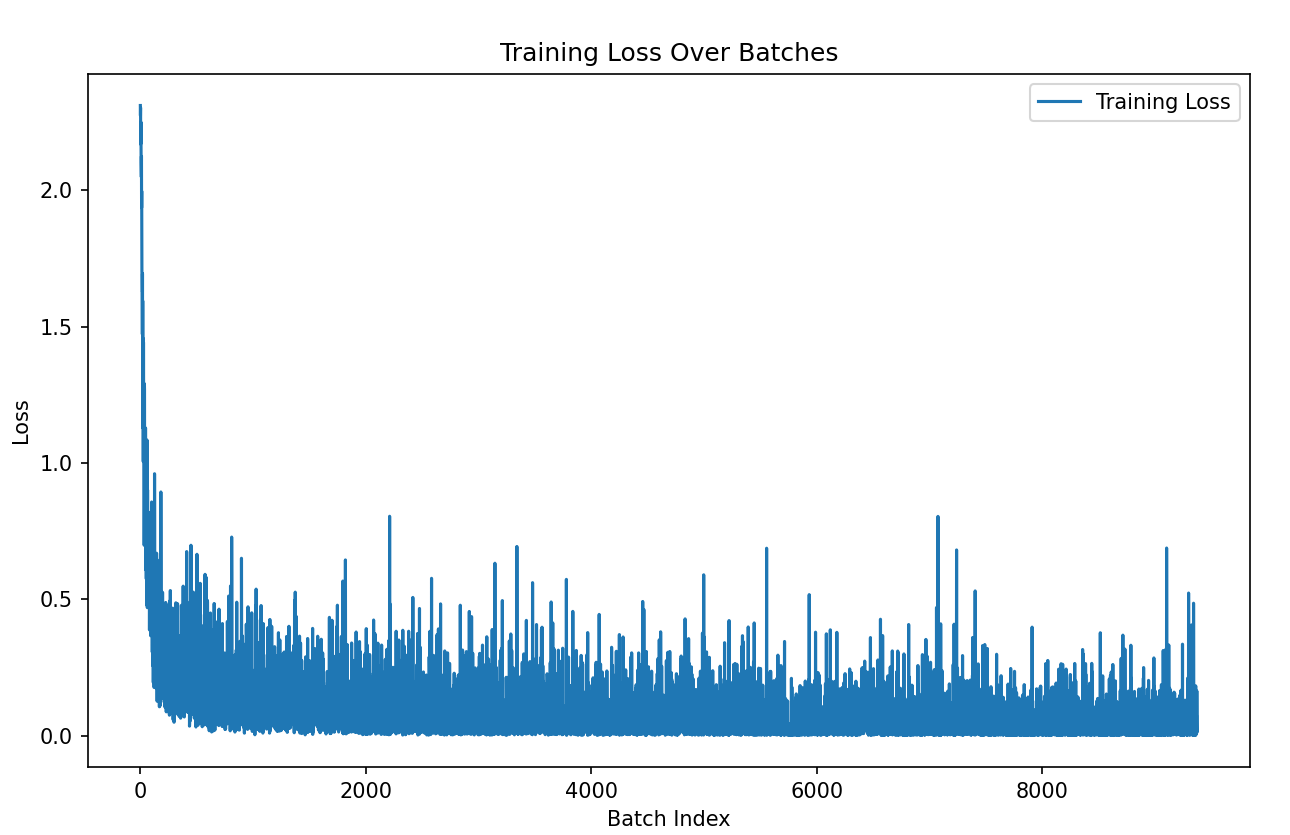
- 약 batch 2000 이후로 수렴함
2.2. 최종 모델 성능
- adadelta (training loss: 0.000609, test loss: 0.0343, test accuracy: 9890/10000)
- adam (training loss: 0.007123, test loss: 0.0316, test accuracy: 9902/10000)
2.3. 매개변수 비교
첫번째 Convolution layer와 flatten 후 dense layer에서 parameter 차이가 크게 발생함.
from copy import deepcopy
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import time
class ConvNet(nn.Module): #nn.Module을 상속받아 기본적인 기능들을 사용할 수 있게 만듦 => nn.Moudle: 부모 클래스
def __init__(self):
super(ConvNet, self).__init__() # super().__init__() 으로 사용해도 같음. 클래스 이름 작성하는 건 python2 버전임
# 1 in_channels : gray scale image, 16 out channels : 16 feature maps, # stride < kernel_size * 0.1
self.cn1 = nn.Conv2d(1, 16, 3, 1) # 1 in_channels := gray scale image.
self.cn2 = nn.Conv2d(16, 32, 3, 1)
# nn.Dropout: 주로 1차원에 사용. 모든 차원에 사용 가능.
# 2D: 2D 데이터. 채널 단위로 드랍 아웃. 각 채널에 대해 동일한 위치에 있는 값을 동시에 드롭하기 때문에, 전체 채널이 드롭되거나 유지되는 방식입니다. 이를 통해 채널 간 상관관계를 보존할 수 있습니다.
# 3D: 동영상. 특정 채널의 모든 프레임이나 볼륨이 드롭되기 때문에, 3D 데이터에서 특정 시퀀스나 채널이 온전히 제거되는 효과를 얻습니다.
self.dp1 = nn.Dropout2d(0.10)
self.dp2 = nn.Dropout2d(0.25)
self.fc1 = nn.Linear(4608, 64) # 32개의 채널, 1개의 채널 = 12 X 12
self.fc2 = nn.Linear(64, 10) # 10개의 class (classification 문제)
def forward(self, x): # input 이미지의 해상도 28 X 28 X 1
x = self.cn1(x) # 3 size kernel 적용 후 26 X 26 X 16
x = F.relu(x)
x = self.cn2(x) # 3 size kernel 적용 후 24 X 24 X 32
x = F.relu(x)
x = F.max_pool2d(x,2) # 2 size kernel 적용 후 12 X 12 X 32
x = self.dp1(x)
x = torch.flatten(x, 1) # 1 X (12 X 12 X 32)
x = self.fc1(x) # 1 X 64
x = F.relu(x)
x = self.dp2(x)
x = self.fc2(x) # 1 X 10
op = F.log_softmax(x, dim=1) # softmax에 log 값 취함. gradient 구할 때 Nan 발생 막아주는 함수
return op
# backpropagation
def train(model, device, train_dataloader, optim, epoch):
model.train() # ConvNet class를 받아옴
train_loss = []
start_time = time.time()
for b_i, (X, y) in enumerate(train_dataloader): # one epoch
# (b_i = batch_idx)
# print(f"Batch {b_i + 1}: data shape = {X.shape}, target shape = {y.shape}")
# Batch 1: data shape = torch.Size([32, 1, 28, 28]), target shape = torch.Size([32])
X, y = X.to(device), y.to(device) # copy data
optim.zero_grad() # optim (torch.optim) 최적화 알고리즘 기능을 담고 있음. SGD, Adam, RMSprop 등
pred_prob = model(X)
loss = F.nll_loss(pred_prob, y) # - log softmax
loss.backward()
optim.step()
train_loss.append(loss.item())
if b_i % 100 == 0: # every 10 batches
print('epoch: {} [{}/{} ({:.0f}%)]\t training loss: {:.6f}'.format(epoch, b_i, len(train_dataloader), 100.*b_i/len(train_dataloader), loss.item()))
end_time = time.time()
print(f"Runtime: {end_time - start_time:.6f} seconds")
return train_loss
def test(model, device, test_dataloader):
model.eval() # 학습할 때만 필요한 Dropout, Batchnorm 등의 기능을 비활성화 하여 추론할 때의 모드로 작동
loss, success = 0, 0
with torch.no_grad(): # gradient calculation을 비활성화하여 메모리 소비를 제한함 (with은 파일이나 데이터베이스를 시작하고 자동 닫기/종료하는 기능)
for X, y in test_dataloader:
X, y = X.to(device), y.to(device)
pred_prob = model(X)
# 배치별 손실 합
loss += F.nll_loss(pred_prob, y, reduction='sum').item()
pred = pred_prob.argmax(dim=1, keepdim=True) # 500개의 데이터에 대한 라벨이 저장됨
success += pred.eq(y.view_as(pred)).sum().item() # view_as : reshape
loss /= len(test_dataloader.dataset)
print('\nTest dataset: Overall Loss: {:.4f}, Overall Accuracy: {}/{} ({:.0f}%)\n'.format(loss, success, len(test_dataloader.dataset), 100.*success/len(test_dataloader.dataset)))
# 평균값과 표준 편차 값은 훈련 데이터셋의 이미지 전체의 픽셀값 전체에 대한 평균으로 계산된다.
train_dataloader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1302,),(0.3069,))])),
batch_size=32, shuffle= True
) # transforms.ToTensor() converts a PIL Image or Numpy array to a torch.Tensor and scales its pixel values to the range [0,1]
test_dataloader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train = False,
transform= transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1302,), (0.3069,))])),
batch_size=500, shuffle=False
)
torch.manual_seed(0)
device = torch.device("cpu")
model_adadelta = ConvNet()
model_adam = deepcopy(model_adadelta)
optimizer_adadelta = optim.Adadelta(model_adadelta.parameters(), lr=0.5) # Adam 비교 report 제작
optimizer_adam = optim.Adam(model_adam.parameters(), lr=0.001)
# adadelta 로 학습
all_train_losses_adadelta = []
for epoch in range(1,6):
train_losses = train(model_adadelta, device, train_dataloader, optimizer_adadelta, epoch)
all_train_losses_adadelta+=train_losses
test(model_adadelta, device, test_dataloader)
# adam으로 학습
all_train_losses_adam = []
for epoch in range(1,6):
train_losses = train(model_adam, device, train_dataloader, optimizer_adam, epoch)
all_train_losses_adam+=train_losses
test(model_adam, device, test_dataloader)
# test_samples = enumerate(test_dataloader)
# b_i, (sample_data, sample_targets) = next(test_samples)
# plt.imshow(sample_data[0][0], cmap='gray', interpolation = 'none')
# print(f"Model prediction is : {model(sample_data).data.max(1)[1][0]}")
# print(f"Ground truth is : {sample_targets[0]}")
# 손실 값 시각화
# plt.figure(figsize = (10,6))
# plt.plot(all_train_losses, label='Training Loss')
# plt.xlabel('Batch Index')
# plt.ylabel('Loss')
# plt.title('Training Loss Over Batches')
# plt.legend()
# plt.show()
# 모델 파라미터 비교
for name, param_adadelta in model_adadelta.named_parameters():
param_adam = dict(model_adam.named_parameters())[name]
print(f"Layer: {name}")
# print(f"SGD Parameter:\n{sum(param_sgd.data)}")
# print(f"Adam Parameter:\n{sum(param_adam.data)}")
diff = torch.mean(param_adadelta.data - param_adam.data)
print(f"Difference:\n{diff}\n")
norm_diff = (torch.max(param_adadelta) - diff)/(torch.max(param_adadelta) - torch.min(param_adadelta))
print(f"Normalized Difference:\n{norm_diff}\n")
# fc1.weight
# cn1.weight
:0